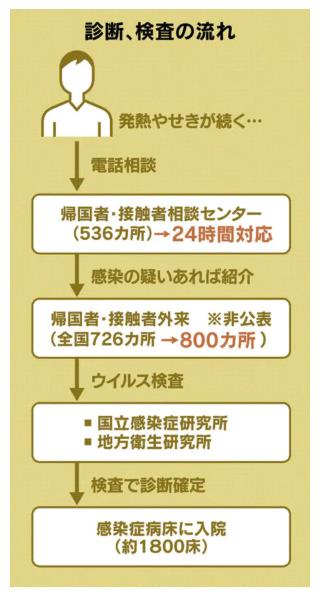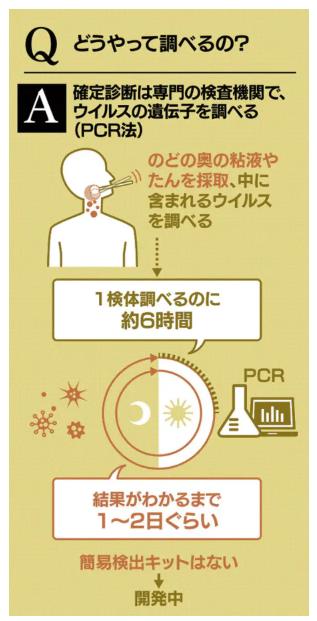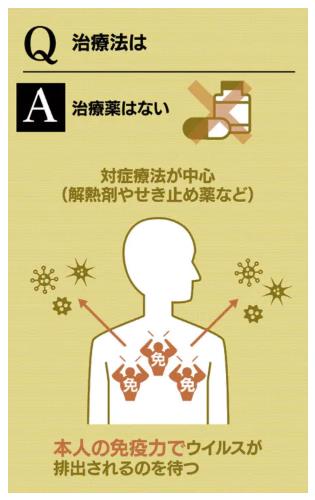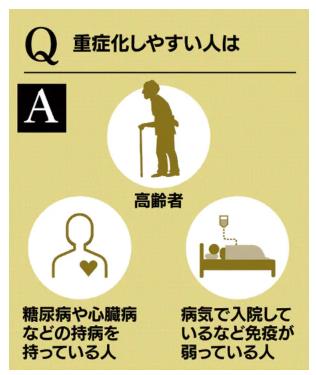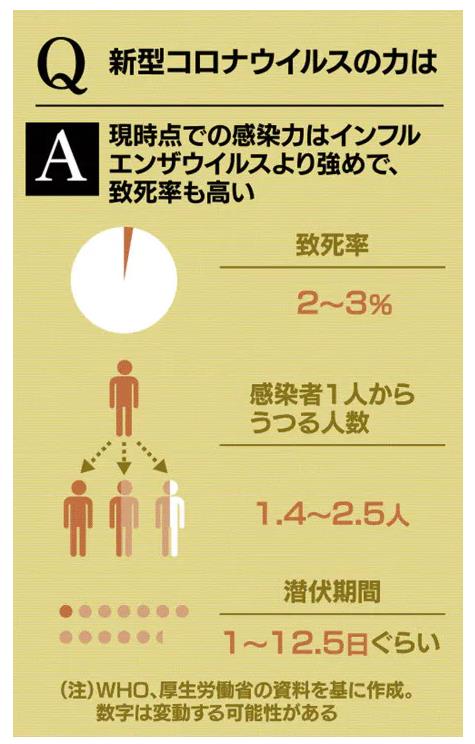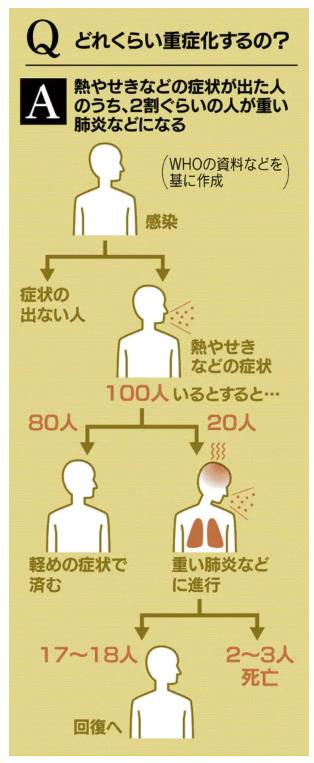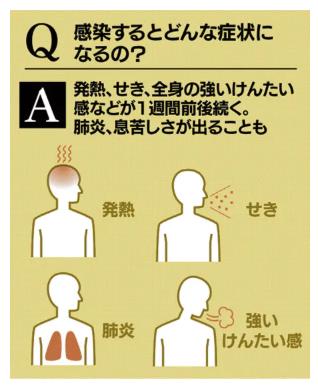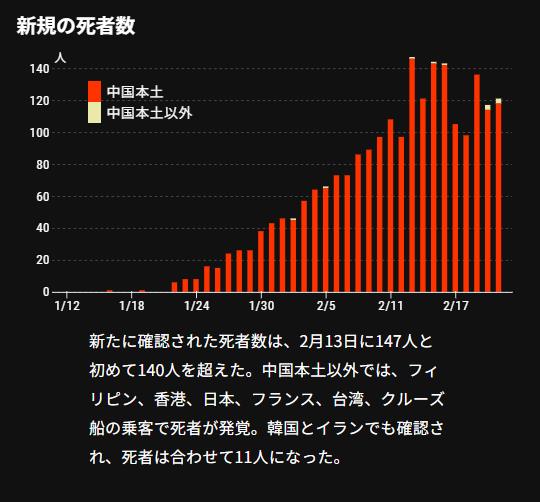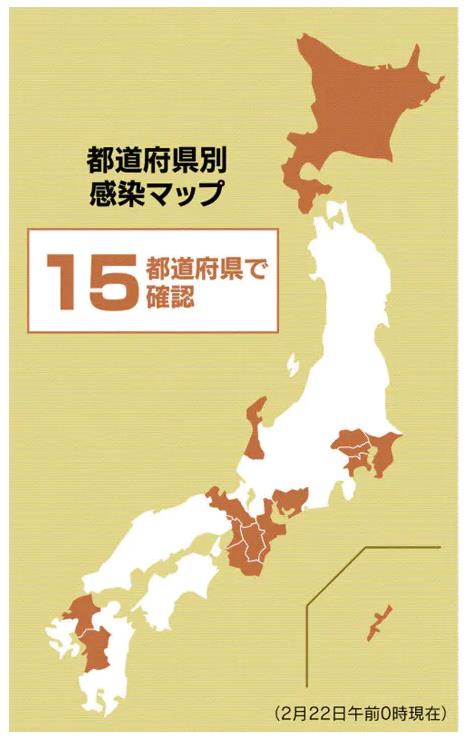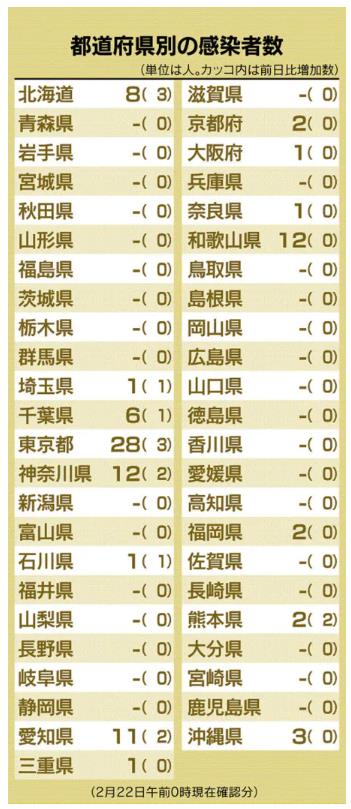

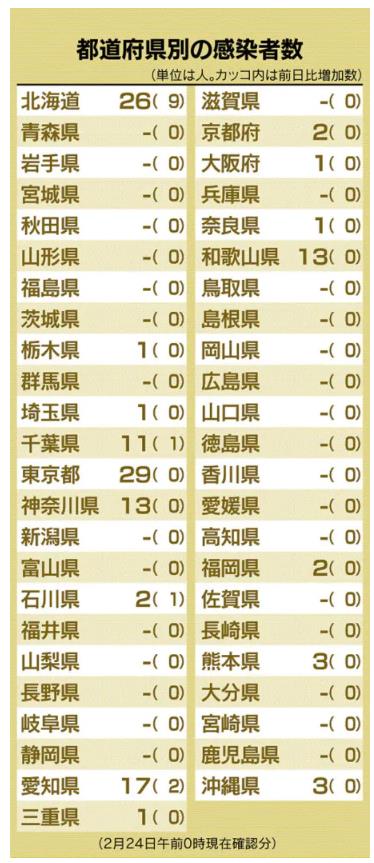
新型肺炎、16都道府県で129人感染(2月24日)
https://www.nikkei.com/article/DGXMZO55811680Z10C20A2I00000/

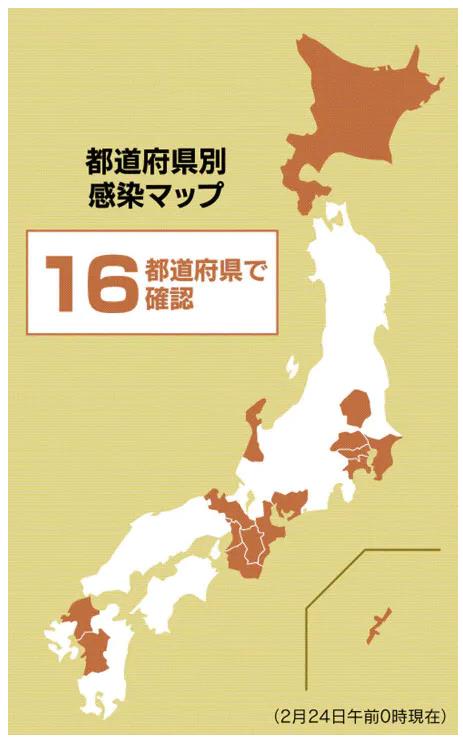
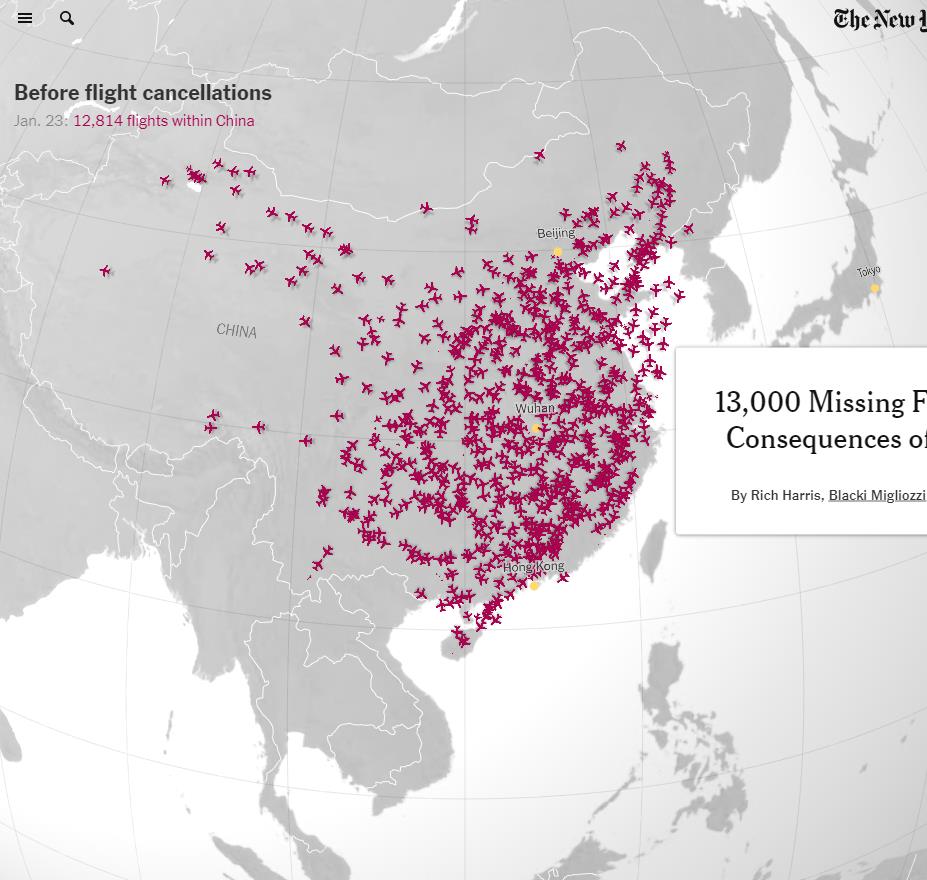
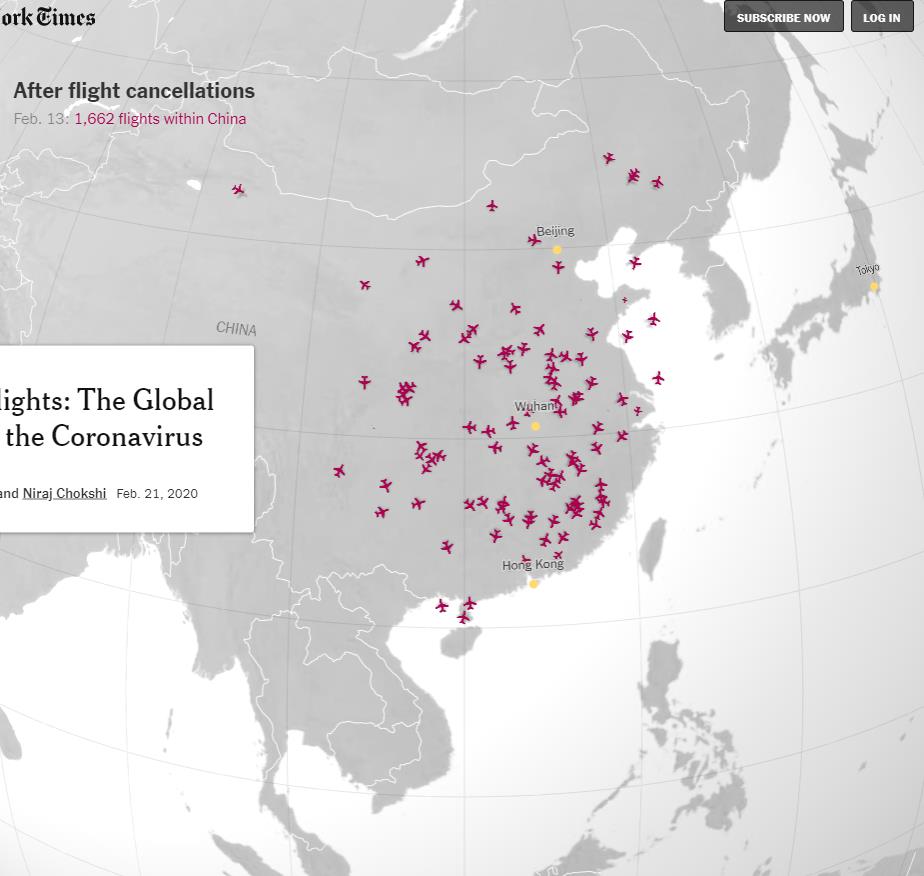
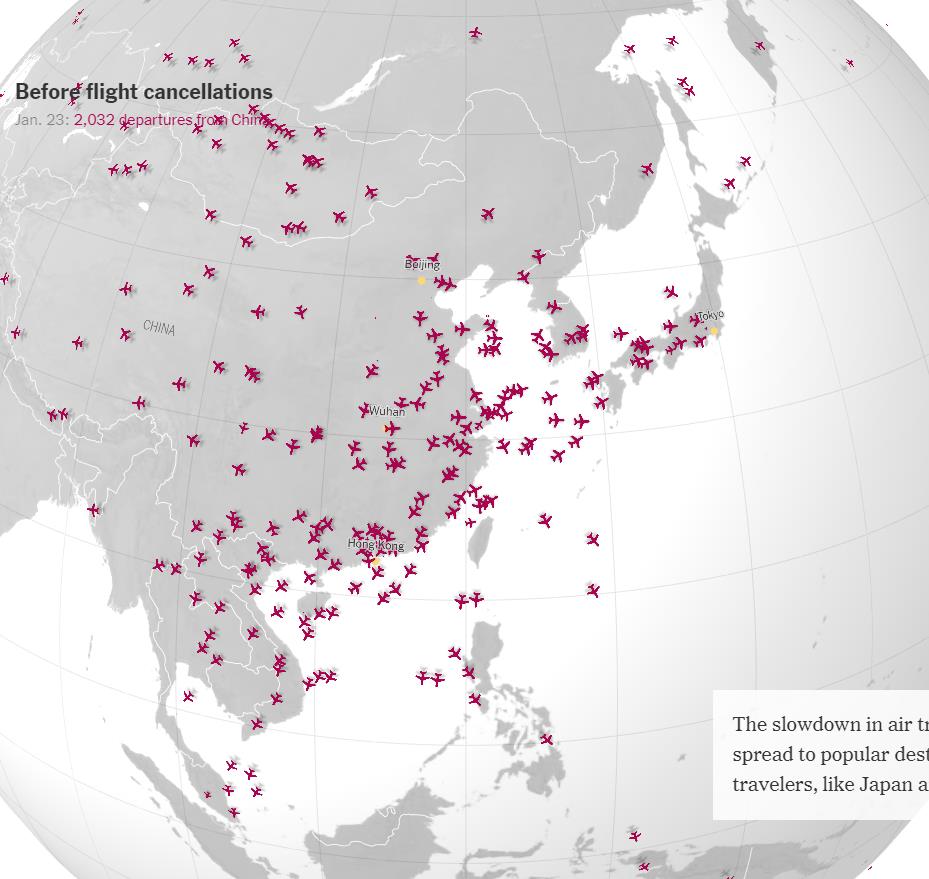
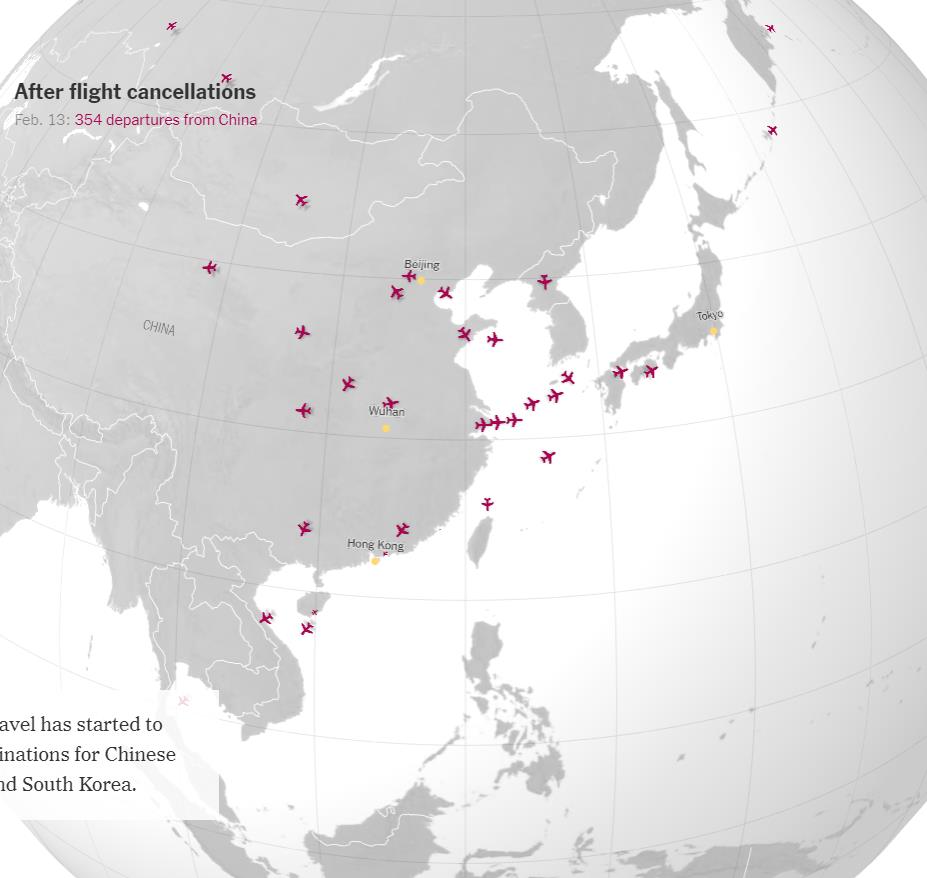
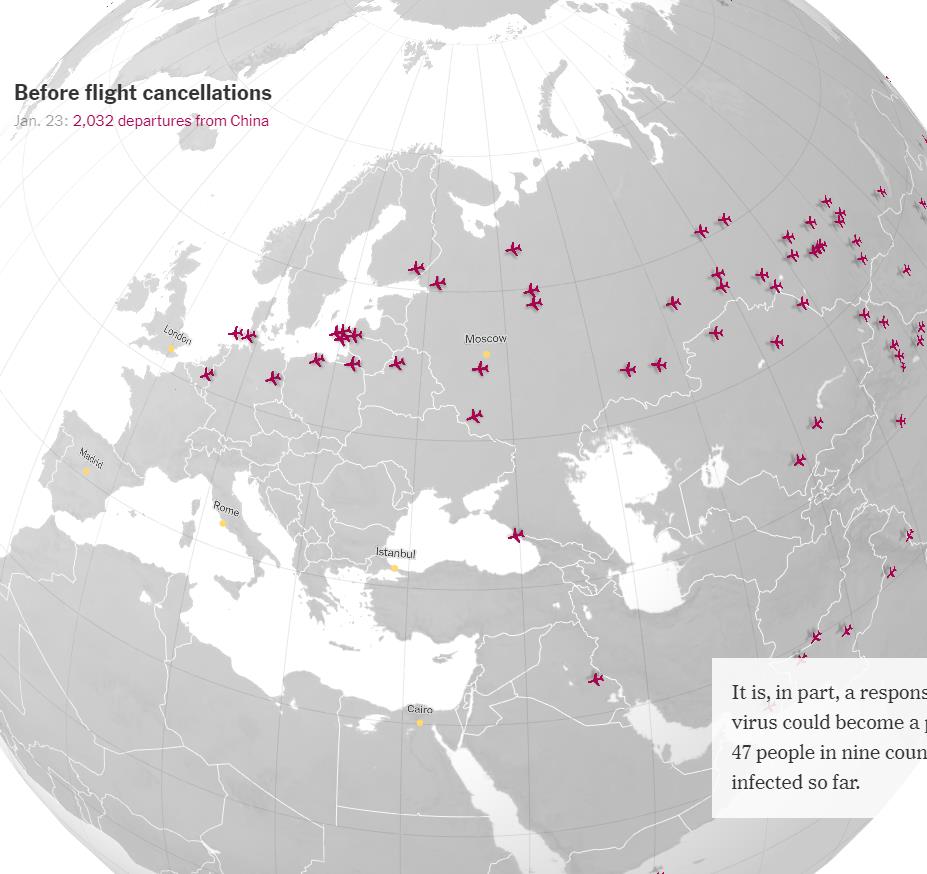
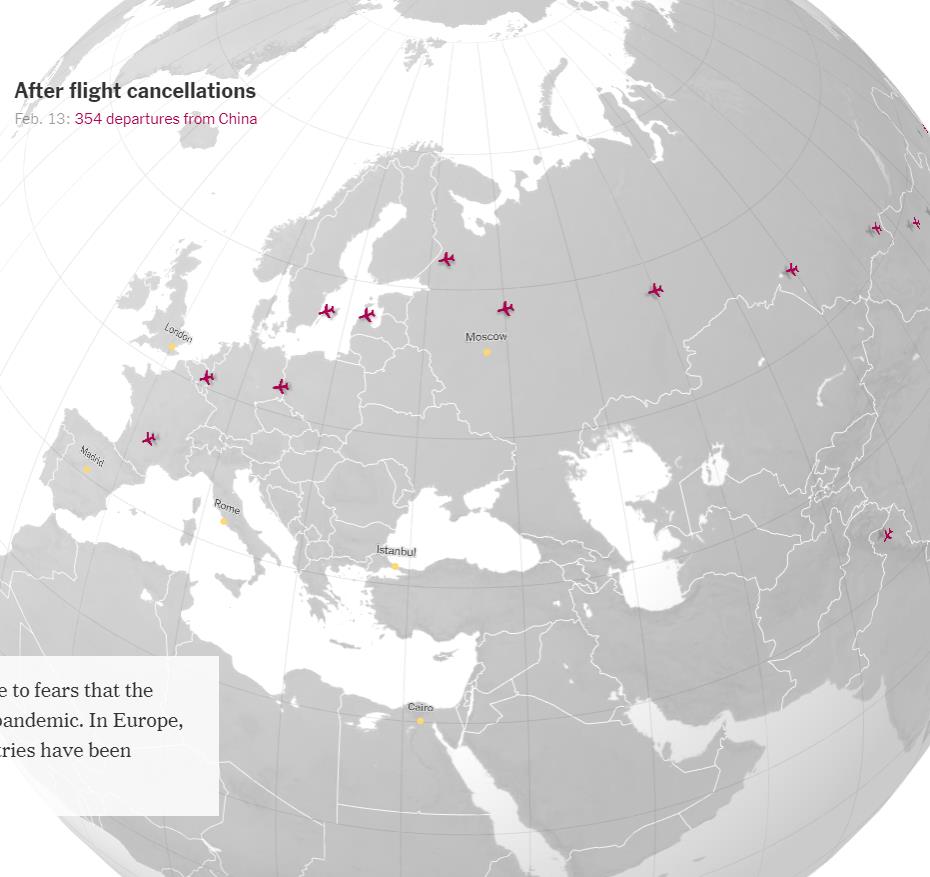
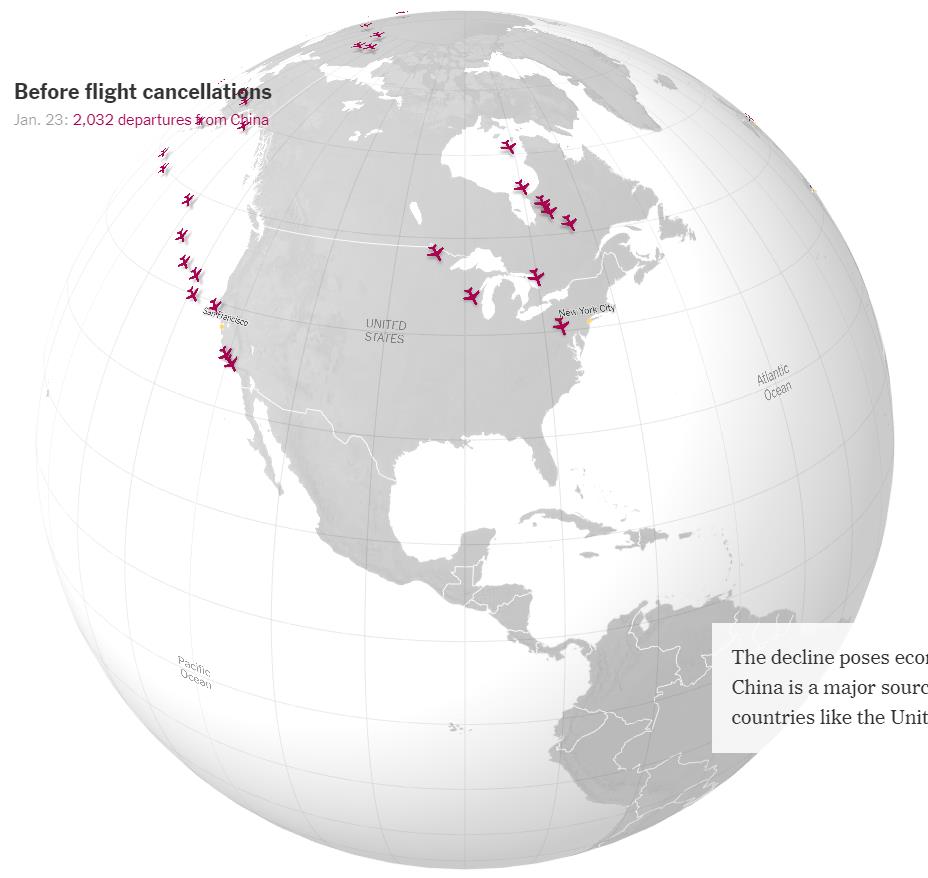
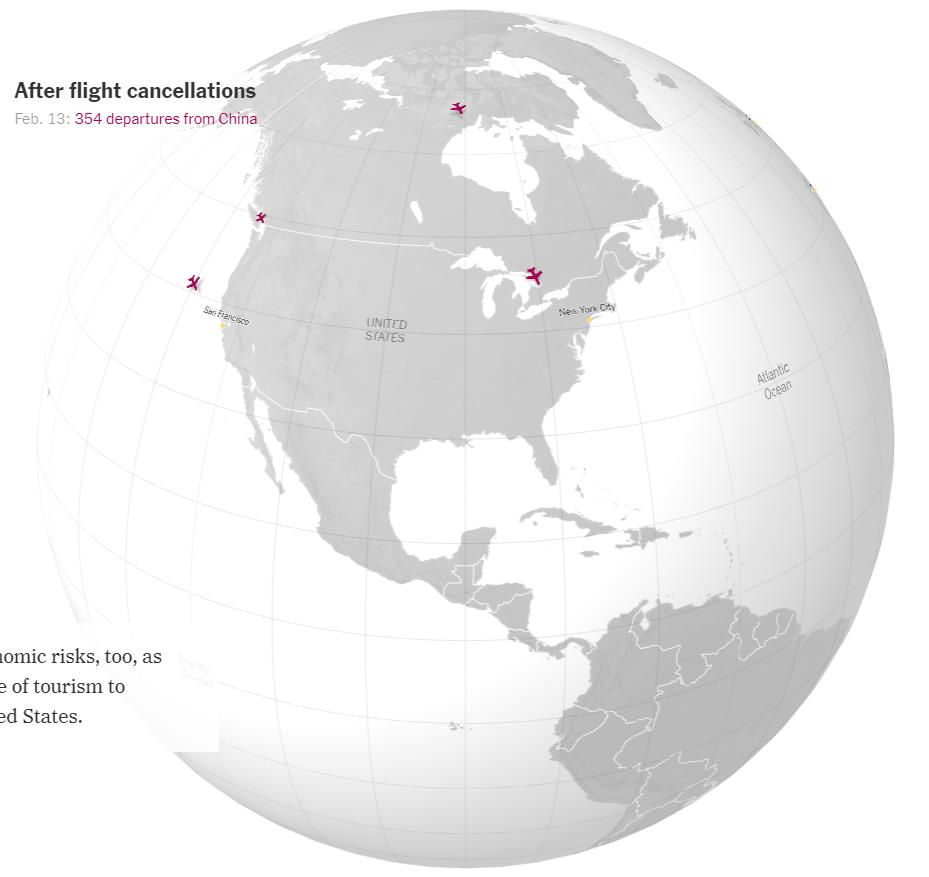
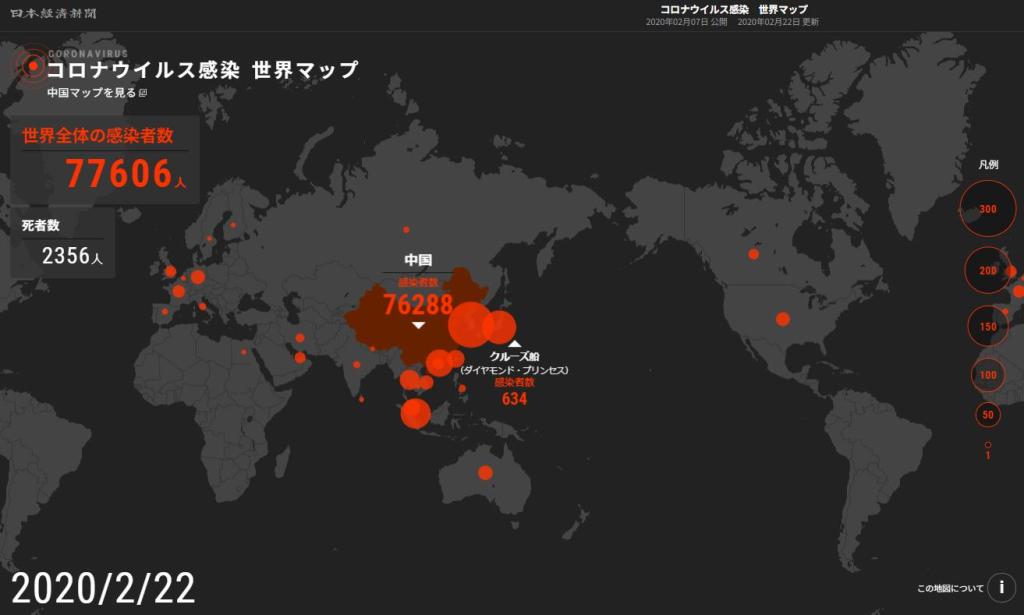
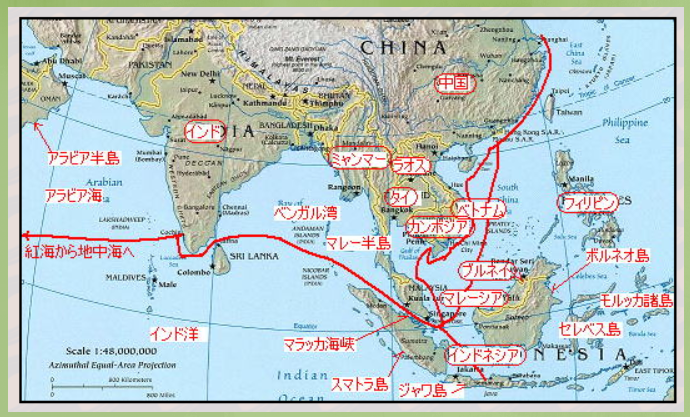
※ これを見れば、どこが感染の中心で、次はどこに飛び火しそうか…、ということが分かるな…。
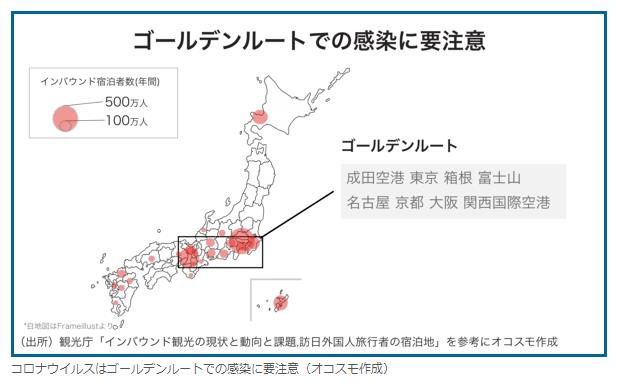
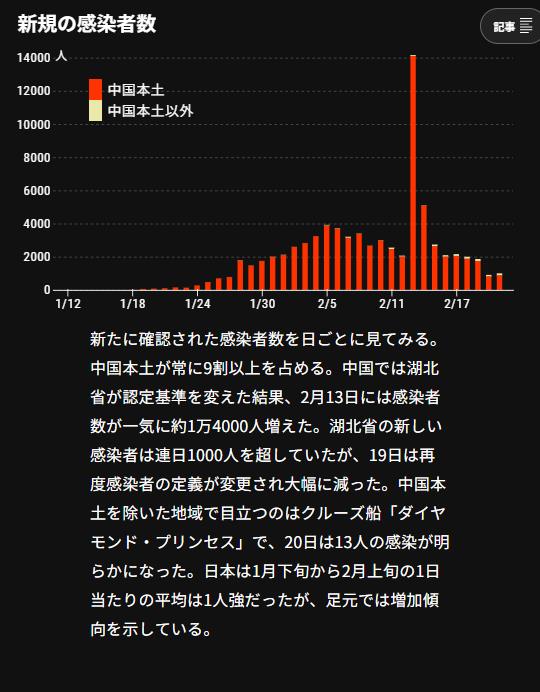
※ まさに、この通りの話しだな…。
新型肺炎「ウイルスに二面性、正体見えず」大安研の奥野理事長
https://www.sankei.com/west/news/200223/wst2002230006-n1.html
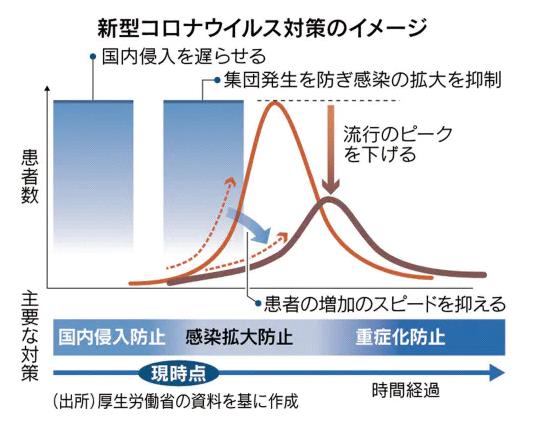
厚労相「流行ピーク抑えたい」 新型肺炎、拡大の移行期
https://www.nikkei.com/article/DGXMZO55991750T20C20A2CZ8000/
インフル・エボラ・HIV薬を転用へ RNA複製など阻止
https://www.nikkei.com/article/DGXMZO55987550S0A220C2EA2000/
トランプ氏、東京五輪に招待 安倍首相から
https://www.nikkei.com/article/DGXMZO55805150Z10C20A2EAF000/
『トランプ米大統領は18日、安倍晋三首相から夏の東京五輪に招待され、出席を検討していると明らかにした。訪問先のカリフォルニア州ロサンゼルスでの五輪関連のイベントで、記者団に「まだ決めていない。行けるかどうか調整したい」と語った。』
ウイルス感染の米国人 チャーター機帰国に大統領激怒 米報道
https://www3.nhk.or.jp/news/html/20200224/k10012298661000.html?utm_int=news_contents_news-main_006
『アメリカの有力紙、ワシントン・ポストは21日、政府関係者の話として、トランプ大統領が、担当者からの事前の相談がなかったなどとして激怒するとともに、政権に打撃を与えかねないと不満を述べたと伝えました。
トランプ大統領には、事前の説明で、ウイルスへの感染が確認されたり、症状がみられたりする乗客は日本にとどまると伝えられていたということです。
また、ワシントン・ポストは、トランプ大統領が、アメリカで大規模な感染が起きれば、大統領選挙でのみずからの再選に影響が出かねないと懸念していると伝えています。』
柔道の山下会長「中国選手の五輪出場機会、奪われないように」
https://www.sankei.com/tokyo2020/news/200223/tko2002230003-n1.html
国民の命は二の次か? 武漢パンデミックを後追いする日本
https://news.yahoo.co.jp/byline/endohomare/20200223-00164330/
『しかしなぜクルーズ船に関してまで、このようなずさんなことをしたのかに関して、「政府の無能」「官僚の不透明さ」あるいは「安倍政権が新型肺炎の悪影響を矮小化しようとしたから」以外に、何があるのだろうと考えあぐねていたところ、あるツイートにぶつかって、ハッとした。それは自民党の参議院議員「たけみ敬三」氏(厚生労働副大臣や外務政務次官等を歴任)のツイートで、そこには以下のようなことが書いてある。
――クルーズ船内の感染予防が不十分だったのではないかとの疑問が出されている。今回のオペレーションの最優先の目的は3700名の乗客乗員の中に何名いるかわからぬ保菌者が入国し国内で感染が広がることを阻止する事だ。これには成功した!(午後10:03 2020年2月20日)
ここに日本政府の思惑が滲み出ているように思う。』
感染者、地方にも拡大 「市中感染否定できず」
https://www.sankei.com/life/news/200223/lif2002230054-n1.html
興行中止保険 新型肺炎は補償外 主催者は泣き寝入りか
https://www.sankei.com/life/news/200223/lif2002230057-n1.html
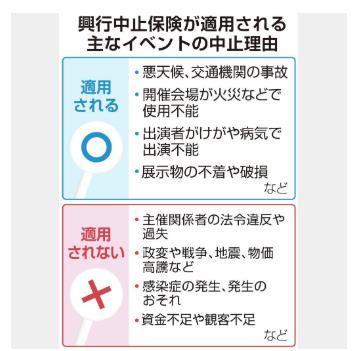
※ なかなか「イベント中止」に踏み切れないのは、こういうことも影響しているようだ…。

“対面”に遠隔ロボット、感染対策で脚光
https://newswitch.jp/p/21254
『同ロボットはデジタルサイネージ(電子看板)とカメラ、無線機器、スピーカー、マイクなどで構成。ホテルのフロント受付や空港・大規模施設の案内など、離れた場所から人に接客や情報案内などのサービスができる。
会社の会議室利用などを想定した据え置き型、受付やインフォメーションセンター向けの振り向き型、時間や客の増減に合わせ巡回ができる移動型の3種類をそろえる。価格はタイプにより異なる。
当初は人手不足に悩むホテルや観光施設の案内需要をにらんでいた。だが、新型肺炎の感染拡大で新たなニーズが発生。遠隔操作で患者と対話することができれば感染防止になるため、病院や薬局などでメリットは大きい。ロボットの生産は外部委託だが「月数十台なら対応可能」(同)という。』
※ 逆に、「チャンス!」と捉えている向きも、あろうな…。