(『日本語の研究」第19巻3号2023.12.1)
105
〔特別寄稿〕
和歌集の歌風の言語的差異の記述
–大規模言語モデルによる分析—-
近藤泰弘
https://www.jstage.jst.go.jp/article/nihongonokenkyu/19/3/19_105/_pdf/-char/ja
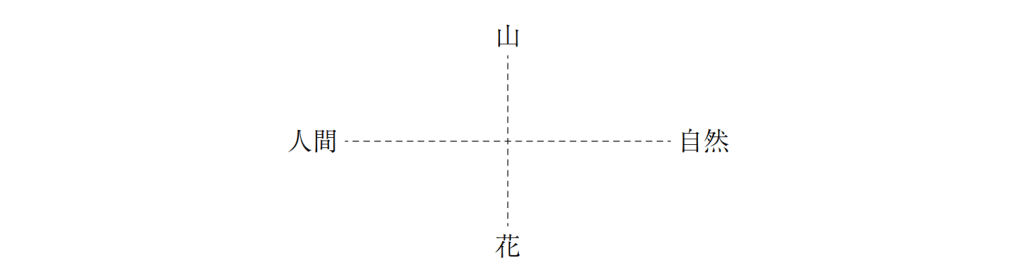
キーワード:和歌、大規模言語モデル、埋め込みベクトル、歌風、主成分分析
要 旨
ある和歌集の持つ「歌風」を統計的に調査するには、従来は、語彙の偏りや分布を
中心に研究することが中心であった。
しかし、近年の機械学習の発達によって、
word2vecなどの単語埋め込みベクトルを用いて研究することが可能になった0
本研
究では、大規模言語モデルによる文埋め込みベクトルを主成分分析で次元圧縮するこ
とで、和歌の歌風の中核にある意味の体系を記述することができることを実証した。
そして、『古今集」と『万葉集」とでは大きな差異があり、それが漢詩の影響による
ものであることの可能性について述べた。
1はじめに
本稿は、和歌集の歌風の言語的な差異について、特に『万葉集』と『古今集』とが、
言語的にどのような差があるかという点について、同時代のその他の言語資料を用いな
がら、大規模言語モデルを活用して研究を行うものである。
まず、言語的な差についてであるが、もちろん、『万葉集』と『古今集』はその成立
の時代も異なり、文学としての性質も大きな差がある。言語的にも、奈良時代の言語と、
平安時代の言語とで異なっている。使役の「しむ」と「す・さす」の差などがよく知ら
れているところである。また、その他、例えば、『万葉集』には敬語があるが、『古今集』
には敬語がないなど、その理由がよくわからない言語的な差も存在する。語彙の面でも、
「花」の代表的なものとして、万葉では「梅」が、古今では「桜」が代表的であるとい
う文化史の反映と思われるものも存在する。
その他の多様な言語的相違を、さらに概括
的に捉えることができないかというのが本稿の視点である。
そのためのツールとして、
「大規模言語モデル」を用いることを試みてみたい。
次に「大規模言語モデル」を活用するということについて、最初に簡単に述べておく。
近時、一般に「大規模言語モデル」と言えば、ChatGPTなどの生成型の言語モデルを
106
指すことが多い。
しかし、ここで行うことは、ChatGPTに「万葉集と古今集はどう違
うか説明してください」などとプロンプトを与えて回答の生成を求めることではない。
本稿での方法は、それとは、まったく異なっている。
具体的には、歌集の本文テキスト
を、ChatGPTが内部表現として扱う形式に変換し、その内部表現を用いて分類•解析
を行う。
つまり本来の働きである「生成」に用いるのではなく、生成のための内部デー
タを用いて、あとは人間側で統計と解釈を行うのである。
データの解釈の方法は従来の
計量言語学の手法と同様である。
以上のようなことを前提として、以下の論を進めてい
くことにする。
2大規模言語モデルの埋め込み表現
ChatGPTのような大規模言語モデルは、非常に大量のテキストを使って、テキスト
のある単語の次の単語をマスクした形で入力し、それを推測させ、そのマスクした部分
の正解(これは元の文に当然存在する)と比べ合わせることで、その学習能力を獲得して
いく。
したがって、基本的には、ある単語の次にくる単語がなんであるかを確率的に推
測するだけだったはずなのであるが、その学習過程で、遠く離れた様々な制約(たとえ
ば、主語と述語、関係節、主題、接続助詞)をも学習するため、実際には、非常に高度な
能力を獲得していく。
また、ある文脈に共通して出現する単語のグループを学習してい
くことで、その単語の意味に相当する情報も獲得することができる。
単純に次の単語を
確率的に推測するといっても、直前直後の単語だけを見ているわけではないのである。
だからこそ、ChatGPTなどがまるで単語の意味や文法を知っているかのように、自然
な文章生成を行うことが可能になっているのである(岡野原(2023)など参照)。
さて、その前後の関係を把握する時に、テキストを単語(実際はやや小さい単位でトー
クンと呼ばれる単位)に分割し、学習させていくが、その過程で、ネットワーク上にその
トークンごとに特定の値が計算されて蓄積される。
この値は、先に示したように、単語
の文脈上の意味、統語的関係などを総合的に取り込んだうえでの、トークンの内部表現
となっている。
センテンスについても、その文脈に応じたトークンの組み合わせで適切
な数値の内部表現を得ることが可能である。
これを用いて、文の生成を行っているので
あるが、その生成するための途中の内部表現を取り出すこともできる。
ChatGPTを運営
しているOpenAIでは、ChatGPTのもとになったGPT-3ベースの言語モデルについて、
外部から単語や文を与えることで、それによるネットワークの内部表現の数値を取り出
すサービスを行っている(OpenAI (2023)) 〇
現在のサービスの名称はtext-embedding-
ada-002というものだが、単語や文を入力することで、それに応じた固定長1536次元
のベクトル数値を出力する。
このように、ニューラルネットワークを用いて、文脈の情
報を含めて数値化するものを、一般に、埋め込み表現と称する。
埋め込み表現の求め方
は、他にも各種あるが、このOpenAIのサービスの場合も、この1536個の数値のどの
〔特別寄稿〕和歌集の歌風の言語的差異の記述107
数値がどういう意味を反映しているかはまったくわからない。
しかし、全体として、単
語や文の類似性をこの数値で判定することが可能である。
これに近いことは、従来word2vecやFastTextなどの単語埋め込み表現を計算するツー
ルでも行うことができた。
これらは、文章を入力することでその中にある単語の共起情
報から、埋め込み表現を獲得する。
また文の生成や分類を行う言語モデルのBERTで
も文の埋め込み表現を計算することが可能である(浅原正幸・加藤祥(2020)など参照)。
ただ、word2vecやFastTextは、あくまでも単語の周辺の単語の共起情報を得るだけで、
文レベルの統語関係などは考慮されない。
また、同音異義語もきちんと区別できない。
BERTでは、よりきめ細かな埋め込み表現を得ることができるが、その言語モデルの大
きさは、3億パラメタ程度であり、GPT-3の数百億パラメタ以上のデータ量とは比較に
ならない。
また、GPT-3は、最初から多言語で学習しており、その出力するベクトル
も多言語に対応している。
したがって、出力をそのまま他の言語と対照して研究できる
のが大きなメリットである。
つまり、いわば、ChatGPTによる非常に高性能な多言語
分析の途中経過を利用して、いろいろな計量分析を行うことができるわけである。
3埋め込み表現による類似検索
以上のように、単語や文をベクトルにして、そのベクトルを相互比較することができ
るわけであるが、その一例として、埋め込み表現による類似検索の例を見てみよう。
ま
ずたとえば、『古今集』のデータを用意する。
埋め込みベクトル生成は、トークンへの
分解も行うため、事前の形態素解析は不要で、そのまま漢字仮字まじり文を用意する。
次にそれを1首ずつ、OpenAIの埋め込みベクトルのtext-embedding-ada-002のAPI (ク
ラウドの機能を利用するシステム)に投入して、埋め込み表現のベクトルの数値に変換す
る。それぞれ1536次元の埋め込みベクトルとなる注‘。
この高次元のベクトルデータは、同じAPIで採取したあらゆる和歌や、他の古典の
文や、現代語の文についてすら、類似性の判別に使える。
次は、「袖ひちてむすびし水
のこほれるを春立つけふの風やとくらむ」を対象の和歌として、その埋め込みベクトル
を求め、『古今集』すべての和歌の埋め込みベクトルと比較して、類似度の高いものか
ら5個を取り出したものである。
類似度は、一般的に数学でベクトルの類似度を測るの
に用いられるコサイン類似度(距離)を用いている注、カッコ内はコサイン類似度であ
る〇
対象文:袖ひちてむすびし水のこほれるを春立つけふの風やとくらむ
順位:本文(コサイン類似度)
1:袖ひちてむすびし水のこほれるを春立つけふの風やとくらむ(0.9999983246522605)
2 :波の花沖から咲きて散りくめり水の春とは風やなるらむ(0.9280744287636585)
3 :春ごとにながるる川を花と見て折られぬ水に袖やぬれなむ(0.9247892761175831)
108
4 :かげろふのそれかあらぬか春雨のふるひとなれば袖ぞ濡れぬる(0.9213311534905383)
5 :春のきる霞の衣ぬきをうすみ山風にこそ乱るべらなれ(0.9184461509961638)
当然のことながら、元の歌が1位で、コサイン類似度はほぼ1となる(1で完全一致。完
全に1にならないのは、様々な計算誤差による)。
したがって、実用的には2位からが類似
歌となる。
すぐわかるように、2位の「波の花沖から咲きて散りくめり水の春とは風や
なるらむ」などをはじめ、非常に意味的に類似度の高い歌が選ばれていることがわかる。
これは別に『古今集』内部に限らない。たとえば、現代日本語(例、「桜の花の散るのを
惜しむ気持ちを表現する」)や英語(例、A song that expresses the feeling of regretting separa-
tion from a friend.)で文を作って、それをベクトル化して比較することも可能である。
また、今回の研究で行うような、日本語と中国語の比較文学的な考察では、漢文も扱え
ることは大きなメリットである。
次は、『和漢朗詠集』の立春の「池凍東頭風度解窓梅北面雪封寒」(藤原篤茂)を同じ
ように用いて、『古今集』力、ら類似歌を抽出したものである。
対象文:池凍東頭風度解窓梅北面雪封寒
順位:本文(コサイン類似度)
1:梅の花それとも見えず久方の天霧る雪のなべて降れれば(0.83671372975217)
2 :逢坂の嵐の風は寒けれどゆくへ知らねばわびつつぞ寝る(0.8344075388592953)
3 :梅の香の降りおける雪にまがひせば誰かことごとわきて折らまし(0.8313966248472829)
4 :浦ちかく降りくる雪は白波の末の松山越すかとぞ見る(0.8297397632079765)
5 :細枝結ふ葛城山に降る雪の間なく時なく思ほゆるかな(0.8293573454140316)
1位の歌等たしかに、かなり近い意味を持っているものと認められる。
これが、
ChatGPTなどが多言語で応答することができる能力の源泉の一部である。
以上のよう
に、文の埋め込みベクトルにはさまざまな意味の文脈情報が盛り込まれており、それは、他の言語とも比較可能な、ユニバーサルな性質を持っている。
したがって、このベクト
ルを詳細に調査することで、言語の持つ意味のある部分を解析することが可能になるは
ずである。
そこで、本稿では、この能力を用いて、古典語の和歌のもつ意味の分布を調
査することを試みた。
4『古今集』の意味構造
word2vecなどの単語埋め込みベクトルを用いて、ある文章の中の構造を明らかにす
る研究は、世界的に広く行われている。
本稿の筆者も、『源氏物語』中のシク活用形容
詞の埋め込みベクトルをword2vecで求め、それを主成分分析の2次元平面において、
ジェンダー性との関係について調査したことがある(近藤泰弘(2022))。
また、先にも
触れた、BERTのセンテンスベクトルを用いた浅原•加藤(2022)の研究も、類義語の
分別や、『源氏物語』の表現分析にそれを利用している。今回は、同様な手法を用いて、〔特別寄稿〕和歌集の歌風の言語的差異の記述109
単語ベクトルではなく、この文埋め込みベクトルを、和歌の1首ずつに適用し、その各
首のベクトルを主成分分析で2次元に圧縮することで、多様な意味のうちもっとも主要
な意味を導きだすことを試みてみたい。
複数の特徴量を持つ統計値をいくつかの主成分
に落とし込んで、分析することも古くから広く行われてきている注、
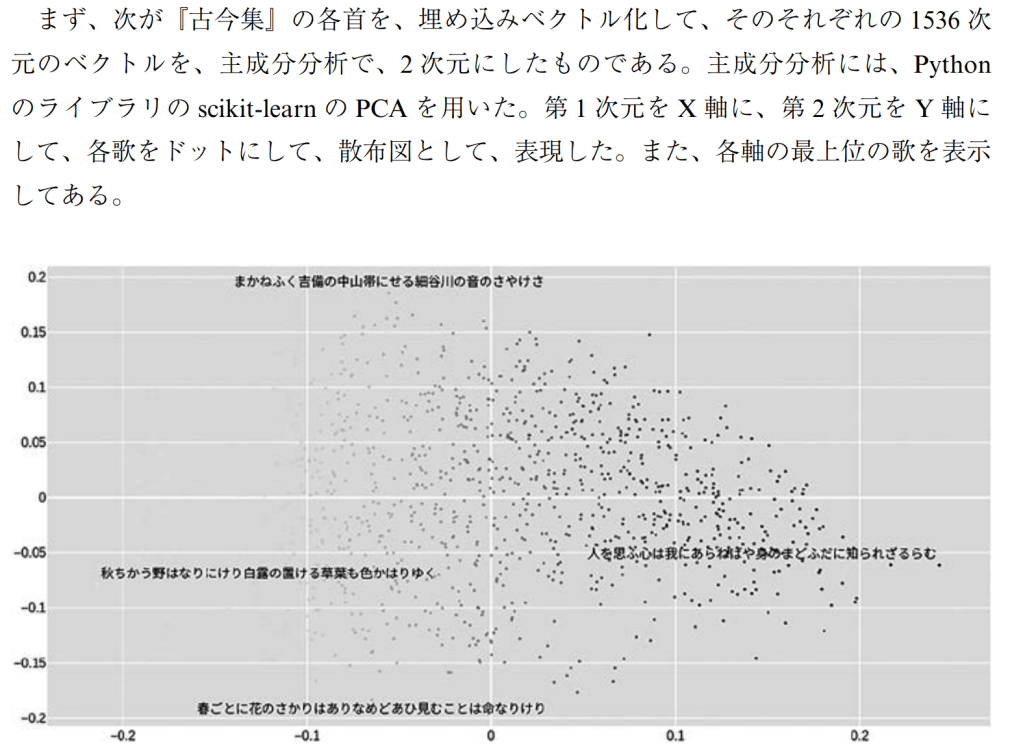
まず、次が『古今集』の各首を、埋め込みベクトル化して、そのそれぞれの1536次
元のベクトルを、主成分分析で、2次元にしたものである。
主成分分析には、Python
のライブラリのscikit-learnのPCAを用いた。
第1次元をX軸に、第2次元をY軸に
して、各歌をドットにして、散布図として、表現した。
また、各軸の最上位の歌を表示
してある。
2 まかねふく剖8の中山帯にせあ!B谷川の音のさやけさ E ■-
- . * ‘ • * . 1 e f : •
1 …• – V . .■. . •へ♦ .•.•一 ・)— . ••• * • <.「•,••••、••足・.••ヽ••
•.、 • •ゝ••• ‘ • • •…….-:: ° ■/.’.»»:» :- .• ‘ . ‘ .•••,..•.•・了’・、•;ら r • – :
5 • .••••ヽー :. . 、. • •• •. :. .•:• •’: .•’け知
秋ちかう好はなりにけり白・の宣ける草Atも色かはりゆん’ * 1 ” .. ••••• • • ,
• • ♦ . • • t ・ » • • •
2 春ごとに花のさかりはありなめどあひ見むことは命なりけり
-«.2 -0.1 0 0.1 0J
この主成分分析の各次元についての統計値は次の通りである。
固有値:[0.00796909 0.00525807]
寄与率:[0.05528386 0.03647674]
累積寄与率:[0.05528386 0.09176059]
やはり、全体が1500次元以上もあるために寄与率は低めだが、それでも2次元目まで
で1割弱あるのは、ある程度評価できるのではないだろうか。
このように値が低いこと
を一応考慮に入れて、以下、具体的なテキストを定性的に観察していきたい。
先の図には、X軸、Y軸の最大値(正)、最小値(負)の歌だけを記載したが、下に、
それぞれの軸の最大値、最小値の3位までのランキングを示した表をあげる。
X-axis Max (Rank1):人を思ふ心は我にあらねばや身のまどふだに知られざるらむ
X-axis Max (Rank 2):思ひけむ人をぞともに思はましまさしやむくいなかりけりやは
X-axis Max (Rank 3):身を捨ててゆきやしにけむ思ふよりほかなるものは心なりけり
no
X-axis Min (Rank1):秋ちかう野はなりにけり白露の置ける草葉も色かはりゆく
X-axis Min (Rank 2):秋の月山辺さやかに照らせるは落つる紅葉のかずを見よとか
X-axis Min (Rank 3):秋風の吹きと吹きぬる武蔵野はなべて草葉の色かはりけり
Y-axis Max (Rank1):まかねふく吉備の中山帯にせる細谷川の音のさやけさ
Y-axis Max (Rank 2):郭公声もきこえず山彦は外に鳴く音をこたへやはせぬ
Y-axis Max (Rank 3):しほの山さしでの磯にすむ千鳥君が御代をば八千代とぞ鳴く
Y-axis Min (Rank1):春ごとに花のさかりはありなめどあひ見むことは命なりけり
Y-axis Min (Rank 2):色見えで移ろふものは世の中の人の心の花にぞありける
Y-axis Min (Rank 3):花見れば心さへにぞ移りける色にはいでじ人もこそ知れ
主成分分析の性質から、それぞれの各軸の意味の評価はこれらの歌の意味の解釈にょ
るが、おおよそ次のようなものと推定できる。
第1次元のX軸では、大のランクの歌
は愛や情熱、恋心、自己の感情などの人間の内面を強く表現したものとなっている。
これに対して、小のランクの歌は自然や季節、特に春に関連した風景や景色を中心に述べている。
これらから、
•X軸の大の方向•••「人間の内面や情感、恋愛に関する表現」
• X軸の小の方向• • •「自然や季節の変わり目を中心とした風景や情景の表現」
といった意味が強いと推定できる。
第2次元の、Y軸に関しては、
大のランクの歌は、
鳥やその鳴き声、音などを中心にした歌となっており、特に、山や川、風景の中での鳥
の声や音の存在感が強調されている。
一方、小のランクの歌は花やそれに関連する情感、
特に花の移ろいやすさや美しさ、それに対する人々の感情の移ろいや変わりやすさを表
現している。
まとめると、
• Y軸の大の方向•••「鳥やその鳴き声、音を中心とした風景や情景の表現」
• Y軸の小の方向•••「花やそれに関連する感情や美しさ、変わりやすさを中心と
した表現」
といった意味が強いと推定できる。
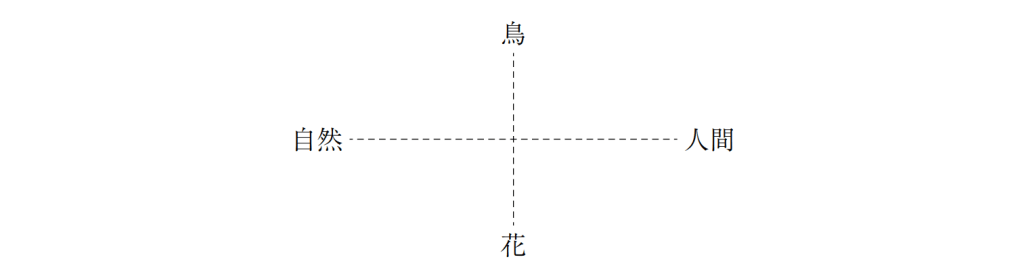
さらに簡単にXY軸を記述するならば、
鳥
自然——j——人間
花
このように概括できると思われる。
つまり、大規模言語モデルの解釈する各歌のもつ意
〔特別寄稿〕和歌集の歌風の言語的差異の記述 111
味の多様な埋め込みベクトルを縮約すると、『古今集』の歌の意味でもっとも基礎的な
ものは「人間ー自然」の軸であり、次に「鳥一花」の軸が来るとするわけである。
『古
今集』の基礎的意味構造が「人間(人事)ー自然(景物)」および「鳥一花」であること
を、大規模言語モデルの埋め込みベクトルの主成分分析という非常に機械的なものから
導き出すことができるのは興味深く、この方法の妥当性を示していることがわかる。
5『万葉集』の意味構造
では、上とまったく同じ手法で、『万葉集』の各首の埋め込みベクトルを主成分分析
で解析してみると以下のようになる。
ここでは、散布図は、省略する。
『古今集』と同
じように、大、小のそれぞれ3位までのランキングを示しておく。
X-axis Max (Rank1):我妹子に恋ふるに我はたまきはる短き命も惜しけくもなし
X-axis Max (Rank 2):我妹子を相知らしめし人をこそ恋の増されば,恨めしみ思へ
X-axis Max (Rank 3):我妹子に恋ひすべながり夢に見むと我は思へど寝ねらえなくに
X-axis Min (Rank1):磯の崎漕ぎ廻み行けば近江の海八十の湊に鶴さはに鳴く
X-axis Min (Rank 2):舟競ふ堀江の川の水際に来居つつ鳴くは都鳥かも
X-axis Min (Rank3):滝の上の三船の山ゆ秋津辺に来鳴き渡るは誰呼子鳥
Y-axis Max (Rank1):秋山の木の葉もいまだもみたねば今朝吹く風は霜も置きぬべく
Y-axis Max (Rank 2):冬ごもり春さり来れば鳴かざりし鳥も来鳴きぬ咲かざりし花も
咲けれど山をしみ入りても取らず草深み取りても見ず秋山の木の葉を見ては黄葉をば取
りてそしのふ青きをば置きてそ嘆くそこし恨めし秋山そ我は
Y-axis Max (Rank3):雪寒み咲きには咲かず梅の花よしこのころはかくてもあるがね
Y-axis Min (Rank1):磯ごとに海人の釣舟泊てにけり我が船泊てむ磯の知らなく
Y-axis Min (Rank2):奈呉の海人の釣する舟は今こそば舟棚打ちてあへて漕ぎ出め
Y-axis Min (Rank 3):大崎の神の小浜は小さけど百船人も過ぐといはなくに
これを解釈すると、x軸に関しては、大のランクの歌は「我妹子」や「恋」に関連する
表現が多く、強い恋心や愛情、悲しみや切なさなどの個人的な感情を強く表現している。
一方、小のランクの歌は海や舟、鳥などの自然や風景、旅に関連するものが中心となっ
ている。
このことから、
•X軸の大の方向•••「恋愛や情熱的な人間の感情や関係に関する表現」
- X軸の小の方向•••「自然や旅、風景を中心とした表現」
112
といった意味が強いと推定でき、このX軸の点では、『古今集』と似た意味構造を持つ
ていることがわかる。
次に、Y軸に関しては、
大のランクは、主に、野や山における自
然の変化を中心にした表現が強調されており、風景やその移り変わりがテーマとなって
いる。
一方、小のランクの歌は船や海、旅に関する表現が多く、特に海上の生活や海人
の日常、海辺の風景などが取り上げられている。
このことから、
•Y軸の大の方向•••「山における季節の移り変わりを中心とした表現」
- Y軸の小の方向•••「海や船、海人の生活を中心とした表現」
といった意味が強いと推定できる。
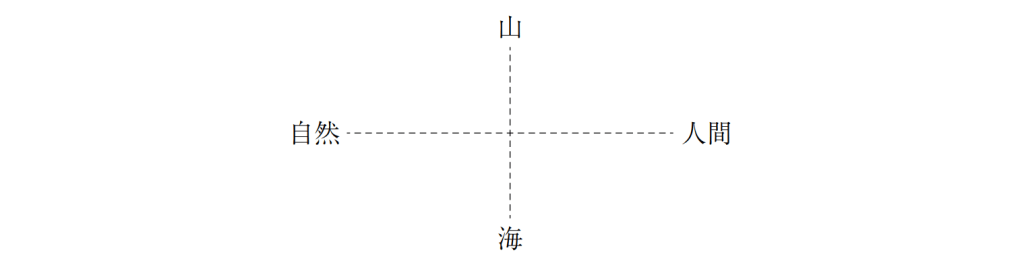
XY軸を簡単にまとめると
山
自然——1——人間
海
のようになり、
Y軸において、『古今集』の「鳥一花」の対立が、『万葉集』においては
「山一海」の対立となっており、意味構造の中心的部分に大きな差異があることがわか
る。
このような差は、それぞれの時代の歌に要求される文化的な部分から生まれている
ものと思われる。
すでに知られているように『万葉集』では、自然を中心に歌われた歌
がその多くを占めている。
その自然のあり方も、平安時代とは異なっており、素材とし
ての「花鳥風月」ではなく、その中で生活する場としての「山」「海」が存在している。
このような意味構造を、埋め込みベクトル分析が捉えていると考えられる。
6『和漢朗詠集』の分析
この『万葉集』と『古今集』の意味構造の差異は明確だが、この変化をもたらした文
化的要因をさらに考えてみると、その間に、漢詩の影響が考えられることは当然予想で
きる。
平安時代に愛好された漢詩の意味構造を反映すると思われる『和漢朗詠集』の漢
詩部分を使っておなじような分析をしてみると、次のようになる。
『和漢朗詠集』は、
白楽天の作品を多く掲載し、部立も、『白居易集』の影響を受けている(菅野禮行(1999))〇
『白居易集』の部立は、『古今集』にも影響を与えているとされる。
その点でも、時代的
には後のものになるものの、『古今集』と比較することには意味がある。
『和漢朗詠集』
の場合は、一句が長いものもあるので、適宜分割して、ベクトル化した。
散布図は省略
して、XY軸のランキングだけを掲載する。
x軸の、大のランキングでは、主に君主や帝王に関する賞賛や称賛の言葉、帝国の政
治や仕組み、権力の構造やその継承に関する内容が中心になっている。
X軸の小のラン
キングでは、秋や風、風景を中心とした表現が目立つ。
そこでは、自然の美しさや哀愁、
〔特別寄稿〕和歌集の歌風の言語的差異の記述113
自然現象の移り変わりに対する感嘆が伝わってくる。
Y軸の大のランクでは、視覚的な
美しさ、小では、動物や鳥や人の声や、景色の静寂など聴覚的なものが感じられる。
Y
軸の小のランキングは特に注目されるので10位までから選んで掲載した。
最後に、XY
軸の簡略な記述も掲載した。
X-axis Max (Rank 1):坐制諸侯。
X-axis Max (Rank 2):忠仁公者皇帝之祖皇后之父也。
X-axis Min (Rank1):葉落風吹色相秋。
X-axis Min (Rank 2):松高風有一声秋。
Y-axis Max (Rank1):野草芳韮紅錦地0
Y-axis Max (Rank 2):澄澄粉餅。
Y-axis Min
Y-axis Min
Y-axis Min
Y-axis Min
Y-axis Min
(Rank 1)
(Rank 2)
(Rank 7)
(Rank 8)
(Rank 9)
:故山無主晚雲孤。
:夜雲収尽月行遅。
:晩鶯声声予参講誦之座。
:五夜之哀猿叫月。
:夜深四面楚歌声。
(Rank10):莫以偃息於五台之雲。
Y-axis Min
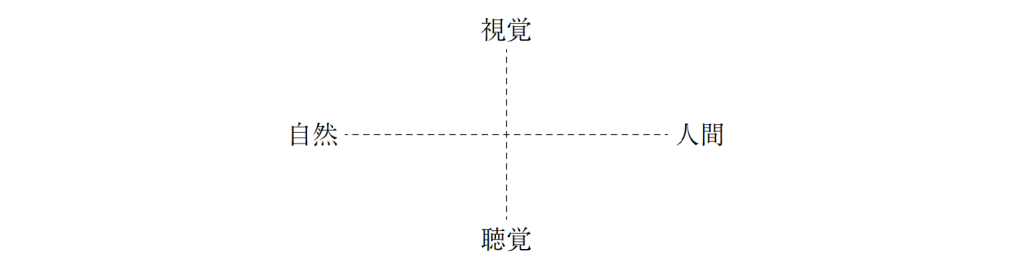
視覚
自然ー
ー人間
聴覚
ここから、非常に興味深い観点が導きだせる。
X軸の「人間ー自然」は、『万葉』とも『古
今』ともほぼ共通する。
それに対して、Y軸では、
万葉集
和漢朗詠集
古今集
山
聴覚
鳥
海
視覚(見やすくするため、Y軸の上下を入れかえた)
花
のように、『万葉集』的な、「自然(山と海)」の歌の構造が、漢詩では、「聴覚ー視覚」という対立になっている。
和歌における「鳥と花」という日本的な景物の対立は、その
114
背後に「聴覚ー視覚」という漢詩の世界の秩序を持つと考えると説明が可能である。
漢
詩では「猿の声」などが代表的だったものが、「鳥の声」を代表とするように置き換え
られ、「草•水•花」などの多くの視覚的なものが「花」として抽象化されたと考えると、
『古今集』的な意味構造が、漢詩の世界の大きな影響によって形成されたと考えること
が可能になる。
漢詩と和歌との文化史的な経緯については、川口久雄(1959)が「句題
の題詠といい、和歌の書式といい、遊覧曲宴の行事様式といい、何れも寛平期までは漢
詩によってなされたものの一種のトランスクリプションと考えていい形式で行われてい
る。
貫之はこのようにして九世紀を通じて権威的であった唐風の文化様式の革義に新興
の和歌という国語意識の抒情詩をもろうとしたのである。」と述べているが、
これを言
語的な和歌の意味構造から裏付けることができると考えられる。
また、実際に使われた
『古今集』の漢詩文素材の対照も、渡辺秀夫(1991)に詳細なものがあり、貫之が受容
していた漢詩文からの強い影響を見ることができる。
このことを、言語内部の分析から
実証できるものと考える。
7『後撰集』の分析
『古今集』の次の勅撰集である『後撰集』についても同様に埋め込みベクトルで調査
してみると、ランキングの用例は省略するが、xの最大が「梓弓入さの山は秋ぎりのあ
たるごとにや色まさるらむ」最小が「人のよの思ひにかなふ物ならばわが身は君にをく
れましやは」、Yの最大が「足曳の山下水は行かよひことのねにさへながるべらなり」
最小が「女郎花はなの心のあだなれば秋にのみこそあひわたりけれ」である。
つまり、
X軸が、「自然一人間」になっているのは『古今集』と同様である注七Y軸が、大が「山」
であることは『万葉集』と同じだが、小が「花」にほぼ限られるのは、『古今集』と同
じである。
つまり、Y軸は、「山一花」のようであり、『万葉集』と『古今集』のまさに
折衷的な意味構造となっている。
山
人間——-1——自然
花
このことは、『後撰集』の撰歌の過程からある程度解釈可能かもしれない。
『後撰集』
の実質的な撰者は、源順、大中臣能宣など、いわゆる梨壺の五人と言われる人々である。
よく知られているように、この五人は、宮中の昭陽舎(梨壺)の撰和歌所において、『後
撰集』の撰歌と『万葉集』の訓膏古を並行して行ったとされる(片桐洋一(1990)など)。
『後撰集』の意味構造に、『万葉集』と近いものがあることには、その影響が考えられる。『後
〔特別寄稿〕和歌集の歌風の言語的差異の記述115
撰集』の意味構造についてのこのような指摘は従来の和歌史研究にはなかったものと思
うが、大規模言語モデルの分析で初めて見えてきたものである。
8『文華秀麗集』の分析
以上分析してきたように、『万葉集』から『後撰集』にいたるまで、X軸が「人間一
自然」の対立、Y軸が、各種の自然の対象の差異に関わるものであることは、共通して
いた。
では、『万葉集』から『古今集』の間に位置する、国風暗黒時代の漢詩集におい
ては、どのようになっているだろうカ、。
また、試行段階であるが、当時の代表的な漢詩
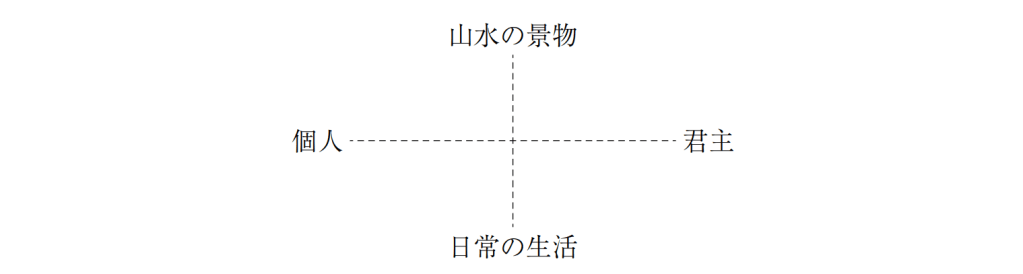
集である『文華秀麗集』についての分析を一部行ってみた。
途中結果は省略するが、
XYの2軸を簡略に記述すると、次のようになる。
山水の景物
個人——:——君主
日常の生活
このように、漢詩であっても、『和漢朗詠集』などに反映する『白居易集』とはかなり
性格が異なっている。
『古今集』に影響を与えた漢詩という点では、後世、『和漢朗詠集』
にまとめられたような漢詩の世界の方が近いことは明らかである。
これについては、『凌
雲集』『経国集』などの他の勅撰漢詩集をさらに分析して、どのような漢詩の意味構造
が、平安時代和歌に影響を与えたかをさらに調査してみたい。
小町谷照彦(1996)の述べるように、「『古今集』を文学史的に定立するものとして、
二つの流れがある。
一つは『万葉集』との連接であり、一つは漢詩文の摂取である」と
いうことは間違いない。
その「漢詩文の摂取」が具体的にどのようなタイプの漢詩文の
意味構造から取られていったかをさらに研究することが必要である。
9大規模言語モデルによる分析の課題
以上見てきたように、大規模言語モデルの内部データを取り出すことに相当する、埋
め込みベクトルによる分析によって、従来知られていなかった各種の知見を得ることが
可能である。
今回は2次元に縮約したデータを対象に研究を行ったが、もともと1500
次元以上のベクトルであるので、2次元だけに限定できるものではなく、3次元の場合
の寄与率を見ていくと注ゝ3次元あるいは、4次元でも十分な情報量を取得することが
できる。
例えば、『古今集』における3次元目(Z軸)の上位•下位を見てみると、
Z-axis Max (Rank1):憂きことを思ひつらねてかりがねの鳴きこそ渡れ秋の夜な夜な
116
Z-axis Max (Rank 2):きりぎりすいたくな鳴きそ秋の夜の長き思ひは我ぞまされる
Z-axis Max (Rank 3):秋は来ぬ今やまがきのきりぎりす夜な夜な鳴かむ風の寒さに
Z-axis Min (Rank1):ひともとと思ひし菊を大沢の池の底にも誰か植ゑけむ
Z-axis Min (Rank2):もみぢ葉の流れてとまる水門には紅深き波や立つらむ
Z-axis Min (Rank 3):ちはやぶる神世もきかず龍田河韓紅に水くくるとは
このようになり、大のランキングでは、「憂き」「長き思ひ」「寒さ」といったネガティ
ブな感情を用いて秋を中心に歌ったものが来るのに対し、小のランキングでは、自然の
美しさに感動したポジティブな表現が中心となっている。
つまり、Z軸(3次元目)では、
自然に対する感情の「ネガティブーポジティブ」という対立的な捉え方が分離されるの
である。
このように、次元を増やしても、十分に意味構造の分離が可能であり、作品の
持っている構造性をさらに深く解析できるのである。
また、今回は示さなかったが、主
成分分析以外の次元圧縮の手法(t-SNE等)や、因子分析の手法等で、埋め込みベクト
ルを分析することも可能である。
さらには、今回のような〇 penAIのクラウドAPIサービスを用いずに、ローカルな
pcで動作できるもう少し小型の多言語対応大規模言語モデルを用いて、それに、言語
資料を直接学習させるような方法も考えられる。
今後、AIの持つ能力がますます上がっ
てくると、本稿で示したように、AIの能力を援用して研究することが非常に容易になっ
てくるはずであり、様々な手法を試してみたいと考えている。
また、対象の和歌集についても、『万葉集』のように成立過程が複雑なものについて
は、成立時期に分けて分析することも重要になってくる。
『新撰万葉集』のように、関
係する重要な資料であるのに、今回は扱えなかったものもある。これらすべてを今後の
研究課題としたい。
注1 各ベクトルの数値は、最大値:0.34から、最小値:-0.64、平均0程度に分布している。
注2コサイン類似度は、コサイン距離とも言われ、ベクトルの類似度を測るもっとも一般的
な数学的手法である。ベクトルの類似度は、その相互の作る角度によるのが一般的である
が、その角度のコサインを得ることで、類似度を0から1までの数値で表現できる。何次
元のベクトルであっても同様に計算できる。
注3水谷静夫(1982)では、数量化理論!E類を用いて、一首中の、複数の単語の共起情報を2
次元にすることで、その散布図において「梅」か「桜」かを弁別する方法を示している。
共起情報による数量化の方法は、現在の大規模言語モデルの方法に類似している部分があ
る〇
注4ここでも、X軸の大小の方向は異なるが、これは特に意味はない。
注5 3次元の場合の各次元の数値は以下の通りである。
〔特別寄稿〕和歌集の歌風の言語的差異の記述117
固有値:[0.00796909 0.00525808 0.004523071
寄与率:[0.05528386 0.03647677 0.031377841
累積寄与率:[0.05528386 0.09176063 0.123138471
使用テキスト
『万葉集」(日本語歴史コーパス•底本(小学館新編日本古典文学全集))
『古今集JI (日本語歴史コーパス•底本(小学館新編日本古典文学全集))
『後撰集JI (日本語歴史コーパス•底本(正保版本「二十一代集」))
『和漢朗詠集JI (Wikisourceテキストファイルを改編•底本不明•日本古典文学大系で校訂)
『文華秀麗集JI (浦本裕氏webサイト資料を改編•底本(岩波書店日本古典文学大系))
引用参考文献•Webサイト一覧
浅原正幸•加藤祥(2020)rr日本語歴史コーパス」の文脈化埋め込みに基づく意味空間」「人文
科学とコンピュータシンポジウム」発表要旨、2020年12月
岡野原大輔(2023)『大規模言語モデルは新たな知能か——ChatGPTが変えた世界一J岩波書店
水谷静夫(1982)『数理言語学」現代数学レクチャーシリーズD-3 •培風館
片桐洋一(1990)『新日本古典文学大系後撰集」岩波書店、解説
川口久雄(1959)『三訂平安朝日本漢文学史の研究 中」明治書院、366-367頁
小町谷照彦(1996)「古今和歌集の成立」『岩波講座日本文学史• 2巻•九•ー〇世紀の文学」
岩波書店
近藤泰弘(2022)「平安時代語に見られるジェンダー的性質について——通時コーパスによる分
析——」日本語学会2020年度春季大会シンポジウム
菅野禮行(1999)『新編日本古典文学全集 和漢朗詠集」小学館、「和漢朗詠集をどう読むか」
渡辺秀夫(1991)『平安朝文学と漢文世界」勉誠社「6章 古今集歌に見る漢詩文的表現」
OpenAI (2023) Embeddings URL:https://platform.openai.com/docs/guides/embeddings/what-are-
embeddings
謝辞:本研究で用いたコーパスは、国立国語研究所「日本語歴史コーパス」である。バージョ
ンは、以下の通り。関係者の皆様に感謝申し上げます。
国立国語研究所(2023)『日本語歴史コーパス」(バージョン2023.3.中納言バージョン2.7.2)
https://clrd.ninjal.ac.jp/chj/ (2023 年 9 月1日確認)
また、本研究は、国立国語研究所通時コーパスプロジェクトの研究成果の一部である。
——青山学院大学名誉教授——
(2023年10月10日 受理)
118
Studies in the Japanese Language Vol.19, No. 3 (2023)
Describing Linguistic Variations in Waka Collections:
An Analysis Using Large Language Models
Kondo Yasuhiro
Keywords: Waka, Large Language Models, Embedding Vectors, Poetic Style,
Principal Component Analysis
Traditionally, the investigation of the “poetic style” inherent in a collection of
Waka was centered around the study of vocabulary distribution and bias.
However, with the recent advancements in machine learning, research utilizing
word embedding vectors such as word2vec has become feasible. In this study,
we demonstrated that by applying principal component analysis to sentence
embedding vectors generated by large language models, we can describe the se-
mantic system at the core of Waka’s poetic style. Moreover, we observed sub-
stantial differences between the “Kokin Wakashu” and “Man?y6shu” and dis-
cussed the potential influence of Chinese poetry on these variations.