【インテル・トリニティの生涯】ロバート・ノイス:ノーベル賞を「2度も」獲り損なった男
https://pc.watch.impress.co.jp/docs/column/semicon/1496846.html






『インテルの創業と発展に寄与した三位一体(トリニティ)
「インテル・トリニティ(Intel Trinity)」とは、インテル(Intel)の共同創業者であるロバート・ノイス(Robert Noyce)氏とゴードン・ムーア(Gordon Moore)氏、それからインテルの社員第1号であるアンドリュー・グローブ(Andrew Grove)氏をまとめた呼称だ。インテルの創業と成長を一体となって支えた3名(三位一体)を意味する。
この呼称は、シリコンバレーで長年にわたって新聞記者をつとめたマイケル・マローン(Michael Malone)氏の著作「The Intel Trinity: How Robert Noyce, Gordon Moore, and Andy Grove Built the World’s Most Important Company」(Harper Business、2014年7月発行)により、米国では広く知られるようになった。邦訳書籍は「インテル 世界で最も重要な会社の産業史」(文藝春秋、2015年発行)である。邦訳タイトルには「インテル・トリニティ」が入っていない。このためか、日本における「インテル・トリニティ」の知名度はあまり高くない。
本コラムの【インテル・トリニティの生涯】では、トリニティで最後の1人となったゴードン・ムーア氏が2023年3月24日に逝去した機会を捉え、トリニティの生涯を紹介する。本来であれば誕生年月順から言ってロバート・ノイス氏を始めに紹介すべきなのだが、逝去したばかりで読者の記憶に新しいであろうムーア氏を先に紹介した。
関連記事
【福田昭のセミコン業界最前線】【インテル・トリニティの生涯】ゴードン・ムーア:インテルを最も長く愛し続けた男
「インテル・トリニティ」を構成するノイス氏、ムーア氏、グローブ氏の生涯(概略、文中敬称略)。公表資料から筆者がまとめたもの
日本語版がないノイス氏の伝記
今回はムーア氏とともにインテルを創業したロバート・ノイス氏の経歴を述べる。ノイス氏の伝記として最も優れているとされるのは、シリコンバレーを専門とする歴史学者のレスリー・バーリン(Leslie Berlin)氏が著した「The Man Behind the Microchip: Robert Noyce and the Invention of Silicon Valley」(Oxford University Press、2005年6月10日初版発行)だろう。440ページというかなりの大著である。
インテルのWebサイトでノイス氏を記念するページを閲覧すると、ノイス氏のバイオグラフィ(伝記)として同書へのリンク(厳密にはバーリン氏のWebサイトへのリンク)が張られている。インテルが公式に認めた伝記本ともいえる存在だ。なお、筆者が調べた限りでは、邦訳本(日本語版書籍)は出版されていない。
ロバート・ノイス氏の伝記へのリンク部分。インテルのWebサイトに置かれたノイス氏を記念するページから抜粋
包括的なキルビーの発明、製造技術に特化したホーニーとノイスの発明
ロバート・ノイス氏(以降は一部を除いて敬称略)の経歴で日本でも知られているのは、フェアチャイルド半導体の共同創業者、インテルの共同創業者、日米半導体貿易摩擦における対日攻撃の急先鋒、モノリシック集積回路の発明者といったところだろうか。バーリン氏の著作「The Man Behind the Microchip: Robert Noyce and the Invention of Silicon Valley」を閲覧すると上記のほか、いくつかの興味深い事実が浮かび上がる。
最も興味深かったのは、ノイスがノーベル物理学賞を2回も獲り損なったというエピソードだ。2回の中で1回は、集積回路(IC)の発明である。このことは、半導体の研究開発コミュニティではよく知られている。
そもそも半導体コミュニティでは「集積回路の発明者」として、テキサス・インスツルメンツ(TI)のジャック・キルビー(Jack Kilby)氏、それからフェアチャイルド半導体のノイスとジーン・ホーニー(Jean Hoerni)氏の3名を挙げることが少なくない。
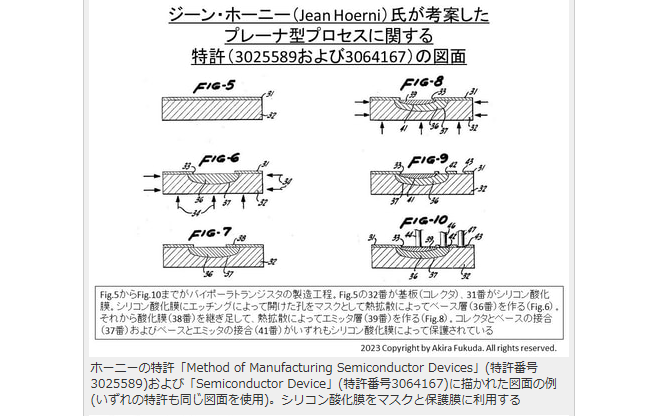
キルビーは1958年7月に、半導体基板にトランジスタやダイオード、抵抗素子などをまとめて搭載するという「集積回路の概念」を着想した。ホーニーは1957年12月にシリコン酸化膜でシリコンのトランジスタを保護するプレーナ型プロセスを考案した。ノイスはホーニーの発明を発展させ、シリコンのプレーナ型プロセスを回路素子間の相互接続(導体配線)に拡張した、モノリシック集積回路を1959年1月に発明した。キルビーの特許は1959年2月、ホーニーの特許は1959年5月(2件)、ノイスの特許は1959年7月に出願されている。
キルビーの特許「Miniaturized Electronic Circuits」(特許番号3138743)に描かれた実施例(マルチバイブレータ回路)の図面。図面で配線は空中の金(Au)線となっている(試作したICと類似している)が、考え方としては半導体基板と配線は一体化させる。図面の出所:1986年11月27日付け特許出願公告「特公昭61-55256」の第1図と第2図(いずれも米国特許と同じ図面)
ホーニーの特許「Method of Manufacturing Semiconductor Devices」(特許番号3025589)および「Semiconductor Device」(特許番号3064167)に描かれた図面の例(いずれの特許も同じ図面を使用)。シリコン酸化膜をマスクと保護膜に利用する
ノイスの特許「Semiconductor Device-and-Lead Structure」(特許番号2981877)に描かれた図面の例。上が平面図、下が断面図。左側のpn接合ダイオードと右側のnpnトランジスタを配線(30番および31番のリード(Lead)で結ぶ
キルビーの発明は最も包括的であり、「半導体集積回路の概念」に関するアイデアだった。請求範囲が広く、米国、日本、欧州を問わずに半導体メーカーにとってはかなり厄介な存在だった。このため手続きに時間がかかったとみられる。3名の中では特許の成立が最も遅く、1964年6月になっている(特許番号は3138743)。
逆にノイスの特許は最も早く、キルビーの3年ほど前、1961年4月に成立した(特許番号は2981877)。1959年当時はトランジスタ全盛時代であり、集積回路の製品がまだ登場していなかったことが、特許の成立を早めたとみられる。プレーナ型トランジスタとダイオードの製造に関わるホーニーの特許2件はノイスよりも1年ほど遅く、1962年3月(特許番号は3025589)と1962年11月(特許番号は3064167)に成立した。
ホーニーのプレーナ型プロセスとノイスのモノリシック集積回路プロセスはその後、シリコン集積回路とトランジスタ(バイポーラおよびMOS)、ダイオードの標準的な製造技術となった。特にMOS FETとその集積回路(MOS IC)は、ホーニーとノイスの発明によって実用化の道筋が開けたと言える。半導体産業の発展に与えた影響は、非常に大きい。
ノーベル賞の対象とは見なされなかった「集積回路」の発明
ただし半導体の研究開発コミュニティでは、集積回路の発明はノーベル賞の対象とはなりにくいとの見方が少なくなかった。集積回路の考案は学問的な業績ではなく、工業的な業績とみなされたからだ。固体物理学における偉大な発見であるトランジスタ(1956年にノーベル物理学賞を受賞)とは、発明の性格が大きく異なる。
たとえばゴードン・ムーアは1994年に、以下のように述べている。「トランジスタを発明したショックレー博士はノーベル賞を受賞したが、キルビー氏やノイス氏は受賞していない。ホーニー氏にいたってはきちんと評価されたとも言えない。その理由は2つあると思う。トランジスタは基礎的な物理研究と密接に関わっていた。ICはそれよりも技術問題だった。もう1つは少人数を特定して功績を断定することがより難しかった。キルビー氏、ノイス氏、ホーニー氏の3氏というのも1つの可能性なのだろうが、この点について明確な提案は残念ながらなかった」(玉置直司、「インテルとともに―ゴードン・ムーア 私の半導体人生―」、1995年6月発行、p.61)。
遅すぎた「集積回路」のノーベル賞授与決定
ところが2000年10月10日、スウェーデン王立科学アカデミーは同年のノーベル物理学賞を、キルビーを含めた3名の研究者に授与すると発表した。授与の理由は、現代情報技術(Modern Information Technology)の構築に寄与したこと。2名は化合物半導体のレーザーと高速トランジスタの基本構造「ヘテロ接合」の開発に対してノーベル賞を与えられ、この2名が賞金の半分を折半するとした。賞金の残り半分は「集積回路の発明に関するキルビー氏の寄与」に対してキルビーに授与された。
2000年10月10日にスウェーデン王立科学アカデミーが発表した、2000年のノーベル物理学賞の授与に関するリリース(Webサイトのページを一部抜粋したもの)
ノイスは、集積回路の発明に対してノーベル賞を授与されなかった。理由は2000年の時点で彼は鬼録に登っていたからだ。ノイスはこの10年前、すなわち1990年に亡くなっていた(ノーベル賞は生者のみに授与される)。ホーニーも1997年に亡くなっており、受賞資格を失っていた。なお同アカデミーが2000年のノーベル物理学賞の対象業績を解説したWebページは、ノイスの業績についてもふれている。
江崎玲於奈氏らよりも早期にトンネルダイオードを着想
ロバート・ノイスが逃したノーベル賞クラスの発明はもう1つある。それは「負性抵抗ダイオード(トンネルダイオード)」を理論的に着想したことだ。「負性抵抗」とは、電圧を上げると電流が減少する状態を意味する。1950年代は量子効果の1つである「トンネル効果」が半導体素子で生じると固体物理学の世界で予想されてはいたものの、実証には至らなかった時期である。pn接合ダイオードにおけるトンネル効果の発見は、半導体における量子効果の実証を意味した。
読者の多くがご存知のように、トンネルダイオードを発明したのはソニー(当時は東京通信工業)の江崎玲於奈氏らのグループである。以下の記述はソニーのWebサイトに掲載されたトンネルダイオード(別名:エサキダイオード)の発見にまつわるエピソードを参考にした。
1957年夏にソニーはゲルマニウム(Ge)の高周波トランジスタを開発する過程で生じたトラブル(ボンディングによるpn接合破壊)に対処するため、不純物濃度を変えたpn接合の特性を調べていた。このときに江崎らのチームは偶然、高濃度にリン(P)をドープしたpn接合の電流電圧特性が異常なふるまいを示すという現象に遭遇した。逆方向バイアスでは電圧の上昇とともに電流が単調に増加する。順方向では電圧の上昇とともに電流がゆるやかに増加し、ある電圧から電流が減少する。さらに電圧を上げると電流は再び増加していく。
トラブルはトランジスタのリン濃度を調節することで解決された。江崎は高濃度pn接合ダイオードで生じた負性抵抗をトンネル効果だと推測し、1957年10月に日本物理学会年会で発表した。残念ながら、反響はあまりなかったという。
江崎らの研究チームが1957年10月の日本物理学会年会で発表したpn接合ダイオードの負性抵抗に関する講演の予稿。出所:日本物理学会年会講演予稿集
ショックレーに潰されたノイスのトンネルダイオード
ソニーの江崎らがpn接合ダイオードのトンネル効果を発見していたのとほぼ同時期に、ノイスはpn接合ダイオードの不純物濃度を極端に高めるとトンネル効果が生じることを理論的に発見した。1956年8月14日のことであり、江崎らの発見よりも1年ほど早い。当時、ノイスはショックレー半導体研究所につとめていた。ノイスによる発見の経緯を、前述のレスリー・バーリンとデューク大学名誉教授のクレイグ・ケーシー(H. Craig Casey Jr.)は共同で、「IEEE Spectrum」誌の2005年5月号に寄稿した(「Robert Noyce and the Tunnel Diode」、May 2005、IEEE Spectrum、pp.49-53)。
ノイスは、通常の数千倍もの高い不純物濃度を有するpn接合ダイオードでは、順方向の電流電圧特性が以下のようになると予想した。
順方向の印加電圧をゼロから少しずつ上げていくとしよう。印加電圧がわずかなときには、通常のpn接合ダイオードよりもやや高い電流が流れて増加し始める。このとき伝導電子はpn接合間の極めて薄い空乏層を「トンネル効果」によって通り抜ける。
印加電圧をもう少し上げるとpn接合のエネルギー帯で空乏層が厚くなり、伝導電流(トンネル電流)が減少する。すなわち負性抵抗が生じる。印加電圧をさらに上げると空乏層の傾斜がゆるやかになり、通常のpn接合と同じように電流が増えていく。
ノイスが1956年8月14日にトンネルダイオードのアイデアを著した研究ノート。右上に日付がある。右下に電流電圧特性の予想曲線(順方向にトンネル電流と負性抵抗が生じる)が描かれている。出所:Computer History Museum, Department of Special Collections, Stanford University
このエキサイティングなアイデアをノイスはまず同僚のムーアに話し、次に上司のショックレー(William Bradford Shockley Jr.)に報告した。若きノイスは、ショックレーがこのアイデアに感激してくれるものと期待した。
ところがショックレーは、ノイスのアイデアに何の関心も示さず、このアイデアに基づく研究(ダイオードの試作や理論の検証など)への道を閉ざしてしまった。ショックレーは競争心が異常に強く、自分の部下が独自のアイデアで研究を進めることを許さない性格だった。失意に打ちのめされたノイスは、ショックレーの意図に沿った別テーマの研究に取り組んだ。
ショックレーが「エサキダイオード」を称賛した不可解
失意のノイスをさらに打ちのめす出来事が、1958年1月に起こる。著名な固体物理の論文誌「Physical Review」の1958年1月15日号に、「New Phenomenon in Germanium p-n Junctions」と題する江崎の論文が掲載された。試作したGeダイオードの順方向電流電圧特性で、トンネル効果による負性抵抗を観測したという報告だった。
ノイスはこのとき、ムーアらとともにショックレー半導体を退社してフェアチャイルド半導体を共同で創業しており、同社で忙しく働いていた。ノイスは江崎論文のコピーをムーアに見せ、ノイスと江崎のトンネルダイオードを比較した。両者の構造と特性は非常によく似ていた。大きく違うのは、ノイスはダイオードを試作しなかったことだ。江崎はダイオードを試作して室温(300K)と低温(200K)で電流電圧特性を測定した。低温ではトンネル効果がより顕著に現れた。
江崎は、続く1958年6月にベルギーのブリュッセルで開かれた国際固体物理学会(International Conference on Solid State Physics)で、高濃度に不純物をドープしたGeトンネルダイオードを発表することにした。ここで不可解なことが起こった。学会の冒頭に実施されたキーノートアドレスで、すでに固体物理学の権威となっていたショックレーが「東京から来た江崎がトンネルダイオードを発表する」と述べ、江崎の研究成果を高く評価したのだ。これには発表者の江崎本人が非常に驚いた。ショックレーが事前にアピールしたこともあり、江崎の発表には多くの聴衆が集まった。
ノイスのトンネルダイオード「ノイスダイオード」をショックレーはすでに知っていた。「エサキダイオード」がノイスダイオードと本質的に同じものであることも理解していたはずだ。ショックレーは「ノイスダイオード」を無視し、「エサキダイオード」を称賛したのはなぜなのだろうか。
先に紹介した「Robert Noyce and the Tunnel Diode」は、いくつかの可能性を挙げている。まず、ショックレーは意見や方針などを頻繁に変える傾向があったこと。ショックレーの部下の1人は、彼は会社をいつも「揺さぶっていた」とコメントした。別の部下は、ショックレーはトンネルダイオードに対する考えを変えたのではないかと述べた。また、1957年8月にショックレーを裏切った8名(ノイスを含めたフェアチャイルド半導体の共同創業者)に対する恨みが1958年6月の時点では癒えてなかったからだとする意見もある。いずれにせよ、今となっては本当の理由は分からない。
ベルギーでの発表から15年後の1973年10月23日、スウェーデン王立アカデミーは1973年のノーベル物理学賞を「固体中のトンネル効果の発見」に関する業績で江崎玲於奈を含む3名に授与すると発表した。
1973年10月23日にスウェーデン王立科学アカデミーが発表した、2000年のノーベル物理学賞の授与に関するリリース(Webサイトのページを一部抜粋したもの)
米国半導体産業の復活に力を尽くす途上で急逝
トンネルダイオードにノーベル物理学賞が授与されたとき、ノイスとムーアが共同で1968年7月に創業したインテルは、創立6年目に入っていた。インテルの1978年版年次報告書によると、1973年の売上高は6,620万ドル、従業員数は約2,500名(1973年末時点)、続く1974年の売上高は1億3,450万ドル、従業員数は約3,100名(1974年末時点)である。急激な成長ぶりがうかがえる。ノイスに過去を振り返っているヒマはなかっただろう。
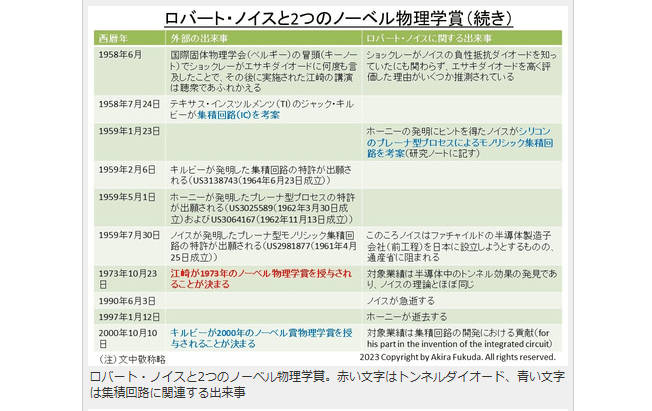
ロバート・ノイスと2つのノーベル物理学賞。赤い文字はトンネルダイオード、青い文字は集積回路に関連する出来事
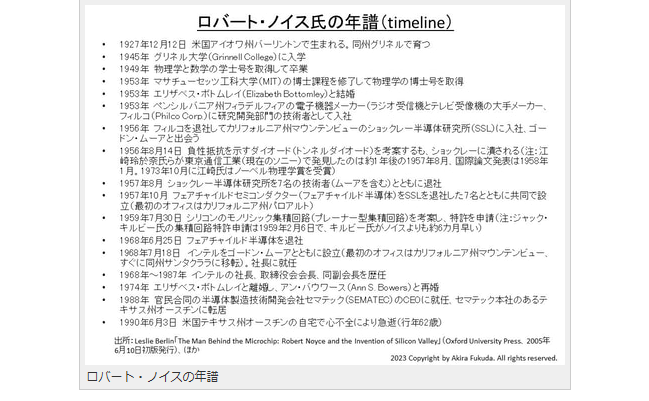
ロバート・ノイスの年譜
ノイスの活動は1970年代半ば以降、ベンチャー企業の育成や米国半導体産業の保護・強化へと軸足を移していく。1975年にインテルの社長を辞して取締役会会長となり、1979年には取締役会副会長へとステップダウンする。この間、日本半導体メーカーのキャッチアップと対米販売攻勢に注意を払うようになる。そして業界団体である「米国半導体工業会(SIA)」の設立(1977年に発足)を主導する。
1980年代には日米半導体貿易摩擦が起こり、米国半導体産業における製造技術の強化を真剣に考えるようになる。1988年には、半導体製造の要素技術開発を目的とする官民合同企業セマテック(SEMATECH)のCEOとなり、現役の経営者に復帰する。そして初めて、米国南部のテキサス州オースチンへと自宅を移す。セマテックの本社がオースチンにあったからだ。それまでノイスはシリコンバレーで暮らしていた。
ノイスはヘビースモーカーだったが、健康診断では何の異常もなかった。しごく健康であり、1990年6月3日には注文していた自家用飛行機を受け取る予定だった。しかし朝に自宅のプールで泳いだあと、体調不良を訴え、病院に搬送されるも不帰の人となってしまう。死因は心不全だった。半導体関係者はノイスの急逝に驚き、悲しみ、落胆した。
そして「インテル・トリニティ」のシリーズでは最後に、アンドリュー・グローブ氏の生涯について紹介する予定だ。ご期待されたし。 』