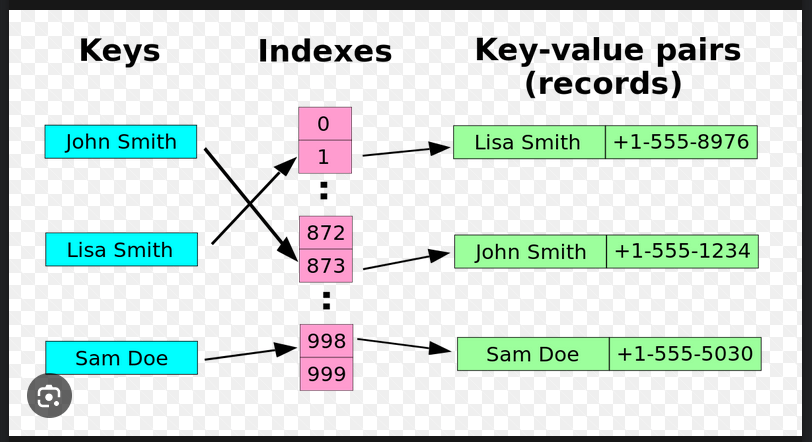
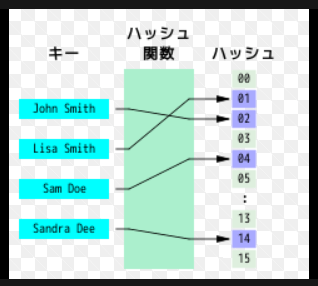
巨大なソートされていないファイルから重複したレコードを探す場合、各レコードをハッシュ関数に入力して配列 T のインデックスを得て、各バケット T[i] にハッシュ値が i になった全レコードの番号をリストの形で集める。この配列が完成すると、重複したレコードは必ず同じバケットに存在しているはずである。そこで、リストの要素数が2つ以上のバケット全てについて実際のレコードを求めて比較することで、重複レコードを探すことができる。配列が適切な大きさであれば、この方法が他のどんな方法(ファイルをソートし、隣り合うレコードを比較していく方法など)よりも高速な場合が多い。 類似レコードの探索
ハッシュ関数は、キーが似ているが全く同一ではない場合のレコード検索にも使える。この場合の入力は1つのキーか、似たようなキーを持つ巨大ファイル内の2つのレコードである。このためには、似たようなキーを与えられたとき、最大でも m しか違わないハッシュ値(m は小さい整数で例えば1か2)を生成するハッシュ関数を必要とする。このようなハッシュ関数を使って全レコードに関するハッシュテーブル T を構築すると、似たようなレコードは同じバケットか近いバケットに格納されることになる。すると各バケット T[i] について、-m から m の範囲の k で表されるバケット T[i+k] に格納されているレコード群を相互に比較すればよい。
他の手法に比べてハッシュ関数を用いた手法をより有利にするには、ハッシュ関数の計算コストが十分小さくなければならない。例えば、n個の要素のあるソート済みテーブルにある要素を挿入する場合、二分探索では log2 n 回のキーの比較を必要とする。したがって、ハッシュテーブルを使った手法が二分探索よりも効率的であるためには、ハッシュ関数が1つのキーからハッシュ値を計算するコストが log2 n 回のキー比較のコストよりも小さくなければならない。暗号学的ハッシュ関数は、そういう意味では時間がかかりすぎる[要出典]。 決定性
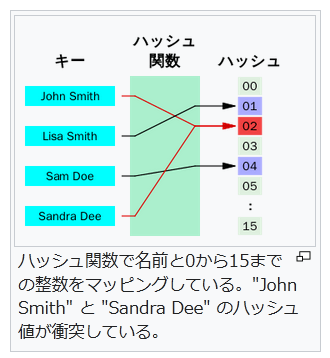
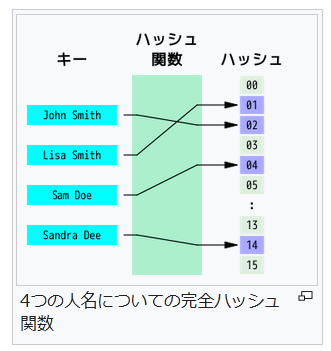
言い換えれば、典型的な m 個のレコードの集合を n 個のバケットにマッピングする場合、1つのバケットに対応するレコード数が m/n より大きくなる可能性をなるべく小さくすればよい。特に m が n より小さい場合、一部のバケットだけが1つまたはせいぜい2つのレコードを格納するようにすべきである。理想的な完全ハッシュ関数では、各バケットには最大でも1つのレコードしか格納されない。しかし、n が m よりずっと大きくても、衝突を完全に無くすことはできない(誕生日のパラドックスを参照)。
ハッシュ関数を評価する場合、ハッシュ値の分布の一様性はカイ二乗検定で評価できる[3]。 可変な値域
多くの用途では、プログラムを実行するたびにハッシュ値の範囲は変化するし、場合によっては1回の実行中にも範囲が変化することもある(ハッシュテーブルを拡張する必要が生じた場合など)。そのような場合、ハッシュ関数は2つのパラメータを入力する必要がある。1つは入力データ z で、もう1つは生成可能なハッシュ値の数 n である。
よくある方式は、非常に大きな値域(例えば 0 から 232−1)のハッシュ関数を用意し、その出力を n で割った余りを最終的な出力とする。n が2のべき乗なら、割り算ではなくビットマスクやビットシフトで代替できる。この方式を採用するなら、ハッシュ関数は n がいくつであっても、0 から n−1 の間でハッシュ値が一様に分布するようなものを選択する必要がある。関数によっては、奇数や素数など特定の n でないと余りが一様分布にならないこともある。 データ正規化
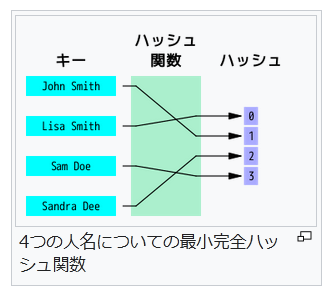
n 個のキーに対する完全ハッシュ関数が最小 (minimal) であるとは、その値域が n 個の連続な整数(通常 0 から n-1)の場合である。単に参照が単純化されるだけでなく、ハッシュテーブルもコンパクトになり、空きスロットができない。最小完全ハッシュ関数は単なる完全ハッシュ関数よりも求めるのが難しくなる。 一様に分布するデータのハッシュ技法
入力が制限された長さの文字列(例えば、電話番号、自動車のナンバー、送り状番号など)で、個々の入力値は独立にかつ一様な確率で発生する場合、ハッシュ関数は個々のハッシュ値にだいたい同じ個数の入力値をマッピングすればよい。例えば、入力 z が 0 から N−1 の範囲の整数、出力 h が 0 から n−1 の範囲の整数で、N が n より大きいとする。するとハッシュ関数としては、h = z mod n ( z を n で割った余り)、h = (z × n) ÷ N (z を n/N 倍して整数に丸めた値)、などの式が考えられる。 その他の分布のデータのハッシュ技法
入力の出現確率が一様でない場合や、独立性がない場合は、上のような単純な方式ではうまくいかない。例えば、あるスーパーマーケットの利用者は地理的に近い場所に集中しているため、電話番号の先頭数桁は同じになってしまう。その場合、(z × n) ÷ N の式では元の数値の上の桁が残るため、衝突が多発する。一方、z mod n の式では、末尾側の桁が残るため、この場合のハッシュ値の分布はこちらの方がよい。 可変長データのハッシュ技法
def make_hash(S0, b) S <- S0 // 状態を初期化 for k in 1..m do // 入力データ単位をスキャン: S <- F(S, b[k]) // データ単位 k を状態に結合 end return G(S, n) // 状態からハッシュ値を抽出 end
この手法は、テキストのチェックサムやフィンガープリントのアルゴリズムにも利用されている。状態変数 S は32ビットか64ビットの符号無し整数である。例の場合、S0 は 0 でよいし、G(S,n) は単に S mod n でよい。最適な F の選択は難しい問題で、データの性質にも依存する。データ単位 b[k] が1ビットなら、F(S,b) は例えば次のようになる。
def F(S, b) return if highbit(S) == 0 then 2 * S + b else (2 * S + b) ^ P end
ここで highbit(S) は S の最上位ビットを意味し、’*’ 演算子は符号無しの整数の乗算でオーバーフローを無視する操作を表す。’^’ はビット単位の排他的論理和演算を表し、P は適当な固定のワードである[4]。 特定用途のハッシュ関数
多くの場合ヒューリスティクスを利用して、汎用のハッシュ関数よりも特定用途で衝突を削減できるハッシュ関数を設計できる。例えば、入力が FILE0000.CHK、FILE0001.CHK、FILE0002.CHK などのファイル名で、多くの場合このような一連の番号が名前に含まれているとする。すると、ファイル名から番号部分 k を抜き出し、k mod n をハッシュ値とすれば、ほぼ最適な結果が得られる。言うまでもないが、特定の入力に最適化したハッシュ関数は、それ以外の分布を示す入力に対しては非常に悪い結果を生じる。 ハッシュとしてのチェックサム関数
チェックサムやフィンガープリント用のアルゴリズムをハッシュ関数として採用することもできる。それらのアルゴリズムの一部は、任意長の文字列データ z から32ビットまたは64ビットのビット列を生成するので、そこから 0 から n-1 のハッシュ値を容易に抽出できる。
この手法は、ハッシュ値の範囲 n がチェックサムやフィンガープリント関数の値域より十分小さい場合に限って、十分一様に分布するハッシュ値を生成する。しかし、一部のチェックサムは雪崩効果が弱いため、用途によっては不向きである。よく使われているCRC32チェックサムは、上位16ビットだけがハッシュ用途に使える。さらに言えば、入力の各ビットはCRC32の1つのビットにのみ影響を与える。したがって、32ビットのチェックサムをそのままハッシュ値に利用する場合は十分な注意が必要である[5]。 暗号学的ハッシュ関数
ドナルド・クヌースによれば、この用語を最初に使ったのはIBMの Hans Peter Luhn で、1953年1月の社内メモで使っていた。そして、Robert Morris が学会誌 Communications of the ACM に掲載した論文でこの用語を使い、単なるジャーゴンから正式な専門用語に昇格した[7]。 脚注・出典
^ https://kotobank.jp/word/要約関数-653412
^ "Robust Audio Hashing for Content Identification" by Jaap Haitsma, Ton Kalker and Job Oostveen
^ Bret Mulvey, Hash Functions. Accessed April 11, 2009
^ A. Z. Broder. Some applications of Rabin's fingerprinting method. In Sequences II: Methods in Communications, Security, and Computer Science, pages 143--152. Springer-Verlag, 1993
^ Bret Mulvey, Evaluation of CRC32 for Hash Tables, in Hash Functions. Accessed April 10, 2009.
^ Bret Mulvey, Evaluation of SHA-1 for Hash Tables, in Hash Functions. Accessed April 10, 2009.
^ Knuth, Donald (1973). The Art of Computer Programming, volume 3, Sorting and Searching. pp. 506–542
Hash Functions and Block Ciphers by Bob Jenkins
Integer Hash Function by Thomas Wang
The Goulburn Hashing Function - ウェイバックマシン(2009年3月19日アーカイブ分) (PDF) by Mayur Patel
Hash Functions by Paul Hsieh
実装
GNU gperf
General purpose hash function algorithms (C/C++/Pascal/Java/Python/Ruby)
The Murmur Hash Function by Austin Appleby
HSH 11/13 by Herbert Glarner
FNV Fowler, Noll, Vo Hash Function
qDecoder's C/C++ hash functions — オープンソースのライブラリ