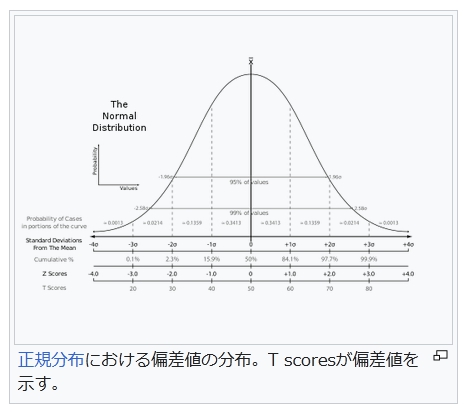
T i = 10 ( x i − μ x ) σ x + 50 {\displaystyle T_{i}={\frac {10(x_{i}-\mu _{x})}{\sigma _{x}}}+50}
ここで、
μ x = 1 N ∑ i = 1 N x i σ x = 1 N ∑ i = 1 N ( x i − μ x ) 2 = 1 N ∑ i = 1 N x i 2 − μ x 2 {\displaystyle {\begin{aligned}&\mu _{x}={\frac {1}{N}}\textstyle \sum \limits _{i=1}^{N}x_{i}\\&\sigma _{x}={\sqrt {{\frac {1}{N}}{\textstyle \sum \limits _{i=1}^{N}(x_{i}-\mu _{x})^{2}}}}={\sqrt {{\frac {1}{N}}{\textstyle \sum \limits _{i=1}^{N}{x_{i}}^{2}-{\mu _{x}}^{2}}}}\\\end{aligned}}}
N:データの大きさ、xi:データの各値、μx:平均値、σx:標準偏差
なお、分子 xi − μx は偏差である。特に、値 xi が平均値 μx に等しいときは、偏差が 0 となり、偏差値は 50 となる。また、値 xi が全て等しいときは、標準偏差 σx = 0 となり、偏差値がこの式では定義できない。この場合、値の偏差値を全て 50 とする[5]。
まず、今私が書いている英語の論文のイントロを丸ごと読ませたら、2秒ほどしてから、数箇所の改善の示唆をしたあと、”Overall, the text is well-written and the grammar is sound.”と言ってくれた。論文のグラフをRで作成するのに試行錯誤で数日を費やしたが、もしChatGPTを使っていたら、この作業は1日に短縮できたと思う。
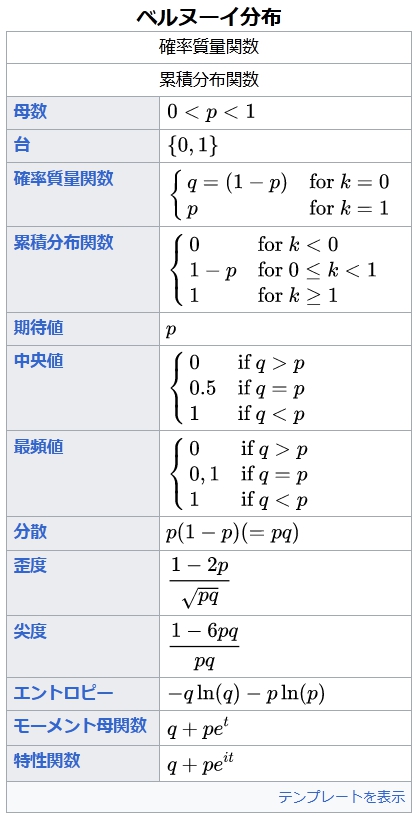
ベルヌーイ分布 確率質量関数 累積分布関数 母数 0 < p < 1 {\displaystyle 0 p 0.5 if q = p 1 if q < p {\displaystyle {\begin{cases}0&{\text{if }}q>p\0.5&{\text{if }}q=p\1&{\text{if }}q p 0 , 1 if q = p 1 if q < p {\displaystyle {\begin{cases}0&{\text{if }}q>p\0,1&{\text{if }}q=p\1&{\text{if }}q<p\end{cases}}} 分散 p ( 1 − p ) ( = p q ) {\displaystyle p(1-p)(=pq)} 歪度 1 − 2 p p q {\displaystyle {\frac {1-2p}{\sqrt {pq}}}} 尖度 1 − 6 p q p q {\displaystyle {\frac {1-6pq}{pq}}} エントロピー − q ln ( q ) − p ln ( p ) {\displaystyle -q\ln(q)-p\ln(p)} モーメント母関数 q + p e t {\displaystyle q+pe^{t}} 特性関数 q + p e i t {\displaystyle q+pe^{it}} テンプレートを表示
ベルヌーイ分布(英: Bernoulli distribution)とは、数学において、確率 p で 1 を、確率 q = 1 − p で 0 をとる、離散確率分布である。
ベルヌーイ分布という名前は、スイスの科学者ヤコブ・ベルヌーイに因んでつけられた名前である。
X をベルヌーイ分布に従う確率変数とすれば、確率質量関数は
P ( X = 1 ) = p , P ( X = 0 ) = q = 1 − p {\displaystyle P(X=1)=p,\qquad P(X=0)=q=1-p}
である。これを
P ( X = k ) = p k ( 1 − p ) 1 − k ( k = 0 , 1 ) {\displaystyle P(X=k)=p^{k}(1-p)^{1-k}\qquad (k=0,1)}