カテゴリー: AI、関連
-
AIカフェロボベンチャーを率いる21歳起業家は300年後を夢見る
ニューイノベーションズ、中尾渓人CEOインタビュー
https://newswitch.jp/p/22867



『ニューイノベーションズ(東京都文京区、中尾渓人最高経営責任者〈CEO〉)は、1億7000万円の資金を新たに調達した。同社は人工知能(AI)で需要予測をする無人コーヒー機を開発するスタートアップ。調達した資金はサブスクリプション(定額制)モデルの実装などに投じる。今夏には東京都内の複数のオフィスビル内などで、無人コーヒー機の導入を計画する。
ソフトバンクグループの100%子会社で、AI支援に特化したベンチャーキャピタルのディープコア(東京都文京区)からの追加出資などで、累計2億4000万円の調達となる。
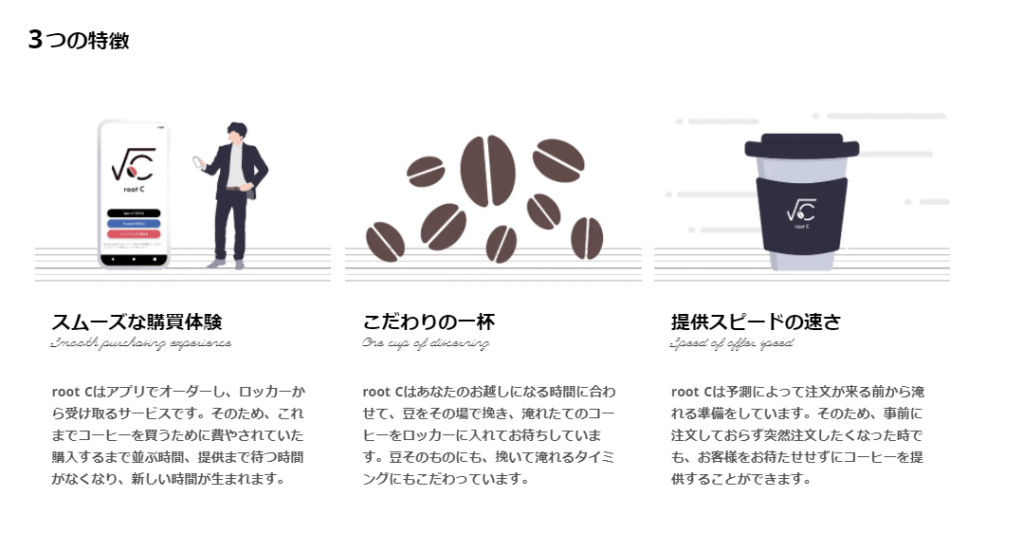
ニューイノベーションズが開発した無人コーヒー機「root C(ルートC)」は、AIで気温や天気、立地、時間、販売データなどを基にコーヒー需要を予測して抽出を始めるのが特徴。ユーザーはアプリを通じて注文と決済ができるため、上質なコーヒーを最大20人が待たずに受け取れる。
3月に実施した三菱地所の新東京ビル(東京都千代田区)での10日間の実証試験では、味の異なる2種類のコーヒーをホット、アイス、普通、濃いめの計8種類から1杯300円(消費税込み)で注文でき、約半数のユーザーが2回以上利用したという。
中尾CEOはロボカップジュニアの世界大会での入賞経験があるなど、長年ロボットを作ってきた。ニューイノベーションズは17歳だった18年に設立した。
日刊工業新聞2020年6月24日
ニューイノベーションズ・中尾CEOインタビュー
中尾渓人CEO
無人コーヒー機「root C(ルートC)」を開発したニューイノベーションズ。率いるのは大阪大学在学中の中尾CEOですが、お話を聞くうちに「学生が起業家になったのではなく、起業家が学生になった」という印象を受けました。聞き手は中尾CEOと同じ年代生まれの3人。年齢が近いことならではの疑問も飛び交いました。(聞き手・熊川京花、鈴木奏絵、伊藤快)-起業の経緯がとてもユニークだと聞きました。
もともとロボット作りが好きなんですけど、小学校4年生のころからロボカップジュニアの大会に出始め、中学生のときに世界大会で入賞しました。そのころから将来自分は何をしようかと考えていましたが、メーカーの開発職を想像してもどうにもこれだ!とはならなくて、モヤモヤしていました。ただ、ロボットの大会には出続けたいと思っていたので、その費用を稼ぐために、高校1年生の時から素性を隠してフリーランスのエンジニアとしてクラウドワークスに登録しました。最終的に取引先が300社くらいになったんですよ。受託作業は睡眠時間もほとんどない状況になりました。このままだと過労死するし、これをずっとやりたいと思っているわけではなかったので、高校卒業のタイミングでやめました。
僕は出身が和歌山県で、智弁学園に通っていたんですが、学校のHPがあまりにしょぼかったんで、理事長に直談判して、「作らせてくれ」とお願いしたこともありました。高校の卒業式の1週間後くらいに手がけたので、ある意味卒業制作ですね(笑)。学費分くらいは回収できたと思います(笑)。理事長も学校のいい宣伝になると思ったんじゃないでしょうか。
そのころにご縁ができたベンチャーキャピタル(VC)の方にいろいろと自分の将来について相談していたら、いつの間にか起業することが既成事実化していました。あと、受託で得た売り上げや取引先のことを考えたら、法人格がないと「社会資本市場的に損かもしれない」と考え始め、それも起業を後押ししたと思います。
あと受験勉強が意味が分からないくらいに嫌いすぎて(笑)。智弁学園は結構進学校なんですけど、周りの友人が「医学部を受ける」とか言っているのを聞いて、「あ、このままだとまずいな」と思いました。
高3で捨て身で起業
-まずいというのは?
学歴を取得することに対して、今の社会からのペイバック(見返り)がなくなってきているなと思いました。嫌いな受験勉強を強制されるくらいなら、やりたいことをやった方が自分の市場価値が上がると考えて、高3の夏に捨て身で起業しました(笑)。17歳の時でした。大阪大学の推薦入試の面接で起業したことをアピールしたんですが、落ちたら東京に行こうと決めていました。-高校生のころからすでにいろいろ経験していますね。
新卒で入社した方とは経験量が違うとは思いますが、社会経験で重要なポイントは押さえられたかなと。高1で受託業務を始めたときは、スキルが全然伴ってなかったんですが、「経験あります!」とか言って案件を受けて、その後死ぬほど怒られたりしました(笑)。でも、その時に世の中の厳しさや当たり前を学ぶことができたかもしれません。自分に能力が足りなかったから相手を怒らせたパターンと、相手がやばい人だったから自分が損害を受けたパターン、というように振り分けが少しずつできるようになってきて(笑)。どう振る舞えばいいかというのはなんとなくつかめていきました。ルートCについて説明する中尾CEO
-17歳で起業ってすごいですよね。周囲は止めたりしなかったんですか?
そもそも起業という行為自体が過大評価されていると思います。なので、大々的に周りに触れ込むようなことはしませんでした。友達に話しても「そうなんだ」みたいな感じ。逆にニュースで知ったという人もいました。先生の中には本気で止めてくる人もいましたが、合理性を説明していたら途中で諦めてくれました(笑)。後はひたすら大きくなるしかない
-起業して中尾さんの中で何が変わりましたか?
周りの対応と見える世界が変わったかもしれません。会社があるかないかで結構みんなオドオドするというか、普通かそうでないかに分けられてしまう。ですが、それは組織としての会社という箱の強さだと思っています。起業した本人にその強さがあるわけではないんです。自分は何も成長していないのに、世界が一気に変わるような怖さも感じました。あと起業するのもやめるのも、事業拡大するのも縮小するのも、自分で決断できるかと思っていましたが、実はそんなことはなくて。資本主義の世の中なので後はひたすら大きくなるしかないんです。無理だったら市場から駆逐されて終わります。そういうことも実感するようになりました。
その点、大企業はコンスタントに成果を出し続けていますよね。だけどそのためには、職階などが良くも悪くも制限されています。そのことに「自由がない」と思うのなら起業すればいい。起業という言葉に流される必要はないと思います。ところで、皆さんは僕と同世代と聞きましたが、周りで起業される人はいないですか?
世の中にフラットな目線、大事
-いませんね。先ほどから中尾さんのお話に圧倒されてばかりです。
全然そんなことはないですよ!いざ自分が起業してみれば「起業するなんてすごいな」という気持ちはゼロになると思います。だけど、世の中全般に対するポジティブなイメージはない方がいいかもしれません(笑)。フラットな目線が大事。ビジネスなので、法人対法人のバトルとか駆け引きとか、情けも容赦もない合理性でしかないでしょ。「札束の殴り合いになったらどうしよう」とか、怖いですよ(笑)。そこで守ってくれる人は誰もいないし。守ってくれる人を確保するか、自分で自分を守る知識を身に付けるしかない。そういう点では大企業はとても守られているかもしれません。
―ところで影響を受けた起業家の方はいますか?
それが全くいません。人なのでうまくいくこともいかないこともあると思うので、僕は人に対してではなく、「●●さんの何回の定時株主総会のあの発言がすごい」というような、その人が成し遂げた行動に対して尊敬するタイプです。―行動に対してなんですね。
そうですね。その点、今の自分にスキルがどれくらいあるのかというのは気になります。僕のことを評価してくださっている人が僕のエンジニアのスキルに対してなのか、今の僕の年齢にしてはすごいという程度のビジネススキルについてなのか。だから実際にビジネスをやって、負けるかどうかを判断した方が現実を知ることができていいと思ってます。市場は冷たいからダメな時もわかりやすいだろうと。その時に、成長の試行錯誤をするパワーを自分たちがまだ持っているならいいんです。そこでつぶれてしまうくらいなら止めた方がいい。僕たちも日々、大小さまざまなトラブルが起きていますが、成長の源泉だと考えて乗り越えています。
ルートCを使用する中尾CEO
無人化の行き着く先に
―今後ニューイノベーションズをどう大きくしていくのでしょうか?
二つあります。一つ目は上場することです。合理性もあるし、それを目標としているから投資をしていただいているというのもあります。もう一つは、「あらゆる業界を無人化する」というのを会社のビジョンとして掲げていますが、社会の中で必要とされていることを成し遂げて、価値を生んでいる状態を維持したいです。コングロマリット的なことはしつつも、今の自分たちが持っている「リアルビジネス×オンライン」という文脈での強みを生かせるところで、次の成長材料になるものを作っていきたい。10年20年のスパンで必要とされる会社だったら、300年後も1000年後も生き残っていられるのかな、と思っています。
少し逆説的な話になりますが、何か大きなことをやりたいと思った時に「お金や権力、人脈、資産がないからできない」という状態になるのを恐れています。それを避けるために今頑張っているというのもあります。
―今の急速なテクノロジーの発達を見ると、「AIやロボットが人の仕事を奪う」という声も大きくなっています。会社のビジョンとして掲げる「あらゆる業界を無人化する」にはどのような意図があるのでしょうか?
労働者を駆逐するというように誤解されることが多いですが、そうではなくて「ヒューマン トゥ ヒューマン」のコミュニケーションが求められるところにリソースを解放したいと考えています。これはあくまで僕の個人的な意見ですが、例えば人の代わりに機械が導入されたら、その機械をメンテナンスする仕事が生まれるように、何かが失われたら何かが生まれるはずです。市場なので満たされている人と、満たされていない人という分布は基本的には変わらなくて、その中での移動性が高まるのではないかと考えています。
低付加価値のものが効率化して代替される、というのは歴史的に何度も繰り返されてきました。それを乗り越えたからこそ、社会は豊かになってきたはずです。だから正しい時代のシフトなのではないでしょうか。』
-

※ 上記は、Edraw Maxというソフトで、テンプレを利用して作成したものだ。3つの価値が三方から、せめぎ合っている…、という感じを出したかったんだが、そういう感じが出ているだろうか…。
※ 思考を図形化する作画ソフトは、いろいろあって、Edraw Maxはその一つだ…。10日間は、無料のお試し期間なんで、有料版を購入するかどうかは、その後で考えよう…。
※ 肝心なのは、思考、分析、考察を深めることで、「見栄えの良い図形」を作画することでは無い…。
※ 何のために図を描くのかと言うと、「イメージや発想・着想が、雲の如く湧いてくる」ということの助けにするためだ…。
※ そういう目的のためには、かえって「ラフなスケッチ」の方が、妙に「発想を刺激する」ことが、よくある…。
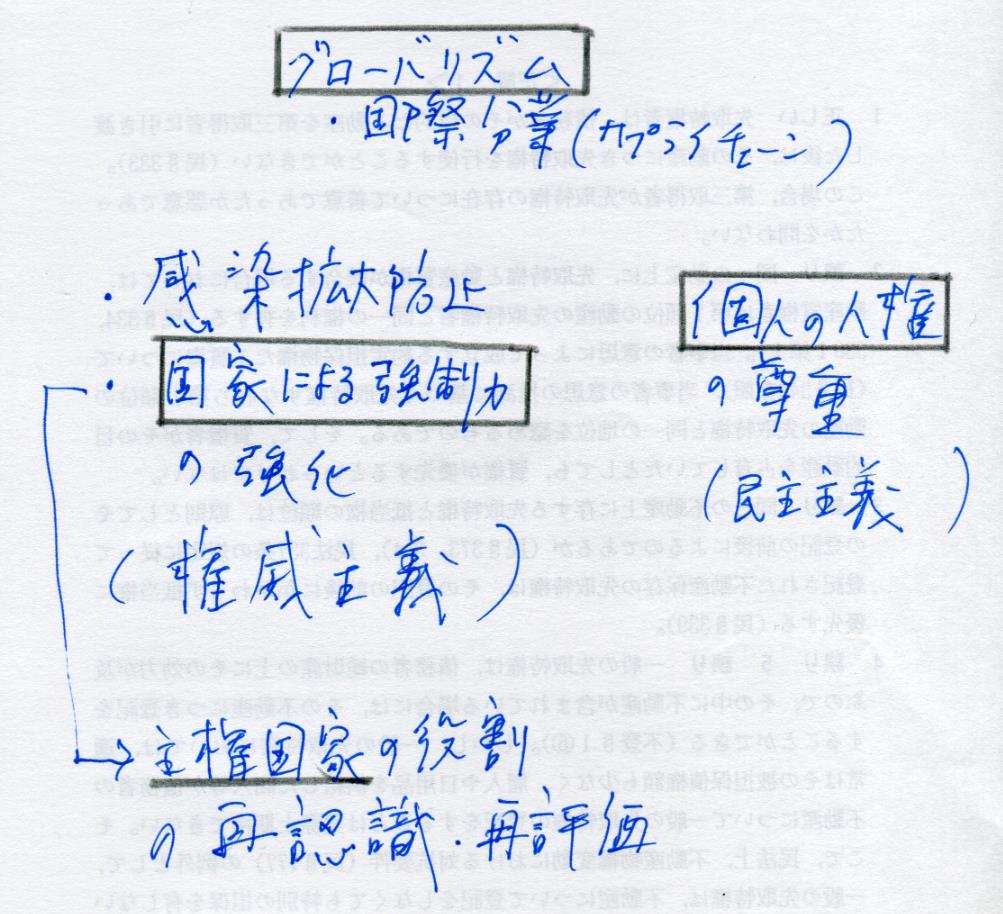
※ こういうものは、あまり整ってはいないが、囲んでいる線(黒の色鉛筆によるものだ…)や、ケチって印刷済みの紙の再利用による裏写りすら、妙に「発想を刺激して来る」…。
※ ただ、プレゼンなんかで、どうしても「整ったもの」が必要だというケースもあろうから、紹介しておく…。
AI開発でも世界に亀裂 異なる道を行く中国
編集委員 太田泰彦
https://www.nikkei.com/article/DGXMZO62380610W0A800C2I00000/

『人工知能(AI)にも「お国柄」がある。判断の基準をマシンに教える側の人間社会に考え方の違いがあるからだ。同じ問題を解くのでも、開発した国や組織が異なれば別々の答えを導き出すことがある。
6月末、米政府の独立機関であるAI国家安全保障委員会が「コロナ危機対応とAI技術の役割」と題する白書を公表した。全米の病院や企業が臨床データを共有し、AIでワクチン開発を急ぐ案など10項目の提言からなる。
同委員会によるAIと新型コロナウイルス対策に関する白書は、5月以来、実に3冊目だ。プライバシーやソフト開発者の責任など根本的な倫理問題の見解について、議会と国民に明確に示す必要があるからだ。政府の予算を使う以上、いくら切羽詰まった状況でも民主主義の手続きは省けない。
中国ではAI導入のスピードが速かった。人の流れを監視するための個人の識別や感染経路の予測など、現場で活用が進んでいるのは事実だろう。
人口100万人あたりの感染者数(8月15日時点)を比べると、米国とブラジルが1万5千人を超えている。数字に信頼性の問題はあるが、ウイルス発生地とされる中国は62人にとどまる。個人情報の保護より監視データの収集を優先する社会の方が、感染対策で有利であるのは明らかだ。
コロナは国ごとの価値観の差異を浮き彫りにした。「機械ではなく人間が中心のAI社会を、どの国が築けるか」。社会と技術の関わりを研究する青山学院女子短期大の河島茂生准教授は、世界史の分岐点が来たとみる。
違いは研究開発の姿勢にも如実に表れている。「XAI」と呼ばれる研究分野が象徴的だ。
「X」は「説明できる(Explainable)」の意味。人間の言葉や画像を使って推論の筋道を分かりやすく説明できる能力を備えた次世代型のAIだ。この分野では米国防総省の国防高等研究計画局(DARPA)が世界の最先端を行く。
機密が多いはずの軍事部門が透明性を高めようとするのは、自律的なロボット兵器や作戦行動の自動立案が、既に米国で実用化されているからだ。機械が人命に関わる判断を下すなら、その判断の理由を説明する責任が軍にはある。「AIが決めたから」では済まされないのだ。
機械学習の原理をみると、AIの「思考」の中身がブラックボックスであるという問題が浮かび上がってくる。
たとえば画像に映る動物が、猫なのか犬なのか判断するAIをつくるとしよう。それには人間が教師となり、1枚ごとにAIに正誤を教えていく。最初はハズレが多くても、教育を数千万回と繰り返せば、アタリの率は限りなく高まる。
だが、耳が三角だから猫と判断したのか、ヒゲが短いから犬なのか。理由は外部からは一切わからない。結果が正しいというだけである。機械学習とは、原理的に不透明な技術なのだ。
異なる社会では、異なるAIが育つ。膨大なデータによって、中国製のAIは今後さらに賢くなっていくだろう。人間にたとえればIQ(知能指数)だけが高くなるようなものだ。
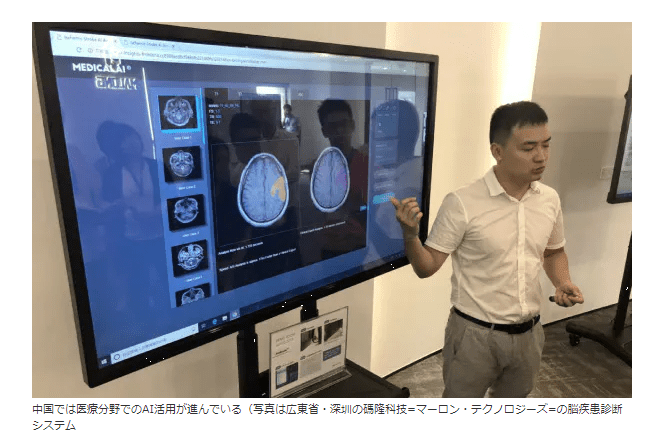
中国では医療分野でのAI活用が進んでいる(写真は広東省・深圳の碼隆科技=マーロン・テクノロジーズ=の脳疾患診断システム
特許庁の7月末の調査によると、中国のAI特許の出願数は2017年に6858件に上り、それまで圧倒的な首位だった米国(5954件)を追い抜いた。毎年2倍のペースで増え続け、中国はAI大国の地位を着実に築きつつある。
中国での出願のほとんどは実用的な機械学習の特許だ。ブラックボックス化を防ぐ「XAI」の研究はみあたらない。思考の中身が分からない機械が医療や自動運転、裁判、組織人事などで、世界に先駆けて実用化されていくかもしれない。倫理と切り離して猛進する中国技術には、危うさがないだろうか。
欧州連合(EU)の欧州委員会は昨年4月、非差別、説明責任など7項目の「AI倫理指針」をまとめた。日米ではグーグル、ソニー、富士通などの企業が、競うように自主倫理規範を導入している。ユーザーに信用されなければAIビジネスが成り立たないからだ。
中国でも昨年6月、国家次世代AIガバナンス専門委員会が、8つのAI原則を公表した。プライバシー尊重も項目の一つだが、果たしてどれほどの効力があるだろう。
美しい言葉を並べて倫理規範をつくっても、形だけに終わる恐れがある。極言すれば、人間の尊厳を軽んじる社会からは人間を大切にするAIは生まれない。』
-
Amazonもハマった、「AIを使うとき」の落とし穴
https://www.itmedia.co.jp/business/articles/2007/09/news022.html
※ まあ、実際の画像は、こういう「クッキリ、スッキリ」ばかりじゃ無いからな…。

『それは大手IT企業も例外ではない。おなじみの米Amazon.comは採用活動を支援するために、応募者から寄せられる履歴書を審査するAIを使っていた。ところがこのAIが、女性の応募者を不当に低く評価していた、つまり女性に“偏見”を持っていたとして利用を中止している。
なぜそのようなことが起きたのか、それはAIにモデルを構築させるために、過去の社員や応募に関するデータを与えていたからだった。米国でも、IT技術者はまだまだ男性の方が多い。そのためAIは、過去のデータから「男性を採用すべき」というモデルを作ってしまったのだ。
将来は、新しいAI開発手法が考案され、こうしたミスを避けられるようになるかもしれない。しかしそれまでは、現在のAIは与えるデータによってアウトプットが大きく左右されてしまうものだという大前提を肝に銘じておこう。
また新しい手法が登場したとしても、それには別の長所と短所、そして別の前提条件が生まれるだろう。だからこそ、自分自身が開発者にならなかったとしても、「いま自分が使おうとしているAIは、いったいどのような仕組みで動いているのか」を理解しておく必要があるのだ。』
『その上で、次に必要になるのは「AIをどこに使うか」という判断力である。いまは第3次AIブームと呼ばれるほどAIへの注目が高まり、AIやそれらを使ったアプリケーションも進化しているが、残念ながらAIは万能ではない。というより、前述のようなAIを実現する仕組み、あるいはそれらが活用される環境では、得意なことと不得意なことが変わってくるのである。私たちには環境を変える力がないことが多いが、使うツールを選んだり、使い道を変えたりすることはできる。これらを考慮して、ツールの価値を最大限に引き出さなければならない。』
『一例を挙げよう。ある旅行会社で、スマートフォンで観光地の写真を撮ると、AIがそこに写っている被写体が何なのか(有名な寺社仏閣やモニュメントなど)を認識し、関連情報を表示してくれるアプリを作ってはどうかという計画が持ち上がった。
これなら外国に出かけたとき、現地語の説明が読めなくてもそれが何なのか理解できる。旅行ガイドを開くより手軽だし、適当に写真を撮っておいて、後からそれが何だったのかを確認することもできる。また、関連情報を表示する際、広告やクーポンなどの情報も表示すれば、旅行者にさらなるアクティビティーを促せる。それが新たなビジネスへとつながるだろう、というわけだ。幸い旅行会社なので、教師データとなる観光地の写真は多数用意できそうだ。早速、試験的なAIの構築が始まったが、精度の高いアプリケーションを実現することはできなかった。
理由は単純で、用意された教師データの大部分が、被写体を美しく撮影したものだったからだ。晴天の中、被写体がもっとも美しく見える角度で撮影された写真ばかり――PRが目的なのだから当然だ。しかしテストに協力してくれた一般の人々は、さまざまな天候、時間、角度で写真を撮っていた。バスで移動中に、急に気になる建物が視界に入ったので、ブレブレでピントも合っていない写真を撮ったという場合もあった。これでは思うような精度は出せない。最終的にこのプロジェクトは、精度が出せるように被写体と用途を限定するという方向へ進むことになった。あらゆる条件下で、達成したい価値の100%を実現できるAIを実現するのは難しい場合が多いが、AIを使用する範囲を一定に絞り込むことで、価値をある程度まで手にできることも多い。実現できなかった部分は、従来通り人間が担当したり、あるいは人間とAIが協力してタスクを実行したりすることができる。そうした判断を、AIを活用する側が下していくわけだ。
もちろんこうした判断を、誰もが正確に下せるわけではない。多くは試行錯誤を経て、あるいは過去の類似事例や経験に基づいて正解へとたどり着くことになる。これからAIを学ぼうというマーケターも、座学だけでなく、大小さまざまな実践と失敗を通じてスキルを磨くことになるだろう。』
『 実践する際には、失敗が致命傷とならないよう、AIが持つリスクを理解しておく必要がある。特にマーケティング活用では、AIの誤作動が顧客に直接的なダメージを与えてしまいかねない。そして前述のように、大手IT企業でも失敗する場合があるほど、AI利用に潜む落とし穴を把握することは難しい。AIの仕組みや利用法に関する知識を得るのと同時に、リスクについても確実に学んでおこう。』
『その際に参考になるのは、各国の政府や国際機関、業界団体が発表しているガイドラインだ。AIを利用する際の注意点についてまとめたもので、その多くは、非技術者にも理解できるような表現が使われている。
例えば、総務省の情報通信政策研究所が2019年8月に発表した「AI利活用ガイドライン」では、「AIサービスプロバイダー、ビジネス利用者およびデータ提供者が留意すべき事項」として、10項目のAI利活用原則を定めている。(1)適正利用の原則:利用者は、人間とAIシステムとの間および利用者間における適切な役割分担のもと、適正な範囲および方法でAIシステムまたはAIサービスを利用するよう努める。
(2)適正学習の原則:利用者およびデータ提供者は、AIシステムの学習などに用いるデータの質に留意する。
(3)連携の原則:AI サービスプロバイダー、ビジネス利用者およびデータ提供者は、AIシステムまたはAIサービス相互間の連携に留意する。また利用者は、AIシステムがネットワーク化することによってリスクが惹起(じゃっき)・増幅される可能性があることに留意する。
(4)安全の原則:利用者は、AIシステムまたはAIサービスの利活用により、アクチュエータなどを通じて、利用者および第三者の生命・身体・財産に危害を及ぼすことがないよう配慮する。
(5)セキュリティの原則:利用者およびデータ提供者は、AIシステムまたはAIサービスのセキュリティに留意する。
(6)プライバシーの原則:利用者およびデータ提供者は、AIシステムまたはAIサービスの利活用において、他者または自己のプライバシーが侵害されないよう配慮する。
(7)尊厳・自律の原則:利用者は、AIシステムまたはAIサービスの利活用において、人間の尊厳と個人の自律を尊重する。
(8)公平性の原則:AIサービスプロバイダー、ビジネス利用者およびデータ提供者は、AIシステムまたはAIサービスの判断にバイアスが含まれる可能性があることに留意し、また、AIシステムまたはAIサービスの判断によって個人および集団が不当に差別されないよう配慮する。
(9)透明性の原則:AIサービスプロバイダーおよびビジネス利用者は、AIシステムまたはAIサービスの入出力などの検証可能性および判断結果の説明可能性に留意する。
(10)アカウンタビリティの原則:利用者は、ステークホルダに対しアカウンタビリティを果たすよう努める。』
『ガイドラインによっては、AIの非軍事的な利用や公教育でのAI教育の必要性など、社会全体で行うべき取り組みを定めているものもあるが、多くは上に挙げた10項目のような、一つの企業や組織内で実践できる取り組みを解説している。信頼できる組織が発表したものを選び、自らの取り組みを検証してみると良いだろう。その際に重要なのは、関係各部との連携だ。AIはITシステムであり、開発から利活用までではシステム部とマーケティング部のやりとりが中心になるだろう。しかしプライバシーに関するリスクのように、コンプライアンスや法務が関係する部分もある。AIの利活用が生み出すリスクは、組織横断的に対応する必要があるのだ。その意味で、AIに関する知識やスキルを学ぶ段階から、他部門との連携や共同作業を進めておくべきだろう。
AIへの正しい対応方法を修得するというのは、誰にとっても簡単な話ではない。テクノロジー自体が現在進行形で進化していることに加え、それを正しく利活用する原則や理論にも、アップデートが加えられている。しかしマーケティングの世界は、これまでも各時代における最新のテクノロジーや理論を積極的に取り入れ、進化してきた。自らが新たなマーケティングの世界を切り開くという気概で、AIにチャレンジしてほしい。』
AI利活用ガイドライン
~AI利活用のためのプラクティカルリファレンス~
https://www.soumu.go.jp/main_content/000637097.pdf -
プログラミング講座 「手に職」求め、申し込み倍増
https://style.nikkei.com/article/DGXMZO60184280Q0A610C2000000?channel=DF040320205903
※ 「プログラミング」と「コーディング」は、違う…。ここを、誤解している向きは多い…。文系AI人材になろう ビジネス利用の基礎知識を伝授
八重洲ブックセンター本店
https://style.nikkei.com/article/DGXMZO54722070S0A120C2000000?channel=DF030920184323&nra
※ この書籍は、実は買った…。電子書籍でだが…。
けっこう、というより非常に参考になった…。
全体的な視点は、もはや「AIは、簡単に作れる段階に至った」。だから、AI人材というものも、「AIを、作れる人材」から、「AIを活用して、問題解決を図っていく人材」というものに、必要とされる人材像が異なる段階となった…。そこでは、むしろ、「理系」よりも、「文系」の人間の方が、活躍の「フィールド」が幅広いだろう…、というものだ…。総合職でもスペシャリストでもない 10年後必要なのは
ミドル世代専門の転職コンサルタント 黒田真行
https://style.nikkei.com/article/DGXMZO60036750V00C20A6000000?channel=DF180320167080&page=3
『1950年ごろに生まれ、新中間層と呼ばれたホワイトカラーは、そこから70年経過して、より生産性の高い領域に進化しようとしています。このプロデューサーやテクノロジストを、さらに総称すると、「しくみをつくれる人」ということになるのではないでしょうか。世の中は、プラットフォームの時代になっています。検索サイトが最も代表的ですが、ほかにも、中古品売買、求人、結婚パートナー探し、住宅などのありとあらゆるマッチングサイトも、プラットフォーム化しています。そのサイト内で、利用者が増えれば増えるほど、プラットフォームを提供している会社がもうかるしくみになっています。
このしくみのよさは「一度、つくったら動き続けてくれて、運営者がいなくてもしくみが稼ぎ続けてくれる」という点にあります。
労働集約の時代には、「与えられた情報を分析して整理し、言語化できる人」がエリートと呼ばれてきましたが、これからはプラットフォームのような「しくみをつくれる人」が求められていくことになります。
しくみをつくるには、自らの企画開発能力が必要なだけではなく、多様なプロデューサーやテクノロジストの力を借りて、事業を組み上げていく編集力が不可欠です。それを実現していくためにはテーマを設定し、ビジョンを言語化し、周囲を巻き込んで協力を得なければなりません。
コロナ・ショックをきっかけに、世の中の価値観が動き始めています。これから10年後の2030年に社会から求められる人材になるために、この記事を参考にしていただき、少しずつ準備を始めていただければ幸いです。』
「僕は起業家向きじゃない」 AI人材の育成こそ天職
東京大学大学院 松尾豊教授(上)
https://style.nikkei.com/article/DGXMZO59989990U0A600C2000000?channel=DF041220173308

『――具体的にどのように起業家向きではないのですか。「僕は物事を抽象化するのは得意です。産業の重要性もよく理解していますが、具体的な事業の話になると興味がだんだん薄れてゆくのです。お金をもうけるのは具体的なところにどこまでこだわっていけるかにかかっています。僕は『知能とは何か』といった抽象的なテーマはとことん突き詰めるタイプだから、研究者としては合っていると思います。だけど、起業家は性質的にあっていません」
「もう一つ理由があります。人を励ますのが下手なんです。研究の世界は勝ち負けがはっきりしています。客観的に評価されて、忖度(そんたく)はありません。しかし、事業をやるとなると、ダメな人でもほめなくてはいけない場面がでてきます。でも、僕は良くないモノをどうしても良いと言えないのです。根が研究者としての設定になっているんでしょう」』
『――尊敬している起業家は。「たくさんいますが、東大出身者だと、江副浩正さん(リクルート創業者、13年没)はすごい人だったと思います。もともと広告を情報として載せる、というビジネスモデルを考え出して事業を成長させました。1980年代にはニューメディア事業を模索していて、インターネットが出るかなり前から新たな情報媒体を使った広告モデルを考えていたようです。90年代も江副さんが現役で活躍していれば、日本でも検索エンジンの開発が進んでいた時代だったので、絶対に広告ビジネスを考え出していたはずです。もしかして、グーグルのような巨大企業が日本から誕生したという、別の未来もあったかもしれないとさえ思っています」』
『「2002年に研究者として、ウェブ上のデータ分析を活用した広告モデルを提案したことがあります。現在でいうターゲット広告の基礎となるような技術なのですが、当時の偉い先生から『広告なんてくだらない』と却下されました。その時、いいメンターがいれば違ったはずだと感じました。世界に先駆けた圧倒的な技術だという自信があったからです。当時、有能なベンチャーキャピタリストがいて、この技術で起業してみればという話になっていれば、もっといろいろ広がったのに、と今でも思います」「江副さんのような人がいれば、僕を支援してくれたかもしれないんです。だから逆に今、若い人にやってあげたいのです。僕がシリコンバレーのベンチャーキャピタリストのような役割を果たしたいと考えています。起業家の成功、失敗の事例をたくさん集めて、きちんと把握し、抽象化して次の挑戦者に伝えてゆく。そして起業の成功率を上げてもらうのです」』
常識打ち破りたい 使える「不思議ちゃん」になる方法
第7回 創造思考
https://style.nikkei.com/article/DGXMZO60013360V00C20A6000000?channel=DF120320205956&page=3
『「アイデアとは既存の要素の新しい組み合わせにすぎない」(ジェームス・ヤング)というのが、もっとも有名なアイデアの定義です。ここから言えるのは、大量の知識や情報を頭につめこんでおかないと発想は生み出せない、ということです。これが1つ目の原理です。実際に、皆さんのまわりにいるアイデアパーソンは、いろんなことに興味を持ち、常に情報収集を心がけ、とても物知りな方ではありませんか。インプットが創造思考の成否を握っています。
2つ目の原理は「数撃てば当たる」です。どのアイデアがヒットするか事前には分からず、次から次へと組み合わせを変え、量を増やすことで質を上げるしか方法がありません。桁違いにたくさんのアイデアが母数として求められます。
そのためには、3つ目の原理として、発散(広げる)と収束(絞り込む)、仮説(考える)と検証(確かめる)のステージをきっちりと分けることです。アイデアを広げるときは評価や批判は厳禁。特に、みんなでアイデア出しをやるときは、注意しなければなりません。』
『創造思考を働かせているうちに、行きづまってしまうことがよくあります。これ以上新しいアイデアが思いつかなくなったり、ありきたりの発想からどうしても抜け出せなくなったりして。そんなときに効果的なのは、「前提を疑う」ことです。「○○すべきだ」「○○でなければならない」という当たり前や常識を、「本当にそうなんだろうか?」と疑ってみることが大事です。』
-
まずは数理的思考を身に付けよ!全大学が「AI教育」を競い合う時代に
https://newswitch.jp/p/22307
※ こういう人が、書いている記事だ…。
『ビジネスや行政などの意思決定の根拠となるデータを、数理的な思考でとらえて人工知能(AI)で分析する―。そんな数理、データサイエンス(DS)、AIの人材育成が急ピッチで進む。政府の「AI戦略2019」では初級レベルは全大学生に必須とされ、認定教育プログラム制度が進みだした。文部科学省のモデル構築事業も拠点6大学から協力校へと展開中だ。これらの教育に関わらずに済む大学は皆無、そんな時代に入っている。(取材=編集委員・山本佳世子)』
『政府が19年にまとめたAI戦略でイメージするのは、組織の活動やIoT(モノのインターネット)で得られるビッグデータ(大量データ)を、統計学やAIで分析して活用する人材だ。企業や官公庁、地域社会などあらゆる分野の課題解決でニーズが急増している。内閣府は象徴的な言葉としてAIを出しているが、教育テーマとしては論理的考え方やデータに基づく分析など広義のものだという。同戦略では25年の目標を掲げ、大学生は学部によらず「全員が初級のリテラシー(読解記述力)レベルを学ぶ」とする。大規模な取り組みとなるため「数理・データサイエンス・AI教育プログラム認定制度」で後押しする。応用基礎レベルの整備は1年先に予定しているが、まず今年3月にリテラシーレベルを2本立てで整えた。
このうち「認定教育プログラム」は「全学での開講」「複数の専門分野の学生の履修」「履修の学生数や率を高める計画」などの要件を満たせば書類審査で済む。ただ申請プログラムで1年以上の活動実績が必要だ。「データサイエンス学部の実績を基に、全学展開を図る大学」などが対象と予想される。』
『もう一つ、一段上となるのが「認定教育プログラム+(プラス)」だ。他大学を先導する独自のプログラムで、認定には実地調査もある。「全学生の半数以上が履修しているか、3年以内に実現する計画」という部分のハードルが高い。内閣府の佐藤文一審議官は「旧帝大や研究型大学には、より先進的な取り組みで『プログラム+』にチャレンジしてほしい」と強調する。どこが先陣を切るのか、視線が集まることは間違いない。』
『文部科学省は17年度から、大学が文系理系を問わず全学的な数理・DS教育を後押しする事業を進めている。20年度は国立大学の運営費交付金の一部の10億円をこれに充てる。事業開始時は「数理・DS教育」としており、前面になかったAIも、今は内閣府の戦略と相まって扱う。拠点校は北海道、東京、滋賀、京都、大阪、九州の6国立大学だ。数学、統計、情報など各大学の強みを出しながら、他大学の参考になる標準カリキュラムの策定に向けて、学内での実施に取り組む。』
『九州大学数理・データサイエンス教育研究センターは最初に、高年次学生・大学院生向け講座に取り組んだ。受講生の卒業・修士研究用のデータ解析プログラムを実装し、個別指導をしつつ理論の学びに誘導した。理論から実装に進む通常の積み上げ式とは、逆の学びにしたのが注目だ。次いで低年次学生向け講座では、看護学や文学など意外な分野も含めた先輩の実例を紹介。その上で学科別に必要なデータ解析法の原理を解説し、学生のやる気を引き出した。
専門が多岐にわたる教員・研究者60人程度が参加する合宿勉強会もユニークだ。共同研究費を用意し、例えば数学、情報、病院の研究者が、病院内の治療方針や医薬品選定を合理的に決める手法の開発に取り組む。内田誠一センター長は「データ分析を串にして、考えられなかったつながりが生まれている」と効果を実感している。』
『一方、北海道大学の場合は「学部、修士、博士の各課程を想定した文科省のDSの3事業すべてで採択されている」(数理・データサイエンス教育研究センターの湧田雄基特任准教授)のが強みだ。またデータを持つ企業と北大の産学共同研究を基に、社会人教育を展開する特色もある。』
『19年度には6拠点大学に加えて計20の国立大を協力校に据え、さらに公私立大へも広げていく計画だ。他大学での実施には、新型コロナウイルス対応で導入が進んだオンライン授業と演習の組み合わせや、指導役の教員を育成するファカルティー・デベロップメント(FD)も重要だ。伝統と異なるさまざまな手法で浸透を図ることになりそうだ。』
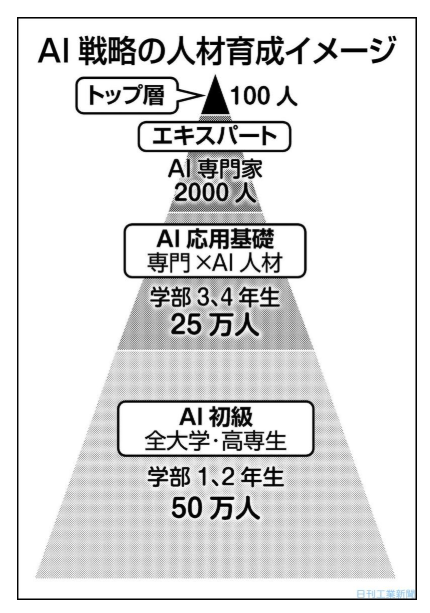
『内閣府の総合科学技術・イノベーション会議(CSTI)などで議論してきたAI戦略のうち人材育成は、25年時点で実施する人数を示している。最も下の小中学生は情報通信技術(ICT)の端末を1人1台で扱う。年間、つまり1学年の全高校生約100万人で理数(理科と数学)の素養を強化する。右図のピラミッド構造で底辺を支える大学などの全学生約50万人は、数理・DS・AIの初級レベルを学ぶ。学部1、2年生が対象だ。ここまでがリテラシーレベルだ。』
『この上の応用基礎レベルは「各専門分野×AI」の教育だ。専門の学びをする学部3、4年生の半分、約25万人を想定する。目を引くのは理工系人材は半分程度にすぎず、保健系や人文・社会科学系での育成も重視されている点だ。ダブルメジャーとして「専門は経営学とDS」などと言えるだけの力を付け、実社会での活躍を最も期待される層だ。その上のエキスパートレベルは大学院生などで、2000人とぐっと数が減る。研究者やその卵としてDS・AIを活用する。最上位のトップレベルは世界と戦うAI先端研究者などで、100人としている。』
『データ分析は多くの数値データから普遍的な真理を導くのが狙いだ。伝統的には統計学を使い、心理学や教育学の調査研究でも行われる。統計学は数学の仲間だ。世の中の現象を1次式で近似する多変量解析には、数学の線形代数が使われる。過去のまとめに適するが、変化の激しい未来の予測手法としては微妙なところだった。一方、AIは多様なツールがあり、未来予測に適する面がある。その一つ、人気のディープラーニング(深層学習)は画像判断や機械翻訳、囲碁などで、その強さが一般社会でも実感されたことで注目が高まっている。
日刊工業新聞2020年5月18日』
社会人のためのデータサイエンス入門|総務省統計局
https://gacco.org/stat-japan/※ 総務省でも、「無料のオンライン学習」をやってるぞ…。




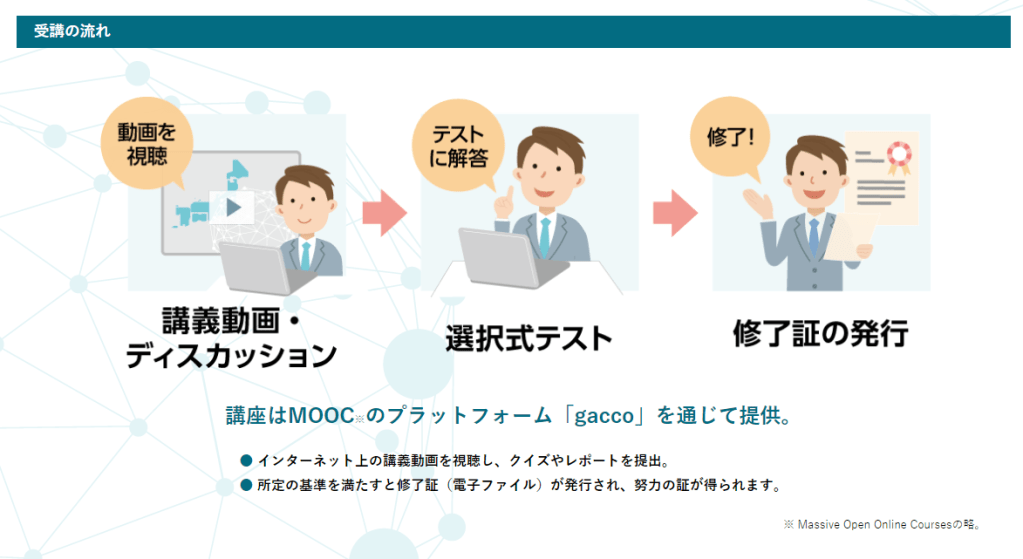
※ むろん、「有料オンライン学習」の講座も、あまたある…。
データサイエンティストのスクール比較・おすすめ講座・コース7選
https://www.bigdata-navi.com/aidrops/1809/データサイエンス独学の書籍、オンライン講座、ブログ50選
https://www.finereport.com/jp/analysis/site/※ にわかにAIにスポットライトがあたり、どの企業でも「AIの活用を図れ!」とか、「AI使って、何かやれ!」とかいう号令が下されるようになった…。しかし、如何せん、そういう「AIが何であるのか」「AIで何かやれる」という「AI人材」なんか、どこにもいない…。いても、数が少なくて、「需要に供給が追いつかない」…。「AI人材」どころか、そもそも「データサイエンス」を分かっている人材(DS人材)すら、数が少ない…。そういうのが、現状だ…。
※ それで、「このままでは、日本企業は、生き残っていけない!」ということで、強力に「政府の尻を叩きにかかった」わけだな…。
※ そういうことで、オレも気にはかけて、若干の資料や画像の収集は、やっていた…。今、フォルダを見ると、どこのサイトからキャプチャしたのかの「データ」までは、保存していなかった…。
※ まあ、いいや…。貼ってしまおう…。出所は、よく分からん…、ネットのどっかに転がっていた…、ということで…。
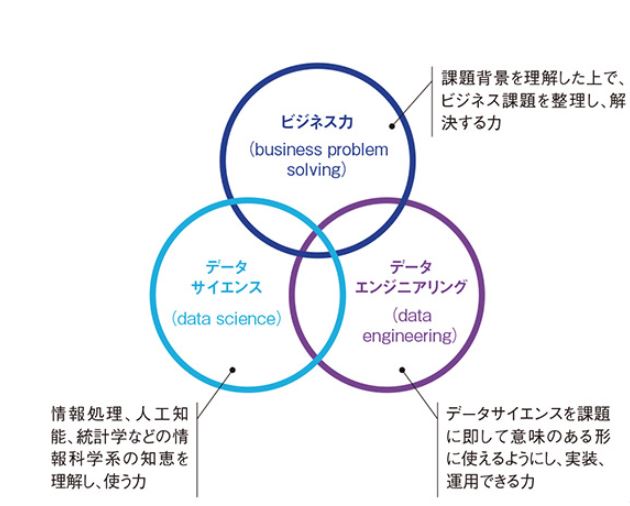
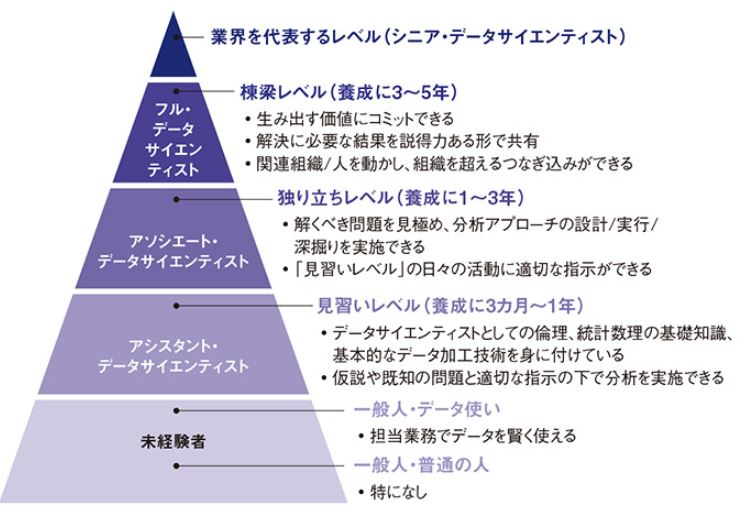
※ 何か新しい分野にチャレンジしてみようと考える時は、
1、文献(紙の書籍、電子データの書籍)で、ざっと感じを掴む。
導入本、初級本、中級本、上級本とあるので、まず「導入本」を2、3冊読んでみる。中には、「マンガで解説する○○」みたいなものもある…。
2、無料の「お試しオンライン学習」を、やってみる…。
3、大体の感じが把握できたら、いよいよ「有料オンライン学習」に取りかかる…。
という段取りで取り組むのが、いいんじゃないか…。
まあ、オレはいつも1で止まっているが…。それも、「導入本」2、3冊読んで「オシマイ」というのが多いな…。
ネットは、玉石混交だ…。中には、「金取り」「詐欺まがい」も混じっている…。そういうものも、回避していかないとな…。Udemyで400コース学んだ黒澤さんがおススメするデータサイエンスコース10選+α
https://zine.qiita.com/products/udemy-datascience/
『──具体的な事例ですごくイメージが沸きました。次に伺いたいのですが、黒澤さん自身、これまで学ばれてきて、データサイエンスにはそもそもどんな知識・スキルが必要だと考えていますか︖また、あわせてそのスキル習得に効果的だったUdemyコースも教えてください。黒澤:データサイエンスに必要なスキルは大きく3つと考えています。
1)数学(微分、線形代数、統計など)
2)プログラミング(Python、R)
3)問題解決力(価値創造する力、論理的思考力など)まず数学についてですが、僕の経験上からもこれがデータサイエンスの学習においては最も重要だと考えています。
というのも、自分自身、Udemyでデータサイエンスを学び始めたころ、数学を学ばなかったことで失敗しているからです。』
『──そうだったのですね。それはどんな失敗だったのですか?
黒澤:正直いうと、もともとプログラミングスキルには自信があったので、PythonやRもすぐに使いこなせて、データサイエンスもできるとおごりがありました。
しかし、実際は、Pythonが使えたとしても数学の理解がないとただチュートリアルを動かすだけしかできません。僕は、データサイエンスを活用した課題解決において重要な「数値予測」か、「カテゴリー予測」かの判断が数学(統計)の知識がなくてできなかったんです。
例えば、手書き文字の画像認識をしたい場合は「カテゴリー予測」を使う。商品の売上シミュレーションをしたい場合は、「数値予測」を使うなど課題に応じて判断しなくてはいけないのですが、それができなかったんです。
数学を学ばずに、機械学習ライブラリを使った⾼度な分析を実⾏しても理解が浅く、チュートリアル以上の事をしようとすると途端に難しくなってしまいました。』
『──エンジニアリング力の素地がある方だからこそ陥ってしまう落とし穴なのかもしれませんね。ただ、「微分・線形代数」については、具体的になぜ必要なのかまだわからないのですが、補足いただけますか?黒澤:微分や線形代数は、機械学習など関数を使った予測モデルの作成に必要になります。機械学習とは、プログラム(機械)にデータを学習させて、予測させることです。予測するためには、実測値と予測値の誤差を最⼩限にさせていくことが必要で、これを「最適化」と言い、微分を使います。
この「最適化」の計算・演算をするためには、画像やExcelで作られた表データなど、すべてのデータを行列の形で数値化する必要があります。この行列を計算するための手段として線形代数が必要になります。さらに、学習させたモデルの精度を確認するために統計が必要になるんです。』
『──なるほど、よく理解できました。では、黒澤さんも特に重要だという数学を学ぶのにおすすめのUdemyコースはありますか?黒澤:「【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 初級編 -」と「【ゼロからおさらい】統計学の基礎」がおススメです。
「【キカガク流】人工知能・機械学習 脱ブラックボックス講座 – 初級編 -」は、板書のように手書きで順を追って説明してくれ、わかりやすく人工知能の仕組みと機械学習の実装に必要な数学(微分と線形代数)を学ぶことができます。さらに得た知識をもとにPythonを使って簡単な機械学習の実装までを4.5時間で経験できるので入門者にはおススメです。』
『「【ゼロからおさらい】統計学の基礎」は、統計の基礎が学べ、統計基礎の鬼門といえる「仮説検証」を中心に理解することができます。また、「アプリの同時起動数」をテーマに統計を使い、「どれだけのユーザーが同時にアプリを起動してもサーバーが落ちずに耐えられるか?」を予測する演習をエクセルを使って行います。』※ 後半は、「宣伝くさい」が、重要なことを言っていると思われる…。こういう、「電子計算機」を使って「機械」に仕事をさせようとする場合、「数学」のある程度の理解は不可欠だ…。なぜなら、「電子計算機」は、しょせんは「計算・演算」しかできないからだ…。そういうものに、「人間の望むような仕事」をさせようとすれば、「数式を組んで」「代入する値(データ)」を与え、「計算・演算」させていくしかない…。それには、「数学」のある程度の知識が前提になってくる…。
-
https://www.nikkei.com/article/DGXMZO55567340T10C20A2FFE000/
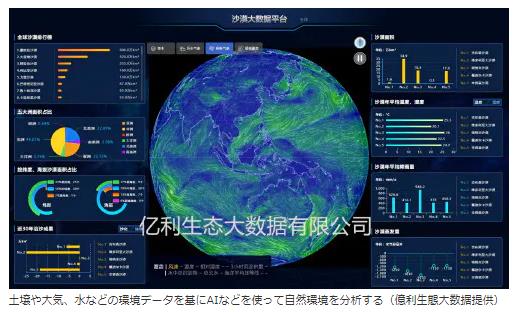
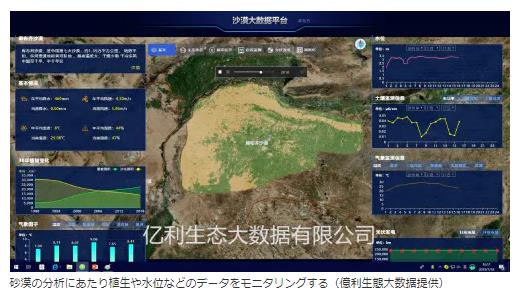
『環境修復とは大自然の自己修復力を利用し、適切な人工的措置を補助的に用いて、生態系が本来持っている環境機能と開発利用などの経済的機能を回復させることを指す。中国では環境修復市場の規模は2017年に2993億元(約4兆8000億円)にまで拡大、2018年には3500億元(約5兆6000億円)になったとみられている。』
『ただし業界には課題も存在する。第一に、プロジェクトの建設と運営という全体的なプロセスの改善。同一の組織がさまざまな環境事業を別々に行っており、運営のことを考慮していない。第二に、データのモニタリングと可視化の必要性。取り組みの成果は主に機関による単発的な評価の中で示され、データ同士が孤立している。第三に、全面調査にかかる時間の短縮。人手による現地でのサンプル採取と検査という従来の調査方法は1~2年もの時間を要する。こうした問題を商機と捉え、「億利生態大数据(Elion Ecological big data)」は2017年に設立された。環境関連のデータサービス企業として、IoT(モノのインターネット)やビッグデータ、人工知能(AI)などの高度技術を用い、環境整備に関するポリシー策定コンサルティング、IoTによる管理、AIによる意思決定支援などを展開する。
同社は環境に特化した監視プラットフォーム「億利生態天眼」を世界で初めて立ち上げた。「山、水、林、湖、田畑、草地、砂漠、観光」といった環境に関する全領域をカバーし、顧客の要望に応じて「リアルタイムモニタリング、環境分析、予測・警報、意思決定支援、緊急対応時の指揮、観光に関する指導」など多岐にわたるソリューションを提供。環境整備の際に行われる全面調査の所要時間を1回につき1~2年から3~6カ月に短縮している。』
『具体的に言うと、億利生態大数据はネットワークに接続されたセンサーから送られる土壌、大気、水など自然環境の構成要素のデータをベースに、衛星データやドローン(小型無人機)で収集したデータ、資源情報データベースなどのデータを組み合わせ、ビッグデータやAIなどを駆使してデータマイニング、データモデリング、データ分析を行う。このうち、ハードウエアの調達や設置、データ収集などの作業は提携企業に任せ、同社は主にデータ統合や分析を担う。同社の鄭利軍総経理によると、将来的には一部のハードウエア企業を買収し、利益率を引き上げることも検討していくという。同社の背後には親会社の「億利集団(Elion)」が控える。億利集団は環境修復分野で30年の歴史があり、長期にわたって環境修復とクリーンエネルギー産業の融合的発展に注力してきた。国連環境計画(UNEP)によると、同集団が30年間で創出した環境資産の価値は5000億元(約8兆円)を超えるという。』
※ こういう風に、「人類の幸福」に貢献できるタネを、多く備えている国だと思う…。
しかし、それも全て「共産党一党支配に貢献する、という価値観」だけに立脚しているのでは、という疑念を拭いきれない点が、残念なところだ…。
-
※ オレが、ほぼ毎日チェックして、参考にしているサイトがある。日頃の感謝を込めて、ここに紹介しておく…。
『北の国から猫と二人で想う事 livedoor版』(nappi10さん)
http://blog.livedoor.jp/nappi11/『兵頭二十八の放送形式 ; 兵頭二十八ファンサイト 半公式』(兵頭二十八さん。「管理人さん」は、別にいるようだ…)
https://st2019.site/?cat=2『東京の郊外より・・・:SSブログ』(マングースさん)
https://holyland.blog.ss-blog.jp/上記タイトルの記事は、兵頭二十八氏のサイトで紹介されていたもので、それを参考に飛んで、元記事を探したものだ…。
前に、「巨大AIチップ」開発成功の投稿を、上げたことがあった…。(『[FT]逆転の発想が生んだ世界最大のAI用チップ』 https://http476386114.com/2019/08/20/ft%e9%80%86%e8%bb%a2%e3%81%ae%e7%99%ba%e6%83%b3%e3%81%8c%e7%94%9f%e3%82%93%e3%81%a0%e4%b8%96%e7%95%8c%e6%9c%80%e5%a4%a7%e3%81%aeai%e7%94%a8%e3%83%81%e3%83%83%e3%83%97/ )

この記事は、その続報にあたるもので、そのチップを使用して、ハード(装置)を開発した…、と言う話しだ。英文記事と、そのグーグル翻訳文を載せておく…。
https://www.technologyreview.com/s/614740/ai-chip-cerebras-argonne-cancer-drug-development/




『A new generation of specialized hardware could make drug development and material discovery orders of magnitude faster.
by Karen Hao
Nov 20, 2019At Argonne National Laboratory, roughly 30 miles from downtown Chicago, scientists try to understand the origin and evolution of the universe, create longer-lasting batteries, and develop precision cancer drugs.
All these different problems have one thing in common: they are tough because of their sheer scale. In drug discovery, it’s estimated that there could be more potential drug-like molecules than there are atoms in the solar system. Searching such a vast space of possibilities within human time scales requires powerful and fast computation. Until recently, that was unavailable, making the task pretty much unfathomable.
But in the last few years, AI has changed the game. Deep-learning algorithms excel at quickly finding patterns in reams of data, which has sped up key processes in scientific discovery. Now, along with these software improvements, a hardware revolution is also on the horizon.
Yesterday Argonne announced that it has begun to test a new computer from the startup Cerebras that promises to accelerate the training of deep-learning algorithms by orders of magnitude. The computer, which houses the world’s largest chip, is part of a new generation of specialized AI hardware that is only now being put to use.
“We’re interested in accelerating the AI applications that we have for scientific problems,” says Rick Stevens, Argonne’s associate lab director for computing, environment, and life sciences. “We have huge amounts of data and big models, and we’re interested in pushing their performance.”
Currently, the most common chips used in deep learning are known as graphical processing units, or GPUs. GPUs are great parallel processors. Before their adoption by the AI world, they were widely used for games and graphic production. By coincidence, the same characteristics that allow them to quickly render pixels are also the ones that make them the preferred choice for deep learning.
But fundamentally, GPUs are general purpose; while they have successfully powered this decade’s AI revolution, their designs are not optimized for the task. These inefficiencies cap the speed at which the chips can run deep-learning algorithms and cause them to soak up huge amounts of energy in the process.
In response, companies have raced to design new chip architectures that are specially suited for AI. Done well, such chips have the potential to train deep-learning models up to 1,000 times faster than GPUs, with far less energy. Cerebras is among the long list of companies that have since jumped to capitalize on the opportunity. Others include startups like Graphcore, SambaNova, and Groq, and incumbents like Intel and Nvidia.
A successful new AI chip will have to meet several criteria, says Stevens. At a minimum, it has to be 10 or 100 times faster than the general-purpose processors when working with the lab’s AI models. Many of the specialized chips are optimized for commercial deep-learning applications, like computer vision and language, but may not perform as well when handling the kinds of data common in scientific research. “We have a lot of higher-dimensional data sets,” Stevens says—sets that weave together massive disparate data sources and are far more complex to process than a two-dimensional photo.
Initially, Argonne has been testing the computer on its cancer drug research. The goal is to develop a deep-learning model that can predict how a tumor might respond to a drug or combination of drugs. The model can then be used in one of two ways: to develop new drug candidates that could have desired effects on a specific tumor, or to predict the effects of a single drug candidate on many different types of tumors.
Stevens expects Cerebras’s system to dramatically speed up both development and deployment of the cancer drug model, which could involve training the model hundreds of thousands of times and then running it billions more times to make predictions on every drug candidate. He also hopes it will boost the lab’s research in other topics, such as battery materials and traumatic brain injury. The former work would involve developing an AI model for predicting the properties of millions of molecular combinations to find alternatives to lithium-ion chemistry. The latter would involve developing a model to predict the best treatment options. It’s a surprisingly hard task because it requires processing so many types of data—brain images, biomarkers, text—very quickly.
Ultimately Stevens is excited by the potential that the combination of AI software and hardware advancements will bring to scientific exploration. “It’s going to change dramatically how scientific simulation happens,” he says.
The chip must also be reliable and easy to use. “We’ve got thousands of people doing deep learning at the lab, and not everybody’s a ninja programmer,” says Stevens. “Can people use the chip without having to spend time learning something new on the coding side?”
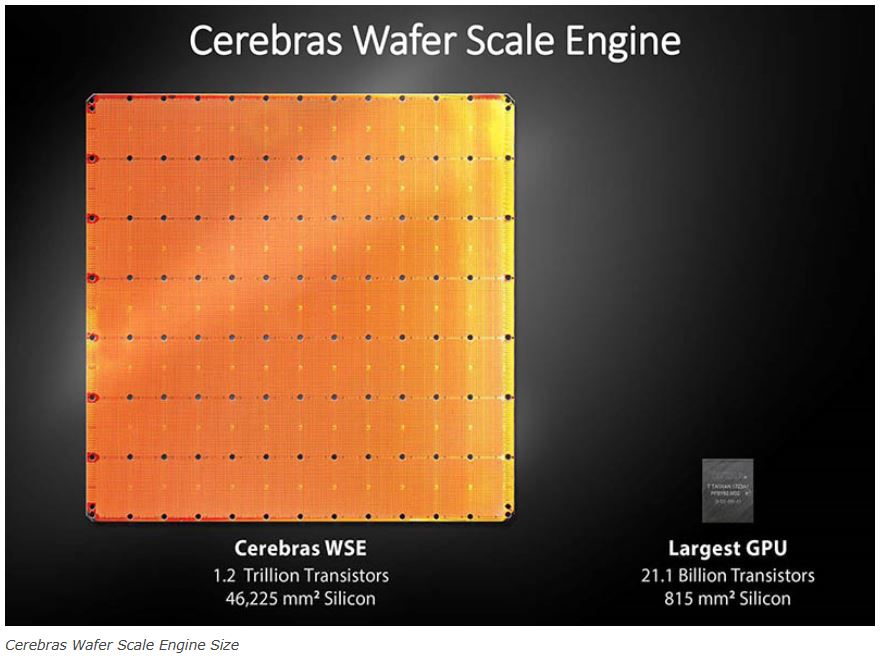
Thus far, Cerebras’s computer has checked all the boxes. Thanks to its chip size—it is larger than an iPad and has 1.2 trillion transistors for making calculations—it isn’t necessary to hook multiple smaller processors together, which can slow down model training. In testing, it has already shrunk the training time of models from weeks to hours. “We want to be able to train these models fast enough so the scientist that’s doing the training still remembers what the question was when they started,” says Stevens.』
『(グーグル翻訳による訳文)
巨大な超高速AIチップが、より良い抗がん剤を見つけるために使用されています
新世代の特殊なハードウェアにより、医薬品開発と物質発見のオーダーを大幅に高速化できます。
よるカレン・ハオ
2019年11月20日シカゴのダウンタウンから約30マイルのアルゴンヌ国立研究所では、科学者が宇宙の起源と進化を理解し、長持ちするバッテリーを作成し、精密ながん治療薬を開発しようとします。
これらのさまざまな問題には、共通点が1つあります。それらは、その規模の大きさのために厳しい問題です。創薬では、太陽系にある原子よりも潜在的な薬物のような分子が存在すると推定されています。人間の時間スケール内でこのような広大な可能性の空間を検索するには、強力で高速な計算が必要です。最近まで、それは利用できず、タスクをほとんど理解できませんでした。
しかし、ここ数年で、AIはゲームを変えました。深層学習アルゴリズムは、一連のデータのパターンをすばやく見つけることに優れており、科学的発見の主要なプロセスを高速化しました。現在、これらのソフトウェアの改善に加えて、ハードウェア革命も視野に入れています。
昨日、Argonne は、スタートアップCerebrasの新しいコンピューターのテストを開始し、ディープラーニングアルゴリズムのトレーニングを桁違いに加速することを約束したと発表しました。世界最大のchi pを収容するコンピューターは、現在使用されている新世代の専用AIハードウェアの一部です。
「科学的問題のために持っているAIアプリケーションを加速することに関心があります」と、アルゴンヌのコンピューティング、環境、ライフサイエンスのアソシエイトラボディレクターであるリックスティーブンスは言います。「膨大な量のデータとビッグモデルがあり、それらのパフォーマンスを向上させることに関心があります。」
現在、ディープラーニングで使用される最も一般的なチップは、グラフィカル処理ユニット(GPU)として知られています。GPUは優れた並列プロセッサです。AIの世界で採用される前は、ゲームやグラフィック制作で広く使用されていました。偶然にも、ピクセルをすばやくレンダリングできるのと同じ特性が、ディープラーニングに適した選択肢となっています。
しかし基本的に、GPUは汎用です。彼らはこの10年間のAI革命に成功しましたが、デザインはタスクに最適化されていません。これらの非効率性は、チップが深層学習アルゴリズムを実行できる速度を制限し、プロセスで膨大なエネルギーを吸収させる原因となります。
これに応えて、企業は AIに特に適した新しいチップアーキテクチャを設計するために競い合っています。うまくいけば、そのようなチップは、ディープラーニングモデルをはるかに少ないエネルギーでGPUよりも1,000倍高速にトレーニングできる可能性があります。Cerebrasは、このチャンスを活かすために飛び上がった企業の長いリストの1つです。その他には、Graphcore、SambaNova、Groqなどのスタートアップや、IntelやNvidiaなどの現職が含まれます。
新しいAIチップを成功させるには、いくつかの基準を満たす必要があります、とスティーブンスは言います。少なくとも、ラボのAIモデルを使用する場合、汎用プロセッサよりも10倍または100倍高速でなければなりません。特殊なチップの多くは、コンピュータービジョンや言語などの商用の深層学習アプリケーション向けに最適化されていますが、科学研究で一般的な種類のデータを処理する場合はパフォーマンスが低下する場合があります。「高次元のデータセットがたくさんあります」とStevens氏は言います。大規模で異種のデータソースを組み合わせたセットで、2次元の写真よりもはるかに複雑です。
また、チップは信頼性が高く使いやすいものでなければなりません。「何千人もの人々がラボでディープラーニングを行っていますが、誰もが忍者プログラマーではありません」とスティーブンスは言います。「コーディング側で何か新しいことを学ぶ時間を費やすことなく、人々はチップを使用できますか?」
これまで、Cerebrasのコンピューターはすべてのボックスをチェックしました。iPadよりも大きく、計算に1.2兆個のトランジスタを備えたチップサイズのおかげで、複数の小さなプロセッサーを一緒に接続する必要がなく、モデルのトレーニングが遅くなる可能性があります。テストでは、モデルのトレーニング時間が数週間から数時間に短縮されました。「これらのモデルを十分な速さでトレーニングできるようにしたいので、トレーニングを行っている科学者は、開始時の質問を覚えています」とStevens氏は言います。
当初、アルゴンヌは抗がん剤の研究でコンピューターをテストしていました。目標は、腫瘍が薬物または薬物の組み合わせにどのように反応するかを予測できる深層学習モデルを開発することです。このモデルは、2つの方法のいずれかで使用できます。特定の腫瘍に望ましい効果をもたらす可能性のある新薬候補を開発するか、さまざまな種類の腫瘍に対する単一の薬候補の効果を予測します。
スティーブンスは、Cerebrasのシステムが抗がん剤モデルの開発と展開の両方を劇的にスピードアップすることを期待しています。これには、モデルを数十万回トレーニングし、さらに数十億回実行して、すべての候補薬を予測することが含まれます。彼はまた、バッテリー材料や外傷性脳損傷など、他のトピックに関する研究室の研究を後押しすることを望んでいます。前者の研究では、数百万の分子の組み合わせの特性を予測して、リチウムイオン化学の代替を見つけるためのAIモデルを開発する必要がありました。後者には、最適な治療オプションを予測するモデルの開発が含まれます。非常に多くの種類のデータ(脳の画像、バイオマーカー、テキスト)を非常に迅速に処理する必要があるため、これは驚くほど難しいタスクです。
最終的に、スティーブンスは、AIソフトウェアとハードウェアの進歩の組み合わせが科学的調査にもたらす可能性に興奮しています。「科学的なシミュレーションがどのように起こるかを劇的に変えるでしょう」と彼は言います。』
※ 「AI兵器」とか、「(攻撃用)AI無人機」などと言う物騒なものでなく、こういう人の幸福に寄与することに役立てて欲しいものだ…。
-
https://www.nikkei.com/article/DGXMZO48751450Q9A820C1000000/
※ 『半導体の集積回路は小型化が続いているが、米カリフォルニア州のスタートアップ企業セレブラス・システムズは、タブレット端末「iPad」の標準タイプの表面積よりも若干大きいサイズのチップを開発した。競合相手である、現状では最大のGPU(画像処理半導体)の56倍に相当する。その消費電力は、データセンターで使われる高さ6フィート(約1.8メートル)強のラック1.5本分に匹敵する。』
『米国の半導体アナリスト、パトリック・ムーアヘッド氏によると、ほとんどの半導体メーカーは「チップレット」と呼ばれるより小さな構成部分をつくり出そうとしてきた。現在の最先端チップはチップレットから組み立てられている。一方、セレブラスはそうした従来のアプローチを捨て、実質的に単一のチップ上にコンピューターのシステムを載せたのだと、ムーアヘッド氏は説明する。』Cerebras Wafer Scale Engine AI chip is Largest Ever https://www.servethehome.com/cerebras-wafer-scale-engine-ai-chip-is-largest-ever/






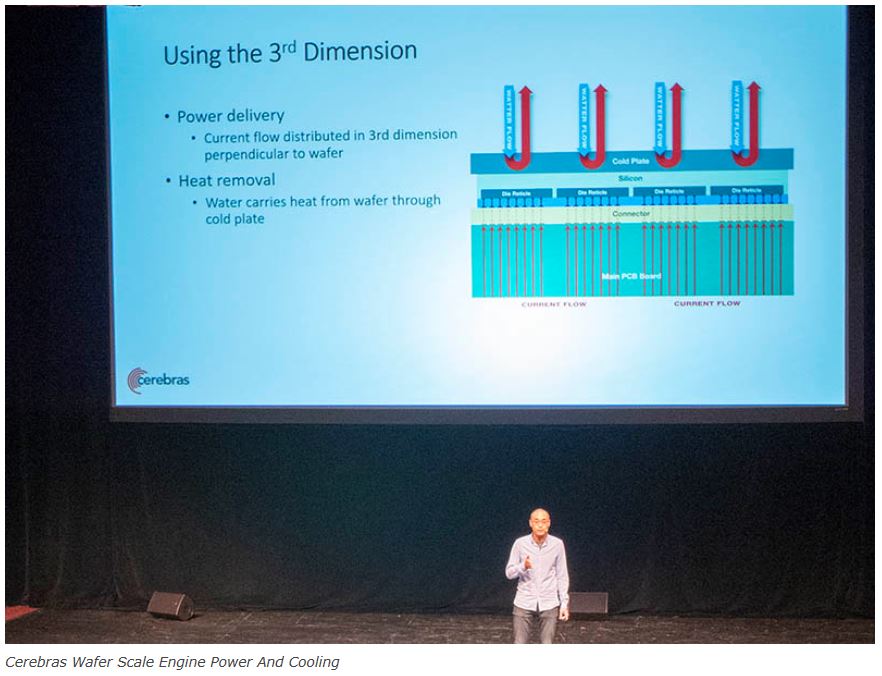
-
結論から言えば、「無いことでは、無い。」
まず、中国側の論者の主張するところを、見てみよう。
【AI開発でなぜ中国が短期間の間に米国の水準に追いつき追い越せたか。その理由は何か。-中国側の論者】
一、中国のAI研究者の数は驚異的なスピードで増えていること。
二、中国は大量のAIデータを生み出していること。データが増えれば、より優れた製品と高度のAIが得られる。 中国人のモバイル決済は米国人の50倍、商品の注文数は米国の10倍。これがAIモデル開発のための重要な参考データになっている。
三、中国は米国のコピー時代を終え、新しい特性を開発し始めたこと。微博、淘宝はツィッターやイーベイよりも機能性の高い製品とサービスを生み出している。
四、中国人はデータのプライバシーを気にせず、道徳上の問題に対する認識が薄い。企業は危険を顧みず、実行することでビジョン実現に専念していること。
五、中国政府は「トライ・アンド・エラー」を認めており、AI企業に巨額の資金援助をしていること。企業は資金調達にかかる時間を短縮でき、より速やかに開発に専念できる。
六、中国は国全体が大胆な冒険精神を持っていること。消費者も企業も政府も中国経済がデジタルへの変換で輝かしい未来を拓けると確信していること。』 http://jbpress.ismedia.jp/articles/-/55053
日本側の論者でも、警鐘を鳴らす論稿は、出ている。次は、宮崎正弘氏の書評だ。本の宣伝と受け取られるとイヤなんで、あえて書名は伏せておく。興味のある人は、リンクで飛んで、自分で確認してくれ。
『半導体もAIも半熟過程の中国が、しかし最先端の米国と伍すことが可能なのは、AIが経験工学ではないからだ。
兵藤氏は独自の情報網から、そう予測されるのだ。
固定電話時代からいきなり携帯時代に突入した中国は、消費においても、現金からカード時代をこえて、いきなりスマホ決済時代に突入したように、設計図とソフトを米国から盗み出して、見よう見まねの自給体制を確立し、ファーウェイが世界の奥地で使われているように、世界を席巻できる。
悪夢が現実、まだ中国に夢を描いて出て行ったAIならびIT産業は、いずれ米国が仕掛ける新ココムによって制裁の対象にさえなる。』 http://melma.com/backnumber_45206_6770403/要は、中国ではプライバシーなんかに考慮を要せず、好きなだけ個人の情報を収集でき、「ビッグデータ」を揃えられる、ってことだ。
ジジイあれこれの投稿でも上げておいた( https://http476386114.com/2018/12/07/%e3%82%a2%e3%83%a1%e3%83%aa%e3%82%ab%e3%81%af%e3%80%81%e3%83%95%e3%82%a1%e3%83%bc%e3%82%a6%e3%82%a7%e3%82%a4%e3%82%92%e6%bd%b0%e3%81%99%e3%81%a4%e3%82%82%e3%82%8a%e3%81%aa%e3%81%ae%e3%81%8b/ )が、現AIは、単なる「行列データ」の変形・演算に過ぎない。結局、どれだけ多量の質の高い「行列データ」を揃えられるか、の勝負になっているんだよ。この点で、中国には、優位性がある。次に、無人機による攻撃の現状を、見てみる。
まず、米軍の無人機攻撃からだ。

悪名も高い米軍のMQ-9だ。「リーパ-(死神)」とか言う、ニックネームがついている…。 
こっちは、MQ-1(プレデター 捕食者)だ。ミサイルが、見えてるな…。 


こういうもので、次々と中東やアフガンでテロリスト(と、アメリカが称する勢力)を、攻撃して来たわけだ…。
そして、その操縦の様子は、次のような感じのものだ…。


空調の効いた部屋で、画面を見ながら操縦・攻撃し、任務が終われば、サッパリとシャワーを浴びて、日常生活を送る…、というわけだ。無人機には、カメラが積んであり、衛星回線を通じて画像は、遠く離れたアメリカの無人機用の空軍基地まで送信され、その画像を見ながらこちらのコントローラーからの操縦命令も、衛星回線を通じて無人機側に送られる、というわけだ。仕組みとしては、プレステでオンラインゲームをやるのと、殆んど変わらない…。
むろん、問題が無いわけでは、無い。人間が目視で攻撃目標を捕捉するのと異なり、あくまで積んでるカメラからの映像で判断する…。それを衛星回線でやり取りするわけだから、遅延・送受信不良の問題はつきまとう…。誤爆で、民間人が巻き込まれる事例が多く生じて、厳しい批判にさらされた…。オバマ政権も、末期には、中東やアフガンでの無人機攻撃に対する中止命令を、出さざるを得なかった…。
ただし、無人機の開発自体を中止したわけではない。現在も、着々と開発中だ…。まだ、実戦配備はされていないようだが、開発中のものを紹介しておく…。


こっちは、X-47Bだ。 次に、中国の無人機開発の現状を見る。

軍事パレードに登場したものだ。胡錦濤さんのようだな…。ミサイルのようにも見えるが、「中国 無人機 パレード」でヒットした画像なんで、無人機なんだろう…。その数に、驚くな…。 
なんか一見すると、茶色い地面にラジコン模型機をならべたようにしか見えないが、どうしてどうして、同時に自律の編隊飛行の世界記録を打ち立てた(米軍の記録を、超えた)という記念すべき画像なんだよ。 中国・軍事用ドローン119機「集団飛行」に成功…米軍の記録を抜く
https://roboteer-tokyo.com/archives/9159


虹彩-5、と呼ばれているものだ。まあ、MQ-1のソックリさんだな…。 
翼竜と呼ばれているものだ。ミサイルの登載が可能のようだな…。 
利剣と呼ばれているものだ。X-47のソックリさんだな…。 
BZK005と称されている偵察機だ。先般、尖閣付近に飛んできて、防空識別圏に侵入したんで空自がスクランブルをかけた…、という事案があったろう。それが、これだったと言われている。 こういう風に、画像を見る限り、中国は着々と無人機開発のピッチを上げているように見受けられる…。それが何故可能なのかという考察だが、中国側の論者が言うようにAI開発における優位性、だけではないようだ…。
と言うのは、上記画像からも見て取れるように、米軍機のソックリさんがあまりに多い…。どうやってその設計図を手に入れているのか…。
むろん、米軍はあちこちの戦線に無人機を投入しているから、敵側に鹵獲されてしまう、という事案も生じる…。
『(※ 2009年)九月十三日、米軍がアフガニスタンで使用している無人攻撃機の一機が制御不能に陥り、カザフスタンや中国方面に向かう事故が発生。米軍はすぐさま、有人戦闘機を発進させ、無人機を追尾し、ミサイルで撃墜して事なきを得た。 米軍は昨年、中国やアフガン国境地域を偵察中にプレデター機を墜落事故で失っている。この墜落地点が中国国境から二十キロ程度だったことから、米軍内では「中国に機体を持ち去られた可能性もある」と懸念されていた。 実際、米誌ディフェンス・ニュースでは今年八月、中国軍がすでに米機をコピーして無人機開発に乗り出していると伝えている。同誌によれば、昨年十一月、広東省珠海で開催された航空ショーで明らかに米軍機を模倣したと見られるデザインの無人機モデルが展示されたという。これらを受け、米軍は今回、撃墜という強硬措置を取ったとみられる。』
https://www.fsight.jp/5232この例では、有人機で撃墜して事なきを得たようだが、最近でもイラン側に無傷で鹵獲され、すぐさま中国が調査団を送った、という記事を読んだぞ。イランと中国は、反米という点で利害が一致してるんだよね。
それだけでなく、アメリカは中国がハッキングや例のスパイチップなんかで、軍事機密情報を盗んでいる…、と疑っている。ファーウェイ潰しも、こういうAI・無人機絡みで捉える必要があるだろうな…。
中国は、無人機を開発・実戦配備しているだけではない。中東やアフリカの独裁的な国々に、無人機を売り込んでいるんだよ。兵器ビジネスで稼いでもいるんだ。
【中国、各国へ無人機の売り込み】
中国がサウジで無人攻撃機の製造修理へ
https://holyland.blog.so-net.ne.jp/2017-03-29イエメンで中国製無人機が反政府指導者を爆殺―専門家「商機到来」
https://news.goo.ne.jp/article/recordchina/world/recordchina-RC_651222.html中国無人機の脅威(※ 5年前の記事)
https://plaza.rakuten.co.jp/foret/diary/201307040000/中国製無人機「翼龍」 アラブ、ウズベキスタンに輸出(※ 6年前の記事)
https://www.excite.co.jp/news/article/Searchina_20121116047/しかしまあ、日本が平和ボケしている間に、世界は遙か彼方の遠い方に、行ってしまったんだなあ、というのがジジイの感想だ…。