大量の火傷患者が発生したとき、そのトリアージをさせるAI…。
https://st2019.site/?p=21377
『Alison Bath 記者による2023-8-10記事「Army project uses AI to develop better diagnostic tools for combat-related burn injuries」。
大量の火傷患者が発生したとき、そのトリアージをさせるAIの開発が進んでいる。
※これは将来の核被弾を考えたとき、必須の技術だよ。』
大量の火傷患者が発生したとき、そのトリアージをさせるAI…。
https://st2019.site/?p=21377
『Alison Bath 記者による2023-8-10記事「Army project uses AI to develop better diagnostic tools for combat-related burn injuries」。
大量の火傷患者が発生したとき、そのトリアージをさせるAIの開発が進んでいる。
※これは将来の核被弾を考えたとき、必須の技術だよ。』
ソフトウェアの中にある、敵ハッカーに対する脆弱性を、AIが自動的に発見してくれる…。
https://st2019.site/?p=21375
『AFPの2023-8-9記事「White House offers prize money for hacker-thwarting AI」。
ソフトウェアの中にある、敵ハッカーに対する脆弱性を、AIが自動的に発見してくれる。そのようなAIを開発してくれた者に、1850万ドルを出そうじゃないか、とホワイトハウスの科学技術政策部長が呼びかけている。
もし弱小スタートアップがこのコンペに参加しにくいのであれば、DARPAが700万ドル支援してくれるそうだ。』
生成AIの性能、百度が首位に 新華社系が比較
https://www.nikkei.com/article/DGXZQOGM045QC0U3A800C2000000/
『【北京=多部田俊輔】中国国営新華社傘下でネットサービスを提供している新華網は文章などを自動で作る生成AI(人工知能)の性能比較結果をまとめた。中国のネット規制対応の経験が豊富な中国ネット大手の百度(バイドゥ)のサービスが、米オープンAIの「Chat(チャット)GPT)」を上回りトップだった。
新華網が性能を比較したのは、百度の「文心一言(アーニーボット)」、オープンAIの「GPT-3.5」、音声…
この記事は会員限定です。登録すると続きをお読みいただけます。』
インドネシア、生成AI市場が拡大 失敗恐れぬ文化後押し
アジアVIEW
https://www.nikkei.com/article/DGXZQOGM249JH0U3A720C2000000/
『インドネシアの国内総生産(GDP)は日本の4分の1の規模だが、スタートアップの数は4倍を超える。起業家精神に富むこの国で生成AI(人工知能)の市場が拡大している。
調査会社の独スタティスタによると、インドネシアにおける2023年の生成AIの市場規模は、20年の10倍を超える2億1260万ドル(約300億円)に達する見通しだ。東南アジアで最も高い。年率30%近い勢いで成長し、30年には11億450…
この記事は会員限定です。登録すると続きをお読みいただけます。』
『ジャカルタの日本企業の駐在員はインドネシアでスタートアップが増えている背景としてリスクへの寛容さを挙げることが多い。失敗を恐れず、新しい知見や技術を取り入れる進取の気風が根付いている。
日本貿易振興機構(ジェトロ)ジャカルタ事務所の町井健太郎シニアディレクターはチャットボットが金融や電子商取引(EC)の分野で広く利用されていると解説する。「映像制作や医療従事者向けの情報提供などより専門的な生成AIのサービスの展開もみられるようになった」と話す。
一方、生成AIには偽情報や個人情報の拡散が懸念としてつきまとう。インドネシアでは取り組みが企業任せになっているのが現状で、市場の拡大には官民のルールづくりも喫緊の課題だ。
(ジャカルタ=地曳航也)』
AIが生成した文章を検出するOpenAI製ツール、精度が低く公開停止に
https://pc.watch.impress.co.jp/docs/news/1519185.html
『 OpenAIは20日、AIが書いた文章かどうかを判別するAIツール「AI classifier」について、精度の低さを理由に提供を停止すると発表した。
AI classifierはOpenAIが1月に公開したAIツール。入力された文章をAIが分析することで、人間によって書かれたものか、AIによるものかを推測できるとされていた。
同社では、現在もフィードバックを取り入れながら、テキストにおけるより効率的な検出技術の開発を進めているほか、音声や映像のコンテンツについてもAIが生成したものかどうかを判別できるような仕組みを開発し提供していくと声明を出している。 』
米政府「AI製」明示で合意 GoogleやOpenAIなど7社と
https://www.nikkei.com/article/DGXZQOGN212790R20C23A7000000/
『米政府は21日、オープンAIやグーグルなど生成AI(人工知能)の開発を手掛ける米主要7社と、AIの安全性を確保するルールの導入で合意したと発表した。AIによって作られたコンテンツに「AI製」と明示させるシステム開発などが柱となる。
「Chat(チャット)GPT」など高度な生成AIが急速に普及するなか、適正な利用や悪用の防止を巡る法整備では欧州連合(EU)が先行する。米国の場合、現状では法的拘束力…
この記事は会員限定です。登録すると続きをお読みいただけます。』
『多様な観点からニュースを考える
※掲載される投稿は投稿者個人の見解であり、日本経済新聞社の見解ではありません。
浅川直輝のアバター
浅川直輝
日経BP 「日経コンピュータ」編集長
コメントメニュー
ひとこと解説 記事の内容からすると、米政府は企業の自主性を尊重しながらAI活用を統制する「共同規制」あるいは「ソフトロー」に近いアプローチを取るようです。その柱は情報開示(disclosure)で、ステマ広告規制などと同じく、情報発信に関わる主体の透明性を高めることを重視しています。公正性を何より重視する米国らしい規制で、欧州が指向するハードロー路線とは異なる道を示したと言えるでしょう。
2023年7月21日 21:59』
【詳説】Attention機構の起源から学ぶTransformer
https://agirobots.com/attention-mechanism-transformer/
※ こちらこそ、ありがとうございました。大変参考に、なりました…。
※ おかげで、昨日の吾に、今日は少し勝つことが、できましたぞ…。
※ 今日は、こんな所で…。






















『023年2月10日
みなさんは、Transformerについてどのようなイメージを持っていますか?
最近は、BERT、GPTなどのTransformerベースのモデルが目を見張るような成果をだしているので、それらを想像する方が多いかと思います。これらはTransformerの発展形ですが、Transformerの起源のほう、即ちAttentionを想像された方もいるかもしれません。この記事で説明していくのは、Transformerの起源のAttention機構についてです。BERTやGPTについては、別の記事で解説できればと思います。
Transformerの論文タイトル「Attention Is All You Need」からTransformerの成功はAttention機構にあることが推測できると思いますが、その通りで、Attention機構なしにTransformerを語るのは難しいです。本記事では、Attention機構に焦点を当て、古くから行われている認知科学に基づく研究なども紹介しながら説明していきます。Transformerの解説だけであれば、もっと短くできるのですが、Attentionに焦点を当てたので、記事が長くなってしまいました。純粋にAttention機構について興味がありましたら、最後までお読みいただけると嬉しいです。YouTubeに解説記事をアップしているので、動画で学びたい方はぜひご覧下さい。
少しでも早くTransformerについて要点を知りたいという方向けに短めの記事も出していますので、知りたい内容がAttention機構についてなら、今開いているこの記事を、Transformerについてなら以下のリンクの記事をお勧めします。
Transformerについて本質を分かりやすく解説!
皆さんこんにちは! 去年(2022年11月)に発表されたChatGPTの話題が尽きない今日この頃、ChatGPTで使われている重要な技術の1つであるTransformerについて、興味を持った方は沢山 ...
本記事の説明動画も公開しています(以下)。ぜひご活用いただければと思います。
この内容に関して、解説スライドも公開しているので、有効活用していただければと思います。
Attentionの基礎からTransformerの入門まで from AGIRobots
本記事の構成について説明します。
まず初めに、認知科学の研究と絡めてAttentionという考え方が知能の実現にどう関わっているのかを説明します。この内容を理解することで、Transformerで突如として知れ渡ったAttention機構が、天才たちによる100%の突発的な発想というわけではないことをご理解いただければと思います。
次に、Transformerが登場する以前のAttention機構について、再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)で見られた既存モデルを紹介します。ここでは、Transformerの論文「Attention Is All You Need」でAttention機構が一般化される以前から、Attention機構の考え方が取り入れられていたことをご理解いただければと思います。
そして、ここまで内容をベースとしてTransformerで使用されているAttention機構について説明をします。
本記事を通じて、古くから考えられてきたAttentionが、近年大きな成功を収めるに至るまでの変遷をご理解いただけるのではないかと思います。
目次[表示]
認知科学と注意(Attention)
ニューラルネットの応用に興味がある方だと、認知科学に馴染みがない方が多いかもしれません。ですが、Attention機構が昨今の深層学習で高精度を叩き出す中、本来、注意(Attention)とは何か、について私たち人間の知のメカニズムから考える認知科学的なアプローチは、深層学習においてAttention機構がなぜ重要なのか、なぜ高精度を出せるのかを直感的に理解する上で有益なものとなるはずです。
認知科学
認知科学とは人間の脳や心といった知の働きと性質を理解しようとする研究分野で、心理学や人工知能、神経科学、哲学など、様々な学問をまたぐ学際的な構造をしています。なかでも、人工知能分野は知能を作るアプローチから古くから認知科学と関わりを持って発展しています。
ウィケンズの情報処理モデル
認知科学では、知のメカニズムを論理的かつ段階的に表現するために、その認知過程をモデル化します。モデル化の範囲は、感覚入力から運動出力に至るまでの知的システムのプロセス、アルゴリズム、過程に至ることが一般的です。
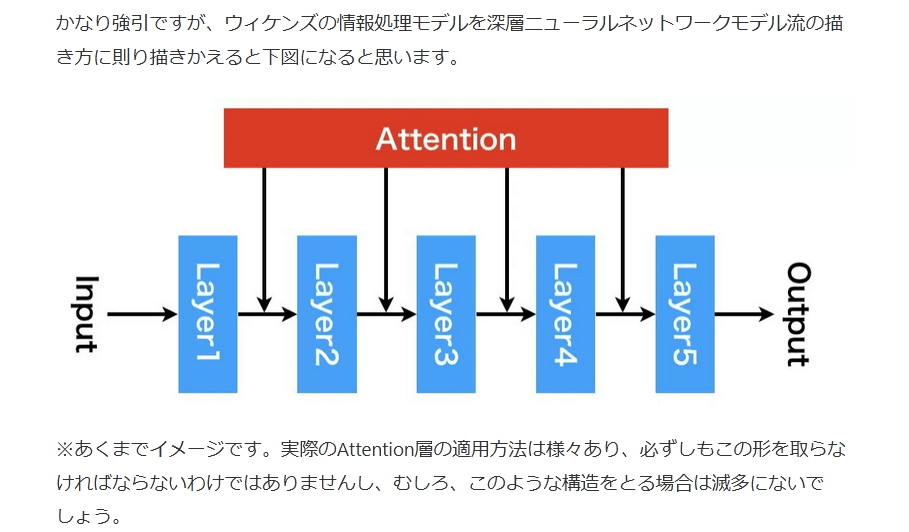
ここでは、心理学者のウィケンズが提案した、ウィケンズの情報処理モデル(下図)について紹介します。これは多くの支持を得ている認知モデルで、また、Attention機構とも大きな関連があります。
ウィケンズの情報処理モデルは、感覚入力から運動出力に至るまでのプロセスを、左から順番に、感覚処理、知覚、記憶・認知、反応選択、反応実行という段階に分け、各々に注意資源から何らかの処理を受ける構造をしています。
特に、注意資源に注目してください。それぞれの項目に何らかの注意(Attention)の矢印を向けていますが、なぜ注意を導入したと思いますか?
ウィケンズの情報処理モデルにおいて、注意とは「特定の対象に感覚や意識を集中させることで、不必要な情報を排除、必要な情報を選択し、限りある知的資源を効果的に配分するもの」という位置付けになっています。
私の解釈ですが、我々の知には空間・時間的に限りがあるので、限りある知を効率的かつ合理的に利用するために導入したのではないかと考えています。
無意識的な注意(Attention)
日本語に、「注意を向ける」という表現があります。これは、特定の物事に注目をすることです。それはまさに注意の働きを意図的に利用したものです。一方で、気づいたら特定の物事を注視していた、みたいに「注意」は無意識的に調節されるのが一般的です。ここでは、無意識的な注意として視覚的注意と聴覚的注意を紹介します。
[視覚的注意]
街を歩いていて看板に書かれた文字を読む行為が可能なのは視覚的注意の為です。まず視覚情報の中から、看板に集中を向けて、その中の文字を認識し理解する一連のプロセスですが、誰でもできますよね。
[聴覚的注意]
カクテルパーティ効果をご存じでしょうか?こでは、騒がしい環境下でも自分と会話している相手の声を認識し、理解することができるというものです。会話相手の声を選択的に選ぶことで、この能力が実現しているものと考えられます。
注意(Attention)の可能性
認知科学と注意の説明の最後に、高度な知能と注意の例を考えてみましょう。我々の高度な知能と言うと、私は真っ先に会話を思い浮かべます。会話は、自分の考えていることを相手に伝えるための重要なインタフェースです。自分の考えていることを言葉にする際に、頭の中にあるあらゆる思考を注意資源をもちいて、取捨選択と順位付けしていますよね?
あれ?会話に限らず、私たちの思考そのものが注意によって成り立っているのでは?と思った方!鋭いと思います。
このように、注意は高度な知能の本質ではないでしょうか?
〈これだけは覚えておこう〉
認知科学におけるウィケンズの情報処理モデルに代表されるように、注意(Attention)は古くから重要な機能を担っていると考えられています。
深層学習と注意(Attention)
注意(Attention)が古くから重要な概念として考えられてきたことをご理解いただいたところで、ここからは、深層学習における注意に話をシフトさせていきます。
深層学習
深層学習とは深層ニューラルネットワーク(Deep Neural Network:DNN)の学習を扱うもので、ディープラーニングとも呼ばれます。深層学習は、近年、驚異的なスピードで成長し、機械学習の主流となっています。
深層学習は何段階ものニューロン層(Layer)を重ねることで階層的に特徴抽出をしており、層数は多いものだと1000層以上になります。複雑なものだと、複数の層をまとめてモジュールを構成し、そのモジュールを何層も重ねているものもあります。具体例として、GoogLeNetの構造を如何に示します。
GoogLeNetの論文「Going Deeper with Convolutions」より引用
かなり強引ですが、ウィケンズの情報処理モデルを深層ニューラルネットワークモデル流の描き方に則り描きかえると下図になると思います。
※あくまでイメージです。実際のAttention層の適用方法は様々あり、必ずしもこの形を取らなければならないわけではありませんし、むしろ、このような構造をとる場合は滅多にないでしょう。
この図ではAttention機構に入力がありませんが、実際に深層学習で使用する際は、さまざまな入力や学習パラメータをもつ機構として実現されます。
上図のようなAttention機構を持つネットワークを考えた場合、このAttention機構の機能はどういったものになるでしょうか?
少し考えてみましょう!
さまざま考えられると思いますが、ウィケンズの情報処理モデルの注意の役割に則ると、前の層が出力した情報において、注目すべき情報を通過させ、注目すべきでない情報を堰き止めるような、ゲート的役割を担い、次の層に入力される情報に変換しているかもしれません。
また、それぞれの層を俯瞰して、より合理的にネットワークが機能するよう指示しているかもしれません。
このような機能を実現しているとしたら、深層学習の性能がグッと上がるかも!って思いませんか?
実際に、Attention機構によって深層学習の精度は大きく上がります。以下に深層学習におけるAttention機構の概要を箇条書きで示します。
今まで深層学習で中心的存在を示してきたCNNやRNNに並ぶ3つ目の画期的なアーキテクチャ。主な使い方は以下の2つ。
CNNやRNNにAttention機構を導入する
完全にAttentionベースのモデルにする(Transformerなど)
コンピュータビジョンや自然言語処理などの多種多様なタスクに対して最先端の性能を示した(SOTAを達成!とよく言われる)
追々説明するTransformerが大いに関係している
解釈可能性の向上
これは結構重要で、近年重要視されている解釈可能なAI(XAI)に関連あり
何らかの方法でAttentionを可視化することでニューラルネットワークが何処に注目しているか、なぜ、その出力結果となるのかに関して情報を与えてくれる
以降の章では、これらについて説明していきます。
Attention機構の起源
Attention機構というのは、CNNやRNNに並ぶ3つ目の機構として紹介されることが多いですが、その起源はCNNやRNNと強い関わりを持っています。というのも、Attention機構として一般化される以前の、Attention機構に似たメカニズムは、CNNおよびRNNの両分野でみられます。具体的には、CNN分野においてはSENet、RNN分野においては語順が考慮できるSeq2Seqです。これは、Appendix的な内容ですが、Memory Networkというものもあったりします。
そこで、本章では、RNNおよびCNNの基礎的な内容から説明し、語順が考慮できるSeq2Seq(以下:Seq2Seq+Attention)とSENet、Memory Networkについて解説していきます。
RNNの発展とAttentionの起源
Attention機構の起源を説明するとき、RNNとCNNのどちらから説明するか迷いましたが、RNNから説明することにします。
RNNの基礎
RNN(Recurrent Neural Network: RNN)とは、内部に再帰的な構造を持つニューラルネットワークで、気温変動、言語処理といった系列的な情報の識別、推論に使用されます。
再帰構造を持たないニューラルネットワークで系列データを扱おうとすると、時刻t−nから時刻tまでの入力情報をすべて一括で与える必要があるなど扱いにくくなりますが、RNNでは内部の状態を次時刻に伝播させる再帰構造により、逐次的な入力環境において、時間依存の特徴を学習できます。
RNNに関する詳しい内容は以下の記事を参考にしていただければと思います。
[keni-linkcard target=”_black” url=https://agirobots.com/lstmgruentrance-noformula/]
ここでは、Seq2Seqと呼ばれる系列モデルにAttention機構を追加したモデルについて理解できるように、その基礎知識として、RNNの表記、RNNの種類、Encoder-Decoderについて解説します。
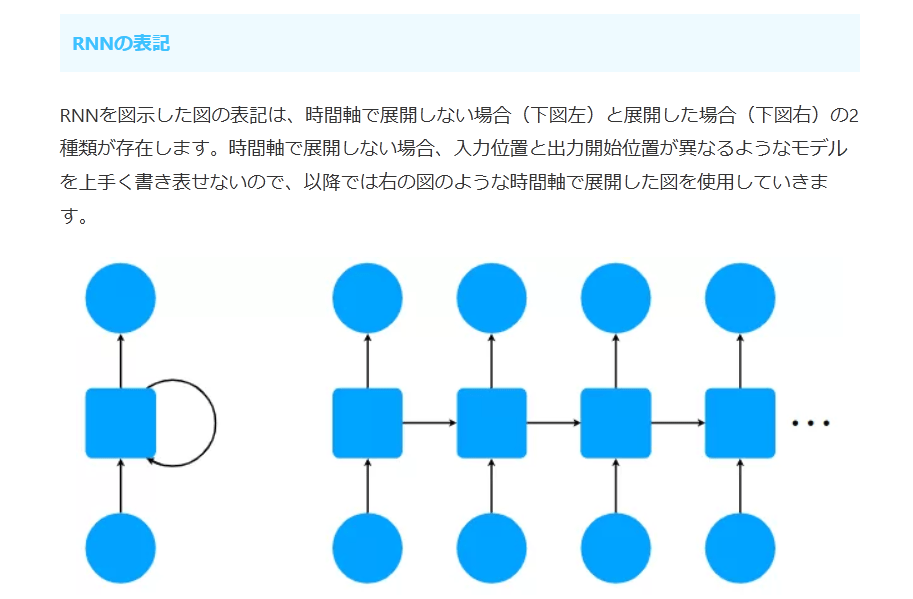
RNNの表記
RNNを図示した図の表記は、時間軸で展開しない場合(下図左)と展開した場合(下図右)の2種類が存在します。時間軸で展開しない場合、入力位置と出力開始位置が異なるようなモデルを上手く書き表せないので、以降では右の図のような時間軸で展開した図を使用していきます。
RNNでは、中間層に使用されている再帰層として何を使うかによって、表現能力が変わります。最も単純なものだと、入力層や出力層で使用するようなニューロン層を使いますし、複雑なものだとLSTM(Long Short Term Memory)、GRU(Gated Recurrent Unit)、SRU(Simple Recurrent Unit)などを使用することもあります。
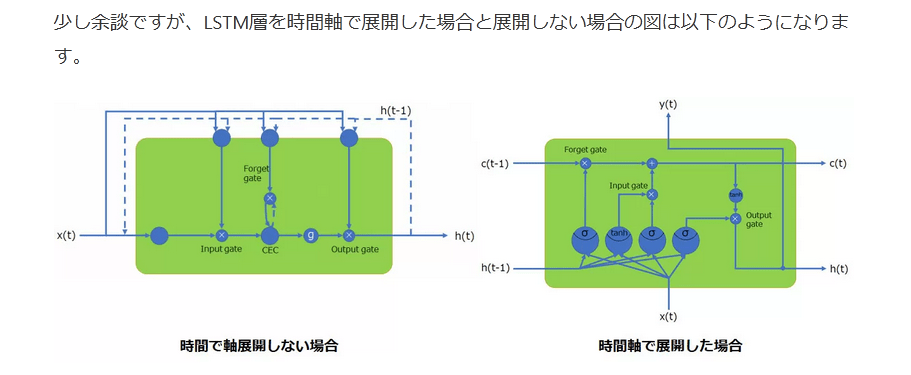
少し余談ですが、LSTM層を時間軸で展開した場合と展開しない場合の図は以下のようになります。
詳しく知りたい方は、以下の記事をご参考ください。
直感で理解するLSTM・GRU入門 - 機械学習の基礎をマスターしよう!
当記事では数式を使わずに、LSTMとGRUのエッセンスを直感で理解できるように説明します。同様の説明をYouTube動画にアップしているのでぜひご活用ください! 当サイトはTwitterやYouTub ...
動画でも説明しています。
RNNの種類
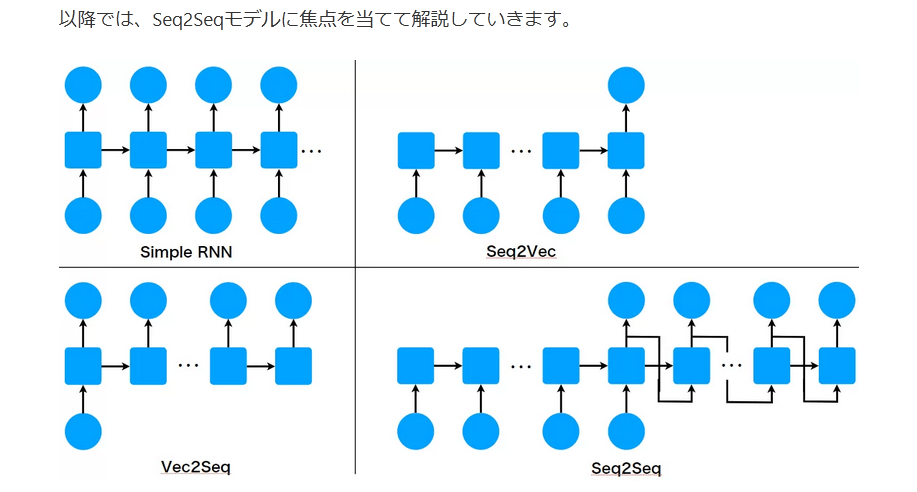
ここでは、入出力形式に注目したときのRNNの種類は下図のように4つに分けることができます。
Simple RNN:系列(シーケンス)を入力として受け続け、同時に、出力として変換後の系列(シーケンス)を出力し続ける
Seq2Vec:有限長の系列(シーケンス)を受け取り最後にベクトルを出力する
Vec2Seq:ベクトルを入力として受け取った直後から、有限長の系列(シーケンス)を出力する
Seq2Seq:有限長の系列(シーケンス)を受け取って有限長の系列(シーケンス)を出力する
どの種類のRNNを使用するかは、扱う対象に依存します。
例えば、気温情報をリアルタイムに受け取り、次の時刻の気温を予測する場合はSimple RNN型が相応しいですし、今日一日の気温変化を受け取って快適度を出力させたい場合はSeq2Vec型が相応しいと思います。Vec2Seqなら快適さの指標を受け取って、相応しい気温辺変化を出力させることができるかもしれません。Seq2Seqは機械翻訳を中心に使用されるモデルで、日本語を入力して英語を出力するといった使い方が可能です。
以降では、Seq2Seqモデルに焦点を当てて解説していきます。
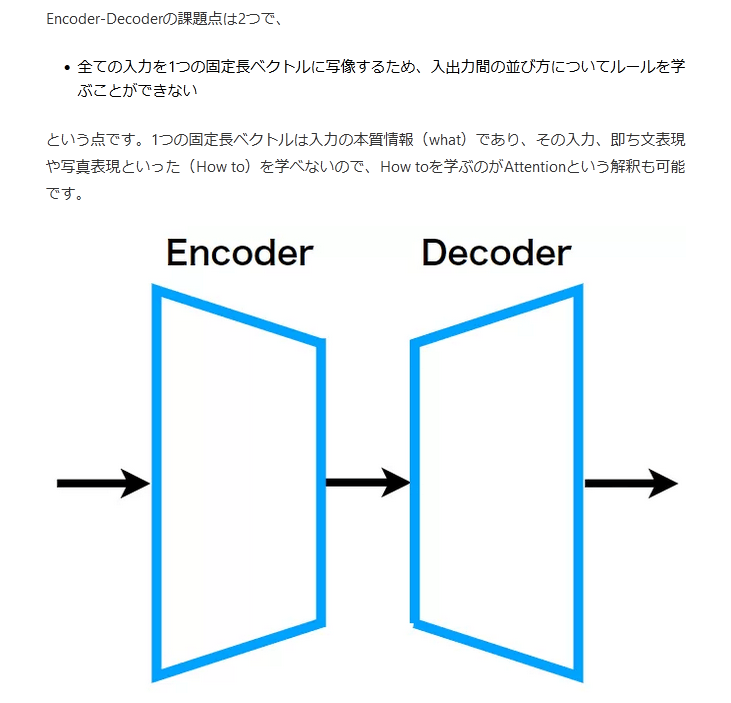
Encoder-Decoderモデル
Seq2Seqの詳しい内容に移る前に、ちょっとした紹介ですが、Seq2Seqモデルの設計はEncoder-Decoderという設計思想に基づいています。この、Encoder-Decoderという設計思想に基づいたものとして、他にAutoEncoderがあります。
Encoder-Decoderモデルとは、かなり抽象度の高い設計思想ですが、前半のEncoderで一般的には入力より小さい特徴空間の固定長ベクトルに圧縮し、後半のDecoderでその固定長ベクトルを入力として受けて復元させる使い方をします。
キーとなるのは入力次元より小さな特徴空間へ写像する際に、必要のない情報を捨てることを学ぶ点です。
例えば、AutoEncoderを使って、出力画像を入力画像に近づけるように学習させた場合、重要度の低いノイズ情報は切り捨てるように学習が行われ、ノイズ除去に使えるモデルを得ることができます。
Encoder-Decoderの重要なポイントは、入力より小さい特徴空間の固定長ベクトルに圧縮するときに、本質的でない情報を捨てる学習をすることです。
長所:本質的な情報を抽出するのが得意
短所:具体的な入力に対して、具体的な出力を変えることが苦手
この機能は、特徴抽出という側面では優れているかもしれませんが、様々な言い回しが可能な文章表現など、本質が同じ(=符号化したベクトルが類似)でも、入力された文章表現によって、翻訳を変化させたいといったタスクは実現が難しくなると考えられます。
このような理由から、Attentionを導入する動機が生まれたといえます。まさに、具体的な文章入力から本質的な特徴を抽出することが得意なSeq2Seqに、さまざまな言い回しなど具体的な表現の文章を出力できるよう、Attentionっぽいメカニズムを加えるという話に繋がります。詳しい話は以降のセクションで説明します。
Encoder-Decoderの課題点は2つで、
全ての入力を1つの固定長ベクトルに写像するため、入出力間の並び方についてルールを学ぶことができない
という点です。1つの固定長ベクトルは入力の本質情報(what)であり、その入力、即ち文表現や写真表現といった(How to)を学べないので、How toを学ぶのがAttentionという解釈も可能です。
Seq2Seq
seq2seqはEncoder-Decoderモデルの1つで、自然言語や音声などの系列データを対象として、入力された系列情報を別の系列情報に変換するモデルです。代表的な用途は機械翻訳です。機械翻訳というのは、「This is a pen.」を「これはペンです。」に翻訳することです。ここでは、今紹介した英語から日本語への翻訳を例に説明していきます。
Seq2Seqによる機械翻訳とその課題
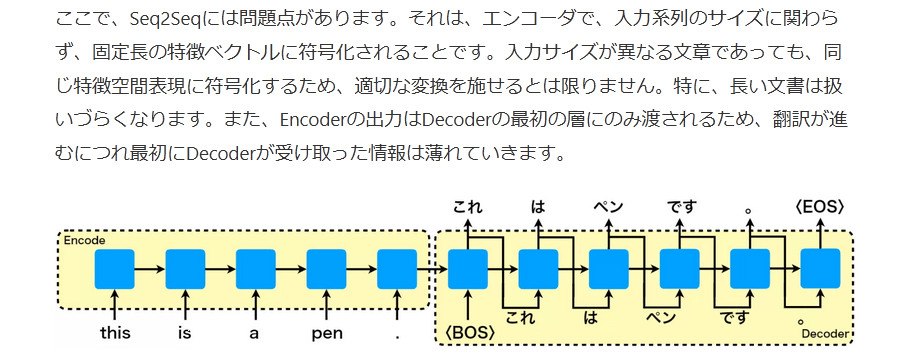
下図はSeq2Seqの入力に「this is a pen.」を与えた際、「これはペンです。」が出力される場合を示しています。ここで、thisのtが大文字でない理由を説明しておきます。実際にモデルに単語を入力する際、埋め込み層を使用して単語を埋め込みベクトルに変換しますが、埋め込み層が対応できる単語形に変換するプロセスが必要で、そのプロセスで大文字が小文字に変換されたと解釈してください。もし、大文字入力を認めるように設計すれば、大文字を小文字に変換する必要はありませんが、今回の例では、それを認めないこととしただけです。
図の中にある、〈BOS〉はbeginning of the sentenceの略で翻訳開始を表しています。〈EOS〉はend of sentenceの略で翻訳終了を表します。つまり、〈BOS〉を受け取ると直ちに翻訳を開始し、翻訳が終了すると〈EOS〉を出力します。
ここで、Seq2Seqには問題点があります。それは、エンコーダで、入力系列のサイズに関わらず、固定長の特徴ベクトルに符号化されることです。入力サイズが異なる文章であっても、同じ特徴空間表現に符号化するため、適切な変換を施せるとは限りません。特に、長い文書は扱いづらくなります。また、Encoderの出力はDecoderの最初の層にのみ渡されるため、翻訳が進むにつれ最初にDecoderが受け取った情報は薄れていきます。
覗き穴(Peeky)を持つSeq2Seq
翻訳が進むにつれて、Decoderが最初に受け取ったEncoderの出力情報が薄れてしまうという問題は、覗き穴(Peeky)構造を用意することで大体、解決できます。覗き穴(Peeky)は、一般的には見えないはずの情報を覗くことができる仕組みで、LSTMではピープホール結合(覗き穴結合)として知られています。興味があれば、以下の記事を読んでみてください。
直感で理解するLSTM・GRU入門 - 機械学習の基礎をマスターしよう!
当記事では数式を使わずに、LSTMとGRUのエッセンスを直感で理解できるように説明します。同様の説明をYouTube動画にアップしているのでぜひご活用ください! 当サイトはTwitterやYouTub ...
先ほどの、Seq2Seqモデルにおいて、DecoderからいついでもEncoderの出力を見ることができる覗き穴結合を施した場合のもモデルの図は以下のようになります。
この覗き穴結合により、Decoder側が何を翻訳したいのかという本質的な情報を常に片手に持ちつつ翻訳することが可能になります。翻訳が進んでも軸がブレにくく、途中で何が言いたかったんだっけ??な状況を防げるイメージです。
Seq2Seq + Attention機構
Seq2SeqはEncoder-Decoderモデルなので、系列データを1つの固定長ベクトルに写像しそれを、再度、系列データに復号します。学習対象の性質上、文章表現などの系列データは順序が重要になることが多いです。
例を上げると、「明日の天気は晴れです」と「明日は晴れの予報です」は本質的には同じ意味ですが、文章表現としては異なります。しかし、固定長ベクトルにエンコードすると、似通ったものになると考えられます。つまり、本質的内容が同じであれば、語句の並びや表現はノイズとして捨てられるため同じような内部表現(固定長ベクトル)になるわけです。これでは、入力文章の文脈に関係なく同じような翻訳結果になる可能性があります。すなわち、独特な言い回しなどの順序情報を翻訳結果に反映させるにはどうしたらいいかを考えていきたいわけです。そこで、Attention機構を導入します。
※この章で紹介するAttention機構は、論文の方ではAttentionという名前が使用されていないことと、後で話すAttentionの一般系には当てはまらないので、厳密に言うとAttention機構ではありませんが、初代Attention機構ということで捉えてもらえればと思います。
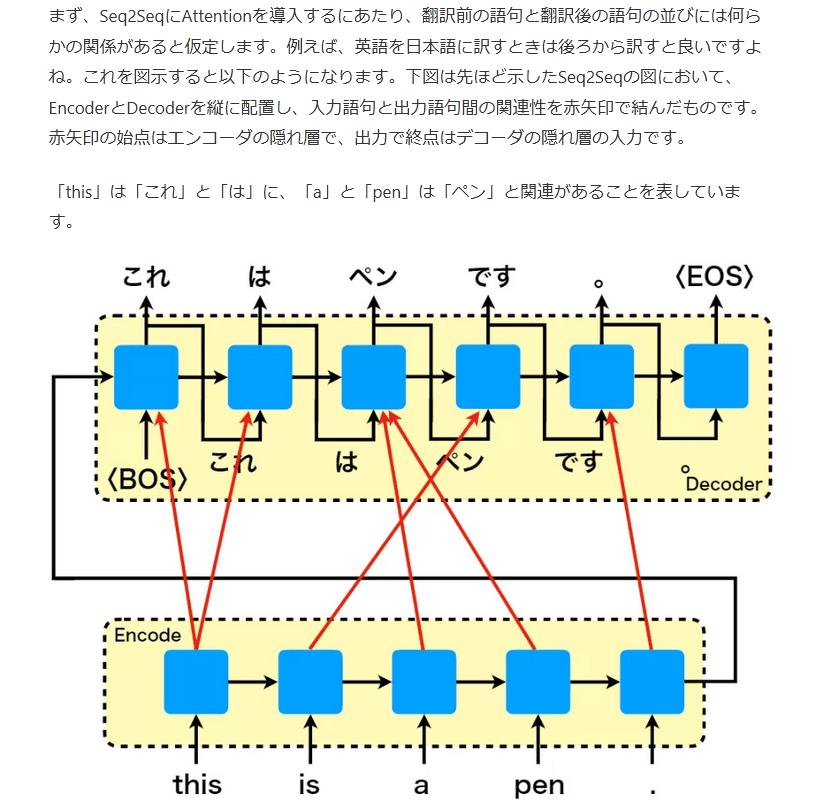
まず、Seq2SeqにAttentionを導入するにあたり、翻訳前の語句と翻訳後の語句の並びには何らかの関係があると仮定します。例えば、英語を日本語に訳すときは後ろから訳すと良いですよね。これを図示すると以下のようになります。下図は先ほど示したSeq2Seqの図において、EncoderとDecoderを縦に配置し、入力語句と出力語句間の関連性を赤矢印で結んだものです。赤矢印の始点はエンコーダの隠れ層で、出力で終点はデコーダの隠れ層の入力です。
「this」は「これ」と「は」に、「a」と「pen」は「ペン」と関連があることを表しています。
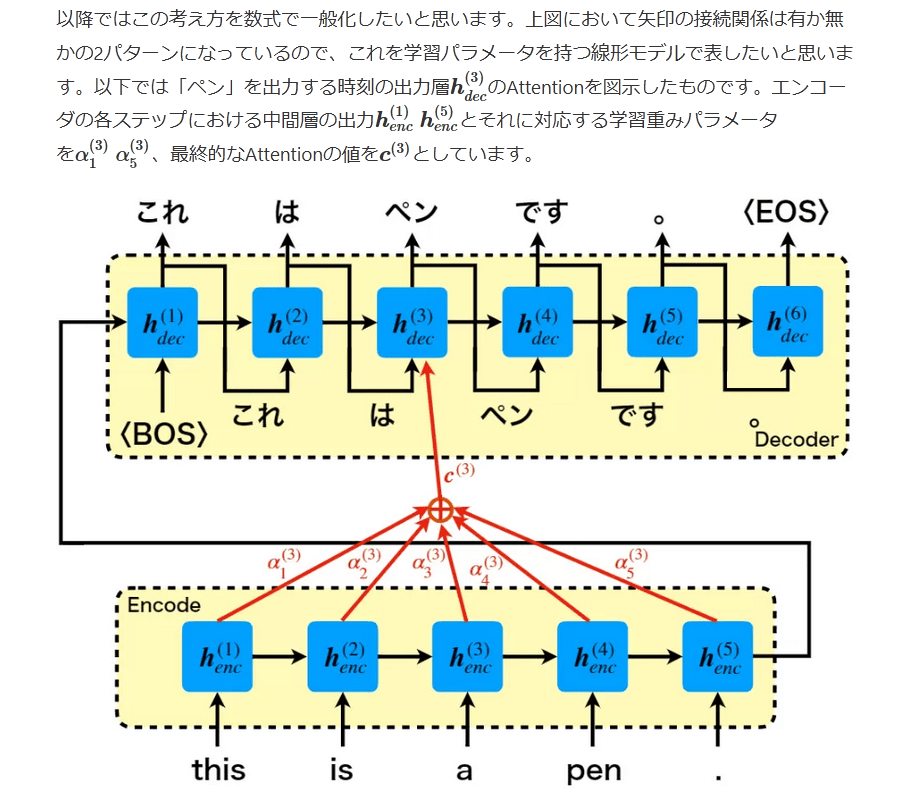
以降ではこの考え方を数式で一般化したいと思います。上図において矢印の接続関係は有か無かの2パターンになっているので、これを学習パラメータを持つ線形モデルで表したいと思います。以下では「ペン」を出力する時刻の出力層h(3)decのAttentionを図示したものです。エンコーダの各ステップにおける中間層の出力h(1)enc h(5)encとそれに対応する学習重みパラメータをα(3)1 α(3)5、最終的なAttentionの値をc(3)としています。
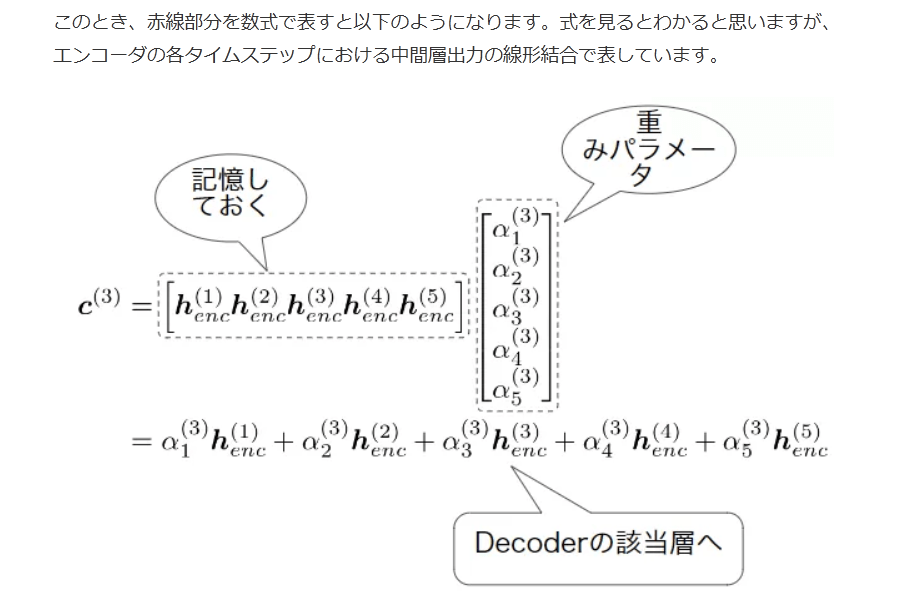
このとき、赤線部分を数式で表すと以下のようになります。式を見るとわかると思いますが、エンコーダの各タイムステップにおける中間層出力の線形結合で表しています。
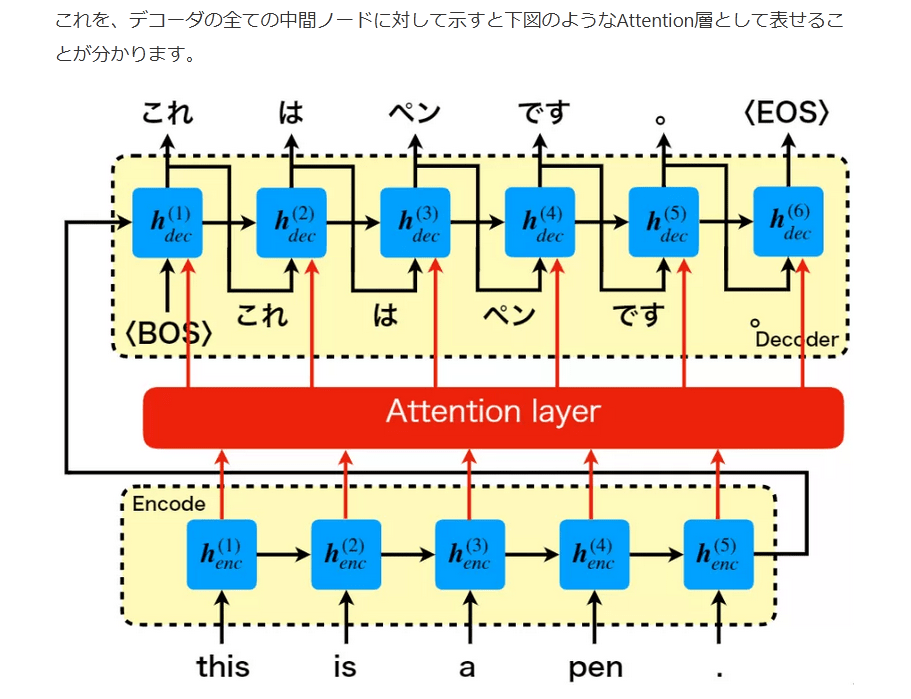
これを、デコーダの全ての中間ノードに対して示すと下図のようなAttention層として表せることが分かります。
ここまでの話が、RNNに導入された初代Attention機構になります。
Memory NetworkとAttention
ここでは、Seq2SeqのAttentionを更に拡張したものとして解釈可能なMemory Networkについて解説したいと思います。
(今後、追記予定)
CNNの起源とAttentionの起源
ここからは、CNNに導入された初代Attention機構について解説していきたいと思います。
この解説にあたりCNNの基礎知識について最初に解説していきます。CNNについてある程度の知識がある方は、CNNの基礎は飛ばしてSENetとAttention機構から読み進めてもらって大丈夫です。
CNNの基礎
CNNの基礎では、CNNの元となったネオコグニトロンから解説し、畳み込み層、プーリング層の仕組みと計算方法、画像認識コンペティションのILSVRCで登場したCNNモデルについて紹介したいと思います。
ネオコグニトロンとCNN
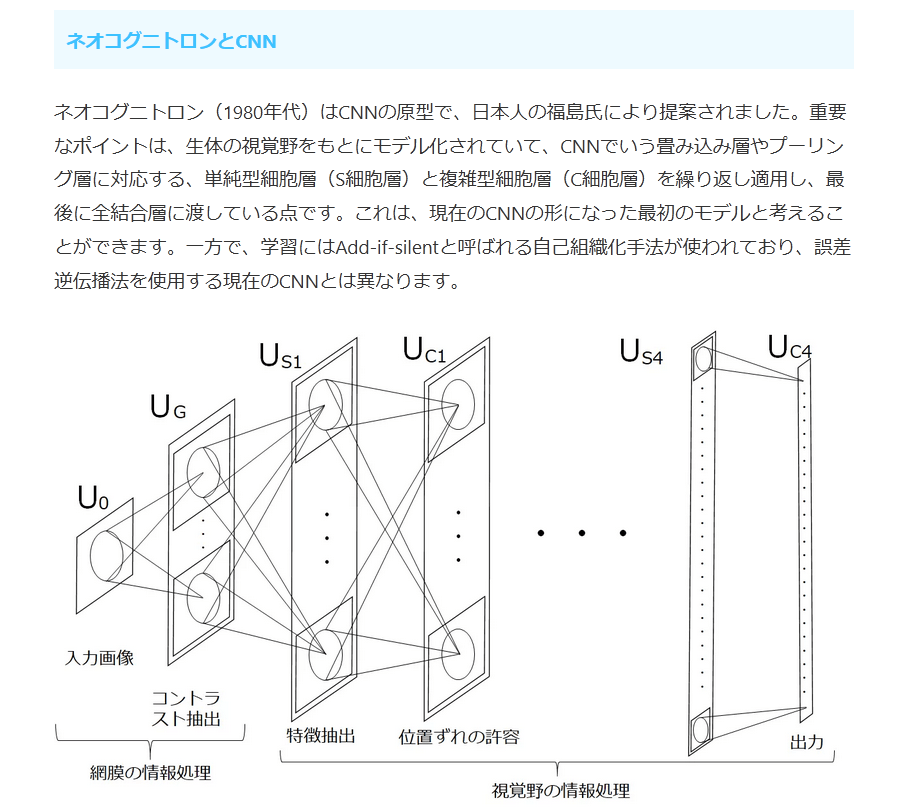
ネオコグニトロン(1980年代)はCNNの原型で、日本人の福島氏により提案されました。重要なポイントは、生体の視覚野をもとにモデル化されていて、CNNでいう畳み込み層やプーリング層に対応する、単純型細胞層(S細胞層)と複雑型細胞層(C細胞層)を繰り返し適用し、最後に全結合層に渡している点です。これは、現在のCNNの形になった最初のモデルと考えることができます。一方で、学習にはAdd-if-silentと呼ばれる自己組織化手法が使われており、誤差逆伝播法を使用する現在のCNNとは異なります。
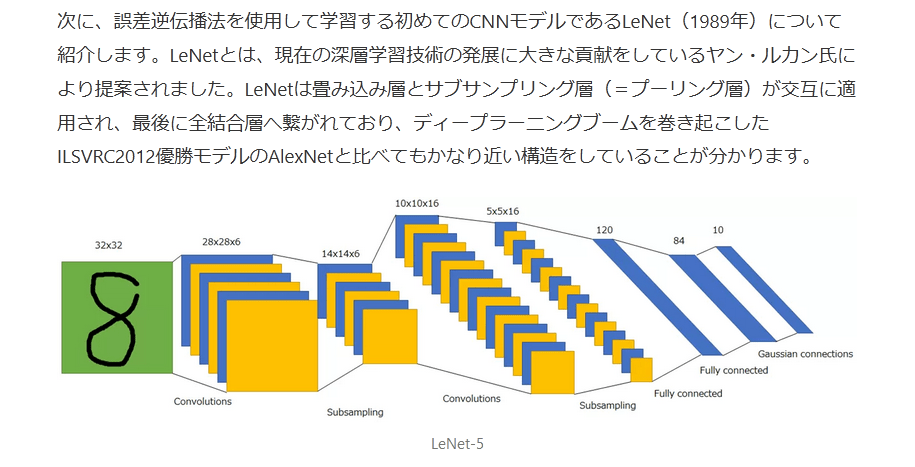
次に、誤差逆伝播法を使用して学習する初めてのCNNモデルであるLeNet(1989年)について紹介します。LeNetとは、現在の深層学習技術の発展に大きな貢献をしているヤン・ルカン氏により提案されました。LeNetは畳み込み層とサブサンプリング層(=プーリング層)が交互に適用され、最後に全結合層へ繋がれており、ディープラーニングブームを巻き起こしたILSVRC2012優勝モデルのAlexNetと比べてもかなり近い構造をしていることが分かります。
LeNet-5
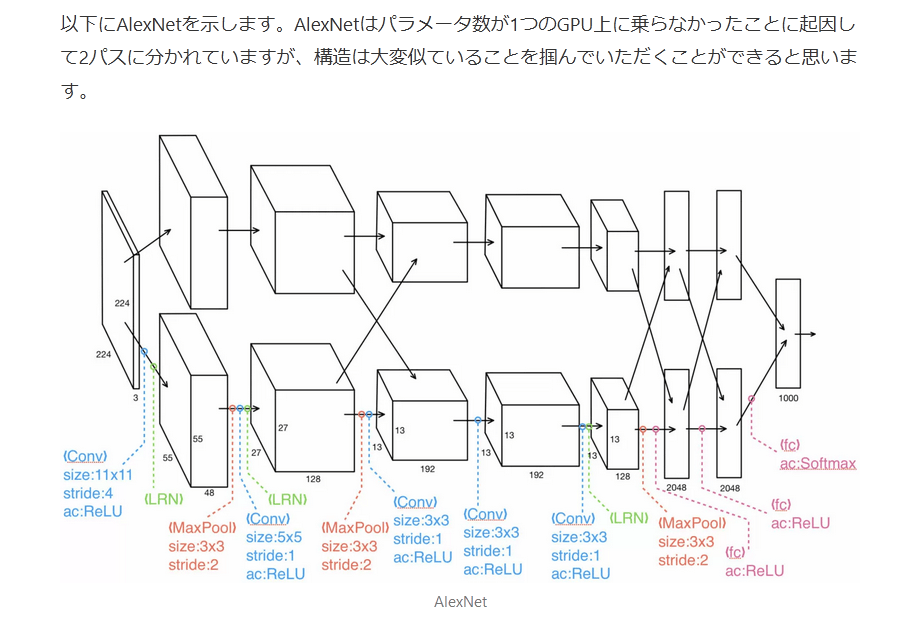
以下にAlexNetを示します。AlexNetはパラメータ数が1つのGPU上に乗らなかったことに起因して2パスに分かれていますが、構造は大変似ていることを掴んでいただくことができると思います。
alexnet
AlexNet
畳み込みニューラルネットワークについてより詳しく知りたい方や、LeNet-5の実相をしてみたい方は以下の記事を参照ください。
畳み込みニューラルネットワークの理論とPyTorchによるLeNetの実装
当記事では畳み込みニューラルネットワーク(Convolutional Neural Network;CNN)の基本的な理論とPyTochを使った実装について解説していきます。 おおまかな構成は、畳み込 ...
また、AlexNetについて詳しく知りたい方は以下の記事を参照ください。
AlexNetの技術についてアイディアレベルで解説 【Deep Learning アドベントカレンダー2020】
今回は、AlexNetの技術についてアイディアレベルで解説します。深層学習ブームの火付け役ともいえる深層ニューラルネットワーク技術についてこの機会にしっかり学んでおきましょう。 当サイトはTwitte ...
畳み込み層
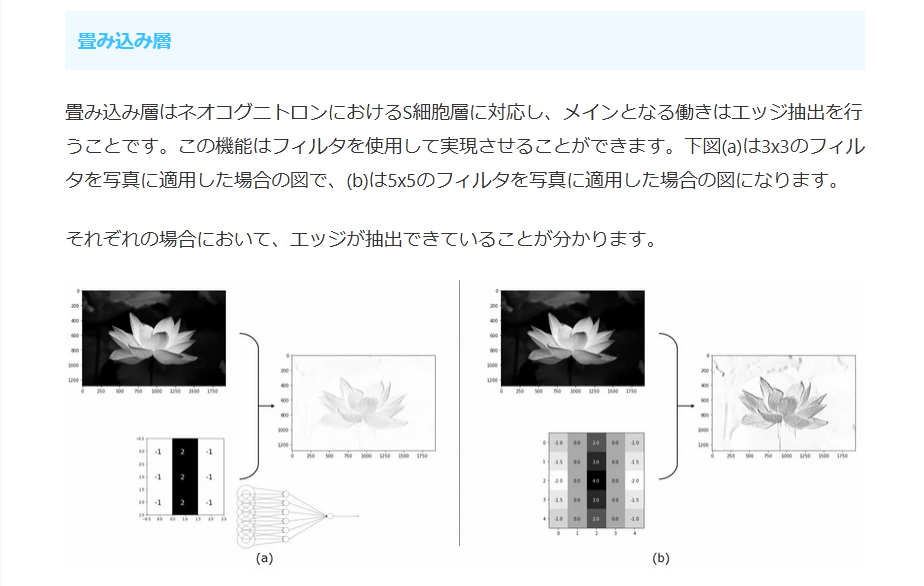
畳み込み層はネオコグニトロンにおけるS細胞層に対応し、メインとなる働きはエッジ抽出を行うことです。この機能はフィルタを使用して実現させることができます。下図(a)は3×3のフィルタを写真に適用した場合の図で、(b)は5×5のフィルタを写真に適用した場合の図になります。
それぞれの場合において、エッジが抽出できていることが分かります。
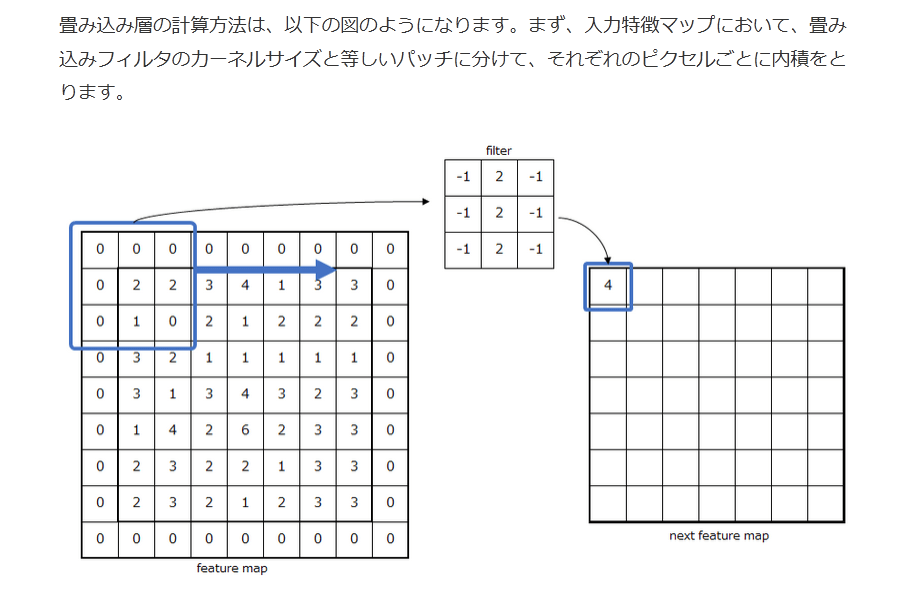
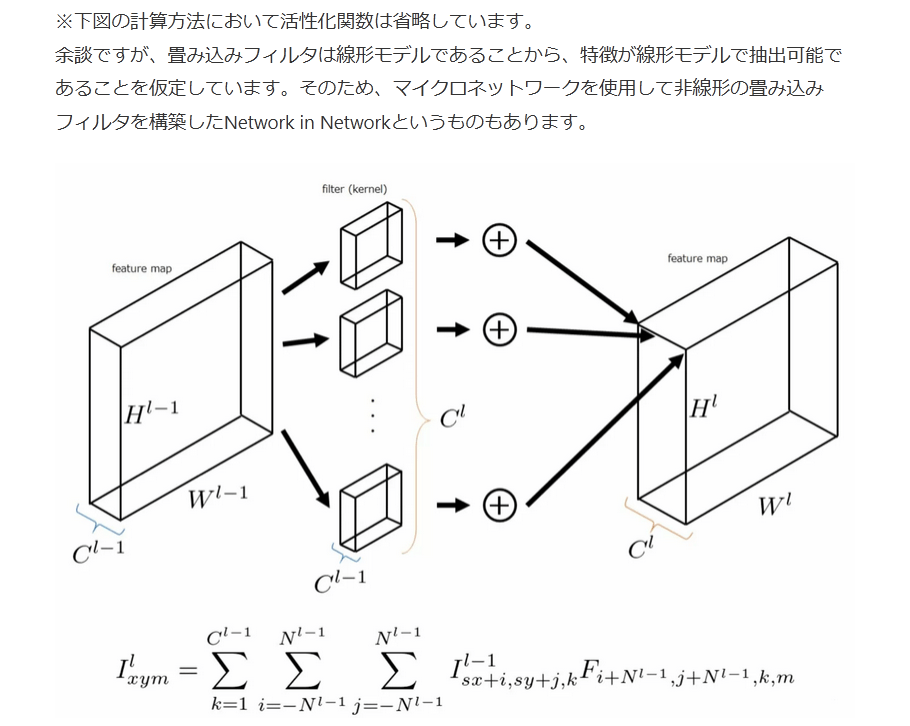
畳み込み層の計算方法は、以下の図のようになります。まず、入力特徴マップにおいて、畳み込みフィルタのカーネルサイズと等しいパッチに分けて、それぞれのピクセルごとに内積をとります。
※下図の計算方法において活性化関数は省略しています。
余談ですが、畳み込みフィルタは線形モデルであることから、特徴が線形モデルで抽出可能であることを仮定しています。そのため、マイクロネットワークを使用して非線形の畳み込みフィルタを構築したNetwork in Networkというものもあります。
プーリング層
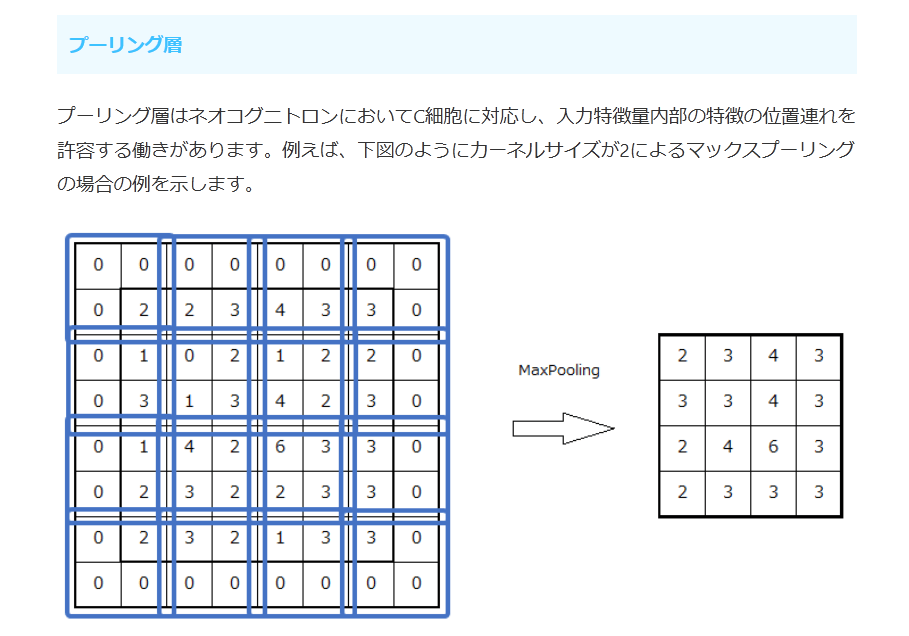
プーリング層はネオコグニトロンにおいてC細胞に対応し、入力特徴量内部の特徴の位置連れを許容する働きがあります。例えば、下図のようにカーネルサイズが2によるマックスプーリングの場合の例を示します。
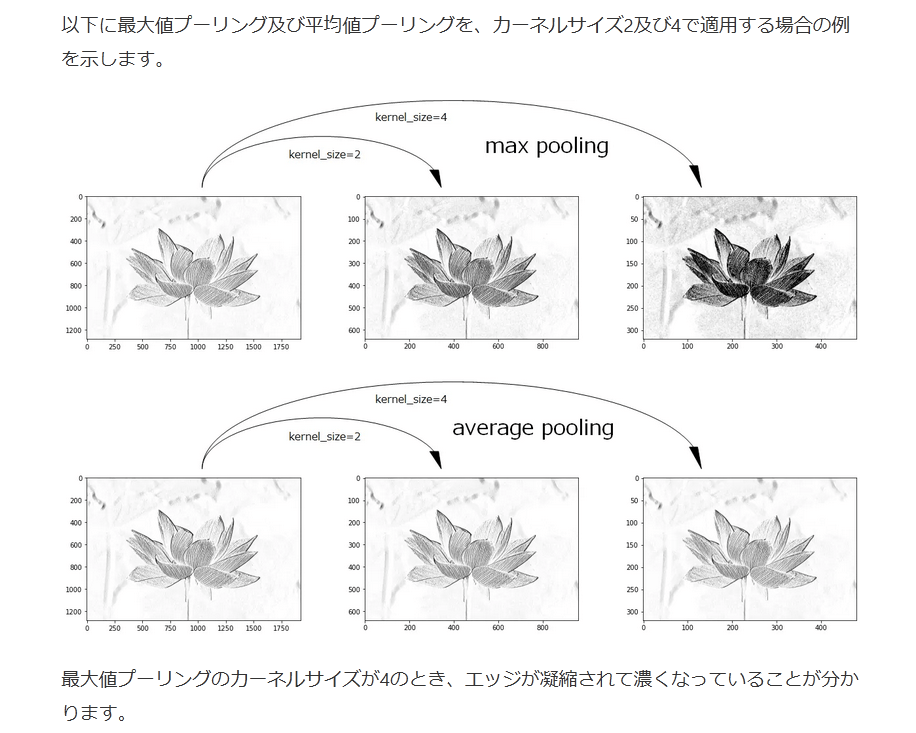
以下に最大値プーリング及び平均値プーリングを、カーネルサイズ2及び4で適用する場合の例を示します。
最大値プーリングのカーネルサイズが4のとき、エッジが凝縮されて濃くなっていることが分かります。
ILSVRCとCNN
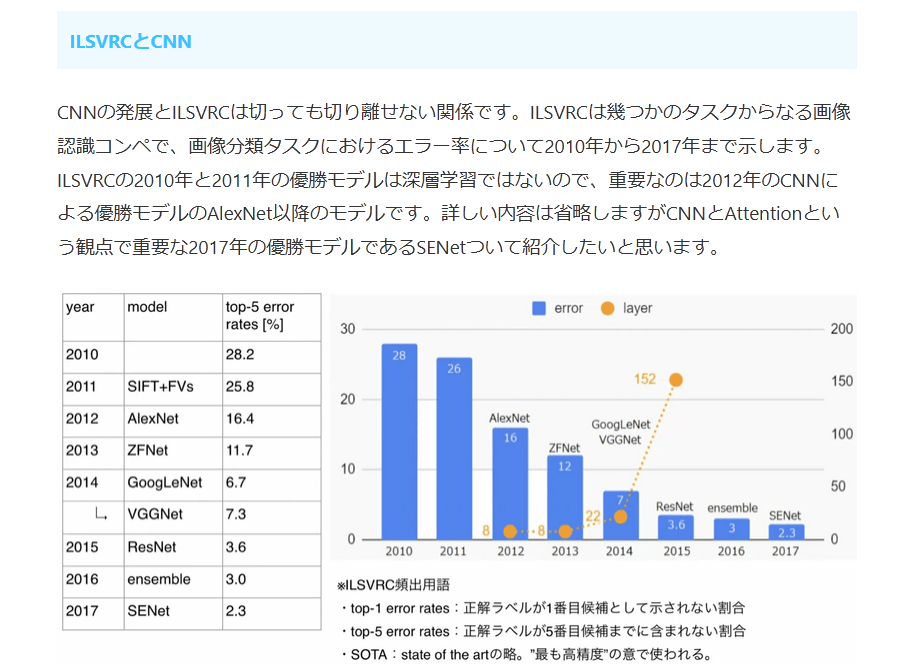
CNNの発展とILSVRCは切っても切り離せない関係です。ILSVRCは幾つかのタスクからなる画像認識コンペで、画像分類タスクにおけるエラー率について2010年から2017年まで示します。ILSVRCの2010年と2011年の優勝モデルは深層学習ではないので、重要なのは2012年のCNNによる優勝モデルのAlexNet以降のモデルです。詳しい内容は省略しますがCNNとAttentionという観点で重要な2017年の優勝モデルであるSENetついて紹介したいと思います。
SENetとAttention機構
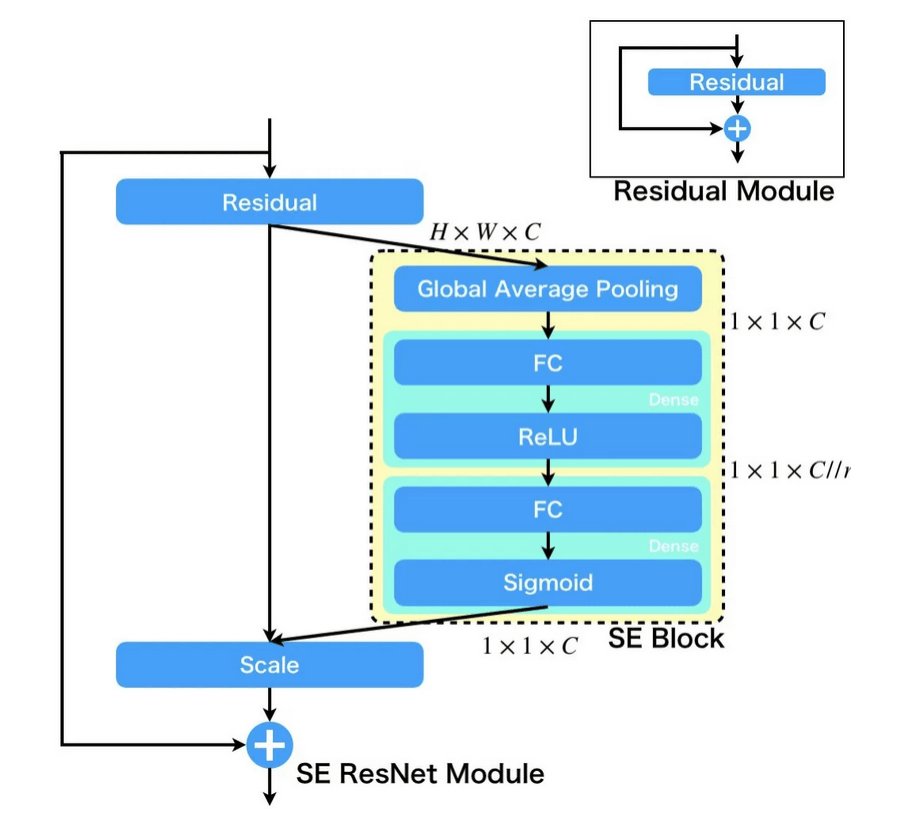
SENetについて解説します。SENetはSqueeze and Excitation Networkの略で、Squeezeには圧縮、Excitationには励起の意味があります。SENetというと、そういった名前のネットワークがあるのかと思われるかもしれませんが、そうではなくて、以下で説明するSE Blockというネットワークのブロックを追加したネットワークの総称です。例えば、ResNetにSE Blockを追加したSE-ResNetというものや、InceptionにSE Blockを追加したSE-Inceptionというものがあります。では、SE Blockとは何なのか具体的に解説していきます。
SE BlockはGAP→FC+ReLU→FC+SIgmoidの3層から構成され、特徴マップのチャンネルに関して、注目すべきと考えられるマップの情報は多く通過し、注目しべきでないと考えられるマップの情報はあまり通過しないようにゲーティングを行います。これは、特徴マップのチャンネルについてAttentionを適用していると解釈することができます。
GAPにより、マップ方向の平均特徴量を求め、2回の変換を施して、シグモイド関数による0~1の値に変換し、マップに掛け合わせることでゲート機構を実現しています。
Attention機構の種類
ここまで、大変長かったですがAttentionの起源ともいえるモデルについて紹介してきました。Attention機構はサブ的なネットワークを用意して注意を実現したものであることをご理解いただけたと思います。ここまでの話しではAttention機構の構造が一般化されておらず、混乱している方も多いと思うので、現在、一般化されているAttention機構の基本形状を説明していきたいと思います。
Attention機構の基本形
まず最初に、Attention機構の入力をQuery、Key、Valueをもつblockとして一般化します。以降では、この形で一般化したものをAttention機構と呼ぶことにします。
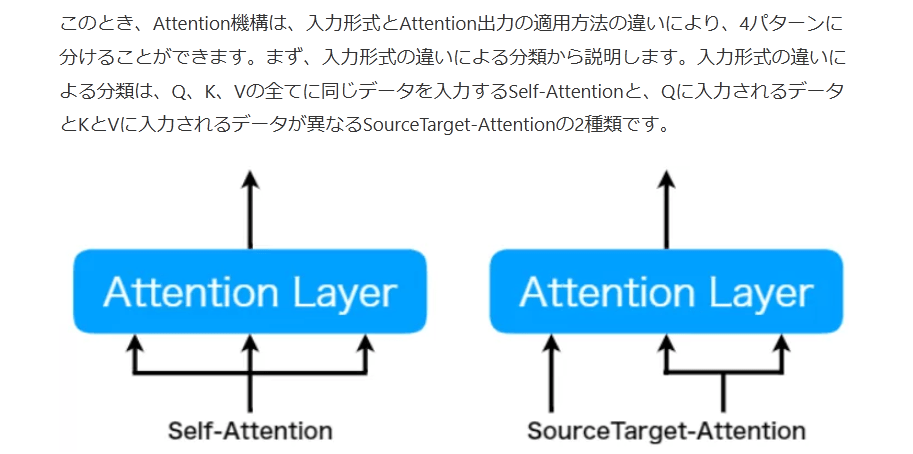
このとき、Attention機構は、入力形式とAttention出力の適用方法の違いにより、4パターンに分けることができます。まず、入力形式の違いによる分類から説明します。入力形式の違いによる分類は、Q、K、Vの全てに同じデータを入力するSelf-Attentionと、Qに入力されるデータとKとVに入力されるデータが異なるSourceTarget-Attentionの2種類です。
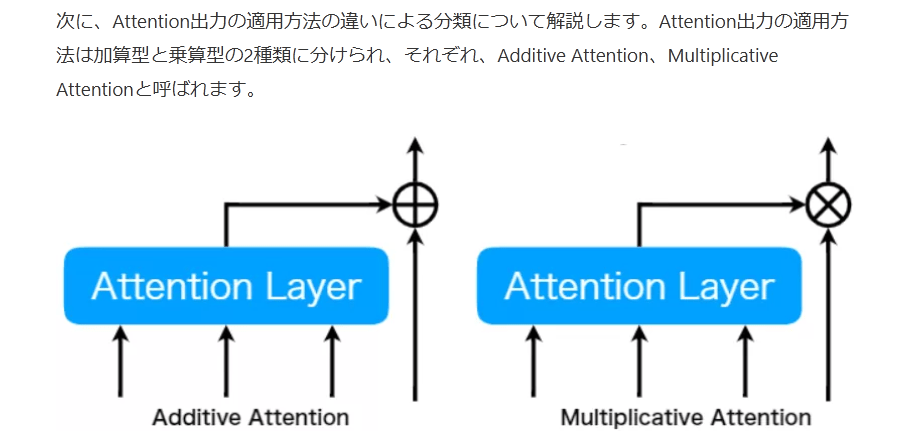
次に、Attention出力の適用方法の違いによる分類について解説します。Attention出力の適用方法は加算型と乗算型の2種類に分けられ、それぞれ、Additive Attention、Multiplicative Attentionと呼ばれます。
Transformer
ここまで、Attention機構について説明してきました。やっと、Transformerの説明を行うことができます。
概要
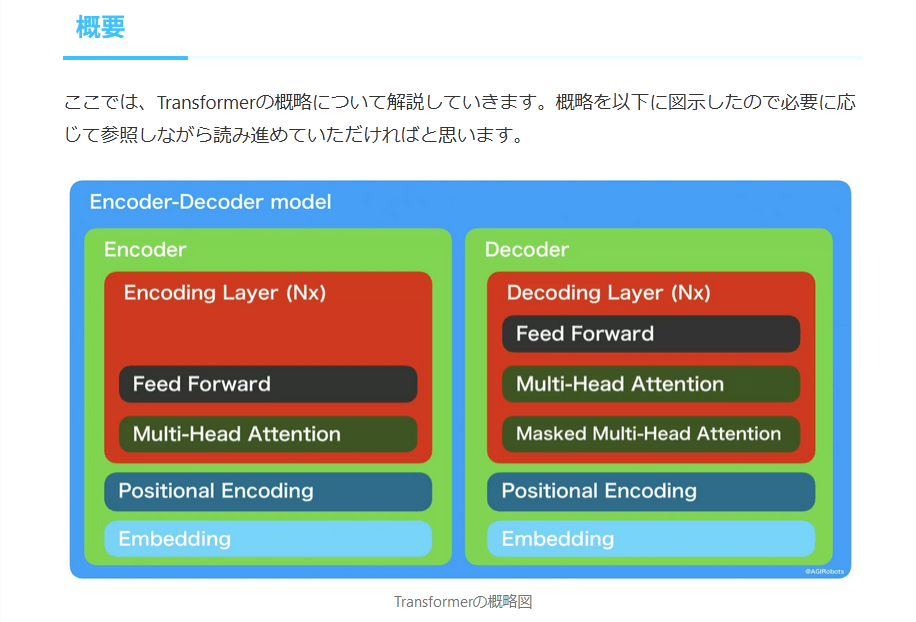
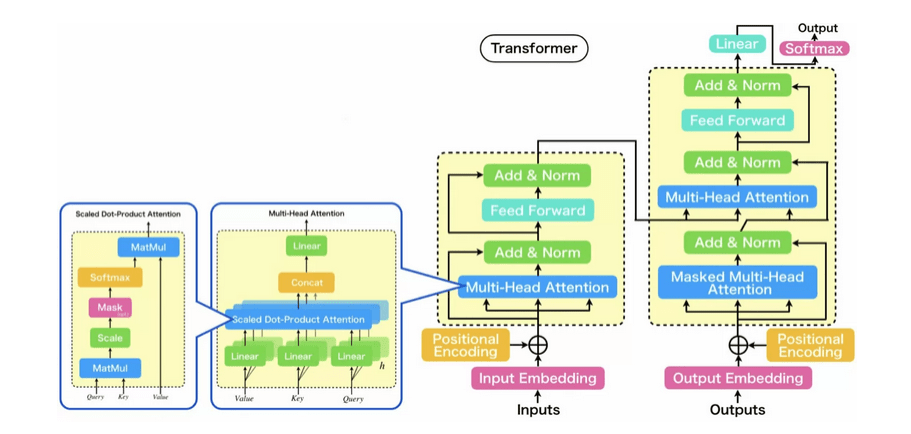
ここでは、Transformerの概略について解説していきます。概略を以下に図示したので必要に応じて参照しながら読み進めていただければと思います。
Transformerの概略図
Attention is all you needで示された初代TransformerはEncoderとDecoderから構成される、Encoder-Decoderモデルです。代表的なEncoder-Decoderモデルには、一般的に教師なしで次元圧縮する際に使われるAutoEncoderや自動翻訳の際に使われるSeq2Seqなどがあり、両モデルのEncoderやDecoderの細部構造に注目すると全く異なりますが、どちらもEncoderとDecoderから構成されるという抽象的な領域において共通点を持ち、本記事のメインテーマであるTransformerも同様の共通点を持っています。
それでは、TransformerのEncoder部分とDecoder部分の内部について順に紹介していきます。TransformerのEncoderとDecoderのアーキテクチャの共通事項としては、入力されたベクトルを埋め込み表現に変換するEmbedding層、単語の位置関係を特徴図けるPositional Encoding層、およびN回繰り返されるNx層を持つ点です(Nxのxは積を表していると考えられる)。
そして、Nx層は、EncoderとDecoderで異なります。Transformerのアーキテクチャを解説する中で最も核となる部分です。
図において、Encoder Layer (Nx)として示されている部分は、Multi-Head Attentionと呼ばれるAttention機構と、Feed Forward層からなります。また、Decoder Layer (Nx)として示されている部分は、Masked Multi-Head Attentionと呼ばれるAttention機構、Multi-Head Attention、Position-wise Feed Forward層からなります。
このように、Transformerは完全に、Attention機構をベースとしたモデルとなっています。
上の概略図では、概要を捉えやすくするためにTransformerを構成する要素間の情報の流れを省略していましたが、ここまでの説明で、大まかに構成要素を理解いただけたと思うので、各要素間の繋がりや情報の流れの矢印を追加したものを下図に示します。
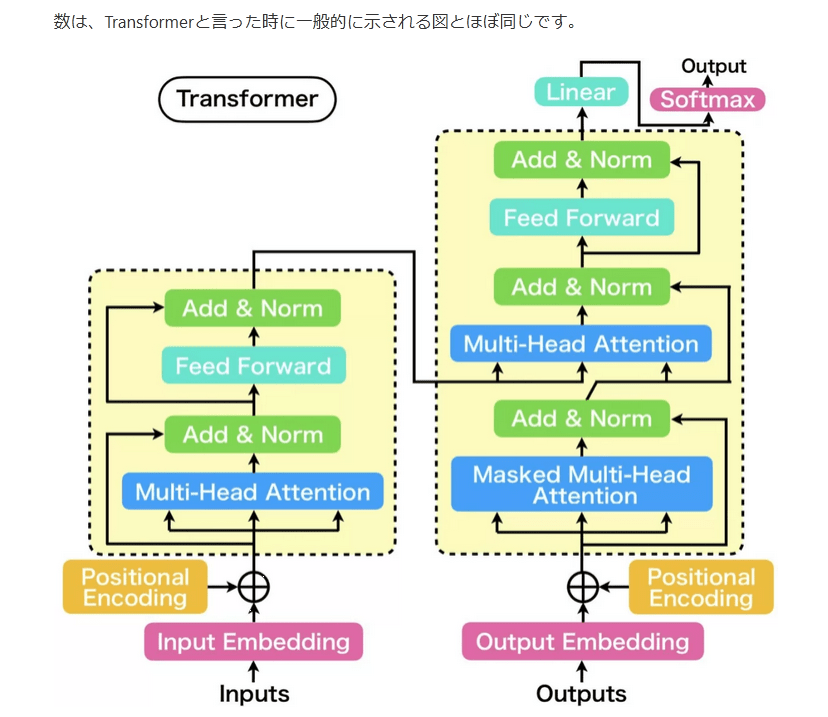
数は、Transformerと言った時に一般的に示される図とほぼ同じです。
上手からわかることを記載します。まず、AttentionおよびFeed Forwardの出力は、それぞれResidual connection(残差結合)され、直後に正規化されます。EncoderのMulti-Head AttentionはSelf-Attention型が、DecoderのMulti-Head AttentionはSourceTarget-Attentionが採用されています。Decoderには、Multi-Head Attentionの他にMasked Multi-Head Attentionがありますが、このMaskというのは、入力からpaddingを除外したり、先読みを防止するために使用されています。
以降では、Transformerを構成する重要な仕組みである、Embedding層、Positional Encoding、Multi~Head Attention、Scaled Dot-Product Attention、Feed-Forwardについて順番に説明してきます。
Embedding層
Embedding層は、Transformerで自然言語が扱えるように、単語を特徴ベクトル空間内に埋め込むときに使用する層で、分散表現と呼ばれる表現形式を扱うことができます。
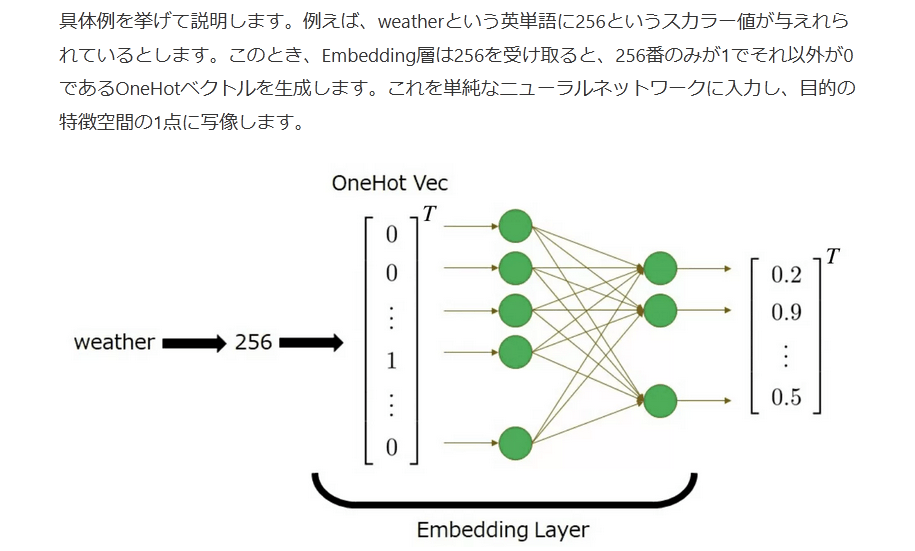
分散表現とは、単語などのトークンを線型空間上の1点に対応させる手法です。埋め込み層では、任意のトークン毎に与えられている唯一のスカラー値を入力として受け取り、その値をOneHotベクトル化&線形変換で固定長埋め込みベクトルに対応付ける働きをします。
具体例を挙げて説明します。例えば、weatherという英単語に256というスカラー値が与えれられているとします。このとき、Embedding層は256を受け取ると、256番のみが1でそれ以外が0であるOneHotベクトルを生成します。これを単純なニューラルネットワークに入力し、目的の特徴空間の1点に写像します。
では、文書が入力される場合は、どのようになるでしょうか?
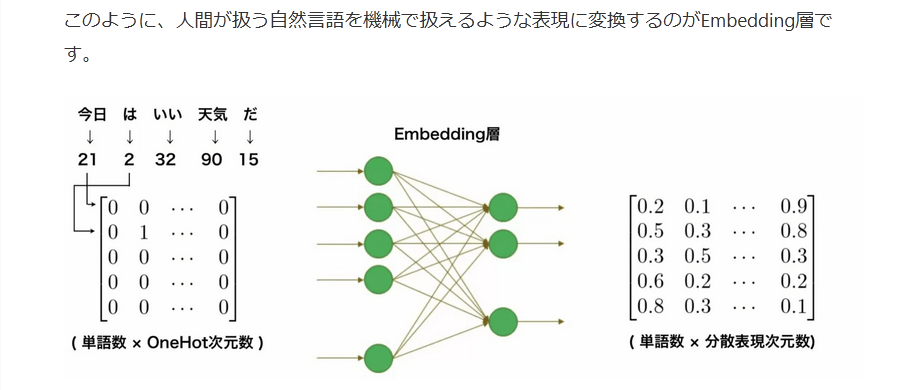
例として、「今日はいい天気だ」を考えてみます。単語分割処理をおこなうと「今日 は いい 天気 だ」となります。それぞれ単語に与えられたスカラー値に変換したとき、「21 2 32 90 15」となったとします。それぞれをOneHot形式の列ベクトルに変換し合体させると、以下のような行列ができます。ちなみに、行列サイズは(入力文章の単語数×OneHotベクトルサイズ)です。
⎡⎣⎢⎢⎢⎢⎢⎢0000001000⋯⋯⋯⋯⋯00000⎤⎦⎥⎥⎥⎥⎥⎥
上の行列をEmbedding層のニューラルネットワークで線形変換したところ、以下の行列が出力されたとします。この行列のサイズは(入力文章の単語数×分散表現次元数)です。
⎡⎣⎢⎢⎢⎢⎢⎢0.20.50.30.60.80.10.30.50.20.3⋯⋯⋯⋯⋯0.90.80.30.20.1⎤⎦⎥⎥⎥⎥⎥⎥
このように、人間が扱う自然言語を機械で扱えるような表現に変換するのがEmbedding層です。
Positional Encoding
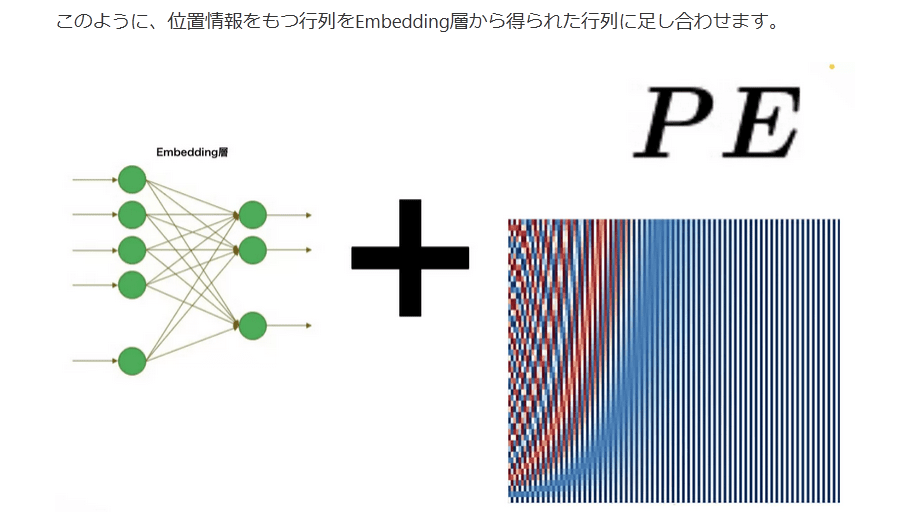
先ほど、Embedding層により、文章を行列で表せることを説明しました。文章というのは、文字を読む方向が重要です。しかし、行列として表され、かつ、一括で処理する場合、文字の順番の概念がなくなってしまいます。これは、文章を正しく扱えるか分かりません。そこで、Embedding層からの行列に位置情報を含んだ行列を足し合わせることで、順番の概念を扱えるようにします。これを可能にするのがPositional Encodingです。
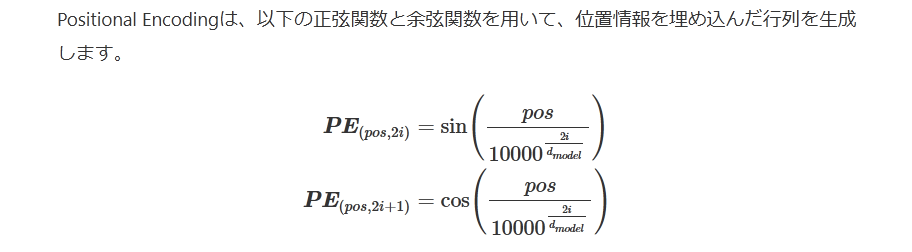
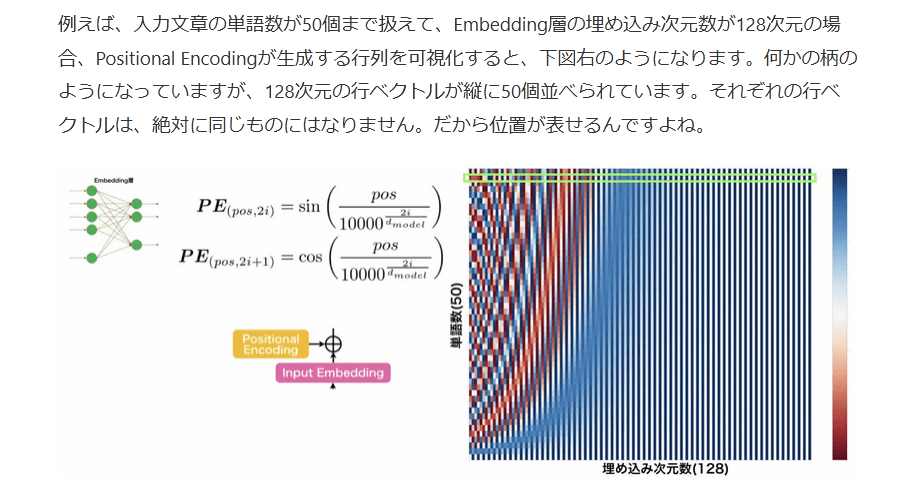
Positional Encodingは、以下の正弦関数と余弦関数を用いて、位置情報を埋め込んだ行列を生成します。
PE(pos,2i)PE(pos,2i+1)==sin(pos100002idmodel)cos(pos100002idmodel)
例えば、入力文章の単語数が50個まで扱えて、Embedding層の埋め込み次元数が128次元の場合、Positional Encodingが生成する行列を可視化すると、下図右のようになります。何かの柄のようになっていますが、128次元の行ベクトルが縦に50個並べられています。それぞれの行ベクトルは、絶対に同じものにはなりません。だから位置が表せるんですよね。
このように、位置情報をもつ行列をEmbedding層から得られた行列に足し合わせます。
Multi-Head Attention
やっと、Transformerを構成する最も革新的な要素であるMulti-Head Attentionの説明にたどり着きました。
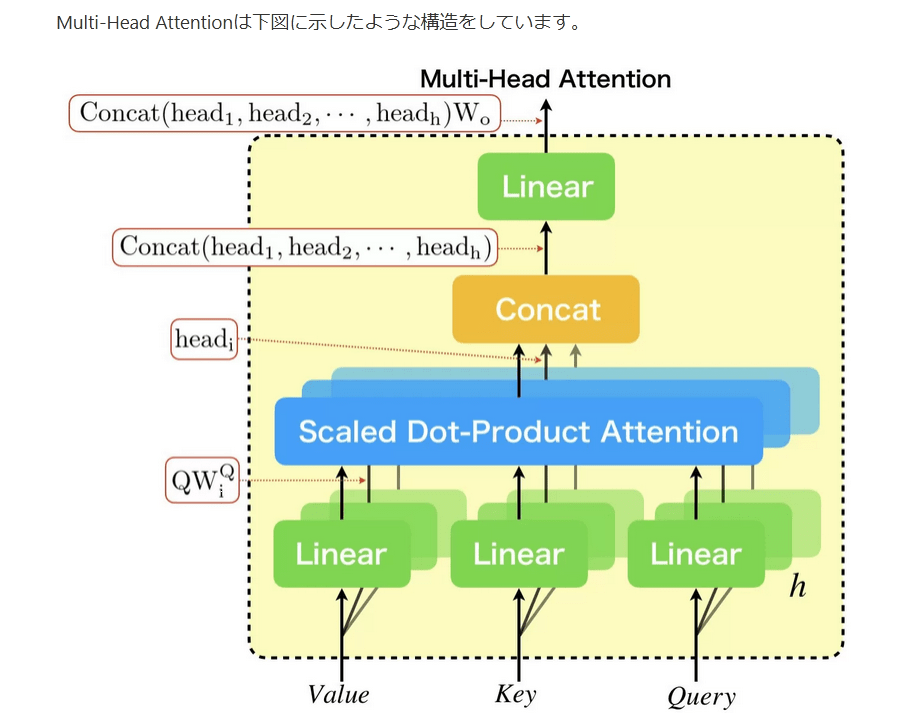
Multi-Head Attentionは下図に示したような構造をしています。
まず、最も大きな特徴は、内部に持っているScaled Dot-Product Attentionをアンサンブルしている点です。Scaled Dot-Product Attentionについては、次に説明しますが、Scaled Dot-Product Attentionの3つの入力は、Multi-Head Attentionの3つの入力(Value、key、Query)を線形層により変換したものとなっています。それぞれのScaled Dot-Product Attentionの直前に置かれている線形層は異なるものとなっています。これは、それぞれ異なる線形変換を施した場合において性能が高いことが実験的に確かめられたためです。ちなみに、線形層は学習パラメータを持っています。
Multi-Head Attentionを数式で表すと、下のようになります。
MultiHeadAttention(Q,K,V)where headi==Concat(head1,head2,⋯,headh)WoScaledDotProductAttention(QWQi,KWKi,VWVi)
Multi-Head Attentionについては、以下の記事で詳しく説明しています。より詳細を知りたい方は、以下の記事をお読みお読みいただければと思います。
【Transformerの基礎】Multi-Head Attentionの仕組み
本記事では、Transformerの基礎として、Multi-Head Attentionの仕組みを分かりやすく解説します。 本記事の構成は、はじめにTransformerおよびTransformer ...
Scaled Dot-Product Attention
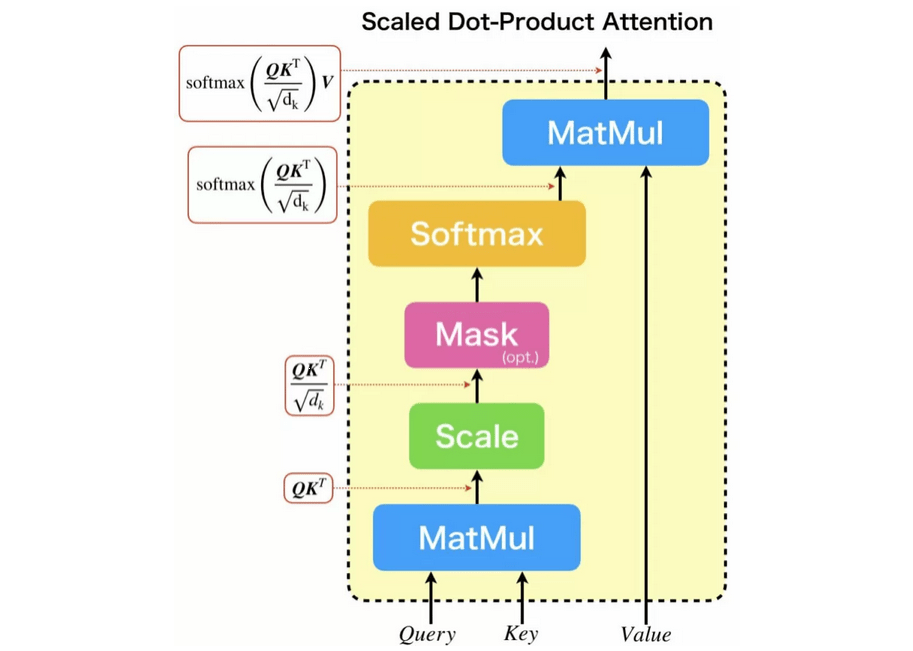
次に、Multi-Head Attention内で使用されてる、Scaled Dot-Product Attentionについて説明します。
Scaled Dot-Product Attentionは、下図に示すような構造をしています。Scaled Dot-Product Attentionの働きを一言で表すと、QueryとKeyの類似度から、Valueのどの値に注意を向けるべきかを計算しています。類似度は内積によって求められます。そのため、Dot-Productという単語が名前の中に使用されているのです。
Scaled Dot-Product Attentionは、内積した値に対して、スケール化を適用しています。スケール化する理由は、QueryとKeyの次元数に依存して値が変化することを防ぐためです。次元数が大きいベクトル同士の内積の方が、次元数が少ないベクトル同士の内積よりも値が大きくなりやすいことは容易に想像できるでしょう。これは、適切な処理が行えないため、次元数の根号で内積結果をスケーリングします。
計算式は以下のようになります。
ScaledDotProductAttention(Q,K,V)=softmax(QKTdk−−√)V
ちなみに、Scaled Dot-Product Attentionは学習パラメータを持ちません。
Feed- Forward
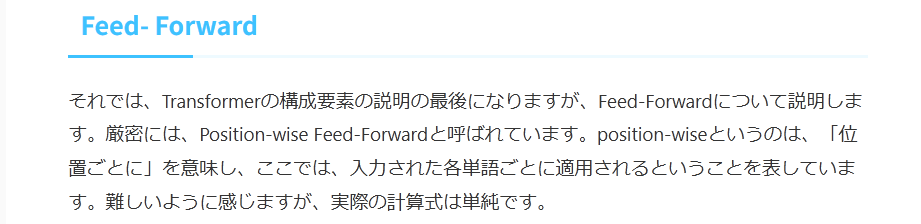
それでは、Transformerの構成要素の説明の最後になりますが、Feed-Forwardについて説明します。厳密には、Position-wise Feed-Forwardと呼ばれています。position-wiseというのは、「位置ごとに」を意味し、ここでは、入力された各単語ごとに適用されるということを表しています。難しいように感じますが、実際の計算式は単純です。
使用されているPosition-wise Feed-Forwardは2層で、1層目は重みがW1、バイアスがb1、活性化関数はReLU、2層は重みがW2、バイアスがb2、活性化関数は恒等関数とすると、以下のような式で表される計算を行います。
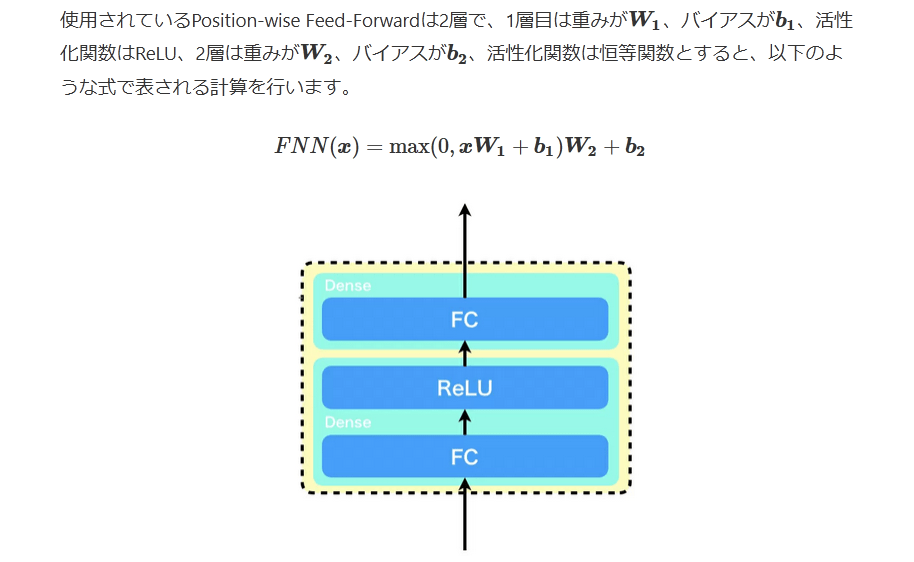
FNN(x)=max(0,xW1+b1)W2+b2
Transformer
最後に、ここまでの話をまとめます。
Transformer本体は、Multi-Head AttentionとFeed Forwardの組み合わせを基本構造とし、それをスタックすることで構成されています。Transformerで文章を扱うために、文章をEmbedding層を用いて分散表現にし、Positional Encoderで位置情報を埋め込んだものを入力として受けます。
Multi-Head Attentionは、Scaled Dot-Product Attentionをアンサンブルした構造をしています。それが、Multi-Headの所以だったりします。Scaled Dot-Product Attentionへの入力は、それぞれ学習パラメータをもつ線形層をかましたものとなっています。
Scaled Dot-Product Attentionは、学習パラメータを持たず、入力されたQuery、Keyの類似度から、Valueに含まれている情報を適切に抽出する仕組みとなっています。
これが、近年、注目されているTransformerの基本概要となります(下図)。
さいごに
本記事では、Transformerについて、Attentionの起源から順番に説明してきました。Transformerを利用したBERTや、GPTなどには触れていませんが、今後の記事で紹介していければと思います。
最後までお読みいただき、ありがとうございました。
関連
Transformerについて本質を分かりやすく解説!
2023年2月5日
ブログ
【Transformerの基礎】Multi-Head Attentionの仕組み
2023年2月9日
ブログ
Perceiver・Perceiver IOについて解説!
2023年7月19日
ブログ
この記事を書いた人
管理人
管理人
このサイトの管理人です。 人工知能や脳科学、ロボットなど幅広い領域に興味をもっています。 将来の目標は、人間のような高度な身体と知能をもったパーソナルロボットを開発することです。 最近は、ロボット開発と強化学習の勉強に力を入れています(NOW)。
-ブログ, 学習 』
いま、生成AIでNVIDIA GPUが引っ張りだこなワケ
https://pc.watch.impress.co.jp/docs/news/1517487.html








『AIによる要約
NVIDIAは19日、生成AIと同社のGPUおよびプラットフォームの関係について説明した。生成AIは人工知能の一種であり、学習、データ分析、結果予測のステップを進化させることで生まれた。生成AIは大規模なデータセットを使用し、ニューラルネットワークで分析し、プロンプトで文脈を理解することでオリジナルのコンテンツを生成する。基盤モデルである大規模言語モデル(LLM)では、Transformerモデルが使用され、データの重要度を重み付けするセルフアテンションメカニズムが特徴となっている。しかし、生成AIには企業個別の知識が欠けるなどの課題があるため、NVIDIAは各種ハードウェアとソフトウェアのソリューションを提供している。さらに、他の企業も新たな大規模言語モデルの開発に取り組んでおり、将来的には競争が激化する可能性もある。
この要約はChatGPTによって自動生成されたものであり、原文の完全性や正確性を保証するものではありません。この機能はベータ運用中です。』
『 劉 尭
2023年7月20日 06:04
このところChatGPTやStable Diffusionといった「生成AI」が話題となっているが、それを支えている基幹ハードウェアは言うまでもなくGPUである。そして生成AIで多く採用されているのがNVIDIAのGPUだ。NVIDIAは19日に記者向け説明会を開催し、生成AIとNVIDIAが提供するGPU、およびそれをベースとしたプラットフォームの関係について、同社テクニカル マーケティング マネージャーの澤井理紀氏が解説を行なった。
生成AIもAI、すなわち人工知能の一種である。「学習」してデータを「分析」、結果を「予測」すること、この3つのステップが人工知能の根幹部分を成す部分であり、生成AIとて変わるものではないが、それぞれのステップで進化を重ねることで「生成AI」が生まれた。
たとえば、これまで「機械学習(マシンラーニング)」と呼ばれていたものは単純にデータから統計と数学アルゴリズムを用いて結果を予測するものであった。それが「ディープラーニング(深層学習)」では、分析の段階でアルゴリズムではなくニューラルネットワークを用いて予測することで実現されてきた。
一方生成AIでは、これまでにない大規模なデータセットを用いて学習し、ニューラルネットワークで分析、そしてプロンプトで入力された文脈を理解することで、単なる予測のみならず「新しいコンテンツ」、しかも「完全にオリジナルの成果物」を生成することから、生成AIと呼ばれるようになった。
その生成AIの中心となるのが「基盤モデル」と呼ばれるもので、もっとも有名になったのがChatGPTのような大規模言語モデル(LLM)だ。基盤モデルで採用されているアーキテクチャが、Googleが提唱した「Transformer」モデルであり、エンコーダ部で言語を理解して、デコーダで言語を生成していく。
生成AIはAIの一部である
オリジナルの成果物を生成するのが生成AI
大規模言語モデル
Transformerモデル
Transformerがこれまでのディープラーニング手法と大きく異なるのは、入力データの各部分の重要度を差分的に重み付けをするセルフアテンションメカニズム。これによりデータの手動ラベル付けが不要となり、パラメータが数十億から数兆へと向上、モデルの汎用性が向上し、並列処理も可能になった。
ただ、“汎用的”となったことで、企業が個別に持つビジネスの問題の解決にはP-Tuningと呼ばれるカスタマイズが必要となる。たとえばBloombergが開発した「BloombergGPT」は金融データの広範なアーカイブを集めることで、金融に関する固有の問題の解決能力を高めている。
基盤モデルは汎用的にさまざまなタスクを処理できるが、その構築には膨大なトレーニングデータ、トレーニング/推論用の大規模計算資源、深い専門知識、大規模インフラの上で構築する複雑なアルゴリズムが必要だ。一方基盤モデルの使用における課題としては、先に述べた用な企業個別の知識が含まれていない点、トレーニングの時点で知識が固定されている点(新しいことを知らない)、幻覚によって望ましくない情報を提供したりする点、偏見と有害情報を出力してしまう点などが挙げられる。
こうした生成AIの構築と運用における課題を解決しつつ支援していくのが、NVIDIAの各種ソリューション、ということになる。
生成AIの利用方法
生成AI開発の課題
NVIDIAは生成AIをどう支えていくのか
まずは膨大なデータと大規模計算資源だが、ハードウェアやクラウドサービスの提供で解決を見出す。たとえば最新のH100 TensorコアGPUは、PCI Expressの拡張カード形態からHGX H100/DGX H100のようなシステムの形態、そしてDGX SuperPODというデータセンター全体のソリューションを提供しており、さまざまな規模で運用可能となる。
また、AIトレーニングサービスとして「DGX Cloud」を提供しており、ソフトウェアやスケール可能なマルチノード、展開を支援するAIエキスパートなどを予測可能な価格で提供している。
さらに、CPU/GPU間のデータのやりとりにかかるエネルギーを削減できる「GH200 Grace Hopper Superchip」、スケールする際に高速かつ大容量メモリを実現する「DGX GH200 NVLink」などを提供。加えて、ビジュアルとAIの両方が必要なユーザーには「L40」、大規模言語モデル処理向けにはNVLinkを用いて188GBのHBM3を実現した「H100 NVL」を用意している。
生成AI用のさまざまなハードウェアソリューション
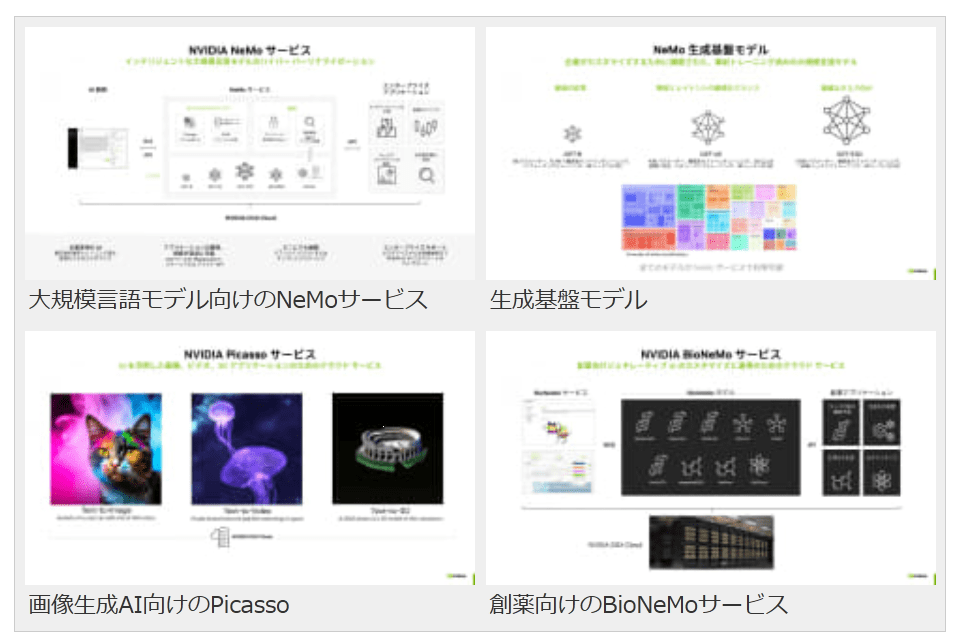
こうしたハードウェア面のみならず、ソフトウェア面では「NVIDIA AI Enterprise」という4,000以上のソフトウェアパッケージを提供。中でも「NeMoフレームワーク」は、生成AIモデルの構築からカスタマイズ、展開まで可能なエンドツーエンドのものとなっており、基盤モデル構築の際の課題を解決し、トレーニングの高速化を実現するという。
加えて、クラウドサービスも提供し、大規模言語モデル構築のための「NeMo」、画像生成AIのための「Picasso」、製薬のための「BioNemo」も、順次展開していく。
NeMoフレームワーク
有害コンテンツ、幻覚などを防ぐNeMo Guardrails
さまざまなクラウドサービス
大規模言語モデル向けのNeMoサービス
生成基盤モデル
画像生成AI向けのPicasso
創薬向けのBioNeMoサービス
NVIDIA生成AI Day 2023 Summerも開催へ
2023年、コンピュータ業界はChatGPTをはじめとした生成AIから話題がスタートしたと言っても過言ではない。生成AIはGPUなしには生まれなかったというのは周知の通りなのだが、なぜそれが他社のGPUではなくNVIDIA一強なのか、疑問に思う人も少なくないだろう。
澤井氏によれば「もちろんGPU自体の高い性能もあるが、大規模言語モデル(LLM)を構築するための高速ネットワーク技術、そして大規模な環境でAIをトレーニングしたり推論したりする際のソフトウェアもある。フルスタックで提供しているところが強みになっている」とのこと。つまり、上で説明されたすべてが、NVIDIA GPUがこれだけ広く使われている理由となっているわけだ。
ちなみにこれはあくまでも“現状”そうなっているのであって、未来もそうなるとは限らない。AIプロセッサ企業TenstorrentのJim Keller CEOは、「近々イノベーションにより新しい大規模言語モデル誕生し、より大きなコンテキストでより小さなメモリフットプリントを実現できる」と予測しており、実際にNECが7月に「標準的GPU 1基で動く日本語LLM」を開発するなど、新たな動きが始まっている。
関連記事
伝説のCPUアーキテクトJim Keller氏が示すAIの未来
NEC、「標準的GPU 1基で動く」世界トップクラスの日本語LLM
そういう意味でも、生成AIとNVIDIAの今後の動向に、ますます目が離せないだろう。NVIDIAは7月28日に、日本で「NVIDIA生成AI Day 2023 Summer」なるイベントを開催予定だ。 』
国連安保理AIテーマの初会合 英外相議長で18日に
https://www.nikkei.com/article/DGXZQOGR162TV0W3A710C2000000/
『【ロンドン=江渕智弘】英政府は17日、国連安全保障理事会が18日に人工知能(AI)をテーマにした会合を初めて開くと発表した。同国のクレバリー外相が議長を務める。AIの安全保障への役立て方とリスクを検証し、安全な活用を模索する。
「Chat(チャット)GPT」など生成AIの利用が世界で急速に広がってい…
この記事は会員限定です。登録すると続きをお読みいただけます。』
『英政府は年内にAIの安全対策に関する国際会議を開く予定だ。7月に議長国を務める安保理で議論を提起し、国際会議につなげる狙いがある。』
NEC、「標準的GPU 1基で動く」世界トップクラスの日本語LLM
https://pc.watch.impress.co.jp/docs/news/1514343.html



『AIによる要約
NECは、日本の性能を持つ大規模言語モデル(LLM)を開発し、わずか130億パラメータで世界トップクラスの性能を実現したと発表した。このLLMは、1枚のGPUを搭載した標準的なサーバーで動作可能であり、高い日本語性能とカスタマイズ対応を提供するもので、業務アプリケーションのレスポンスも良く、消費電力やコストも抑えられる。また、開発には国内企業で最大のAI研究用スパコンが活用され、2023年3月から稼働する予定とのこと。NECは、LLMのライセンス提供だけでなく、専用ハードウェアやソフトウェア、コンサルティングサービスなども提供する計画であり、今後の3年間で約500億円の売上を目指すとしている。
この要約はChatGPTによって自動生成されたものであり、原文の完全性や正確性を保証するものではありません。この機能はベータ運用中です。』
『 劉 尭
2023年7月6日 14:42
NECのLLMにおける質問応答出力例
NECは、わずか130億パラメータで世界トップクラスの日本語性能を有するという大規模言語モデル(LLM)を開発したと発表した。標準的なGPU 1枚を装備したサーバー動作可能と謳っている。
ChatGPTにより生成AIの1つであるLLMは注目を集めつつあるが、既存のLLMのほとんどは英語を中心に学習されているため、高い日本語性能を有しつつ、各業種の業務で活用できるカスタマイズ対応のLLMはほぼない状況だった。今回NECは、LLM性能はパラメータサイズだけでなく、学習に使われた高品質なデータの量や学習時間にも左右されることに着目。多量のデータと膨大な計算時間をかけることで高い性能を実現した。
具体的には、開発にあたって国内企業で最大のAI研究用スパコンを独自構築し、2023年3月より全面稼働。これを活用することで約1カ月という短期間で高性能LLMの構築を実現したという。
ほかのLLMでは多数のGPUを必要とするのに対し、NECのLLMはパラメータ数を130億に抑えており、GPUを1枚搭載した標準的なサーバーで動作可能としており、業務アプリケーションがレスポンスよく動作し、消費電力やサーバーのコストを抑えられる。さらに、短期間で容易に構築可能で、オンプレミス環境でも動作できるため秘匿性の高い業務でも安心としている。
性能面では、自然言語処理分野で標準的なベンチマークである日本語言語理解ベンチマーク「JGLUE」を用いて評価したところ、現時点での知識量に相当する質問応答で81.1%、推論能力に相当する文書読解において84.3%と、世界トップレベルの性能を達成したとしている。
NECでは5月より社内で生成AIの業務利用を開始しており、資料作成時間が50%削減され、議事録作成時間を約平均30分から5分に短縮したという。また、システム開発におけるソースコード作成業務の効率化で、工数80%削減といった成果が出ているという。
同社はこのLLMのライセンス提供に加え、日本市場のニーズに合わせた専用ハードウェア/ソフトウェア/コンサルティングサービスを提供する「NEC Generative AI Service」を順次開始する。また、LLM活用のためのソフトウェア整備/組織立ち上げなどを包括的に支援するプログラム「NEC Generative AI Advanced Customer Program」を約10の企業/大学とともに立ち上げ。生成AI関連事業において、今後3年間で約500億円の売上げを目指す。 』
