logit ( p i ) = ln ( p i 1 − p i ) = α + β 1 x 1 , i + ⋯ + β k x k , i , {\displaystyle \operatorname {logit} (p_{i})=\ln \left({\frac {p_{i}}{1-p_{i}}}\right)=\alpha +\beta {1}x{1,i}+\cdots +\beta {k}x{k,i},} i = 1 , … , n , {\displaystyle i=1,\dots ,n,\,!}
ここで、n 個のユニットと共変動 X があり、以下のような関係にある。
p i = E ( Y | X i ) = Pr ( Y i = 1 ) . {\displaystyle p_{i}=E(Y|X_{i})=\Pr(Y_{i}=1).\,!}
結果のオッズ(1から確率を引いたもので確率を割った値)の対数は、説明変数 Xi の線形関数としてモデル化される。これを次のようにも表せる。
p i = Pr ( Y i = 1 | X ) = 1 1 + e − ( α + β 1 x 1 , i + ⋯ + β k x k , i ) {\displaystyle p_{i}=\Pr(Y_{i}=1|X)={\frac {1}{1+e^{-(\alpha +\beta {1}x{1,i}+\cdots +\beta {k}x{k,i})}}}}
Agresti, Alan, Categorical Data Analysis, 2nd ed., New York: Wiley-Interscience, 2002, ISBN 0-471-36093-7.
Amemiya, T., Advanced Econometrics, Harvard University Press, 1985, ISBN 0-674-00560-0.
Balakrishnan, N., Handbook of the Logistic Distribution, Marcel Dekker Inc., 1991, ISBN 0824785878.
Green, William H., Econometric Analysis, fifth edition, Prentice Hall, 2003, ISBN 0-13-066189-9.
Hosmer, David W. and Stanley Lemeshow, Applied Logistic Regression, 2nd ed., New York; Chichester, Wiley, 2000, ISBN 0-471-35632-8.
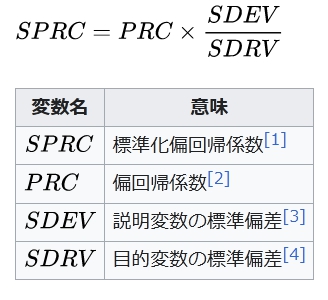
S P R C = P R C × S D E V S D R V {\displaystyle SPRC=PRC\times {\frac {SDEV}{SDRV}}}
変数名 意味
S P R C {\displaystyle SPRC} 標準化偏回帰係数[1]
P R C {\displaystyle PRC} 偏回帰係数[2]
S D E V {\displaystyle SDEV} 説明変数の標準偏差[3]
S D R V {\displaystyle SDRV} 目的変数の標準偏差[4]
例
中学生を対象に調査を行いその結果を重回帰分析したところ下の式が得られたとする。
t C × 3 + t S J × 5 + 20 = n {\displaystyle t_{C}\times 3+t_{SJ}\times 5+20=n}
変数名 意味
t C {\displaystyle t_{C}} 中学で勉強した時間数
t S J {\displaystyle t_{SJ}} 小学生の時代の塾の学習時間数
n {\displaystyle n} 知っている英単語の数
Microsoft Excel
SAS
Stata
SPSS
College Analysis
多変量解析入門
R言語 - 統計解析言語。重回帰分析だけでなく多変量解析ほか多くの統計関数を標準装備したフリーウェア。『モデル式』でモデル記述や当てはめが容易。他アプリケーションのファイル取込やODBC接続対応。FDA公認。CRANなる仕組で世界の膨大なソフトを無償利用可能。可視化機能に優れ、日本語対応。マルチプラットフォーム。Rの基本パッケージ中の回帰、分散分析関数一覧。重回帰分析はlm関数で行えるほか、独自に書かれた関数もある: [1][2]。
NAG
IMSL
R言語 - 統計解析言語。回帰分析ほか多くの統計関数を標準装備したフリーウェア。『モデル式』でモデル記述や当てはめが容易。他アプリケーションのファイル取込やODBC接続対応。FDA公認。CRANという仕組みで世界の膨大なソフトを無償利用可能。可視化機能に優れ、日本語対応。マルチプラットフォーム。
Stata
Gretl
脚注
^ 『統計学入門』(東京大学出版会)、257頁
参考文献
『統計学入門』東京大学出版会、1991年。
J. R. Taylor 著、林茂雄、馬場凉(訳) 編『計測における誤差解析入門』東京化学同人、2000年。
蓑谷千凰彦『回帰分析のはなし』東京図書、1985年。
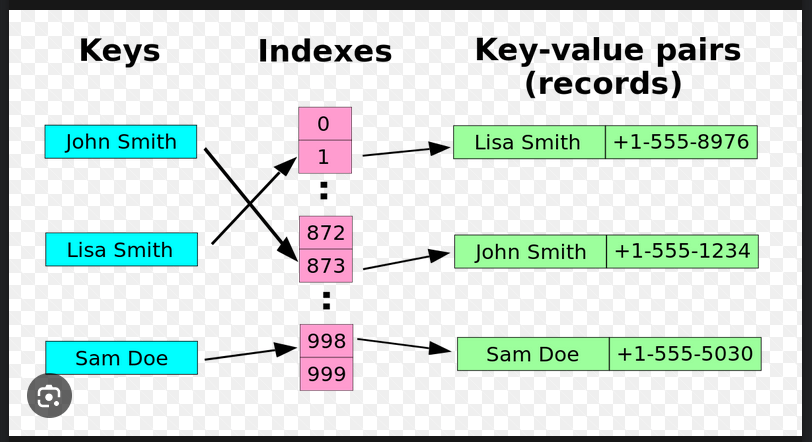
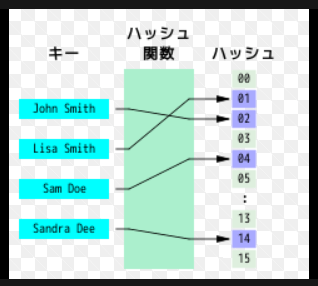
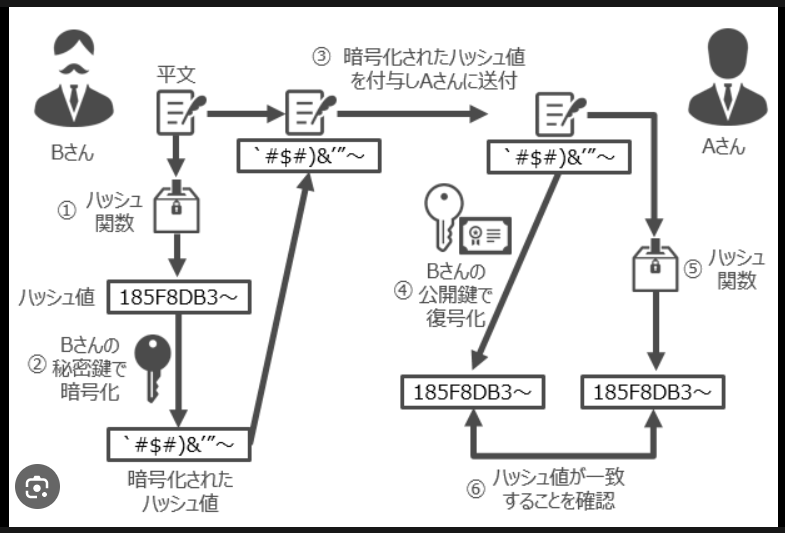
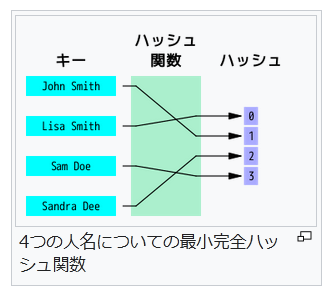
巨大なソートされていないファイルから重複したレコードを探す場合、各レコードをハッシュ関数に入力して配列 T のインデックスを得て、各バケット T[i] にハッシュ値が i になった全レコードの番号をリストの形で集める。この配列が完成すると、重複したレコードは必ず同じバケットに存在しているはずである。そこで、リストの要素数が2つ以上のバケット全てについて実際のレコードを求めて比較することで、重複レコードを探すことができる。配列が適切な大きさであれば、この方法が他のどんな方法(ファイルをソートし、隣り合うレコードを比較していく方法など)よりも高速な場合が多い。 類似レコードの探索
ハッシュ関数は、キーが似ているが全く同一ではない場合のレコード検索にも使える。この場合の入力は1つのキーか、似たようなキーを持つ巨大ファイル内の2つのレコードである。このためには、似たようなキーを与えられたとき、最大でも m しか違わないハッシュ値(m は小さい整数で例えば1か2)を生成するハッシュ関数を必要とする。このようなハッシュ関数を使って全レコードに関するハッシュテーブル T を構築すると、似たようなレコードは同じバケットか近いバケットに格納されることになる。すると各バケット T[i] について、-m から m の範囲の k で表されるバケット T[i+k] に格納されているレコード群を相互に比較すればよい。
他の手法に比べてハッシュ関数を用いた手法をより有利にするには、ハッシュ関数の計算コストが十分小さくなければならない。例えば、n個の要素のあるソート済みテーブルにある要素を挿入する場合、二分探索では log2 n 回のキーの比較を必要とする。したがって、ハッシュテーブルを使った手法が二分探索よりも効率的であるためには、ハッシュ関数が1つのキーからハッシュ値を計算するコストが log2 n 回のキー比較のコストよりも小さくなければならない。暗号学的ハッシュ関数は、そういう意味では時間がかかりすぎる[要出典]。 決定性
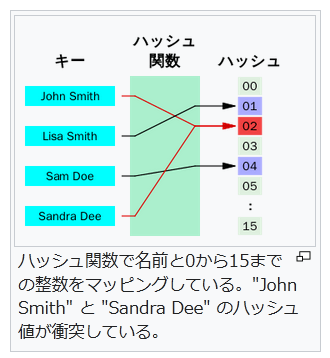
言い換えれば、典型的な m 個のレコードの集合を n 個のバケットにマッピングする場合、1つのバケットに対応するレコード数が m/n より大きくなる可能性をなるべく小さくすればよい。特に m が n より小さい場合、一部のバケットだけが1つまたはせいぜい2つのレコードを格納するようにすべきである。理想的な完全ハッシュ関数では、各バケットには最大でも1つのレコードしか格納されない。しかし、n が m よりずっと大きくても、衝突を完全に無くすことはできない(誕生日のパラドックスを参照)。
ハッシュ関数を評価する場合、ハッシュ値の分布の一様性はカイ二乗検定で評価できる[3]。 可変な値域
多くの用途では、プログラムを実行するたびにハッシュ値の範囲は変化するし、場合によっては1回の実行中にも範囲が変化することもある(ハッシュテーブルを拡張する必要が生じた場合など)。そのような場合、ハッシュ関数は2つのパラメータを入力する必要がある。1つは入力データ z で、もう1つは生成可能なハッシュ値の数 n である。
よくある方式は、非常に大きな値域(例えば 0 から 232−1)のハッシュ関数を用意し、その出力を n で割った余りを最終的な出力とする。n が2のべき乗なら、割り算ではなくビットマスクやビットシフトで代替できる。この方式を採用するなら、ハッシュ関数は n がいくつであっても、0 から n−1 の間でハッシュ値が一様に分布するようなものを選択する必要がある。関数によっては、奇数や素数など特定の n でないと余りが一様分布にならないこともある。 データ正規化
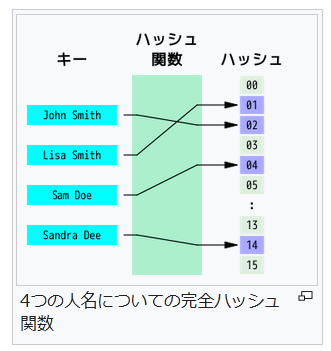
n 個のキーに対する完全ハッシュ関数が最小 (minimal) であるとは、その値域が n 個の連続な整数(通常 0 から n-1)の場合である。単に参照が単純化されるだけでなく、ハッシュテーブルもコンパクトになり、空きスロットができない。最小完全ハッシュ関数は単なる完全ハッシュ関数よりも求めるのが難しくなる。 一様に分布するデータのハッシュ技法
入力が制限された長さの文字列(例えば、電話番号、自動車のナンバー、送り状番号など)で、個々の入力値は独立にかつ一様な確率で発生する場合、ハッシュ関数は個々のハッシュ値にだいたい同じ個数の入力値をマッピングすればよい。例えば、入力 z が 0 から N−1 の範囲の整数、出力 h が 0 から n−1 の範囲の整数で、N が n より大きいとする。するとハッシュ関数としては、h = z mod n ( z を n で割った余り)、h = (z × n) ÷ N (z を n/N 倍して整数に丸めた値)、などの式が考えられる。 その他の分布のデータのハッシュ技法
入力の出現確率が一様でない場合や、独立性がない場合は、上のような単純な方式ではうまくいかない。例えば、あるスーパーマーケットの利用者は地理的に近い場所に集中しているため、電話番号の先頭数桁は同じになってしまう。その場合、(z × n) ÷ N の式では元の数値の上の桁が残るため、衝突が多発する。一方、z mod n の式では、末尾側の桁が残るため、この場合のハッシュ値の分布はこちらの方がよい。 可変長データのハッシュ技法
def make_hash(S0, b) S <- S0 // 状態を初期化 for k in 1..m do // 入力データ単位をスキャン: S <- F(S, b[k]) // データ単位 k を状態に結合 end return G(S, n) // 状態からハッシュ値を抽出 end
この手法は、テキストのチェックサムやフィンガープリントのアルゴリズムにも利用されている。状態変数 S は32ビットか64ビットの符号無し整数である。例の場合、S0 は 0 でよいし、G(S,n) は単に S mod n でよい。最適な F の選択は難しい問題で、データの性質にも依存する。データ単位 b[k] が1ビットなら、F(S,b) は例えば次のようになる。
def F(S, b) return if highbit(S) == 0 then 2 * S + b else (2 * S + b) ^ P end
ここで highbit(S) は S の最上位ビットを意味し、’*’ 演算子は符号無しの整数の乗算でオーバーフローを無視する操作を表す。’^’ はビット単位の排他的論理和演算を表し、P は適当な固定のワードである[4]。 特定用途のハッシュ関数
多くの場合ヒューリスティクスを利用して、汎用のハッシュ関数よりも特定用途で衝突を削減できるハッシュ関数を設計できる。例えば、入力が FILE0000.CHK、FILE0001.CHK、FILE0002.CHK などのファイル名で、多くの場合このような一連の番号が名前に含まれているとする。すると、ファイル名から番号部分 k を抜き出し、k mod n をハッシュ値とすれば、ほぼ最適な結果が得られる。言うまでもないが、特定の入力に最適化したハッシュ関数は、それ以外の分布を示す入力に対しては非常に悪い結果を生じる。 ハッシュとしてのチェックサム関数
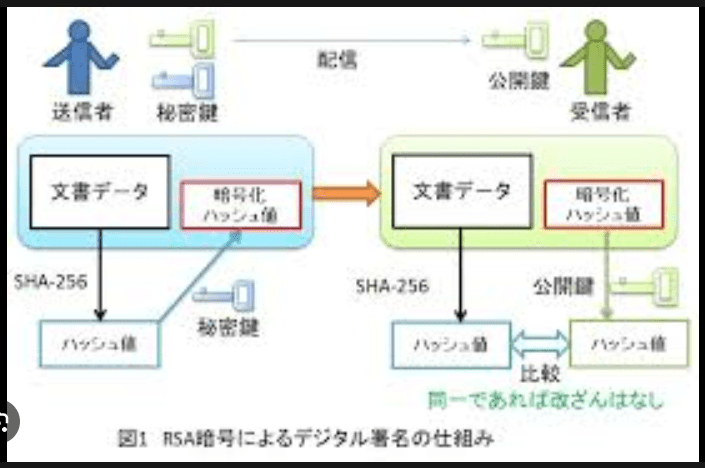
チェックサムやフィンガープリント用のアルゴリズムをハッシュ関数として採用することもできる。それらのアルゴリズムの一部は、任意長の文字列データ z から32ビットまたは64ビットのビット列を生成するので、そこから 0 から n-1 のハッシュ値を容易に抽出できる。
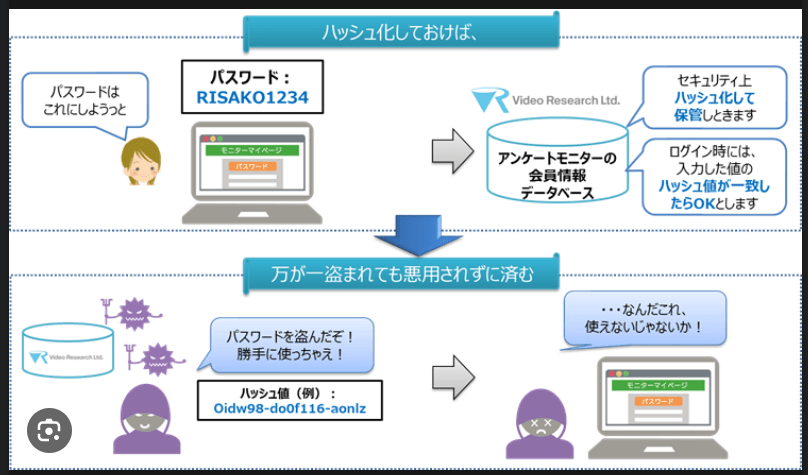
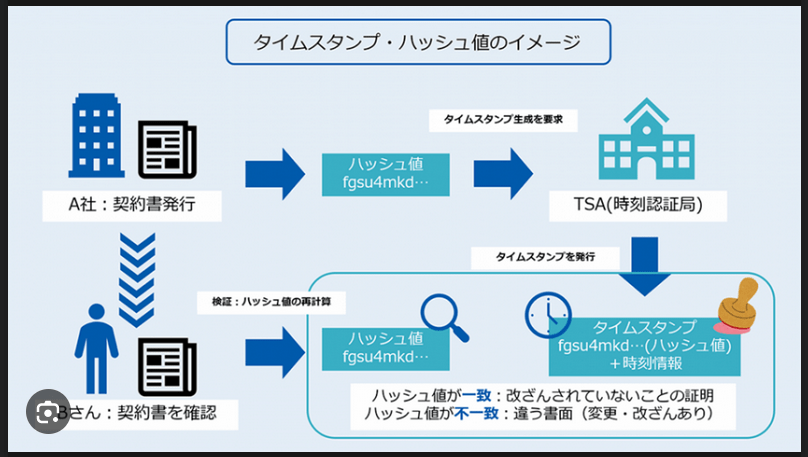
この手法は、ハッシュ値の範囲 n がチェックサムやフィンガープリント関数の値域より十分小さい場合に限って、十分一様に分布するハッシュ値を生成する。しかし、一部のチェックサムは雪崩効果が弱いため、用途によっては不向きである。よく使われているCRC32チェックサムは、上位16ビットだけがハッシュ用途に使える。さらに言えば、入力の各ビットはCRC32の1つのビットにのみ影響を与える。したがって、32ビットのチェックサムをそのままハッシュ値に利用する場合は十分な注意が必要である[5]。 暗号学的ハッシュ関数
ドナルド・クヌースによれば、この用語を最初に使ったのはIBMの Hans Peter Luhn で、1953年1月の社内メモで使っていた。そして、Robert Morris が学会誌 Communications of the ACM に掲載した論文でこの用語を使い、単なるジャーゴンから正式な専門用語に昇格した[7]。 脚注・出典
^ https://kotobank.jp/word/要約関数-653412
^ "Robust Audio Hashing for Content Identification" by Jaap Haitsma, Ton Kalker and Job Oostveen
^ Bret Mulvey, Hash Functions. Accessed April 11, 2009
^ A. Z. Broder. Some applications of Rabin's fingerprinting method. In Sequences II: Methods in Communications, Security, and Computer Science, pages 143--152. Springer-Verlag, 1993
^ Bret Mulvey, Evaluation of CRC32 for Hash Tables, in Hash Functions. Accessed April 10, 2009.
^ Bret Mulvey, Evaluation of SHA-1 for Hash Tables, in Hash Functions. Accessed April 10, 2009.
^ Knuth, Donald (1973). The Art of Computer Programming, volume 3, Sorting and Searching. pp. 506–542
Hash Functions and Block Ciphers by Bob Jenkins
Integer Hash Function by Thomas Wang
The Goulburn Hashing Function - ウェイバックマシン(2009年3月19日アーカイブ分) (PDF) by Mayur Patel
Hash Functions by Paul Hsieh
実装
GNU gperf
General purpose hash function algorithms (C/C++/Pascal/Java/Python/Ruby)
The Murmur Hash Function by Austin Appleby
HSH 11/13 by Herbert Glarner
FNV Fowler, Noll, Vo Hash Function
qDecoder's C/C++ hash functions — オープンソースのライブラリ
^ a b c d “ケンブリッジ・アナリティカとは”. 日本経済新聞 (2018年3月21日). 2018年3月21日閲覧。
^ “英選挙コンサルが破産=FB情報不正入手の疑い”. 時事通信. (2018年5月3日) 2018年5月3日閲覧。[リンク切れ]“"FB個人情報流出 不正疑惑の英企業が全業務停止 破産申請へ 米大統領選と英国民投票に利用?"”. 産経新聞社. (2018年5月3日) 2019年7月8日閲覧。
^ a b Calabresi, Massimo (2017年5月19日). “Inside Russia's Social Media War on America”. 2017年8月8日閲覧。
^ “Trump campaign's digital director agrees to meet with House Intel Committee”. ポリティコ (2017年7月14日). 2017年8月8日閲覧。
^ https://www.wsj.com/articles/u-s-eyes-michael-flynns-links-to-russia-1485134942
^ https://www.nytimes.com/aponline/2017/08/04/us/politics/ap-ustrump-russia-probe-flynn.html
^ Mayer, Jane (2017年3月17日). “The Reclusive Hedge-Fund Tycoon Behind the Trump Presidency”. The New Yorker. ISSN 0028-792X 2018年3月20日閲覧。
^ a b c d “Cambridge Analytica's Facebook data abuse shouldn't get credit for Trump”. The Verge 2018年3月20日閲覧。
^ Trump, Kris-Stella (2018年3月23日). “Analysis | Four and a half reasons not to worry that Cambridge Analytica skewed the 2016 election” (英語). Washington Post. ISSN 0190-8286 2018年3月23日閲覧。
^ Nyhan, Brendan (2018年2月13日). “Fake News and Bots May Be Worrisome, but Their Political Power Is Overblown”. The New York Times. ISSN 0362-4331 2018年3月20日閲覧。
^ “Cambridge Analytica Was Doing Marketing, Not Black Magic”. Reason. (2018年3月19日) 2018年3月19日閲覧。
^ a b Fovind Krishnan V. (June 3,2017). “Aahaar in the head of psies Big Data, global surveillance state and the identity project”. Fountain Ink Magazine 2017年8月27日閲覧。
^ a b c Confessore, Nicholas; Hakin, Danny (2017年3月6日). “Data Firm Says 'Secret Sauce' Aided Trump; Many Scoff”. The New York Times. ISSN 0362-4331 2017年3月7日閲覧。
^ a b Davies, H (2015年12月11日). “Ted Cruz using firm that harvested data on millions of unwitting Facebook users”. Guardian 2016年2月7日閲覧。
^ a b Michael Biesecker, Julie Bykowicz (2016年2月11日). “Cruz app data collection helps campaign read minds of voters”. Associated Press 2016年2月13日閲覧。
^ Dwoskin, Elizabeth (2018年3月16日). “Facebook bans Trump campaign's data analytics firm for taking user data”. The Washington Post. "Facebook said it was suspending the accounts of Strategic Communication Laboratories, the parent company of Cambridge Analytica, as well as the accounts of a University of Cambridge psychologist Aleksandr Kogan, and Christopher Wylie of Eunoia Technologies, Inc. Cambridge Analytica, a firm specializing in using online data to create voter personality profiles in order to target them with messages, ran data operations for Trump's presidential campaign."
^ “Trump Campaign Pays Millions to Overseas Big Data Firm”. NBC News (November 4,2016). November 5,2016閲覧。
^ a b Mayer, Jane (March 27, 2017). “The Reclusive Hedge-Fund Tycoon Behind the Trump Presidency: How Robert Mercer exploited America's populist insurgency”. The New yorker., Reporter at Large
訳注
^ 消費者を心理的属性をもとに説明するための手法のこと。
^ a b c いずれも企業名を表す固有名詞。英語版では今のところ簡単な説明だけの記事が多い。
『本書の原題は“Targeted: The Cambridge Analytica Whistleblower’s Inside Story of How Big Data, Trump, and Facebook Broke Democracy and How It Can Happen Again”(『ターゲットにされて ケンブリッジ・アナリティカ内部告発者のインサイドストーリー。ビッグデータ、トランプ、フェイスブックはどのように民主政を破壊し、それはどのようにもういちど起きるか』)。Targetedとは、自分がターゲットにされたことと、ケンブリッジ・アナリティカが有権者をターゲットに選挙結果を操作していることをかけているのだろう。』
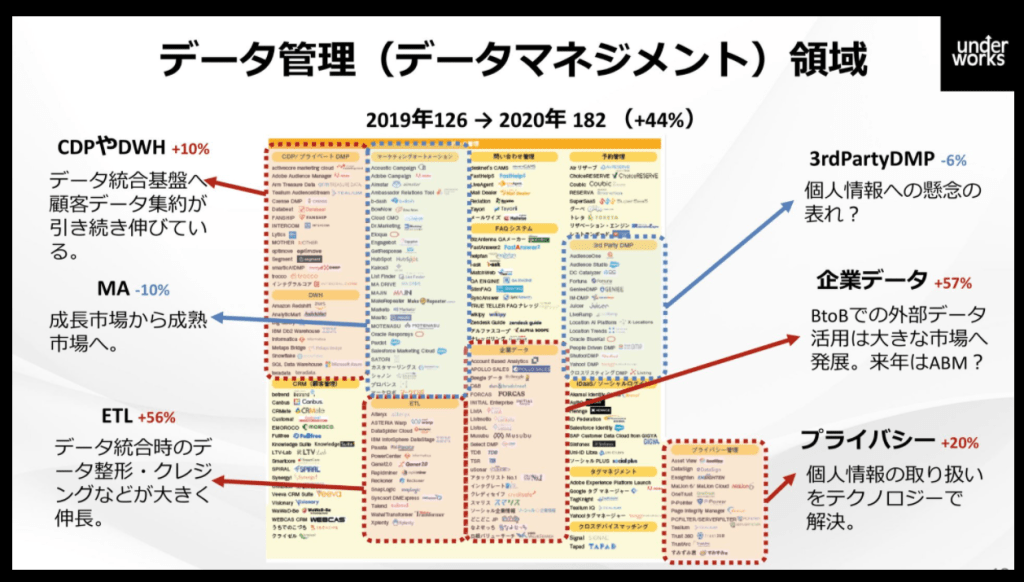
『デジタルマーケティングの支援を行うアンダーワークス(東京都港区)は9月15日、国内の主要マーケティングテクノロジーを分類してまとめた「マーケティングテクノロジーカオスマップ JAPAN 2020」を公開した。コロナ禍を受けて、マーケティングや営業の手法が対面からオンラインに急速にシフトしてきており、関連のサービスが大きく伸びた。
また、自社以外の企業が集めたユーザーデータを使った「3rd Party DMP」は、個人情報の取り扱いに関する懸念などから数が減った。一方で、「プライバシー」関連のテクノロジーは20%増加している。「GDPRやカリフォルニア州消費者プライバシー法(CCPA)、改正個人情報保護があり、個人情報の取り扱いに関心が増えている」(田島氏)』