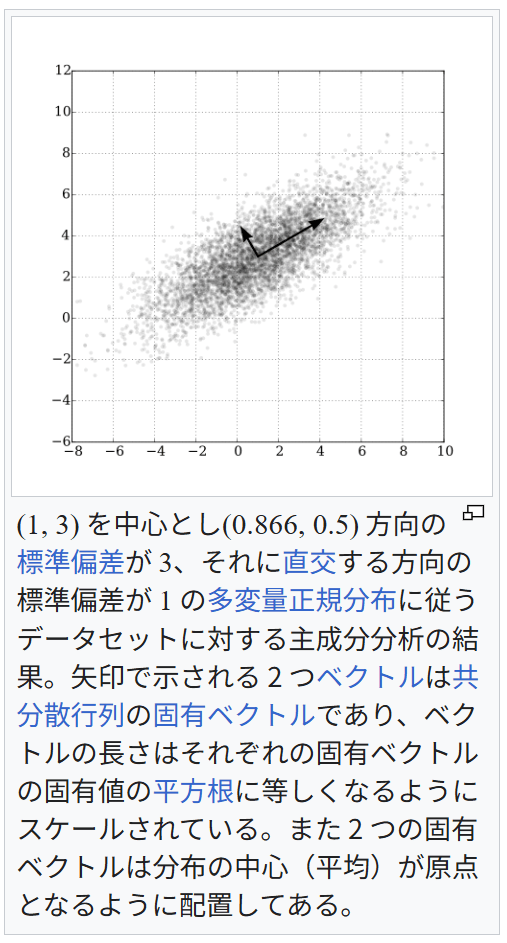
直感的な説明 主成分分析は与えられたデータを n 次元の楕円体にフィッティングするものであると考えることができる。このとき、それぞれの主成分は楕円体の軸に対応している。楕円体の軸が短いほどデータの分散は小さく、短い軸に対応する主成分を無視することで、データの分散と同程度に小さな情報の損失だけで、データをより少ない変数で表現することができる。
楕円体の軸を見つけるには、データの平均を座標軸の原点に合わせる必要がある。そのため、データの共分散行列を計算し、共分散行列に対する固有値と固有ベクトルを計算する。また、それぞれの固有ベクトルを直交化し、正規化する必要がある。固有ベクトルの組として互いに直交する単位ベクトルが得られたなら、それらに対応する軸を持つ楕円体によってデータをフィッティングすることができる。それぞれの軸に対する寄与率(proportion of the variance: 分散の比)は、その軸に対応する固有ベクトルに対する固有値を、すべての固有値の和で割ったものとして得ることができる。
歴史と名称 主成分分析は1901年にカール・ピアソンによって導入された[4]。ピアソンは力学における主軸定理(英語版)からの類推によって主成分分析の方法を得た。主成分分析は、ピアソンとは独立に1930年代にハロルド・ホテリングよっても導入され、ホテリングによって主成分分析 (principal component analysis) と呼ばれるようになった[5][6]。(Jolliffe (2002, 1.2 A Brief History of Principal Component Analysis) 参照。)
以下では、データ行列 X として、各列の標本平均が 0 になるものを考える[注 9]。データ行列の各列 p はそれぞれデータが持つ特定の指標に対応し、データ行列の各行 n はそれぞれ異なる事例に対する指標の組を表す[注 10]。
主成分分析は p 次元ベクトル wk によってデータ行列 X の各行 xi を主成分得点のベクトル t(i) = (t1, …, tk)(i) に変換することであり、主成分得点tk(i) はデータ点 xi と負荷量ベクトル wk の内積によって与えられる。
t k ( i
)
x i ⋅ w k {\displaystyle {t_{k}}{(i)}=\mathbf {x} {i}\cdot \mathbf {w} _{k}} 負荷量ベクトル w は単位ベクトルであり、各主成分得点の分散を第一主成分から順に最大化するように選ばれる。負荷量ベクトルの個数(つまり主成分の数)k は、元の指標の数 p に等しいか、より小さい数が選ばれる (k ≤ p)。負荷量ベクトルの個数、つまり新しいデータ空間の次元を元の空間の次元より少なくとることで、次元削減をすることができる(#次元削減を参照)。主成分分析による次元削減は、データの分散に関する情報を残すように行われる。
第一主成分 第一主成分に対応する負荷量ベクトル w1 は以下の条件を満たす[注 11]。
w
1
a r g m a x ‖ w
‖
1 ‖ X w ‖ 2 . {\displaystyle \mathbf {w} _{1}={\underset {\Vert \mathbf {w} \Vert =1}{\operatorname {arg\,max} }}\Vert \mathbf {Xw} \Vert ^{2}.} さらに変数 w が単位ベクトルという制約を除けば、上述の条件は次の等価な条件に簡約化することができる[注 12]。
w
1
a r g m a x w ≠ 0 ‖ X w ‖ 2 ‖ w ‖ 2 . {\displaystyle \mathbf {w} _{1}={\underset {\mathbf {w} \neq \mathbf {0} }{\operatorname {arg\,max} }}{\frac {\Vert \mathbf {Xw} \Vert ^{2}}{\Vert \mathbf {w} \Vert ^{2}}}.} 右辺の最大化される量は XTX に対するレイリー商と見ることができる。XTX は対称行列だから、レイリー商の最大値は行列の最大固有値となり、それに伴い負荷量ベクトルは対応する固有ベクトルとなる。
第一負荷量ベクトル w1 が得られれば、データ点 xi に対応する主成分得点 t1(i) = xi · w1、あるいは対応するベクトル (xi · w1)w1 が得られる。
他の主成分 k 番目の主成分は k − 1 番目までの主成分をデータ行列 X から取り除くことで得られる:
X ^
k
X − ∑
s
1 k − 1 X w s w s T . {\displaystyle \mathbf {\hat {X}} {k}=\mathbf {X} -\sum {s=1}^{k-1}\mathbf {X} \mathbf {w} {s}\mathbf {w} {s}^{\rm {T}}.} 負荷量ベクトルは新たなデータ行列に対して主成分得点の分散が最大となるようなベクトルとして与えられる。
w
k
a r g m a x ‖ w
‖
1 ‖ X ^ k w ‖
2
a r g m a x w ≠ 0 ‖ X ^ k w ‖ 2 ‖ w ‖ 2 . {\displaystyle \mathbf {w} {k}={\underset {\Vert \mathbf {w} \Vert =1}{\operatorname {arg\,max} }}\Vert \mathbf {\hat {X}} {k}\mathbf {w} \Vert ^{2}={\underset {\mathbf {w} \neq \mathbf {0} }{\operatorname {arg\,max} }}{\tfrac {\Vert \mathbf {\hat {X}} _{k}\mathbf {w} \Vert ^{2}}{\Vert \mathbf {w} \Vert ^{2}}}.} このことから、新たな負荷量ベクトルは対称行列 XTX の固有ベクトルであり、右辺の括弧内の量の最大値は対応する固有値を与えることが分かる。したがって、すべての負荷量ベクトルは XTX の固有ベクトルである。
データ点 xi の第 k 主成分は主成分得点 tk(i) = xi · wk として負荷量ベクトルを基底とする表示が与えられ、また対応するベクトルは主成分得点に対応する基底ベクトルをかけた (xi · wk) wk となる。ここで wk は行列 XTX の第 k 固有ベクトルである。
X の完全な主成分分解は以下のように表わすことができる。
T
X W {\displaystyle \mathbf {T} =\mathbf {X} \mathbf {W} } ここで W は p × p の正方行列であり、各列ベクトルは行列の XTX の固有ベクトルであり単位ベクトルである。
1 n t k ( i ) 2 . {\displaystyle \lambda {k}=|\mathbf {X} \mathbf {w} {k}|^{2}=\sum {i=1}^{n}(\mathbf {x} {i}\cdot \mathbf {w} {k})^{2}=\sum {i=1}^{n}t_{k(i)}^{2}.} 行列 W が得られれば、行列 W の直交性を利用して、主成分ベクトルを基底とする経験共分散行列として次の表示が得られる。
W T Q W ∝ W T W Λ W T
W
Λ . {\displaystyle \mathbf {W} ^{\mathrm {T} }\mathbf {Q} \mathbf {W} \propto \mathbf {W} ^{\mathrm {T} }\mathbf {W} \,\mathbf {\Lambda } \,\mathbf {W} ^{\mathrm {T} }\mathbf {W} =\mathbf {\Lambda } .} 次元削減 線型変換 T = XW はデータ点 xi を元の p 次元の空間から、与えられたデータセットに対して各成分が互いに無相関になるような p 次元の空間へ写すが、一部の主成分だけを残すような変換も考えることができる。第一主成分から順に、各主成分に関するデータの分散が単調減少するように負荷量ベクトルが得られるため、最初の L 個の負荷量ベクトルだけを残し、残りの説明能力の低い負荷量ベクトルを無視すると、次のような変換が得られる。
T
L
X W L {\displaystyle \mathbf {T} {L}=\mathbf {X} \mathbf {W} {L}} WL は p × L の行列であり、TL は n × L の行列である。上記の変換はデータ点 x ∈ Rp に対する変換として[注 13]、t = WTx (t ∈ RL) と書くこともできる。つまり、主成分分析は p 個の特徴量を持つデータ点 x を L 個の互いに無相関な特徴量を持つ主成分得点 t へ写す線型変換 W : Rp → RL を学習する手法であるといえる[10]。 データ行列を変換することで得られる主成分得点行列は、元のデータセットの分散を保存し、二乗再構成誤差 (reconstruction error) の総和、
‖ T W T − T L W L T ‖ 2 2 ( ‖ X − X L ‖ 2 2 ) {\displaystyle |\mathbf {T} \mathbf {W} ^{\mathrm {T} }-\mathbf {T} {L}\mathbf {W} {L}^{\mathrm {T} }|_{2}^{2}\qquad (|\mathbf {X} -\mathbf {X} {L}|{2}^{2})} を最小化するように与えられる。
354の個体について、37のY染色体STRマーカーの反復回数から計算された Y-STR(英語版) ハプロタイプに対する主成分分析の結果。主成分分析により、個体のY染色体の遺伝的な系統についてクラスタリングするようなマーカーの線型結合を得ることに成功している。 元のデータセットの分散をできる限り残すように次元削減することは、高次元のデータセットを可視化する上で重要である。例えば、主成分の数を L = 2 に選び、2つの主成分がなす平面にデータセットを射影すると、射影されたデータ点は主成分のなす平面に対して最もよく分散し、データに含まれるクラスタはそれぞれ分離される。したがって、2つの主成分がなす平面はデータを平面上にプロットする上で都合がよい。射影平面として別の平面を選んだ場合、クラスタ間のばらつきは小さくなり互いに重なり合うようになるため、実質上はそれぞれのクラスタを分類することが困難になってしまう。
次元削減はノイズの大きなデータを分析する上でも適切であることが多い。データ行列の各列、つまりそれぞれの特徴量に対して独立同分布なガウシアンノイズが含まれる場合、変換されたデータ行列 T の列にも同様に独立同分布なガウシアンノイズが含まれる(座標軸の回転操作 W に対して独立同分布なガウス分布は不変であるため)。しかしながら、最初の少数の主成分に関しては、全体の分散に比べてノイズに由来する分散が小さくなるため、シグナル・ノイズ比を高めることができる。主成分分析は主要な情報を少数の主成分に集中させるため、次元削減によってノイズが支配的な成分だけを捨て、データ構造を反映した有用な成分を取り出すことができる。
特異値分解 主成分変換は行列の特異値分解とも結び付けられる。行列 X の特異値分解は以下の形式で与えられる。
X
U Σ W T . {\displaystyle \mathbf {X} =\mathbf {U} \mathbf {\Sigma } \mathbf {W} ^{\mathrm {T} }.} ここで、Σ は n × p の矩形対角行列であり、対角成分 σk が正の行列である。Σ の対角成分を行列 X の特異値という。U は n × n の正方行列であり、各列が互いに直交する n 次元の単位ベクトル[注 14]となる行列(つまり直交行列)である。各々の単位ベクトルは行列 X の左特異ベクトルと呼ばれる。同様に W は、各列が互いに直交する p 次元の単位ベクトルとなる p × p の正方行列である。こちらの単位ベクトルは行列 X の右特異ベクトルと呼ばれる。
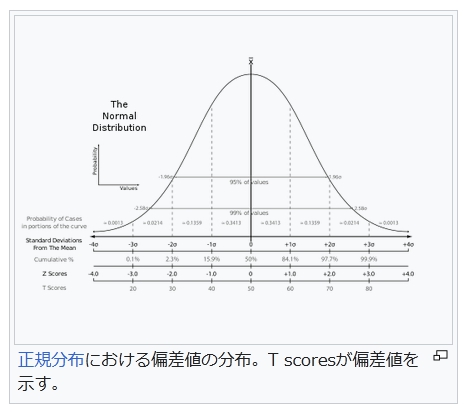
T i = 10 ( x i − μ x ) σ x + 50 {\displaystyle T_{i}={\frac {10(x_{i}-\mu _{x})}{\sigma _{x}}}+50}
ここで、
μ x = 1 N ∑ i = 1 N x i σ x = 1 N ∑ i = 1 N ( x i − μ x ) 2 = 1 N ∑ i = 1 N x i 2 − μ x 2 {\displaystyle {\begin{aligned}&\mu _{x}={\frac {1}{N}}\textstyle \sum \limits _{i=1}^{N}x_{i}\\&\sigma _{x}={\sqrt {{\frac {1}{N}}{\textstyle \sum \limits _{i=1}^{N}(x_{i}-\mu _{x})^{2}}}}={\sqrt {{\frac {1}{N}}{\textstyle \sum \limits _{i=1}^{N}{x_{i}}^{2}-{\mu _{x}}^{2}}}}\\\end{aligned}}}
N:データの大きさ、xi:データの各値、μx:平均値、σx:標準偏差
なお、分子 xi − μx は偏差である。特に、値 xi が平均値 μx に等しいときは、偏差が 0 となり、偏差値は 50 となる。また、値 xi が全て等しいときは、標準偏差 σx = 0 となり、偏差値がこの式では定義できない。この場合、値の偏差値を全て 50 とする[5]。
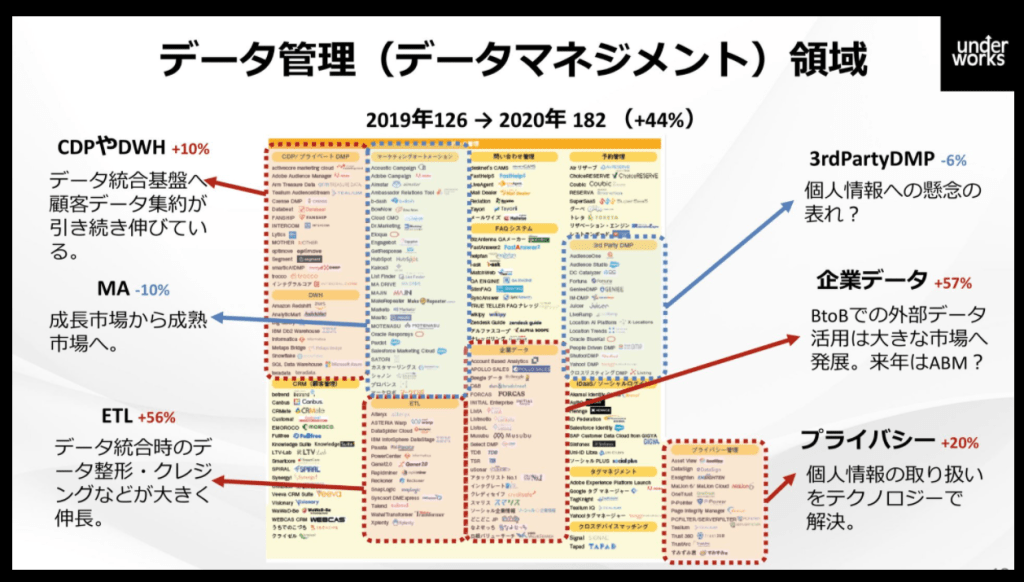
『デジタルマーケティングの支援を行うアンダーワークス(東京都港区)は9月15日、国内の主要マーケティングテクノロジーを分類してまとめた「マーケティングテクノロジーカオスマップ JAPAN 2020」を公開した。コロナ禍を受けて、マーケティングや営業の手法が対面からオンラインに急速にシフトしてきており、関連のサービスが大きく伸びた。
また、自社以外の企業が集めたユーザーデータを使った「3rd Party DMP」は、個人情報の取り扱いに関する懸念などから数が減った。一方で、「プライバシー」関連のテクノロジーは20%増加している。「GDPRやカリフォルニア州消費者プライバシー法(CCPA)、改正個人情報保護があり、個人情報の取り扱いに関心が増えている」(田島氏)』