

ためになる3Dグラフィックスの歴史(6)。AI技術の進化にGPGPUがもてはやされる背景
https://pc.watch.impress.co.jp/docs/column/zenji/1493893.html
※ 「なぜ、AIの実装に、GPUが用いられるようになったのか」の背景の一端が語られている…。
※ 長年の疑問が、ある程度解消した…。
※ 『マシンラーニング型AIの形成過程(≒学習過程)、そしてそのAIを活用過程(≒推論過程)において、この畳み込み演算を、大量に行なうことになる。
畳み込み演算は、実務的には「行列同士の掛け算」なので、この計算はGPUが内包する膨大な「プログラマブルシェーダ実行ユニット」(つまりはシェーダプログラム実行ユニット)でそのまま演算可能なのだ。
すなわち、GPUをGPGPU的に活用すれば、膨大なデータ量の畳み込み演算が高速に行なえるわけで、だからこそ、AI技術開発にGPUが引っ張りだことなったわけである。』…、という部分がキモか…。
※ 『ただ、GPUは、もともと3Dグラフィックスを描画するためのプロセッサだ。畳み込み演算専用機として利用するには、シェーダプログラム実行ユニットには、テクスチャユニットを始めとしたグラフィックス描画支援機能がたくさん接続されている。
NVIDIAは、「GPGPU業界の方々がそこまで熱望するならば」……ということで、シェーダプログラム実行ユニットから余計な機能をバッサリとカットした畳み込み演算実行専用ユニットを、2017年発表のVolta世代のGPU「GV100」から搭載した。
Quadro GV100
そう、それが言わずと知れた「Tensorコア」である。実は「推論アクセラレータ」の異名を持つTensorコアだが、実際に行なえるのは畳み込み演算(行列の乗算)だけ。
Tensorコアは、実はシンプルに畳み込み演算器に相当する』…。
※ 内部回路的には、ここがキモか…。かつ、NVIDIA一強となったキモでも、あるのか…。




























『 トライゼット西川 善司 2023年4月17日 06:05
2022年3月、NVIDIAはその当時で世界最高性能のGPU「GH100」を発表。GPGPU専用として提供された。3Dグラフィックスを処理できないわけではないが、基本的にはGPGPUでの利用が想定されたプロセッサである。GPGPUセンセーションは、現在進行形で産業を席巻しつつある
前回は、熟成を極めたDirectX 11と、「別バージョンのDirectX 11」として誕生したDirectX 12を紹介した。そしてこのDirectX 12がDirectX 11と併存することになった経緯、DirectX 12が誕生した時勢などについても解説しつつ、最後は近代GPUの基本技術基盤である「プログラマブルシェーダ」技術が進化していった結果、新概念「GPGPU」技術が誕生したことにも触れた。
今回は、現在このGPGPU技術が、GPUにとって「3Dグラフィックス描画」に優るとも劣らぬほどに「重要なGPUの活用先」となってきている状況について深掘りしていきたい。
実は、昨今の「人工知能ブーム」や「自動運転技術の発展」は、このGPGPUという概念が誕生しなければ、ここまで急速に進歩しなかったかもしれないと言われている。
「ゲームの映像を描画すること」が主な仕事だったGPUが、どのようにして人工知能や自動運転といった技術開発に関係していったのか、その流れを振り返っていくことにしよう。
今回は、かなり話が方々へと脱線していくが、このシリーズのまとめということで、あらかじめご了承いただきたい(笑)。
GPGPUが巻き起こしたマシンラーニング型AIのビックバン現象
その筋の研究者達が、GPGPU技術をマシンラーニング(機械学習)型AIの実現に応用し始めたのは、2010年前後くらいからだとされる。
そして、昨今のAIブームの直接のきっかけは、2012年に起きた「ある象徴的な事件」ではないか、とも言われている。
スタンフォード大学が2010年より立ち上げた大規模な画像データベースに「ImageNet」というものがあり、当時約1,400万枚におよぶ膨大な画像データベースから課題として抽出された約50万枚の画像を学習し、その学習を完了したAIに対して約2万枚の試験画像を見せ、「これがなんであるか」を推論させる画像認識AIの競技「ImageNet Large Scale Visual Recognition Challenge」(ILSVRC)が毎年行なわれていた。
ちなみに、この競技自体は2017年が最後の開催となっている。
この「AIの画像認識力の優劣を競う競技」の2012年大会において、トロント大学のAlex Krizhevsky氏らが、GeForce GTX 580×2基構成のGPGPUマシン(要は2GPU構成のPC)で、平均的な人間の正解率を超える結果をはじき出して優勝した。
なお、優勝したマシンラーニング型AIの実装手法についてまとめた論文は「ImageNet Classification with Deep Convolutional Neural Networks」としてまとめられている。
NVIDIAのCEO、ジェンスン・フアン氏も、後年この2012年の出来事を「マシンラーニング型AIの世界にビッグバンが起きた」と語っている。
この事件以降、マシンラーニング型AIはKrizhevsky氏が行なった実装手法に倣うようになり、進化と発展が一気に加速する。
NVIDIAが毎年開催しているGPU技術を主題にしたカンファレンス「GTC 2015」にて、ジェンスン・フアン氏(Co-Founder and CEO, NVIDIA)は、マシンラーニングの一形態である「ディープラーニング」(深層学習)が急成長していることをアピールした
CNN(Convolutional Neural Network : 畳み込みニューラルネットワーク)の論文が発表されたのは1998年だが、2012年のAlex Krizhevsky氏らの論文以降で劇的に研究開発が活発化したことに言及し、ジェンスン・フアン氏は、Krizhevsky氏らの論文が「マシンラーニング界にビッグバンをもたらした」と表現した
また、2014年にはスタンフォード大学のAndrej Karpathy氏らが、画像を見せると流暢な英語でその画像の内容を解説する作文生成タイプのマシンラーニング型AIを発表した。これはまさに、昨今大ブームになっている対話型AIの源流に相当する研究だと言える。
AIに鳥が写っている画像を入力すると、単に主題としての「鳥」だけを認識するのではなく、その画像中に描かれているすべてのオブジェクトを認識して、各オブジェクトの関係性を解釈して「鳥が木の枝に止まっています」と作文にまとめることができるAIが発表されたのだ。この論文は以下の動画で紹介されている。
スタンフォード大学のAndrej Karpathy氏らの論文「Automated Image Captioning with ConvNets and Recurrent Nets」からの抜粋。写真を見せられた学習型AIがかなり的確な英作文を披露する事例。学習した知識にないものが示されると間違えることもある。「赤ちゃんの例」はそのささやかな誤り例。
人間に拮抗する人工知性がビジネスになる予感は10年前から?
ChatGPTに代表される、言語処理系AIの「凄み」は、実は今から10年以上前からその片鱗が現れていた。
2011年、アメリカのTVクイズ番組「Jeopardy!」の全米チャンピオン大会に、IBMの研究グループが開発したマシンラーニング型AI「Watson」を出場させたところ、人間の挑戦者達を抑えて優勝したことがある。
アメリカのTVクイズ番組「Jeopardy!」の全米チャンピオン大会にIBM製のAI「Watson」が挑戦した
とは言っても、当時出題された問題のAIへの入力は、音声認識経由ではなく、人間の手入力によるものだった。そのため、対等な対決ではなかったようだが、「AIが人間にクイズで勝つ」という事象は大きな驚きとして受け止められた。
この「Watson」を開発したIBMの研究グループのリーダーRob High氏(IBM Fellow,VP,CTO)によれば、2010年代の人間は1日あたり2.5エクサバイト(2,500,000テラバイト)のデータをネットワーク上のストレージ上に出力しており、これが2020年代には1日あたり44ゼタバイト(44,000,000,000テラバイト)に突入すると予測している。
また、High氏は、そうなったときに膨大なデータから人間の興味のある事柄を抽出したり、そこから分析を進めたり、あるいはそれらを組み合わせて新たなるコンテンツを創出したりするための手助けをしてくれる存在として、マシンラーニング型AIエージェントはいずれ不可欠な存在となるだろうと述べていた。
2020年代の今は、まさにそんな状況になりつつある。
IBMのAI「Watson」研究開発グループのリーダーRob High氏(IBM Fellow,VP,CTO)は「今(発言時は2016年)から10年以内に、ネットワーク上を往来するデータのすべてをAIが認知を取得して学習するサーバーシステムが運用される時代が来るはずだ」と予見した
こうした「AIに支援を受けるコンピューティングパラダイム」をIBMでは「COGNITIVE COMPUTING」と命名し、2013年に新しいジャンルのクラウドサービスとして事業化している(日本でのサービス開始は2016年から)。
現在直近のWatsonの応用事例は、IBMのWatson活用事例のページにまとめられている。
IBM自身も斬新な料理レシピを生成する「シェフ・ワトソン」などを稼動させ、話題を呼んだ。また、Watsonを幼児向けの知育玩具に応用した「CogniToys」などもリリースされた。
幼児の「なんで?」に応対できる能力を持つ知育玩具「CogniToys」シリーズ。登場時は話題にはなったが、シリーズが継続するほどの人気商品とならなかったようだ(笑)
ゲーム画面を見てプレイするゲームAIの誕生
2015年にはGoogle系の英国ベンチャーのDeepMind社が開発したAIに、クラシックなゲーム機「Atari 2600」のブロック崩し、インベーダーなど、全49種のゲームをルールを教えずにプレイさせ、以前のプレイよりもスコアが高かったら「そのプレイは良いプレイだった」という評価を与え、反復的にプレイさせて学習させたところ(いわゆる強化学習モデル)、半数以上のゲームにおいて人間のトッププレイヤーの腕前を上回った成果を報告した。
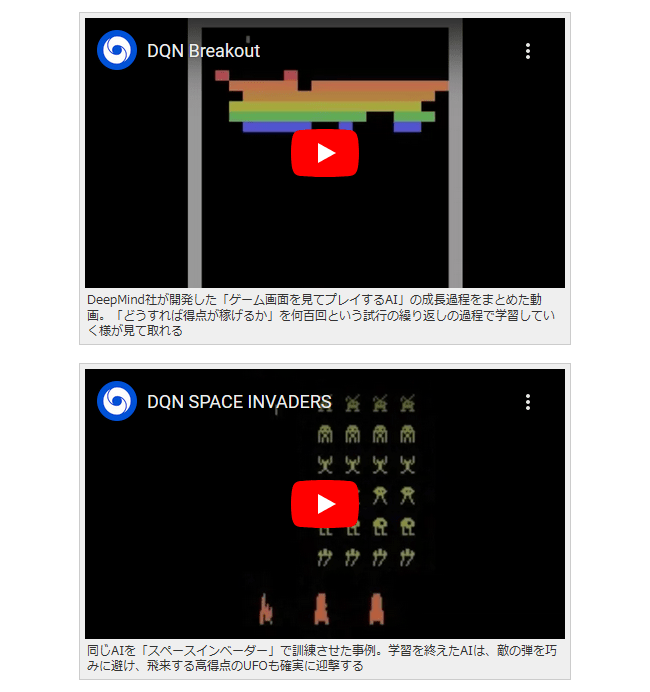
DeepMind社が開発した「ゲーム画面を見てプレイするAI」の成長過程をまとめた動画。「どうすれば得点が稼げるか」を何百回という試行の繰り返しの過程で学習していく様が見て取れる
同じAIを「スペースインベーダー」で訓練させた事例。学習を終えたAIは、敵の弾を巧みに避け、飛来する高得点のUFOも確実に迎撃する
2016年には、このDeepMindの開発したAI「AlphaGo」が、人類最強の囲碁プレイヤーとも言われる韓国人のイ・セドル九段を4勝1敗の戦績で打ち破ったニュースが世界を駆け巡った。
ちなみに、このAlphaGoは、前出のAtari 2600をプレイしたAIと仕組み的には同じで、AlphaGoは基本的には囲碁のルールを知らないという事実も、業界に大きな衝撃を与えた。
実は、AlphaGoは過去の膨大な上級者同士の対戦の棋譜の流れを「白石を白ピクセル」「黒石を黒ピクセル」とした「白黒画像の遷移データ」として学習し、最終局面において「これが勝ち」「これが負け」という「流れの筋」を学習して構築されたAIだった。
なので、囲碁というゲームのルールそのものを深く理解はしていない。セドル九段が唯一勝利を収めた第4局は、中盤でAlphaGoが学習した膨大な過去の棋譜にないと推測される“奇手”を打ったことが勝因につながったと分析されている。
囲碁の基本ルールすら知らなかったAlphaGoの弱点を突いてセドル九段は勝利したというわけである。SF漫画みたいな話でちょっとカッコイイ逸話である。
日本におけるマシンラーニング型AIのゲームへの導入事例
日本においても、コンピュータゲームに対するAIの導入の研究は盛んだ。
2019年に開催されたCEATEC 2019において、バンダイナムコは縦スクロールシューティングゲームの名作「ゼビウス」をプレイするAIロボを発表した。
このAIは、前出のDeepMindが開発したゲームプレイAIとほぼ同方針の「教師なしAI」×「強化学習型AI」として開発されたものになる。
つまり、AIはゲームのルールを一切教えられていない赤子状態でゼビウスをプレイさせられ「良い行動」をしたら「えらいぞ」と褒美を与えて訓練を繰り返し、開発されたものになる。
学習にあたっては「実際のゲーム画面の15fps単位の画像」(一部処理しやすいように画像を低解像度化+鮮鋭化)を入力情報とし、「ゲーム画面に反応したレバー/ボタン操作」を出力情報としていた。
「Q56」(きゅうごろう)と名付けられたゼビウスAIプレイヤーロボ。実際の頭脳はこの白い展示台の下に隠されたデスクトップPC。Q56がアケコンを操作しているように見えるが、実はアケコン側の方が動いていて、Q56の腕の方が動かされている仕組み。ただ、展示中のゲーム画面が推論エンジンに入力され、リアルタイムにレバー/ボタン操作を出力しているので、AIデモとしてインチキはない
開発最初期の報酬授与条件は「高得点」だったが結果が振るわず。しかし開発後期「生存時間」に改めたところ、プレイが急激に洗練されたとのこと。ただ、あまりにも上手すぎても展示としておもしろみがないため、ブースではときどき失敗する学習レベルの低いAIをあえてお披露目したとしている。ちなみに、自機が死ぬとこちらに顔を向けて困った顔をする
我々がPCやゲーム機で普段プレイしているようなコンピュータゲームに対しても、マシンラーニング型AIの導入の研究は行なわれている。
特に興味深いのは、対人戦を想定したバトルAIの研究で、それらのAIは我々人間が実際に対人戦をプレイするように「その時点での戦局(ゲーム状況)」を理解した上で、AIが的確に方向レバー入力とボタン操作を行なわせて戦うものである。
まず、先陣を切って商品化にまで漕ぎ着けたのがSNKだ。同社が2019年に発売した「サムライスピリッツ」(以下、サムスピ)で、そのAIプレイヤーが実装されている。
SNKの公式サイトに掲載されているサムスピのゴーストモードの紹介
サムスピでは、プレイヤーという存在をシンプルな入出力演算器として考えているのが興味深い。
具体的には、プレイヤーについて「1フレーム単位のゲーム状況」を入力情報として与えてやると、「レバー操作とボタン押し」を出力する演算器と見なすのである。
なお、AIが出力する「レバー操作とボタン押し」は、あくまで「そういう操作をした」と見なされるゲーム操作データになる。物理的に実在するコントローラのレバーやボタンをロボットハンドが操作するわけではない。
ここで言う「ゲーム状況」とは具体的には、闘い合う2体の両キャラ位置とモーション状態、両者のゲージ状態、残り時間、現ラウンド数(ラウンド取得状況)などを指す。
サムスピでは、人間がサムスピを遊んだ際の「1フレーム単位のゲーム状況」とそのプレイヤーの「レバー操作とボタン押し」をマシンラーニングさせることで、そのプレイヤーのプレイスタイルを模倣するAI(ゲーム内ではゴーストと呼称)を構築する機能を搭載したのだ。
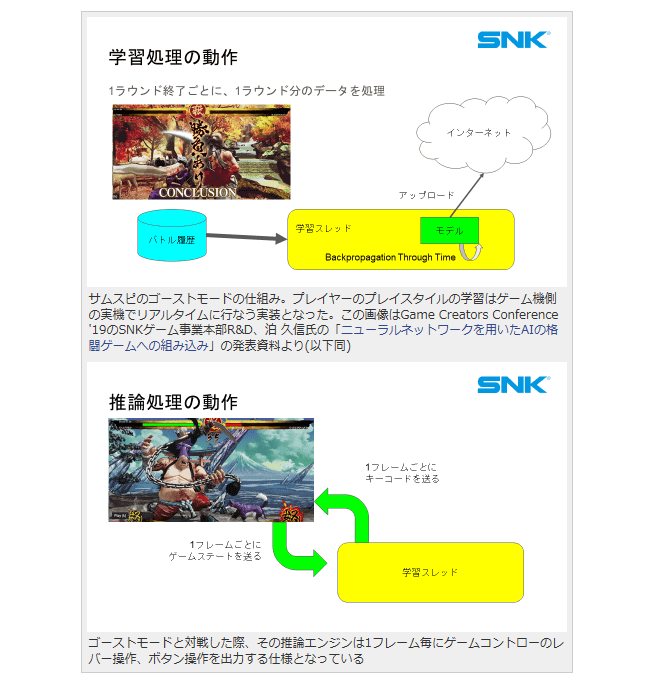
サムスピのゴーストモードの仕組み。プレイヤーのプレイスタイルの学習はゲーム機側の実機でリアルタイムに行なう実装となった。この画像はGame Creators Conference ’19のSNKゲーム事業本部R&D、泊 久信氏の「ニューラルネットワークを用いたAIの格闘ゲームへの組み込み」の発表資料より(以下同)
ゴーストモードと対戦した際、その推論エンジンは1フレーム毎にゲームコントローのレバー操作、ボタン操作を出力する仕様となっている
同年、2019年に開催されたCEDEC 2019では、スクウェア・エニックス傘下の株式会社Luminous Productionsに所属する上段達弘氏が、3DバトルゲームのプレイヤーAIを、サムスピのゴーストAIに近いアプローチで制作した事例を発表している。
黒服キャラが敵AI、白服キャラがプレイヤーAI。ともにゲームコントローラを操作してキャラクタを動かしているというのがとても興味深い
AI技術の開発になぜGPGPUが有効なのか
前出のAlphaGoでは、公開されている過去の膨大な数の世界トッププレイヤー同士の対戦棋譜を「畳み込みニューラルネットワーク」(CNN)に入力してマシンラーニングさせ、これを言わば「基礎知識」として持ち、この同じ基礎知識を持ったAI同士で対戦させて、勝敗が付いたら勝った方のゲームの進め方を「良棋譜」として学習結果に加えることで「腕前の強化」が行なわれていった。
CNNは画像認識AIによく使われるニューラルネットワークで、入力した画像の特徴を抽出することに向いている。
たとえば、膨大な「猫」の画像をCNN入力して、その学習結果として猫の特徴を取得すれば、撮りたてほやほやの新たな「猫」写真についても、このCNNはこれを猫として判断できるようになる(実際には入力画像が猫である確率を算出する)。
CNNの模式図例。512×512ピクセルの入力画像を256×256ブロックで畳み込み演算を行ない、その結果をさらに128×128ブロックで畳み込み演算を行なう。これを繰り返していくことで、入力画像ジャンルごとの特徴データが得られる。この特徴データの分類集積が実質的な学習ということになる。CNN基礎理論の発案は1970年代に行なわれていたが、演算量が膨大であったことから近年になってやっと実用レベルの技術に進化した
CNN以外のニューラルネットワークには、たとえば回帰性ニューラルネットワーク(RNN : Recurrent Neural Network)と呼ばれるものもある。このRNNは、当初、音声や文章のような1次元データを取り扱うのに有効だとされていた。
たとえば英語で「I」(私)のあとに続く単語として「am」や「was」が来る確率が高いことが見込まれるが、もし「I」の前に「When」があったとすると「When I」となるので「am」ではなく「was」へ続く可能性がグッと高まる。
このように、データ同士の相関性を学習して動作するAIがRNN型AIである。言語の解読や翻訳、作文といった用途には、RNNが適しているとされる(現在はほかの手法が活用される傾向にあり)。
さて、そもそもこのニューラルネットワークとは何なのか。
和訳すれば「神経回路網」となるが、機能だけに着目して簡潔に説明すれば「複数要素からなるデータを入力してやると何らかの結果を返す関数」のようなものだ。
これまでにさまざまな形態のニューラルネットワークが考案されているが、その多くの根幹演算には畳み込み演算(Convolution)が用いられる。
畳み込み演算とは、与えられた2つの数列(データ)の要素同士を全組み合わせで乗算して加算し合わせる演算のことだ。
ギターなどの楽器音に残響を与えるエフェクター装置などは、この畳み込み演算をもっともシンプルに活用した音響機器である。
数列X「3,5,-7」と数列H「12,-4」に対する畳み込み演算。数列Yに結果が収められるまでの演算過程
マシンラーニング型AIの形成過程(≒学習過程)、そしてそのAIを活用過程(≒推論過程)において、この畳み込み演算を、大量に行なうことになる。
畳み込み演算は、実務的には「行列同士の掛け算」なので、この計算はGPUが内包する膨大な「プログラマブルシェーダ実行ユニット」(つまりはシェーダプログラム実行ユニット)でそのまま演算可能なのだ。
すなわち、GPUをGPGPU的に活用すれば、膨大なデータ量の畳み込み演算が高速に行なえるわけで、だからこそ、AI技術開発にGPUが引っ張りだことなったわけである。
ただ、GPUは、もともと3Dグラフィックスを描画するためのプロセッサだ。畳み込み演算専用機として利用するには、シェーダプログラム実行ユニットには、テクスチャユニットを始めとしたグラフィックス描画支援機能がたくさん接続されている。
NVIDIAは、「GPGPU業界の方々がそこまで熱望するならば」……ということで、シェーダプログラム実行ユニットから余計な機能をバッサリとカットした畳み込み演算実行専用ユニットを、2017年発表のVolta世代のGPU「GV100」から搭載した。
Quadro GV100
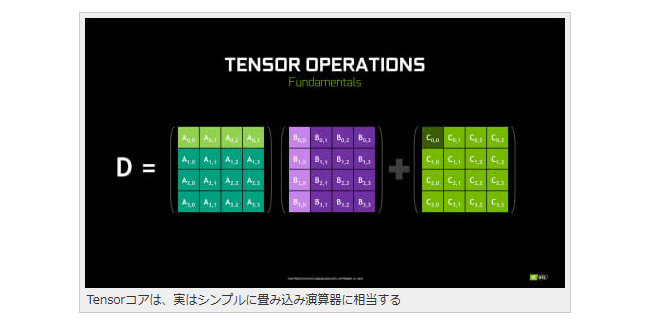
そう、それが言わずと知れた「Tensorコア」である。実は「推論アクセラレータ」の異名を持つTensorコアだが、実際に行なえるのは畳み込み演算(行列の乗算)だけ。
Tensorコアは、実はシンプルに畳み込み演算器に相当する
Tensorコアは、1基あたり、最大4×4要素の行列同士の乗算が1クロックで行なえる。具体的には、下図のような64回の乗算と48回の和算を1クロックで行なうことができる。
Tensorコアの1クロックあたりの演算実務を展開するこんな感じ。人間が筆算するには拷問レベルで面倒臭い
普通のシェーダプログラム実行ユニットでは、1要素(1データ)が最大32bit浮動小数点(FP32)演算に対応しているが、Tensorコアはここは割り切っており、最大16bit浮動小数点(FP16)までと制限している。
AI技術開発用途では、精度的にはFP16で必要十分過ぎるくらいであり、AIが取り扱う学習テーマによっては8bit以下でも十分とされることも多い。よって、最近のNVIDIA GPUのTensorコアでは8bit整数(Int8)、4bit整数(Int4)、1bit(バイナリ)にまで対応する。
そうそう、最近のスマートフォン製品においては「AIチップ搭載!」というような触れ込みが目立つようになってきている。
AIチップ搭載という魅惑のキーワードに痺れて、つい「オレのスマホちゃんは人工知能搭載だぜ、すげえぜ」と自慢したくなることがあるが、実はそのAIチップとは、ここまでで解説してきた「シンプルな行列演算器の塊」にしか過ぎない。
いずれにせよ、高尚なAIも最小演算単位が畳み込み演算(行列の乗算)から成り立ってるということを考えると、我々の知性も根源自体はシンプルな演算の賜なのかもしれない……と思わされてなんとも感慨深い。
広がりを見せるマシンラーニング型AIの応用先
さて、2012年以降、センセーショナルな発展を見せたマシンラーニング型AIのすべてにおいて、NVIDIAのGPUがGPGPU的に利用されていた。
この事実は、前回紹介した「2010年の世界最速スパコンTOP10のうちの3台がNVIDIAのGPUベースだった」という事象に並ぶほど、NVIDIAにとって「GPGPUに対する強風の追い風」となったことは言うまでもない。
マシンラーニング型AIは、ごくごく簡単にたとえれば「膨大なデータ同士の相関性を計算し、これを学習データにする」「AI利用時には、入力データとその学習データの相関を求めて、その度合いに応じた推論を導く」……というような処理系となっている。
この仕組みは、画像の認識、インベーダーゲームをプレイするAI、囲碁をプレイするAIなどなど、あらゆる分野への応用が利く。
そう、2012年以降、GPGPUベースとなったマシンラーニング型AIは「どんな分野で有効か」の探索フェーズに入り、まさに各産業分野において高効率かつ高精度なAI開発が急ピッチで進められている状況となっていった。
たとえば音声データを取り扱った音声認識や、膨大な言語の文書データを取り扱った翻訳への応用はすでに実用レベルに達している。
意外なところではディズニーやピクサーなどのCGアニメーション映画制作会社が、キャラクターに魅力的な動きを付けるのに、モーションキャプチャではなく、マシンラーニング型AIを応用する研究を始めている。
日本では、塩野義製薬が新薬試薬の臨床試験解析にマシンラーニング型AIの導入を開始したことを発表しているし、レントゲン写真やMRI像から疾患の有無を判断するエキスパートシステムに、マシンラーニング型AIを導入しようとする研究も進められている。
そして、リアルタイムに周囲の情景(映像)を認識して最良の行動を判断するだけでなく、過去の学習データから、今の情景から未来に起こりうる危険なことを確率的に予測できるマシンラーニング型AIもありふれた存在となりつつある。そう、自動車の自動運転向けAIなどはその最たる事例だと言えよう。
2017年5月にNVIDIAが開催したGTC 2017の基調講演にて、トヨタ自動車は自社の自動運転技術開発に、NVIDIAのGPUを搭載したSoCを採用することを発表した
マシンラーニング型AIは、学習データ次第で今見えている状況から、この先で起こりうる未来が確率論的に予測できるところが、従来のセンサーからのリアルタイム情報に基づいてアルゴリズムでリアクション的に意志決定するAIとの大きな違い。ドアが閉まっている車があったとき、過去に「突然ドアが開いて、そのドアに衝突したことがある。これは良くないこと」という学習があれば、同じ状況時に警戒ができる。リアルタイムにリアクションするだけでなく、起こりうることを予測して警戒できるAIは、自動運転技術の意志決定には非常に都合が良い
GPGPUの世界でも激化が進むGPUメーカー同士の戦い
近年では「NVIDIAは妙にGPGPUに注力している」などと言われることがあるが、むしろ「GPGPUを積極活用している業界の方が金に糸目を付けない勢いで高性能GPUを欲している」状況になっており、今やグラフィックス業界に優るとも劣らぬほどのGPU市場の上客になりつつある。
そんなわけで、企業体であるNVIDIAの行動方針に「GPGPUユーザー重視」の傾向が見られるようになったとしても不思議なことではない。
冒頭で紹介したGH100のような「GPGPU専用のGPU製品をグラフィックス描画向けよりも先行してリリースする」という状況は、こうした背景があるからなのだ。
さて、なぜここまでGPGPUの世界がNVIDIA一強になってしまったのだろうか。これにはいくつかの理由が考えられる。
Radeonブランドを有し、プログラマブルシェーダ技術の進化に大きく貢献したはずのATIは、大手CPUメーカーのAMDに2006年に買収されている。
AMDはCPUメーカーでもあるため、HPC(High Performance Computing : 学術界や産業界が欲する科学技術計算用の超高性能な計算処理系。端的に言えばスパコン)業界にCPUを訴求したいという思惑を捨てきれず、GPGPUの方向へ大きく傾倒した戦略をとることができなかった……と筆者は考えている。
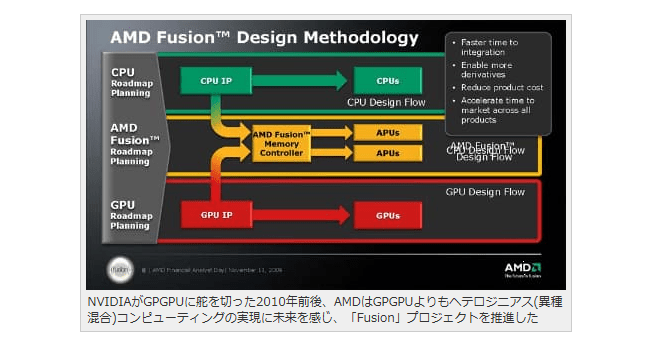
さらに、AMDは「そうしたHPC分野には、CPUとGPUを統合させた新構造のプロセッサが適しているはず」という姿を見出していた。
この着想を元にした新プロセッサは当初「Fusion」というプロジェクトネームで発表されたのち、実際の製品としてはAPU(Accelerated Processing Units)シリーズで展開された。
またAMDは、次世代APUシリーズに向けて、CPU管理下のメモリ空間とGPU管理下のメモリ空間を論理的に共有一体化させたGPGPUプラットフォームとして、HSA(Heterogeneous System Architecture)を提唱。
NVIDIAがGPGPUに舵を切った2010年前後、AMDはGPGPUよりもヘテロジニアス(異種混合)コンピューティングの実現に未来を感じ、「Fusion」プロジェクトを推進した
この流れは非常に有効そうに見えたのだが、初期のAPUはどちらかと言えばエントリークラスからミドルクラスの性能を持った、一般ユーザー向けの普及価格帯PC向けソリューションとして訴求されていため、HPC業界に振り向いてもらえなかった。。
歯に衣着せずに言うと、最初期のAPUはCPU性能もGPU性能もHPCが求めるパフォーマンスに達していなかった……ということである。
このタイミングで、若干時代の流れを読み間違えたAMD(ATI)は、GPGPU向け戦略(≒近代HPC戦略)においては相応の遅れをとってしまった感がある。
ATI買収をきっかけにしてAPU開発に傾倒し、GPGPU環境整備に遅れをとったAMDだったが、このAPUプロジェクトそのものは一定の成功を収めているということだけは付け加えておこう。
そう、PS4、PS5、Xbox One、Xbox Series Xなどの近年の家庭用ゲーム機のメインプロセッサは、すべてAMDのAPUであり、言わばFusionプロジェクトの間接的な産物なのであった。
近年の家庭用ゲーム機の多くは、AMDのAPUを使用している
さて、AMDは、この「遅れ」を取り戻すべく、2015年前後あたりからGPGPU環境整備ヘの取り組みを積極的に行なうようになり、2016年にAMD独自のプラットフォーム「ROCm」(Radeon Open Compute Platform)の推進を開始した。
NVIDIAのCUDA戦略に対抗すべく、GPGPU(≒GPU COMPUTING)環境整備に力を入れ始めたAMDは、ROCmを推進中
以降、堅実的な開発と環境整備を続けたことで(まだまだNVIDIAのCUDAプラットフォームほどではないが)、徐々にHPCの世界で存在感を強めつつはある。
近年では、AMDのRyzen CPUと、同社のGPGPU専用GPU製品であるRadeon Instinctの組み合わせで構成されたスパコンが、米国のオークリッジ国立研究所(ORNL)と米国エネルギー省(DoE)に採用されたことが大きく報じられた。
米エネルギー省、世界最速の新スパコンにAMD製CPU/GPUを採用
GPUの覇権争いは、今後GPGPUの世界でも続くと見て間違いない。
「ためになる3Dグラフィックスの歴史」シリーズのまとめ
もともとこのシリーズは、編集部から「なぜNVIDIAとAMD、Intelといった異なる半導体メーカーが作るGPUで、同じようなゲームグラフィックスが出せるのでしょうか?」というお題が起点となっていた。
全6回の間、だいぶ脱線することも多かったが、GPUというプロセッサの活用のされ方がここ20年くらいで、まるっきり変貌してしまったので、それも致し方がないといったところ。
今回のシリーズは、本稿でひとまずの終わりとなる。最後に、全6回のまとめを年表的な箇条書きで示し、元々のお題に対する回答のようなものを示そうかと思う。
【1】1990年代初期。もっとも身近なリアルタイム3Dグラフィックスはゲームセンターのゲーム機に存在した。
1993年に登場した「バーチャファイター」
【2】1990年代中期。PCでリアルタイム3Dグラフィックスを実現する気運が高まるが、それを担当する3Dグラフィックスハードウェアとその制御APIが乱立した。DirectX(Direct3D、以下同)は登場当時は求心力が低かった。
初代Voodooを搭載した3Dグラフィックスハードウェア。当時はDirectXの影は薄く、これを動かすには3dfx社独自のAPI「Glide」を用いる必要があった
【3】1990年代後期。DirectX7登場とともに、それまでCPUが担当していたジオメトリ演算系までをも、3Dグラフィックスハードウェアが担当可能になる。「GPU」というキーワードの誕生を機に、いくつかあった3DグラフィックスAPIにおいても淘汰が開始され、DirectXの立場が向上する。
1997年に登場した「バーチャロン」。IntelのSIMD拡張命令であるMMX技術が使われた
【4】2000年代初期。GPUの機能拡張(≒3Dグラフィックスにおける新表現の実装)をソフトウェアの形で行なっていく枠組み「プログラマブルシェーダ技術」が誕生する。これにいち早く対応したDirectX 8がこの技術の進化を牽引していく流れに。
DirectX 8世代のGPUから採用された「プログラマブルシェーダアーキテクチャ」。写真はその対応GPU「GeForce3」
【5】2000年代中期。プログラマブルシェーダ技術の発展とともにGPUの進化が加速。一方で、たくさん存在した3Dグラフィックスハードウェアメーカーの淘汰が進む。
Permedia2を搭載した「Fire GL 1000 Pro」。3Dlabs社は2002年にシンガポールのCreative Technology社に買収され、2006年にはGPU事業から撤退
【6】2000年代後期。NVIDIA GeForce対ATI(AMD) Radeonの闘いが激化。この闘いが追い風となってGPUはより高性能化。プログラマブルシェーダ技術のプログラマビリティが一層強化。DirectXもDirectX 11まで進化する。
「GeForce FX 5900 Ultra」と「RADEON X1800 XT」
【7】2010年代初期。高まったGPUのプログラマビリティがGPGPU技術を育み、実用化へと進む。任天堂、ソニー、Microsoftの三大家庭用ゲーム機はすべてプログラマブルシェーダ技術ベースへ。対応最後発は2012年発売の任天堂のWii U。ちなみに、もっとも早く対応したのは2001年発売の初代Xbox。2番手は2006年発売のPS3。
2001年に発売された初代「Xbox」は、世界初のプログラマブルシェーダ技術採用の家庭用ゲーム機
【8】2010年代中期。GPGPUがマシンラーニング型AIの開発に大きく貢献。GPU制御APIの抽象レイヤーを薄型化する流れが発祥した結果、DirectX 12とVulkanが台頭する。ただし、旧来APIのDirectX 11とOpenGLも併存することに。
Vulkanの前身となった「Mantle」。AMDが2013年に発表
【9】2010年代後期。GPGPU技術の加速度的な進化で、自動車の自動運転技術開発を始め、GPGPUとAIが切っても切れない関係性へ。GPGPU市場が大規模化する。また、このタイミングでGPUにリアルタイムレイトレーシング機能が搭載される(本シリーズでは未フォロー)。
世界初のGPGPU対応GPU「GeForce 8800 GTX」。発表は2006年
こんな感じになるだろうか。
「なぜ、NVIDIAとAMD、Intelといった異なる半導体メーカーが作るGPUで、同じようなゲームグラフィックスが出せるのでしょうか?」という問いに対しては、
「プログラマブルシェーダ技術」の規格化によって、3Dグラフィックス表現がソフトウェアの形で行なえるようになり、広範囲な互換性が担保されるようになったから
……ということになろうか。
プログラミング言語的な方言、APIのパラメータの与え方の違い、座標系の違い……といった細かな差異はあれど、同じプログラミングモデルで制作されているため、ほとんどの近代3Dゲームグラフィックスは異機種間に対する相互移植が可能となっている。
また、昨今の発展著しい先進のゲームエンジン技術の台頭により、そうした相互移植性まで面倒を見てくれるようにもなってきている。
ただ、今でもGPUごとに、プログラマブルシェーダ技術の実行時の結果に、微細な結果が出ることはある。
なぜそうしたことが起こりうるのかについては、本シリーズの2回目や3回目で紹介した「緑のたぬきと赤いきつね」の闘いのあたりで触れたエピソードのようなことが、未だに細かい部分で残っているからである。
なお、今回のシリーズでは、レイトレーシング技術に付いては一切触れなかったが、これはまだ進化の途中であり、この後の進化の方向性が定まっていないためだ。また時間が経ったときに、このあたりの話題はお届けすることにしたい。
それではまた。 』
中国、生成AIに審査義務 「国家分裂の扇動」など禁止
https://www.nikkei.com/article/DGXZQOGM116QU0R10C23A4000000/
※ どこまで行っても、「人間らしく、自分の頭で、ものを考える力」が、「鍵(かぎ)」となる…。
『2023年4月11日 17:19
【北京=多部田俊輔】中国政府は11日、精緻な文章や画像などを作り出す生成AI(人工知能)の規制案を発表した。社会主義体制の転覆や国家の分裂などを扇動する内容を禁止し、当局による事前審査を義務付ける。生成AIを含めてネット世論の統制を強化する。
中国でネットを統制する国家インターネット情報弁公室が同日、全21条で構成する「生成型AIサービス管理弁法案」を公表した。5月10日まで専門家らの意見を聴取…
この記事は会員限定です。登録すると続きをお読みいただけます。』
『5月10日まで専門家らの意見を聴取し、年末までの実施を見込む。
規制案は第1条でインターネット安全法(サイバーセキュリティー法)、データ安全法(データセキュリティー法)、個人情報保護法に基づき、生成AIの健全な成長を目的とすると明記した。第2条でアルゴリズム(計算手法)やモデルなどに基づいて生成された文章、画像、音声、動画などを規制対象とした。
第4条で生成AIのサービスは法律、法規を順守し、習近平(シー・ジンピン)指導部が示す社会主義核心価値観を体現しなければならないと規定した。政権や社会主義体制の転覆、国家分裂の扇動、国家統一を損なう内容、テロリズムの宣伝、暴力、わいせつ、虚偽情報などを含む内容を禁止した。
中国共産党と習指導部による統治や、台湾統一に向けた動きに対する批判を排除する狙いがあるとみられる。
消費者へのサービス提供前にネット当局のセキュリティー審査を受けることも義務付けた。当局はネット検索サービスなどに事前審査を求めており、生成AIも対象に加える。
中国は「ChatGPT(チャットGPT)」など米国の生成AIの国内利用を厳しく規制している。当局の指導の下で百度(バイドゥ)やアリババ集団などが独自の生成AIの開発に取り組む。
生成AIをめぐってはデータの不正収集や差別、偽情報の助長、サイバー攻撃への悪用といった懸念も出ている。イタリアが利用を一時禁止するなど、個人データ保護法制が厳しい欧州を中心に規制強化が進む可能性がある。米国でも非営利団体などがAI開発の危険性を指摘して規制を訴えている。
【関連記事】
・高度なAIの開発中断、マスク氏ら要求 慎重論の背景は?
・ChatGPTは「人類の危機」か AI開発停止運動で波紋
・[FT]ChatGPTの背中を追う中国テック大手
ニュースレター登録
多様な観点からニュースを考える
※掲載される投稿は投稿者個人の見解であり、日本経済新聞社の見解ではありません。
楠正憲のアバター
楠正憲
デジタル庁統括官 デジタル社会共通機能担当
コメントメニュー
ひとこと解説 LLMの開発において、たくさんの利用者に使ってもらって、そのフィードバックで強化学習を行うプロセスは重要だ。表現の自由が認められている西側諸国にとって、中国がLLMを使ったサービス提供を厳しく規制することは、開発競争を優位に進める機会となり得る。一方で子どもによる利用でトラブルが生じたり、LLMを悪用した事件が起きた場合、もっと厳しく規制すべきとの議論が起こるのも時間の問題だ。対話型AIの悪用や国家による統制といった負の側面からも目を背けずに、社会としての向かい合い方を考えて、様々な立場からオープンな対話を積み重ね、国際的なルールの形成に貢献していく必要があるのではないか。
2023年4月11日 20:26いいね
16
佐藤一郎のアバター
佐藤一郎
国立情報学研究所 教授
コメントメニュー
ひとこと解説 一般論だが、対話型AIは、国家による言論操作にとっても強力なツールとなりうる。
というのは①学習・生成アルゴリズムの調整、学習対象のデータを限定したり、特定の質問を制限することで、容易に結果を偏らせることもできる。②利用者が対話型AIの結果に満足すればその結果の元情報を見なくなるからだ。つまり、国家の都合のいい情報空間に人々を閉じ込めることができる。さらにそうした偏った対話型AIを他国に輸出することは、その他国の世論を操作できることになる。
対話型AIを画期的な技術だとして、その効用を議論するのも結構だが、そろそろ対話型AIの負の影響を議論すべき時期に来ているのではないか。
2023年4月11日 19:12 (2023年4月11日 19:29更新)
いいね
40
浅川直輝のアバター
浅川直輝
日経BP 「日経コンピュータ」編集長
コメントメニュー
ひとこと解説 中国が求める対話AIを開発するには、対話AIが出力するテキストが「体制の転覆」「国家分裂の扇動」などに相当する否かを判定するAIモデルを新たにつくり、強化学習などを通じて対話AIの出力に一定の制約を設ける必要がありそうです。
ただChatGPTが自ら証明したように、ユーザーが質問文(プロンプト)を工夫することでこうした制約を外す「脱獄」も原理的には可能です。脱獄を試みるユーザーが増え、続いて中国が脱獄用のプロンプトを規制し・・・といったいたちごっこになる可能性があります。
2023年4月11日 21:08 』
AIが人間の司令官の「決心を補助する」とは、具体的にはいったいどんな感じなのか?
『Benjamin Jensen and Dan Tadross 記者による2023-4-12記事「How Large-Language Models Can Revolutionize Military Planning」。
AIが人間の司令官の「決心を補助する」とは、具体的にはいったいどんな感じなのか?
一例を想像しよう。
司令官は、当面している敵地上部隊を、カンネーのような両翼二重包囲を仕掛けることで、殲滅してやりたいと思っている。
データは、偵察衛星や偵察航空機や電波傍受から得られる。それをデジタルマップ上に可視化すると、これまでの敵軍の動きが時系列的に細密に動画化される。
だがそれは司令官と幕僚に対するいわば余計なサービスにすぎず、AIは黙って淡々と本業の仕事にかかっている。すなわち、この土地でこのパターンの動きを見せている敵軍を両翼二重包囲するには、我が軍は時々刻々、どのように動かなければならないかを、全範囲にわたって詳細に、計算してくれているのだ。
我が軍のデータのうちで肝要なのは、「燃料補給」である。燃料補給の目処が立たないのに理想的なマヌーバを提案されても、前線のリアル部隊にはどうしようもない。AIは、今、間に合う燃料兵站の条件で、現実的に可能な包囲機動の作戦計画を立ててくれる。それがMapに示される。
もし、こちらの準備できる燃料があまりに少なければ、こちらの一部の部隊を後退(偽退却)させることで敵軍を我が陣中に深く誘い入れ、それによって「カンネー」型の決戦を再現できる可能性があるから、AIはそれを映示して「提案」することになるだろう。
偽退却機動は、人間の司令官にとっては、リスキーな決心になる。もしAIの予想が外れ、あるいは一部現地将兵の戦意が崩壊するなどすれば、予期に反して我が軍は大敗を喫するかもしれぬ。その場合、人間の司令官は戦史に末永く汚名をさらし、幕僚のキャリアはおしまいとなり、なにより国家には大打撃だ。しかしAIには恥の観念は無いし、切腹しろと迫ってくる世論の圧力もない。気楽なものである。
人間の司令部は、それでも敢てカンネー型の勝利を追求するのかどうかまで含めた、高度判断を下さなければいけない。
司令官は、おのれ個人の名声と国家の興廃をもろともに賭けた決断を、数分のうちにしなくてはならん。
……ざっと、こんな感じだろうか。
AIの得意技は、人間の司令部がある判断で迷っているところに、最新の偵察データがとびこんできたときに、瞬時に、それを加味した「再計算」を、トータルでやりなおしてくれることである。人間の幕僚には、とてもそんなスピード仕事はできないので、古くなった当初案にこだわることになりがちだ。
いまやAIは、医師国家試験にも合格できるし、弁護士資格試験もパスしてしまう(米国の話)。
わずか数ヵ月のうちに、とてつもなく進化しているのである。
ラダイティズム(そんなもの無い方がいいと叫ぶ運動)の入る余地はない。これは使いこなすしかないのだ。』
NSAの長官は警告した。チャットGPTを使うと、…。
https://st2019.site/?p=21048
『Jon Harper 記者による2023-4-11記事「NSA: ChatGPT and similar tech will make hackers more effective」。
NSAの長官は警告した。チャットGPTを使うと、英語の文章がいかにも自然な調子になるので、メールで人を騙す仕事をしている悪人どもの仕事が今まで以上にはかどってしまうことになるだろう。善人にとっては、《不自然な文章》から詐欺メールであることを見抜くことが難しくなる。
NSA長官としては、大統領に「データ」を示して何かを説明するときに、たいへんなジレンマに直面する。というのは、チャットGPTは、存在しないデータをいくらでも捏造できてしまうからだ。情報機関が、それらの偽データを拾い集めて、本物だと信じて分析していた――というオチが、これからは、待っているわけである。
これだけは言える。将来も、分析して報告するのは人間の役目であり続けるだろう。AIは、「分析のツール」として有用である。しかし「分析」そのものの代行は、できない。
ペンタゴンではAIを「決心」の補助に使えないか、研究中である。
来る6月には、ヴァジニア州マクリーンで、AIについてのカンファレンスをDoDが開催する。』
AIって何のために開発してるの?
http://blog.livedoor.jp/bluejay01-review/archives/60351413.html#more
『 2023年04月04日14:01
1: 風吹けば名無し 2023/04/03(月) 16:32:56.98 ID:OHAglE750
人から仕事や生き甲斐を奪うため?
2: 風吹けば名無し 2023/04/03(月) 16:33:32.50 ID:yX9snrrZ0
無能より役に立つからや
6: 風吹けば名無し 2023/04/03(月) 16:35:30.69 ID:9lWCH8VWM
もう終わりの始まりやと思う🥺
12: 風吹けば名無し 2023/04/03(月) 16:37:45.29 ID:49K+su9x0
労働を全てAIのものにすれば人類は働く必要が無くなる
13: 東風吹かば名指し 2023/04/03(月) 16:37:51.00 ID:ZzoHRNMk0
人間に限らず動物が仕事も狩猟もなんもしないで楽しく生きてくためや
18: 風吹けば名無し 2023/04/03(月) 16:39:36.04 ID:OHAglE750
13
自己実現のための仕事や創造の愉しさを奪われた生言うほど楽しいかな?
19: 風吹けば名無し 2023/04/03(月) 16:40:43.88 ID:49K+su9x0
18
そうなったら娯楽としての仕事を提供してもらえばよい
20: 風吹けば名無し 2023/04/03(月) 16:40:51.37 ID:EUUlbQx60
18
一人一人がやりたい事を実現できる仮想世界に入り込めるようになると思うで
そんでひとまず現実世界は幕を閉じるんや
21: 東風吹かば名指し 2023/04/03(月) 16:41:15.46 ID:ZzoHRNMk0
18
ニキはなんjしてるだけで楽しくないんか?
プログラミングとか音楽とか筋トレとか、別に仕事になんなくたっていくらでも続けられるやろし
やっぱりワイはAIの悪いとこが分からんわ
31: 風吹けば名無し 2023/04/03(月) 16:44:14.45 ID:OHAglE750
21
AIとベーシックインカムの世界は完全にニヒリズムの世界やぞ?
みんなはニーチェみたいに超人として生きるんか?それとも新しい宗教を見つけるんか?
34: 風吹けば名無し 2023/04/03(月) 16:45:59.74 ID:49K+su9x0
31
皆が遊んで暮らせば良いだけや
37: 東風吹かば名指し 2023/04/03(月) 16:48:31.35 ID:ZzoHRNMk0
31
一生遊び回るのに虚無も何もないやろ
楽しければそれでええんやで
15: 風吹けば名無し 2023/04/03(月) 16:38:58.65 ID:ORhBr+mo0
衣食住のどれか
例えば一部の食品だけでも生産を全てAIで完結して無料配布出来る下地が出来ないものか
それで生きるのが大分楽になるだろうに
16: 風吹けば名無し 2023/04/03(月) 16:39:13.10 ID:EUUlbQx60
やってる事は数十年間蓄積されてきた情報を「チャット」という形で還元してるだけなんやけどな
情報が飽和してる状態やからチャットも完全体になりつつある
AI自体が学習するかもしれないなんて話も出てきとるし
29: 風吹けば名無し 2023/04/03(月) 16:44:04.53 ID:KDARMOWE0
世界を支配するためやで
30: 風吹けば名無し 2023/04/03(月) 16:44:12.88 ID:zJmglQWl0
人間を更に追い込むため
32: 風吹けば名無し 2023/04/03(月) 16:45:09.03 ID:KBUCGESD0
人間がAIと融合するため
28: 風吹けば名無し 2023/04/03(月) 16:44:02.81 ID:7HZ9ISBn0
仕事でしか評されへんから仕事なくなったら生きる意味失うとか
昭和の熱血サラリーマンと呼ばれたジジイ達みたいやな
35: 風吹けば名無し 2023/04/03(月) 16:46:05.66 ID:OHAglE750
いやワイは学生やぞ
趣味にしても鑑賞者がおらんようになるぞ
36: 風吹けば名無し 2023/04/03(月) 16:48:03.51 ID:49K+su9x0
35
なんや鑑賞者って
40: 風吹けば名無し 2023/04/03(月) 16:50:47.77 ID:OHAglE750
36
絵を描いたり音楽を作ったとしてもAIの圧倒的な物量と質に押されてそもそも人の目に入らないって話や
農工にしてもAIで全てが片付く時代に誰がその生産を評価するやってことや
45: 風吹けば名無し 2023/04/03(月) 16:54:02.92 ID:7HZ9ISBn0
40
ああ、芸術作品の評価が単一基準やと思ってるんか
すでにAIに超えられてそうな価値観やな
39: 東風吹かば名指し 2023/04/03(月) 16:50:08.01 ID:ZzoHRNMk0
35
ワイは話し相手がAIだけになっても別にええが
人間じゃなきゃイヤイヤなのって人は当然おるやろうし
そういう仲間集めて見せてあげればええんちゃう
41: 風吹けば名無し 2023/04/03(月) 16:52:08.00 ID:OHAglE750
39
そうなんか
じゃあGPT5が出た段階で誰とも会話せんでよくなるな
44: 風吹けば名無し 2023/04/03(月) 16:52:44.64 ID:49K+su9x0
41
それは暴論やろ
まだクオリティが充分とは言えないし
48: 風吹けば名無し 2023/04/03(月) 16:55:27.50 ID:7HZ9ISBn0
そもそもどんなAIを想像してるんやろこれ
52: 風吹けば名無し 2023/04/03(月) 16:56:11.37 ID:49K+su9x0
48
これは割と大きい問題やな
本来の意味としてのAI、つまりAGIのことなのか
それとも弱いAIのことなのか
50: 風吹けば名無し 2023/04/03(月) 16:55:41.75 ID:+krN+H/s0
業務圧縮の為
55: 風吹けば名無し 2023/04/03(月) 16:57:58.93 ID:PvnO6xjL0
テクノロジーが加速度的に進化するなら万々歳やろ
そのための多少の犠牲は必要やしそうして人類は進歩してきたわけや
58: 風吹けば名無し 2023/04/03(月) 17:00:06.03 ID:OHAglE750
55
既に豊かなんやしそういう価値観から抜け出してもええんやないか
64: 風吹けば名無し 2023/04/03(月) 17:04:27.06 ID:AlNVsQJp0
58
脱成長やな反資本主義にもその考えもある
でも結局は競争心が人間の心にあるから資本主義による競争社会は脱せないと思うわ
多くの人間が職にあぶれているのに資本主義のままとか、一体どんな世界になるか見ものやな
超ディストピアやろね
78: 風吹けば名無し 2023/04/03(月) 17:11:39.55 ID:c6fbGkc6a
64
というか今AI開発したり支持してる人は多少なり競争心があってやってるやろうに自分らが用無しになったときのこと考えてないんかね
105: 風吹けば名無し 2023/04/03(月) 17:29:18.06 ID:AlNVsQJp0
78
考えて無いやろ
質問しても「僕は社会や政治の専門家ではないので…」みたいなテンプレートな回答しかしないで?
分からないのは別にいいんやけど、個人の肖像権や著作権、プライバシーをぶっ壊すような発言してるのは流石に頭おか
個人の権利無くしてどうやって生きていくつもりなんやろね?
57: 風吹けば名無し 2023/04/03(月) 16:59:55.34 ID:+7jqUAIMM
AIに3日で作らせたゲームが想像以上に良く出来ててビビったわ
そのうち開発にAIを使うのが当たり前になるやろな
63: 風吹けば名無し 2023/04/03(月) 17:04:17.27 ID:yxNNIR5v0
どうせいずれ世界的に「あれっテクノロジーって格差を拡大してるだけじゃん」って気づく
一部が気づいても大衆が気づかないと意味ない
いずれ大衆にも明らかなレベルで明白になる
66: 風吹けば名無し 2023/04/03(月) 17:05:48.15 ID:MHN4HARZ0
ネットが出てきた時も似たようなこと言われてたな
ネットにしろAIにしろただのツールでしかない
電話やテレビと同じ
67: 風吹けば名無し 2023/04/03(月) 17:07:08.90 ID:49K+su9x0
66
いくら何でも先見の明が無さすぎる
68: 風吹けば名無し 2023/04/03(月) 17:08:12.20 ID:c6fbGkc6a
66
電話やテレビを結局のところ人を繋ぐコミュニケーションの道具やっただけやし道具自身が生産することは無かったやん
72: 風吹けば名無し 2023/04/03(月) 17:10:07.95 ID:MHN4HARZ0
68
ただの道具って意味や
パソコンとかって言ったほうが良かったか?
82: 風吹けば名無し 2023/04/03(月) 17:14:23.37 ID:c6fbGkc6a
72
ただの道具って考え方が理性主義の古い考え方やわ
「道具は人間が作り、人間は道具によって形作られる」マクルーハンの言葉や
83: 風吹けば名無し 2023/04/03(月) 17:14:33.62 ID:jMohptQid
72
人間も生物が進化するための踏み台って気付かんのか?
自分達が生物の最終進化系だと勘違いしてないか?
チャットGPTに肉体を持たせたら既に人間に迫る勢いなんやで
人類は滅亡に向かうと分かっていてもAIの開発を止められへん
これは本能なんや
90: 風吹けば名無し 2023/04/03(月) 17:17:22.71 ID:OHAglE750
83
AIにユートピア思想抱いてる人間より君みたいな破滅主義者の方がまだ理解できるよ
91: 風吹けば名無し 2023/04/03(月) 17:17:47.27 ID:MHN4HARZ0
83
人類は滅亡なんてしないよ
人口は半分くらいになるかもしれんけど間違いなく残る
74: 風吹けば名無し 2023/04/03(月) 17:10:38.76 ID:AlNVsQJp0
66
歴史は韻を踏むけど同じではないんやで
馬車と車、電卓とコンピューターがよく比較に出されるけど
こいつらがやってることは同じ、人間が脳みそを使って道具を利用してるだけ、だからホワイトカラーが生まれた
今のマシンラーニングだと無理やけど、AGIが完成したら完全自走になるから、そのホワイトカラーも消える
じゃあ何が新しく職業として生まれるんや?
77: 風吹けば名無し 2023/04/03(月) 17:11:34.17 ID:AlNVsQJp0
74
あっ電卓とコンピューターやなくて、そろばんと電卓やったわ
86: 風吹けば名無し 2023/04/03(月) 17:15:33.64 ID:MHN4HARZ0
74
さあな?
働く事自体がナンセンスな世の中になるのかもよ
企業だけが資本を総取りしてそのおこぼれで一般人が生活するとかおもろそうだけどw
88: 風吹けば名無し 2023/04/03(月) 17:16:32.78 ID:49K+su9x0
86
流石に草
73: 風吹けば名無し 2023/04/03(月) 17:10:08.16 ID:jm9h4d/a0
シンギュラリティが発生したら制御できなさそうな感はあるよな
80: 風吹けば名無し 2023/04/03(月) 17:12:23.57 ID:AVOGWPFKd
資本家の夢である人件費ゼロの従業員の実現のためやぞ
81: 風吹けば名無し 2023/04/03(月) 17:13:21.70 ID:cx6Bg0800
人は悪い人がいても一部で済むんだけど
AIが悪さをしたらすべて統括されてて全部が敵になるってのが怖い
人間って生きるのに色々と必要なものがあるけど
食も水もAIが管理しだしたら人が生きるのは困難になるだろうな
85: 風吹けば名無し 2023/04/03(月) 17:15:18.41 ID:AVOGWPFKd
AIという最高の話し相手が常についてくれるから
他人とコミュニケーションする必要すらなくなっていくで
110: 風吹けば名無し 2023/04/03(月) 17:30:29.67 ID:zBT4lLP7M
仕事しなくても生活できるんならよくね
ドラえもんみたいなの1台買ってそいつに仕事させて自分は遊んでればいいんだろ?
111: 風吹けば名無し 2023/04/03(月) 17:30:53.99 ID:j38D7UiE0
担い手不足を補うのには有効
112: 風吹けば名無し 2023/04/03(月) 17:31:23.06 ID:lwmX6f+dd
先行利益狙いでバンバン開発しとるから 』
45万件弱に影響したフレッツ光の障害。特定パケットに起因、攻撃の可能性はほぼなし
https://pc.watch.impress.co.jp/docs/news/1490737.html



『 大河原 克行 2023年4月3日 20:55
NTT東日本およびNTT西日本は、4月3日午前に発生したフレッツ光サービスやひかり電話などの同社通信サービスが利用できない、あるいは利用しにくくなった事象について説明した。
同日午後6時からオンラインで行なった会見では、NTT東日本 ネットワーク事業推進本部サービス運営部の鈴木康一部長と、NTT西日本 執行役員 設備本部サービスエンジニアリング部の桂一詞部長が出席し、「本日発生した障害により、多くの皆様にご迷惑をおかけしたことをお詫び申し上げる。申し訳ありませんでした」と陳謝。両社ともに「多くの利用者に影響が出たこと、1時間以上にわたる障害であること、緊急通報も利用できない状況であったことから、重大事故にあたると認識している」と述べた。
障害は同一メーカー、同一機種の一部で発生。特定のパケット受信に起因
加入者収容装置の機能概要・発生事象
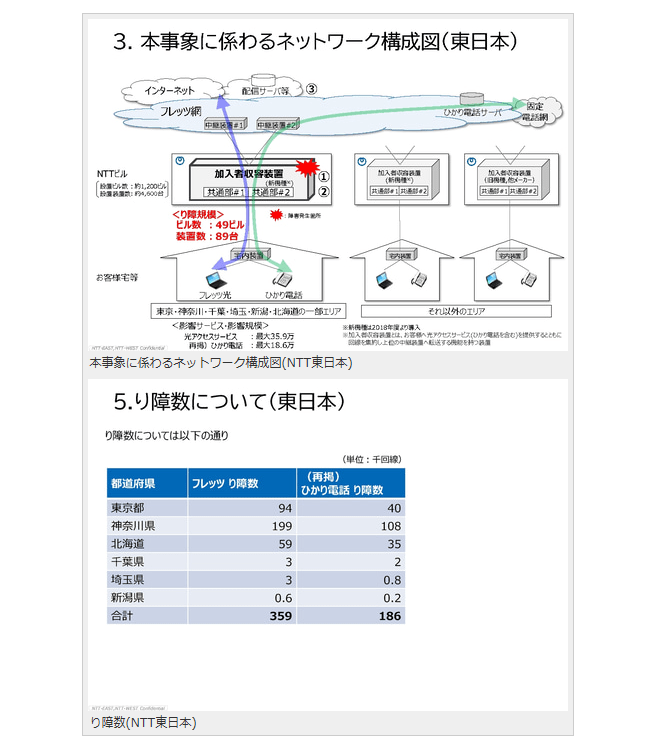
NTT東日本では、49ビル/89台の加入者収容装置で、NTT西日本では、21ビル/27台の加入者収容装置において、特定の配信サーバーからのパケット受信に起因して、障害が発生したという。
加入者収容装置は、利用者に光アクセスサービスを提供するとともに、回線を集約し、上位の中継装置に転送する機能を持つ。インターネットや電話のパケットが流れる装置であり、今回は加入者収容装置のパケット転送部に障害が発生。パケット転送部は二重化されていたが、両方に障害が発生したことで、フレッツ光サービスとひかり電話が使用できなくなった。
NTT東日本およびNTT西日本が導入している特定の海外メーカーの加入者収容装置だけで同時に障害が発生していること、これが、2018年から順次導入している機種であり、その機種の一部の装置で障害が発生していること、特定の配信サーバーからのパケット受信が起因で障害が発生していることを示しながら、「現在、詳細な原因の究明と抜本対策を急いでいる」と説明。
「故障した装置は2018年以降に導入したものであり、こなれたものである。だが、同一メーカーの同じバージョンの装置で故障が同時発生しており、同様の原因があると考えている。同一機種で、特定のパケットが重なったことに起因し、想定外の動作をしたことで障害が発生したと見ている。なお、NTT東日本およびNTT西日本の作業において、事象を誘発するものは確認されていない」などと述べた。
また、「特定のサーバーからのロングパケットによるものであり、これまでにも類似したパケットは経験したことがある。だが、こうした挙動が起きたのは初めてである。どういう振る舞いによって不具合が発生したのかは解析中である。パケットがどこから来たのかについても確認を急いでいる」とする一方で、「現時点でのログ解析によると、攻撃の可能性は限りなく低い」としている。
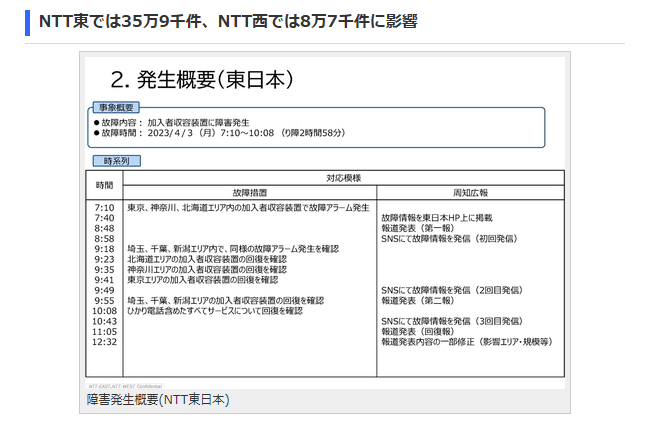
NTT東では35万9千件、NTT西では8万7千件に影響
障害発生概要(NTT東日本)
NTT東日本では、午前7時10分~午前10時8分までの2時間58分に渡り、障害が発生。光アクセスサービスで最大35万9,000件、そのうち、ひかり電話で最大18万6,000件に影響した。
午前7時10分に、東京、神奈川、北海道エリア内の加入者収容装置で故障アラームが発生。9時18分には埼玉、千葉、新潟エリアで同様の故障アラームが発生。その後、加入者収容装置に4分間隔で再起動処理を実施した。9時23分に北海道エリアで、9時35分に神奈川エリアで、9時41分に東京エリアで、9時55分に埼玉、千葉、新潟エリアで回復し、10時8分にはすべてのサービスでの回復を確認した。「1回の再起動処理で回復した装置があれば、最後まで再起動処理を繰り返していた装置もあった」という。
なお、NTT東日本では約1,200ビル、約4,600台の加入者収容装置が稼働しており、障害が発生した加入者収容装置以外は通信サービスが利用できた。
本事象に係わるネットワーク構成図(NTT東日本)
り障数(NTT東日本)
障害発生概要(NTT西日本)
一方、NTT西日本では、午前7時10分~午前8時49分までの1時間39分に渡り、障害が発生。光アクセスサービスで最大8万7,000件、そのうちひかり電話で最大4万7,200件での影響があったという。
7時10分に富山、石川、福井、滋賀、大阪、鳥取、島根、徳島、愛媛、岐阜エリアで、加入者収容装置に故障アラームが発生。7時13分に徳島エリアで、8時46分に愛媛、福井、岐阜、滋賀、島根エリアで、8時47分に富山エリアで、8時48分に石川、鳥取エリアで回復し、8時49分にはすべてのエリアでの回復を確認した。なお、NTT西日本では約1,110ビル、約3,560台の加入者収容装置が稼働しているという。
本事象に係わるネットワーク構成図(NTT西日本)
り障数(NTT西日本)
NTT東日本およびNTT西日本によると、今回の障害による大規模な被害の申告は、現時点では、法人、個人ともに聞かれていないという。
「今回の事象をしっかりと解析する。どのような原因で発生したのか、なぜ特定の装置だけに発生したのかを分析し、その結果をもとに可及的速やかに対処したい。特殊なパケットの侵入については監視を強化し、同じような事象が短期間に再発しないように努める」と述べた。 』
Samsung、ChatGPTの社内利用で3件の機密漏洩
https://pc.watch.impress.co.jp/docs/news/yajiuma/1490904.html
『韓国이코노미스트(Economist)は3月30日、Samsung Electronicsが社内でChatGPTの使用を許可したところ、機密性の高い社内情報をChatGPTに入力してしまう事案が発生したと報じた。少なくとも3件が確認されているという。
報道によれば、Samsungの半導体事業などを担うDS(Device Solution)部門において、3月11日にChatGPTの使用を許可。その後、約20日間で少なくとも3件の事案が発生したという。内訳は、設備情報の流出が2件、会議内容の流出が1件。同社では、事故の経緯の調査を進めるとともに、緊急措置としてChatGPTへの1質問あたりのアップロード容量を1,024B(バイト)に制限。今後も同様の事案が発生するようであれば、接続を遮断する可能性もあるという。
事案の詳細は、1件目が、半導体設備測定データベースのダウンロードソフトに関するエラーを解消するため、ソースコードをChatGPTに入力して解決策を問い合わせたもの。2件目が、歩留まりや不良設備を把握するプログラムに関するソースコードをChatGPTに入力し、コードの最適化を図ったもの。3件目が、社内会議の録音データを文書ファイルに変換後、ChatGPTに入力し、議事録を作成したものだという。
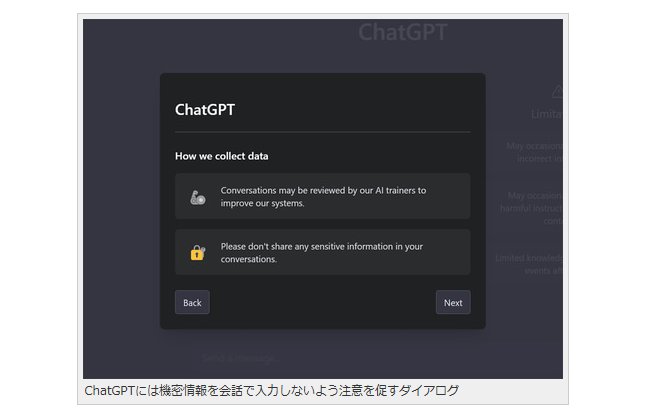
ChatGPTでは、入力されたデータを学習データとして活用する場合があるため、機密性の高い内容を入力すると、不特定多数にその内容が流出する恐れがある。これについてはOpenAI側でも、ChatGPTを利用するユーザーに対し、機密情報を入力しないよう注意喚起している。
ChatGPTには機密情報を会話で入力しないよう注意を促すダイアログ 』
大規模言語モデル(LLM:Large Language Model)とは?
https://atmarkit.itmedia.co.jp/ait/articles/2303/13/news013.html

『用語解説
大規模言語モデル(LLM:Large Language Models)とは、大量のテキストデータを使ってトレーニングされた自然言語処理のモデルのことである。一般的には大規模言語モデルをファインチューニングなどすることによって、テキスト分類や感情分析、情報抽出、文章要約、テキスト生成、質問応答といった、さまざまな自然言語処理(NLP:Natural Language Processing)タスクに適応できる(図1)。大規模言語モデルの代表例としては、2018年にGoogleが発表した「BERT」や、2020年にOpenAIが発表した「GPT-3」などが挙げられる。2022年12月に発表された「ChatGPT」は、2022年初頭にトレーニングした「GPT-3.5シリーズ」をチャット(対話)向けにファインチューニングしたものであり、大規模言語モデルの応用例の一つだ。
図1 大規模言語モデル(LLM)のイメージ
大規模言語モデルの「大規模」に明確な基準はないが、BERTとGPT-3を参考値として示しておく。BERTは、28億語のWikipediaデータと8億語のGoogle BookCorpusデータで合計33億語のデータからトレーニングされている。GPT-3は、45TB(テラバイト)のデータ(最終的に合計4990億トークン)からトレーニングされている。GPT-3.5のデータセットについては筆者が調べた限り発表されていない。
大規模言語モデルは、その内部のニューラルネットワークに含まれるパラメーターの数も非常に多い。BERTは3億4千万、GPT-3は1750億、GPT-3.5は3550億ものパラメーターを持っている。
ちなみに、GPT-3やGPT-3.5は基盤モデル(Foundation Model)であり、かつ大規模言語モデルでもある。ただし、「テキスト以外のデータ」(例えば“画像”データ)を使ってトレーニングした基盤モデルは、当然ながら「大規模“言語”モデル」とは言えないことに注意してほしい。つまり、必ずしも「基盤モデル = 大規模言語モデル」ではない。』
ChatGPTのプロンプトエンジニアリングはとても「変なもの」。PKSHAと東大・松尾教授が語る
https://pc.watch.impress.co.jp/docs/news/1491102.html
『AIソリューション、AI SaaSの開発・提供を行なっている株式会社PKSHA Technology(パークシャテクノロジー)は2023年4月4日、「歴史転換期におけるChatGPT/LLMのビジネス活用の展望」と題したメディア向け勉強会を行なった。
勉強会は、東京大学大学院 工学系研究科 人工物工学研究センター/技術経営戦略学専攻 教授でPKSHA Technology技術顧問でもある松尾豊氏と、株式会社PKSHA Technology 代表取締役の上野山勝也氏の対談形式で行なわれた。大規模言語モデル(LLM)やOpenAIの「ChatGPT」は一時的トレンドか技術的転換か、今後事業成長に繋げるには、日本企業の勝機はどこにあるのかといったテーマで議論が行なわれた。
ChatGPTは技術的転換点
株式会社PKSHA Technology 代表取締役 上野山勝也氏
最初のテーマは「『ChatGPT』は一時的トレンドか技術的転換か」。松尾氏は「一時的トレンドではない」と断言。「ChatGPTは次の単語を予測するnext-token-predictionを行なっているだけだが、使ってみれば分かるように、相当複雑な概念も学習していて、それをプロンプトで引き出すと良い答えが出てくる。これが世の中に広まっていくことは間違いない」と語った。
PKSHAの上野山氏は「新しい知を産んでいるのかどうか。どう解釈するといいか」と質問。松尾氏は「生み出していると思う」と答えた。「プロンプト・エンジニアリングで、つまり人間とのコンビネーションで生み出している。確かに学習データはインターネット上のデータだが、もともとだいたいの創造性は類型化+混ぜ合わせ。ChatGPTがやっていることもかなり創造的だと言えると思う」と述べた。
一方「逆に人間にしかできないことは何か」という問いに対しては「目的を考えること」と答えた。「人間の場合、大脳基底核の報酬系の機能で楽しいこと、嬉しいことをやるためにはと考える。さらにそこから世の中の役に立つことはと考える」と述べ、そこは人間独自だと述べた。
今後もオープンに研究を進めることが重要
東京大学大学院 工学系研究科 人工物工学研究センター/技術経営戦略学専攻 教授、PKSHA Technology技術顧問 松尾豊氏
次のテーマ、AI研究者がみる「ChatGPT」の本質的な価値について松尾氏は「研究界隈も騒然としている」と答えた。「だいぶ変わり目。3月の言語処理学会でも「ChatGPTで自然言語処理は終わるのか?」という緊急パネルが行なわれた。これまでは深層学習の研究はかなりオープンに行なわれてきたが、今後はかなりクローズドになるのではないかという流れがある。産業化する時はだいたいそうなる。アカデミアでできる研究はこれから限られてくるかもしれない。だからもっとオープンにという流れも必要」と考えているという。
コミュニケーション問題をチャットAIが解決する時代へ
「日常生活をどう変えるか」というテーマについては「相当変えると思う」と答えた。PKSHAの上野山氏は以前から「世の中のほとんどの問題はコミュニケーションの問題だ」と言っていたとのことで「その多くが解決する可能性がある」と述べた。
「コミュニケーションの不具合が多くの問題の根底にある」ということについてはPKSHAの上野山氏が補足した。上野氏は「例えば、ある事業部が『こういうことをやったら良いんじゃないか』と考えても、事前のコミュニケーション不足が原因でできなかったりすることは多い。社内にチャットエージェントを解き放つと、まずAIエージェントに話しておくと、AIが他の人に話しておいてくれるかもしれない。人間のコミュニケーション構造を変えるかもしれない」と述べた。
今回はメディア向け勉強会だったこともあり、松尾氏は「ほとんどの人は情報加工業を営んでいる。情報加工業をAIが担うようになると、一番最初と最後しか価値がなくなるという説明の仕方もある」と語った。
また、学習や教育への変化についてもよく質問されるという。だがこれについては松尾氏は「分からない」と苦笑しながら答えた。「3カ月前から世の中激変したけれど教育は10年単位。どんな影響が起こるのかはわからない。でもうまく使うと学びにとっても良いツールになるはず。少なくとも個別の学びを提供できるようになったりするはず」と述べた。PKSHA 上野山氏は「問を立ててもらうこと」や、環境が変わっても適用できる能力の学習に興味を持っているという。
また、ARグラスと組み合わせることで、喋るべきことや質問候補などを自動でAIが提示してくれるようになるのではないかといった未来も想定できるとし、将来は生身で喋るのは怖いことになるかもしれないと語った。PKSHA 上野山氏によれば、実際、既にそのようなプロトタイプは作られているという。
プロンプトエンジニアリングはとても「変なもの」
では事業成長に繋げるためにはどうすればいいのか。PKSHA 上野山氏は「伝統的な企業、ソフトウェア企業、スタートアップはそれぞれゲームルールが違う。トラディショナルなところはAI、DXをどう使うのかという話。
ただし今まではソフトウェアがバックエンドで動いていたが、今回は貫通してフロントエンドにまで出てきている。ソフトウェアで対話しながらアプリケーションが作れる。こういう動的システムを社内でどうデザインするのかは大会社の人事制度をどうするのかみたいなものと似ている」と語り、組織全体の仕組みに関わる本質的な課題に直面すると述べた。
一方、「スタートアップやソフトウェアは使えばいい」と述べた。「我々は主にコミュニケーション領域でAIを使っている。人とソフトウェアを最も対話させている。これをうまく組み込むことで、今までできなかった雑談もできるようになる。スタートアップはうまく使えばいいし、ゼロイチの立ち上げをやってる人には面白いタイミングでもある」と語った。
松尾氏は「すごく変なものが生まれた。この『変なもの感』をうまく伝えたい」と述べた。プロンプトエンジニアリングはとても「変なもの」なのだという。
ChatGPT
例えばChatGPTと顧客DBを連動させる場合を考える。顧客とChatGPTが対話する時には「あなたはスポーツジムの申し込みを担当するアシスタントです。プランはこういう種類のものがあります」と書く。顧客DBと連動させる場合は、顧客の名前を聞くと社内DBにクエリを出してDBから情報を取り出して、例えば過去に来たことがある人かどうかを参照する。つまりChatGPTは顧客と既存のDB両方と話す。それも全部プロンプトに書く。
「あなたにはこういうツールがあります。DBにアクセスしてID、購入履歴を参照できます。ツールを使うかどうかもYes/Noで選択してください」といったことを書くわけだ。DBを引き、帰ってきた返事をプロンプトにまた入れることもできる。こういうことを全部プロンプトで書く。松尾氏は「こんな変なプログラミングありますか」と会場に投げかけた。
自然言語で手順を全て指示書として書く。また変数だけ定義すると、その変数が勝手に計算されたりもする。「そういう、なんだか今までにない変なものが生まれている感がある。すごく不思議な現象が起こっている」と松尾氏は語った。
PKSHA 上野山氏は「文字ドキュメントを大量に学習することで『社会の縮図』みたいなものが表現されているということか」と質問を投げた。松尾氏は同意し、「人間の法律や社内基準、手順書などを元に人間がちゃんと動けるのも、人間というLLMを備えるものが、それのとおりに動いているから。むしろ今までのプログラミングのほうが変わったものだったのかもしれない。今はむしろLLMをどう使うかというほうに揺れ動いているというか、新しいものができつつある」と答えた。
今まで「世界モデル」と言っていたものは、もっと連続的なものだったが、離散的な言語空間のなかに世界モデルが存在しているし、そのなかで行動や概念も学習してしまっているようだという。
創造性については「今までは外挿的なものはクリエーションと言われていた。でもChatGPTが出てきたので、それをクリエーションに入れないように定義が変えられつつある」と述べた。
コミュニケーションテクノロジーの未来
今後はどうなるのか。PKSHA 上野山氏は同社のビジネスについて「顧客接点と社内コミュニケーションの2つにAIエージェントを5,000体くらいばらまいていて、会話したりソフトウェアを動かしたりしている」と紹介。「これがさらに拡張する。ベテランのスポーツコーチがやるように、AIによってコミュニケーションがエンパワーされたり、不具合問題が減っていく。今の会社の部下と上司のコミュニケーションは、ほぼ壊れている。それをちゃんとサポートする。企業と顧客のコミュニケーションもソフトウェアによって滑らかになる」と述べた。
松尾氏は「顧客が欲しいものや嫌なものをちゃんと認識できるようにする。今は社内で色んなことが分かってもらえない、新技術が使えない、事業側と営業側に伝わってない。政治家も同じ。社会全体を個人がこうしたいということを1人ずつ聞き取っているけど、もっとやり方がある」とコメントした。
PKSHA 上野山氏は、そもそも認知されていないジョブがどんどん変わっていく可能性があると述べ、AIエージェントがクレームを言ってる人をいなしたりすることができるだろうと語った。
ChatGPTの画面
AIの新時代における日本の勝機
一部の国ではChatGPTが禁止されたりする動きも始まっている。その中で日本の勝機に繋げるにはどうすればいいのだろうか。松尾氏はまず「LLMを作ったほうがいい」と語った。PKSHA 上野山氏も「いろんなレイヤーがあり、レベルがあるが、何も作らないのはありえない」と同意した。どんなものを作るにしても少なくともLLMを作る人材サイクルが日本にないのは致命的であり、「新しい時代だからこそ基盤技術は自分たちでもやるということだ」と述べた。
ではグローバルに勝ち目があるのか。日本くらいの規模の国ですらLLMを作ることに足踏みしている。PKSHA 上野山氏は「アジア全体の競争戦略として、アジアのバーティカルを横断するようなものとして作ることはあり得る。例えば医療特化モデルをデータ共有しながらつくる、それを日本がリードする」といったかたちはどうかと提案した。
松尾氏は「新時代なので何をやってもいい。何に関してもチャンスがある。ぜひ大きな構想をやっていきたい」と同意した。
今は新しいフロンティアが開けた瞬間だ。松尾氏は「今回はOpenAIからしても予想外のクリーンヒットなので、期せずして『用意ドン』になってしまった。LLMの価値自体はジワッと広がってきていた。ところがそれが『ChatGPT』により史上最速の速さで一気に多くの人が理解して、みんなが話題するようになり、お金も人もそっちに流れている」と現状認識を紹介した。
インターネットの時は一部の人たちが世間から馬鹿にされている間に発展していったが、「今回は全員が価値を認識した。ほとんどの人がヤバいと思っている。だから『用意ドン』になるとビッグテックは速い。だからイーロン・マスクのように『半年止まろうよ』と言い出す人たちも出てくる。『強さは速さなんだ』と再認識した。今までは巡航速度だったのが今は戦闘モードだ」と述べた。
以前から松尾氏は、顧客ニーズを吸い上げて修正するフィードバックがハイサイクルであることが強い会社の共通特徴だと述べており、「スピードが大事と言っていたけれど、自分は遅かった。この2カ月くらい、『自分はなんて遅いんだろう』と再認識して絶望的な気分になっている」と語った。
なお、質疑応答では、汎用人工知能(AGI)はLLMの延長線上にあるのかといった質問もあがった。松尾氏は「汎用人工知能には距離がある。LLMからはまだ複数の課題がある。まだまだだと思っている。でもLLMが世の中にインパクトを与えるのは間違いない」と答えた。また、日々、ChatGPTの新しい活用法を見出して開示している人がたくさんいる文化は日本の強みだと2人は語った。 』
