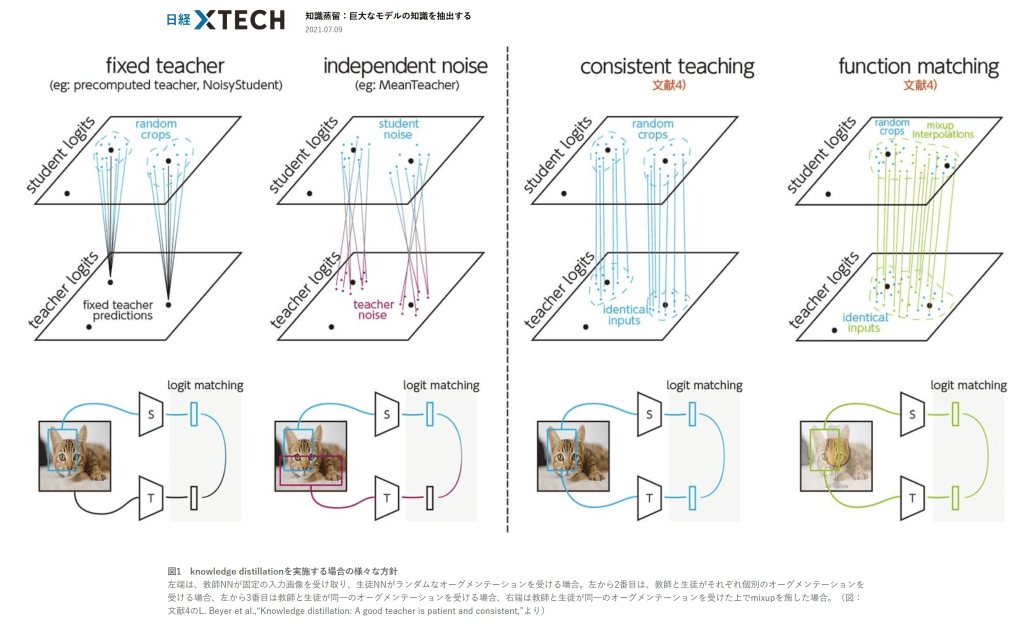
1つ目は教師NNと生徒NNが同じデータオーグメンテーションを適用した入力を使うことである。従来は目標となる教師NNの予測分布には計算資源の節約のために特定のデータオーグメンテーション(クロップなど)を適用して計算したものを毎回固定で使い、生徒NNには毎回異なるデータオーグメンテーションを使っていた。この場合、生徒NNからは教師NNの本当の予測とは違う目標を学習していることになる。生徒と同じ入力を教師NNが使うことで、一貫性のある目標を設定することができる。さらに複数の学習データの線形補間を入力に使うmixupをアグレッシブに使うことが重要であった(図1)。 図1 knowledge distillationを実施する場合の様々な方針 左端は、教師NNが固定の入力画像を受け取り、生徒NNがランダムなオーグメンテーションを受ける場合。左から2番目は、教師と生徒がそれぞれ個別のオーグメンテーションを受ける場合、左から3番目は教師と生徒が同一のオーグメンテーションを受ける場合、右端は教師と生徒が同一のオーグメンテーションを受けた上でmixupを施した場合。(図:文献4のL. Beyer et al.,“Knowledge distillation: A good teacher is patient and consistent,”より) [画像のクリックで拡大表示]
1)G. Hinton et al.,“Distilling the Knowledge in a Neural Network,” NeurIPS Deep Learning and Representation Learning Workshop, 2015. https://arxiv.org/abs/1503.02531 2)T. B. Brown et al.,“Language Models are Few-Shot Learners,”NeurIPS 2020. https://arxiv.org/abs/2005.14165 3)Z. Allen-Zhu et al.,“Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning,”https://arxiv.org/abs/2012.09816 4)L. Beyer et al.,“Knowledge distillation: A good teacher is patient and consistent,” https://arxiv.org/abs/2106.05237 5)R. Müller et al.,“When Does Label Smoothing Help?,” NeurIPS 2019. https://arxiv.org/abs/1906.02629 6)H. Mobahi et al,“Self-Distillation Amplifies Regularization in Hilbert Space,” https://arxiv.org/abs/2002.05715