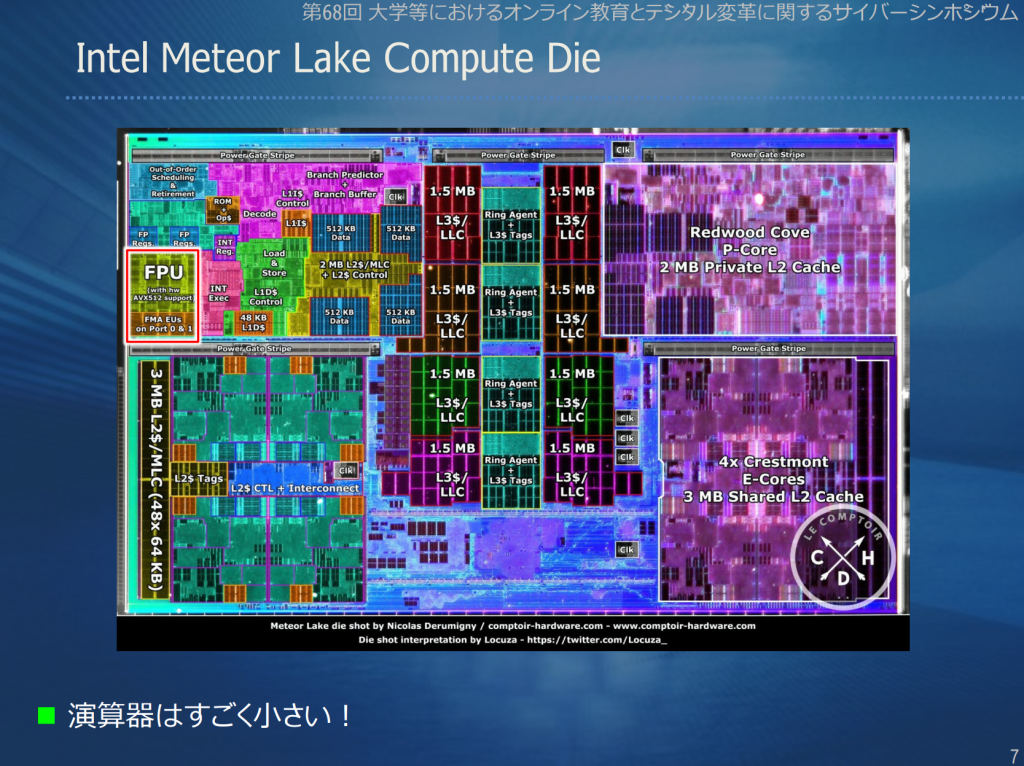
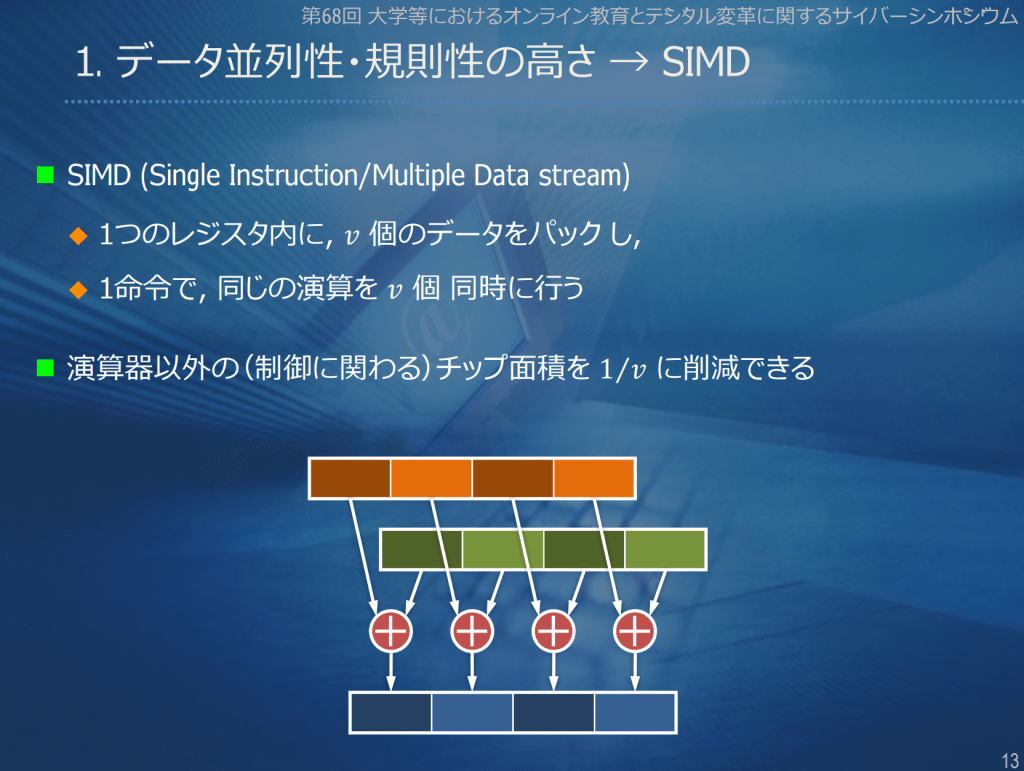
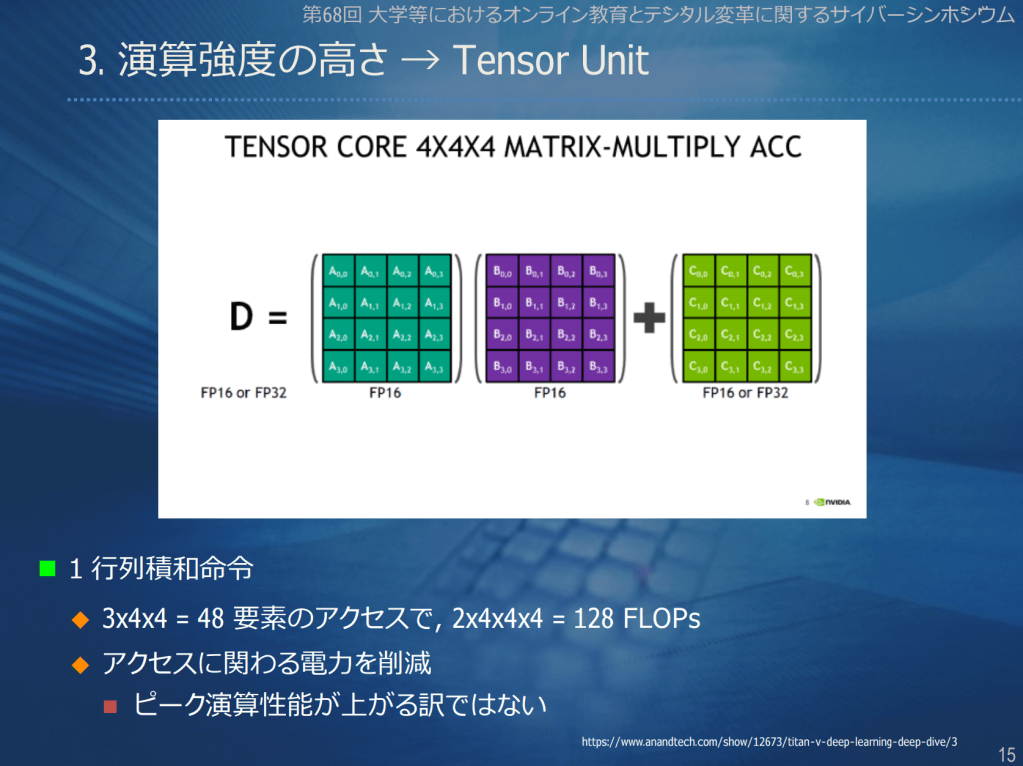
カテゴリー: GPU、関連
-
GPUの起源と進化
https://gdep-sol.co.jp/gpu-technology/no6/




『2021年3月5日
- はじめに
GPUの源流は、1982年に発表されたジオメトリーエンジン(Geometry Engine)です。
本稿ではGPUがどのように誕生し進化したかを振り返ります。筆者は1990年代後半にシリコングラフィックス(Silicon Graphics, Inc.)の日本法人にシステムエンジニアとして勤務し、ハイエンド3D CGのコンピューターシステム(ワークステーション)の導入やインハウスのプログラマーへの支援を担当していました。
顧客は主に、国内の大手メーカーや研究所で、ときにはアジアの拠点に赴き、中韓台シンガポールの顧客を支援することもありました。GPUの機能がボードや筐体に分散していた頃で、フレームメモリを積んだ追加ボード1枚が2000万円から4000万円もしていました。ハードウェア構成をどうするかは顧客にとって重大問題でした。アプリも少なく、顧客は自らプログラムを組んで問題解決を行う場合が多い時代でした。
ハード、ソフトの両方を業務とし、技術製品開発者と顧客との橋渡しをした者の視点で、多少の人間ドラマも交えて、GPUの発展を振り返ってみたいと思います。
- GPU以前の実時間描画のシステム
3D CGの基本的処理として、三次元の仮想空間に配置した形状モデルを二次元の画面上に対応づける座標変換があります。
多数の頂点座標に対して同じ処理を行うため、この座標変換を高速化することは描画処理全体を高速化することに直結します。
1982年にスタンフォード大学のジム・クラークは座標変換に特化したチップ(ジオメトリーエンジン)を考案しました[1] 。
?彼はこの技術を広めるために、大学院生とともにシリコングラフィックスを1982年に起業しました。
80年代はCG分野で現在の基盤となる高度なアルゴリズムが多数研究された年代で、光線追跡法(レイトレーシング)、ラジオシティ法、ボリュームレンダリング、レンダリング方程式、経路追跡法(パストレーシング)、フラクタルなどが紹介されました。
?動力学シミュレーション、流体シミュレーションがCGで研究されるようになったのもこの時期です。
そしてこの80年代は、CG処理を高速で実行する多数のハードウェアシステムが研究され、商品化された時期でもあります。
その中でシリコングラフィックスの「IRISシリーズ」というラスター処理のシステムが市場で優位を占めるようになり、90年代前半にはCGの研究開発や応用を行う者にとって同社のワークステーションは必須の道具となりました(ちなみに、最盛期の同社営業は電話を受けて注文を断ることがその業務だと言われるくらい市場を占有しました)。
シリコングラフィックスのカート・エイクリーらは、1988年に三角形の塗りつぶし処理を行う方式を発表しました[2] 。
彼のラスター化方式は、後年のGPUの処理そのものであり、現在でもこの方式が使われています。エイクリーは同社の創業メンバーであり、ジム・クラークの研究室の修士学生でした。
またエイクリーは、CGプログラマーが同社のワークステーションで描画処理を記述するためのグラフィックスライブラリとしてIRIS GLを提供しました。
シリコングラフィックスのハードウェアが普及した理由の一つがこのIRIS GLの使い易さです。
1990年代には関数名などを整理してオープン化し、OpenGLとして普及しました。
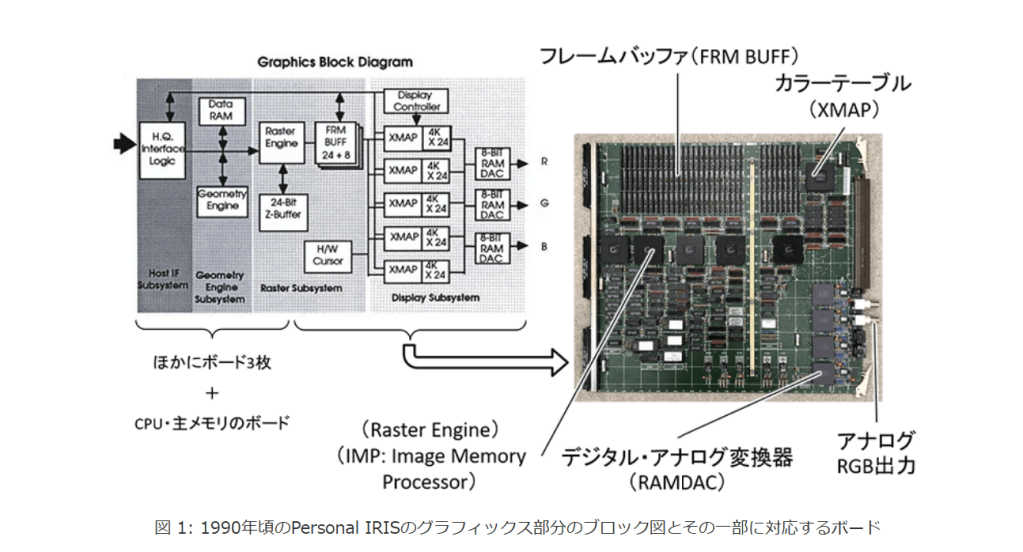
図 1: Personal IRIS
図 1: 1990年頃のPersonal IRISのグラフィックス部分のブロック図とその一部に対応するボード
図1は、同社のワークステーションPersonal IRIS(1990年頃)のグラフィックス部分のブロック図とボードの一部です[3] 。
このブロック図全体のうちフレームバッファ(”FRM BUFF”)を除く部分が概ね現在のGPUチップに相当します。当時はこのブロック図に相当する部分が大きなボード4枚で構成されていました。
ブロック図の最初の主な処理は頂点処理で、ジオメトリーエンジンのチップが載ったボード(”Geometry Engine Subsystem”)で実行されます。
CPUの主メモリから転送されてきた3D空間内の三角形の頂点座標に4×4行列を乗じていき、最終的にはスクリーン座標の値を得ます。後年の頂点シェーダーの処理です。
写真のボードは、処理の最終段階を担うもので、フレームバッファに塗りつぶし結果を格納する”Raster Subsystem”と、画像のRGB出力を行う”Display Subsystem”が載っています。後年で言うと、ラスタライズ処理部分とフラグメントシェーダー(ピクセルシェーダー)処理部分です。
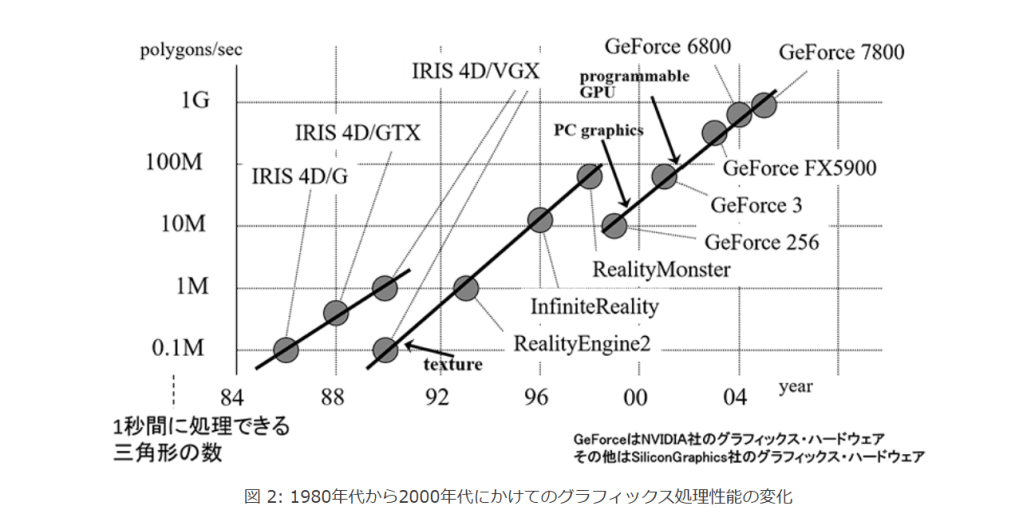
図 2: グラフィックス処理性能の変化?
図 2: 1980年代から2000年代にかけてのグラフィックス処理性能の変化?
図2は、1980年代後半から2000年代中頃までのグラフィックスハードウェアの処理性能のグラフを示しています。
一つの目安として、1秒間に座標変換処理を何頂点に対して実行できるか、という頂点処理性能を縦軸に対数軸で示しています。グラフが2か所で不連続になっているのには理由があります。
1990年で性能が一桁下がったのはテクスチャマッピングの機能が標準的に加わったことがその理由です。
1998年頃で一桁下がったのは、それまでは高価なワークステーションのシステムだったのが、GPUチップ登場によりPCベースの安価なシステムが標準になったためです。
ちなみにこのときコストは、1~2億円から20万円程度と三桁下がっています。つまりこの時点でコストパフォーマンスは100倍になったということです。
また、このグラフ全体を見ると、ほぼ一貫して3年ごとに十倍程度の性能向上が実現されていることがわかります。2005年頃までで、このグラフは終わっていますが、頂点処理性能という指標が意味をなさなくなったためで、詳細は後述します。
- GPUの登場とプログラマブル化
1990年代前半には、CGの実時間描画(リアルタイムレンダリング)処理であるラスタライズ方式が確立しました。
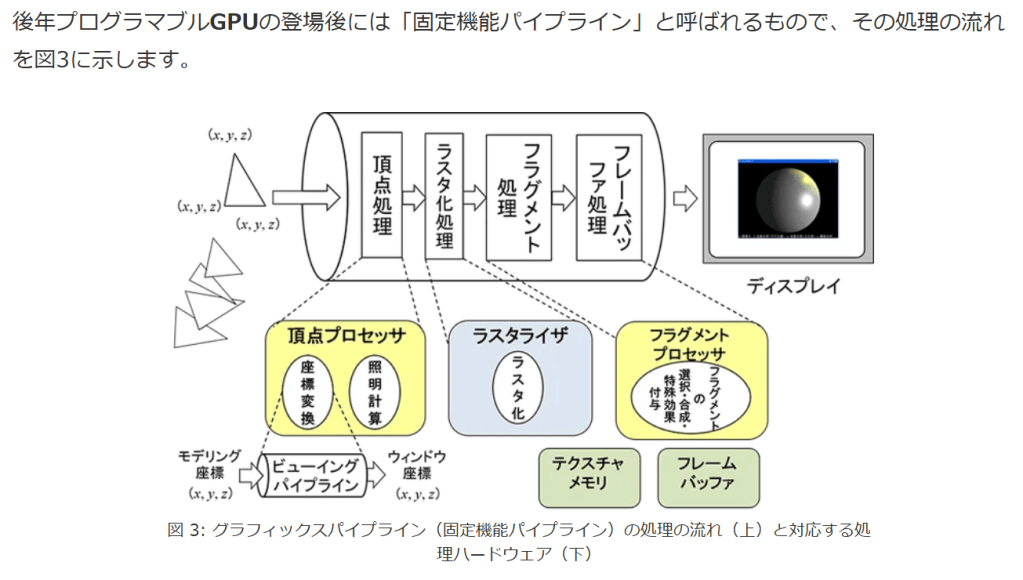
後年プログラマブルGPUの登場後には「固定機能パイプライン」と呼ばれるもので、その処理の流れを図3に示します。
図 3: グラフィックスパイプライン
図 3: グラフィックスパイプライン(固定機能パイプライン)の処理の流れ(上)と対応する処理ハードウェア(下)
頂点プロセッサで座標変換と頂点の輝度を計算し、線形補間で三角形内部の画素を塗りつぶしたラスタライズを行い、フラグメントプロセッサで画素ごとの処理を行いフレームバッファ(画像メモリ)に結果を格納します。
90年代半ばのシリコングラフィックスのハイエンド製品でも数枚のボードでこれらの処理を行っていました。
実は、当時から図3のプロセッサの部分をカスタマイズすることで、プログラマブルな処理は可能でした。そのやり方は、内部のEEPROM(書き換え可能な読み出し専用メモリ)に埋め込まれたマイクロプログラムを書き換えるという方法です。
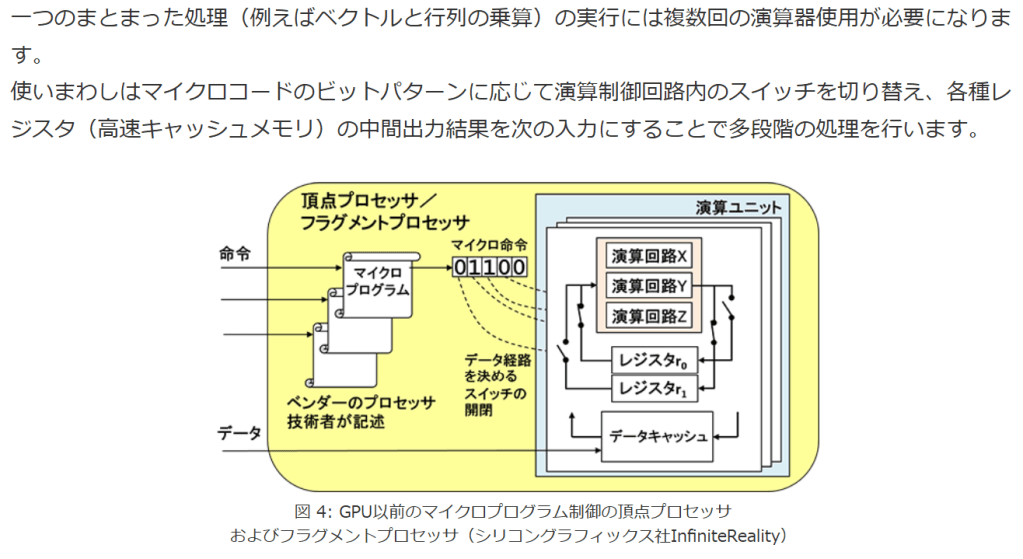
図3のプロセッサ部分を詳細化したのが図4です。
?マイクロプログラムは、チップ集積度が低く演算ユニットが少なかった時代の工夫で、一つの演算器を使いまわす方式です。
一つのまとまった処理(例えばベクトルと行列の乗算)の実行には複数回の演算器使用が必要になります。
使いまわしはマイクロコードのビットパターンに応じて演算制御回路内のスイッチを切り替え、各種レジスタ(高速キャッシュメモリ)の中間出力結果を次の入力にすることで多段階の処理を行います。
図 4: 頂点プロセッサ
図 4: GPU以前のマイクロプログラム制御の頂点プロセッサ
およびフラグメントプロセッサ(シリコングラフィックス社InfiniteReality)
当時のシリコングラフィックスでこのマイクロコード作成を担当していたのがエリック・リンドホルムです。
図5は、マイクロコード化を行う前にCPUプログラムで頂点処理をエミュレートした「シリンダーマッピング」という処理の結果です。
円筒状に線光源が配置された大きな部屋に、車の形状モデルを置いた場合の映り込みが頂点レベルで正確に計算できる機能で、頂点における反射方向を求め円筒内側との交点を求める計算を行います。
マッピング)は、MayaなどのCGソフトでも簡単に使えるようになっていますが、1997年当時のシリコングラフィックスのOnyx2 InfiniteRealityというハイエンドグラフィックス製品を使い、自動車会社の依頼を受けて作成されました。
図5: シリンダーマッピング
図 5: シリンダーマッピングによる実時間表示例(1997年当時)。
?マイクロコード化の予定であったが、実現することはなかった。業界では90年代後半になると、PC用の3Dグラフィックスチップが開発されるようになりました。
1995年頃にはラスタライズとフラグメント処理を行うチップが市場に出て、1999年にはエヌビディア社(NVIDIA)が頂点プロセッサも載ったGeForce256を発売しました。固定機能パイプラインを1チップで処理するもので、GPUと呼べる最初のチップです。
残念ながらシリコングラフィックスは、ハイエンド製品にこだわり、1996年にスーパーコンピュータのクレイ・リサーチ社を買収したため、GPU開発の方向には進みませんでした。
その後シリコングラフィックスは、毎年のように赤字となり2000年代半ばには、2度に渡り会社更生法(Chapter 11)の適用を受けて倒産に至りました。典型的な「イノベーションのジレンマ」による凋落です。
歴史に仮定は禁物ですが、1990年代半ばにクレイの代わりにエヌビディアを買収していれば、現在のAIブームに至ってもシリコングラフィックスがIT業界で活躍していた可能性が高いと思います。
さて、前述のリンドホルム氏は90年代後半、他の多くのシリコングラフィックスの優秀な技術者と同様にエヌビディアへ移籍しました(その後カート・エイクリーも同社に移籍)。
初期のGeForceシリーズでもリンドホルムはプロセッサのカスタマイズを担当していましたが、社内からのカスタマイズ要求は多く、その対応は多忙を極めたと推測されます。
リンドホルムは、ついにはいくつかの基本的な命令を処理する演算ユニットをそれぞれ用意し、それらを自由な順番で呼び出すためのアセンブラ命令体系を公開しました。
GPU処理のカスタマイズはアプリケーションのプログラマーが自由にやってくれということです。2001年に発表されたプログラマブル頂点シェーダーです[4] 。
同年、頂点シェーダー機能が搭載されたGeForce 3が発売され、ラスタライズ処理後の各画素での処理を行うフラグメントシェーダーもその後のGeForce 4で実現されました。
- 汎用の並列計算チップへの発展
半導体チップの集積度向上により、2002年頃になるとマイクロプログラム制御で演算器を使いまわしする必要がないくらい多数の演算器をGPUに搭載できるようになりました。
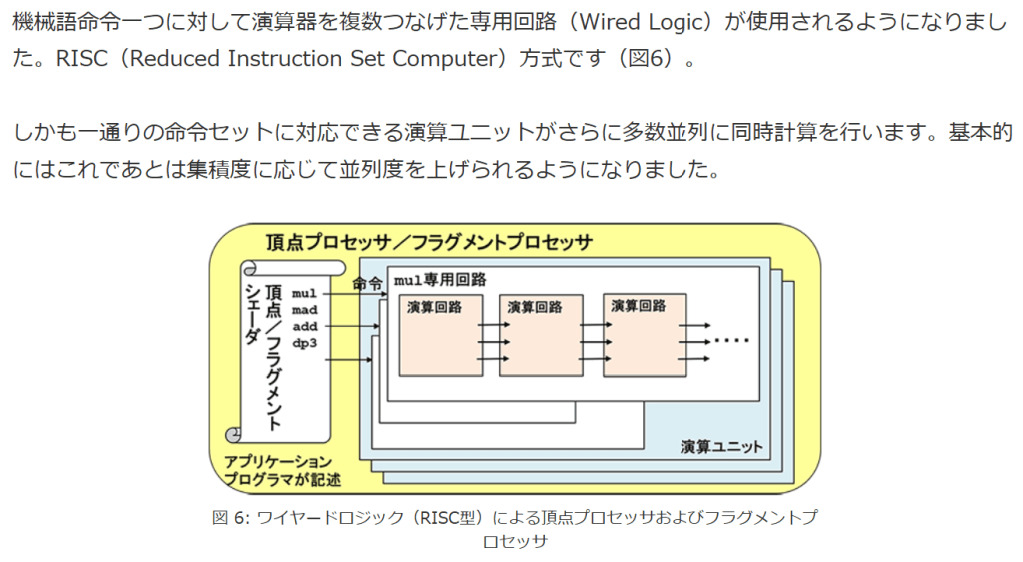
機械語命令一つに対して演算器を複数つなげた専用回路(Wired Logic)が使用されるようになりました。RISC(Reduced Instruction Set Computer)方式です(図6)。
しかも一通りの命令セットに対応できる演算ユニットがさらに多数並列に同時計算を行います。基本的にはこれであとは集積度に応じて並列度を上げられるようになりました。
図 6: ワイヤードロジック(RISC型)
図 6: ワイヤードロジック(RISC型)による頂点プロセッサおよびフラグメントプロセッサ
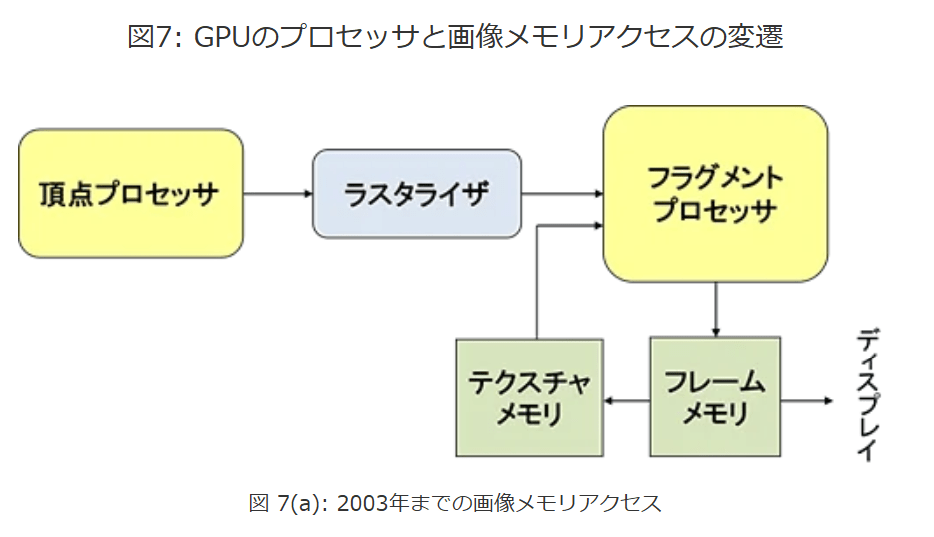
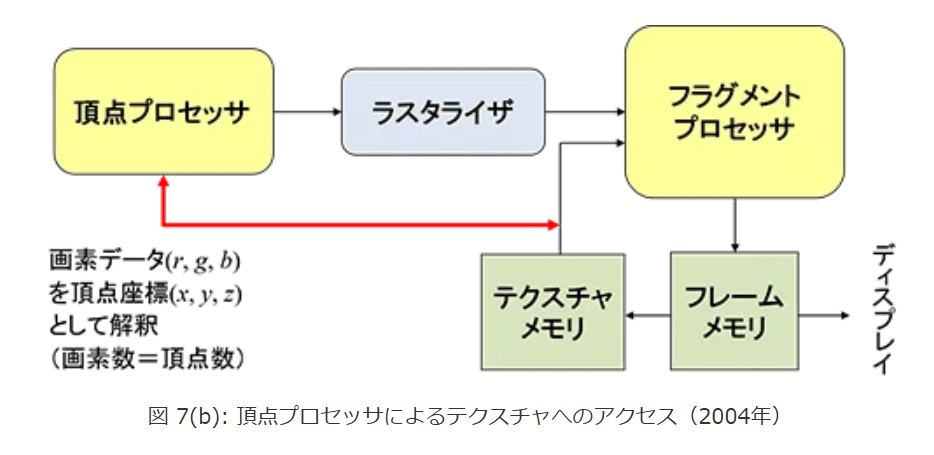
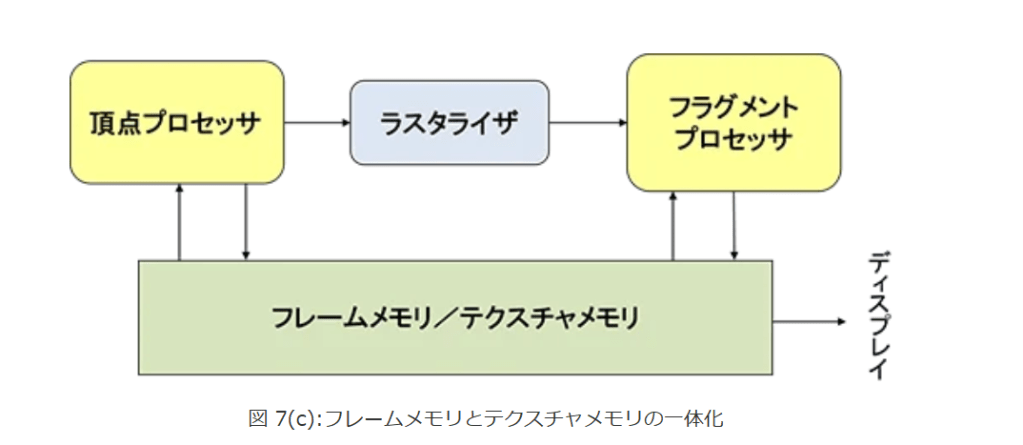
さらにGPUチップ外のフレームバッファとテクスチャメモリのアクセスについても改良が行われました。
2004年には、頂点プロセッサからテクスチャメモリに直接アクセスができるようになり、さらにはテクスチャメモリとフレームメモリが一体化して描画結果を転送なしでそのままテクスチャとして使用できるようになりました。
図7はこれらの変遷を示すブロック図です。
図7: GPUのプロセッサと画像メモリアクセスの変遷
図 7(a)2003年までの画像メモリアクセス
図 7(a): 2003年までの画像メモリアクセス
図 7(b): テクスチャへのアクセス
図 7(b): 頂点プロセッサによるテクスチャへのアクセス(2004年)
図 7(c):フレームメモリとテクスチャメモリ
図 7(c):フレームメモリとテクスチャメモリの一体化?2006年には、頂点シェーダーとフラグメントシェーダーで利用する演算ユニットを共通化?するユニファイド・シェーダー(Unified Shader)が実現しました(図8)。
それまでは両シェーダーがそれぞれに演算ユニット群を持っていたため、処理負荷が偏るとグラフィックスパイプラインの流れ作業でいずれかが資源を遊ばせてしまう事態になっていました。
図 8: ?ユニファイド・シェーダー
図 8: ?統合されたプロセッサによるユニファイド・シェーダーの実現
多数の演算ユニットを一つのグループとして共有することにより、負荷に応じて演算ユニットを再配分する負荷分散が実現されました。
前述の図2のグラフが2006年以降プロットされないのは、頂点処理性能が指標として適さなくなったためです。
頂点処理に最大性能を費やすことは、他の処理が演算ユニットを使えない結果になり、明らかに無意味な処理です。
ユニファイド・シェーダーによって、現在のGPUの基本形ができあがり、あとは演算ユニットの並列度を高め性能を上げていくという流れができました。
また、その頃から頂点シェーダーとフラグメントシェーダー以外にもパイプラインの途中に各種シェーダーが加わることになりました。
新たな頂点を生成するジオメトリーシェーダーはその代表例で、2011年のShader Model 5.0では7種類のシェーダーが利用できるようになりました。
さらに、GPGPU(General Purpose GPU)の分野が、2000年代半ばから徐々に広がりました。
もともとGPUがプログラマブルになった2000年代前半から、グラフィックス以外の汎用の並列計算にGPUを利用しようというGPGPUの概念はあったのです。そのための開発環境であるCUDAもエヌビディア社によって提供され利用されていました。
GPGPUの需要に拍車をかけたのが、2010年代前半からのディープラーニングを中心とした人工知能のブームです。
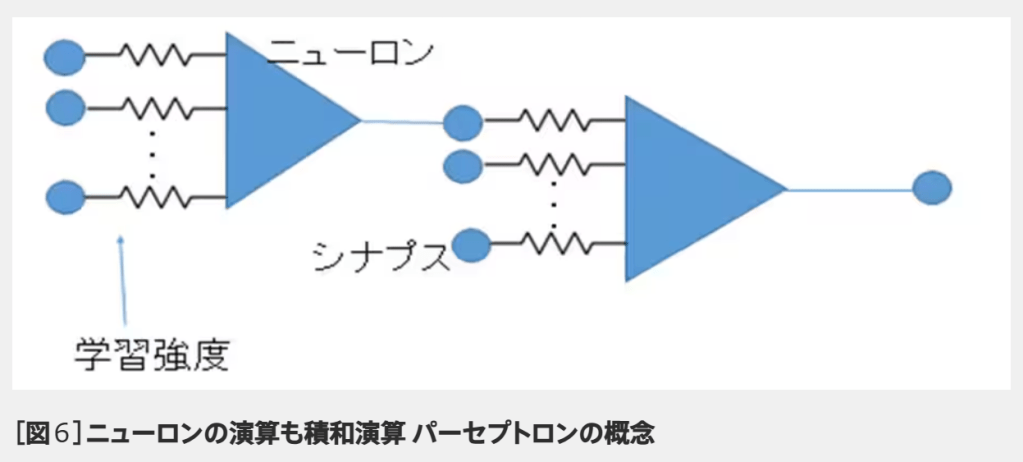
ニューラルネットワークの演算である並列の積和演算は、GPUがもっとも得意とする処理です。
?いまやエヌビディア社は人工知能銘柄の代表格になっています。
- おわりに
本来この記事のシリーズは、GPUに関連する最新の研究や動向を紹介するものですが、今回はGPUの歴史的な側面を紹介しました。
読者がGPUの起源を知ることにより、将来何かのきっかけで役に立つことがあれば幸いです。
筆者がいつか記録として残したいと思っていた内容で、このような記事を書く機会を与えて下さった西田友是先生はじめGDEPソリューションズ株式会社の関係各位に感謝いたします。
【参考文献】
[1] Jim Clark, “The Geometry Engine: A VLSI Geometry System for Graphics,” Computer Graphics, Vol. 16, Issue. 3 (Proc. ACM SIGGRAPH 82), pp. 127-133, 1982.
[2] Kurt Akeley and Tom Jermoluk, “High Performance Polygon Rendering,” Computer Graphics, Vol. 22, Issue. 4 (Proc. ACM SIGGRAPH 88), pp. 239-246, 1988.
[3] Silicon Graphics, Inc., “The Personal IRIS ? A Technical Report,” 1989.
[4] Eric Lindholm, Mark J. Kilgard, and Henry Moreton, “A User-Programmable Vertex Engine,” Proc. ACM SIGGRAPH 2001, pp. 149-158, 2001.著者紹介
柿本 正憲 先生
柿本 正憲 先生
東京工科大学 教授
プロメテックCGリサーチ 研究員東京大学工学部電子工学科卒業後、富士通研究所、グラフィカ、ノバ・トーカイ、日本シリコングラフィックス(現 日本SGI)、シリコンスタジオを経て現職。この間、東京大学大学院情報理工学系研究科電子情報学専攻博士課程修了、情報処理学会グラフィクスとCAD研究会幹事・可視化情報学会理事等を歴任。
所属:東京工科大学 メディア学部 メディア学科、大学院 メディアサイエンス専攻 / 教授、メディア学部長 』 -
NVIDIAの新卒採用条件wwwwwwww – PCパーツまとめ
http://blog.livedoor.jp/bluejay01-review/archives/61591977.html※ そもそもが、AIに「最適化」できる「行列演算」の速度で「覇権」を取ろうとしている会社なわけだ…。
※ AIのアルゴリズム、ニューラルネットワーク、ディープラーニング等のソフトウエア理論に精通し、それを実際の半導体チップ(GPU)の「設計」に落とし込めるハードウエア関係構築に精通している必要があることは、当然だ…。
※ 「世界最先端」の戦いとは、そういうものなんだろう…。
※ CPUの設計では、既に、微細加工技術中心の2Dの戦いから、3D構造やチップレットによるタイル構成の戦いへと、フェーズは移行している…。
※ GPUの設計の世界においても、そういう「ブレークスルー」を見据えているんだろう…。

『 2024年06月22日14:01
1: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:48:33.021 ID:qYqPo0eB0
・コンピュータ科学/工学、電気工学などの博士号を取得、または同等の研究経験があること。・LLMと基礎モデル、ディープラーニングの理論と実践に関する優れた知識
・著名な国際会議で最低8本の論文を発表していること
no title2: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:49:13.480 ID:xDu7kTK90
はえーやさしい3: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:49:49.037 ID:UTP8/DGv0
緩いな4: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:49:51.311 ID:dT8cygO70
楽勝やな6: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:49:54.854 ID:FPBvJXGKM
半導体のやつか8: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:50:24.792 ID:zTFfqloM0
Exellent communication skills←11: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:51:26.873 ID:gmf1VPuu0
8
あっ…10: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:51:00.338 ID:NKv6Y8Z2M
お前らが一番だめなやつ入ってるじゃんExcellent communication skills
9: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:50:57.568 ID:DcZ+ucq40
お前らなら楽勝だろ?12: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:51:39.186 ID:qYqPo0eB0
Vipperの8割は余裕やろ13: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:51:51.587 ID:JhSMRKne0
当てつけでやってるわけじゃなく本当に欲しい人材の条件を明記してるだけ14: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:51:51.909 ID:/mu0jNNA0
海外でも研究開発者にコミュ力は必要なんだな16: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:52:33.999 ID:1af3AvEn0
中途ならいそうだけど新卒だと一握りしかいなさそう19: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:53:07.646 ID:f1f3mDPz0
まぁギリいけるかな20: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:53:19.857 ID:bA7uKdfwd
日本人「博士?論文?」21: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:54:18.097 ID:O7PoLYAu0
一人の天才が世界を変えられる時代は終わった
今はどこでもコミュちからよ23: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:55:35.523 ID:o+xjBEbB0
アメリカ企業は新卒採用なんてしないからどこも当たり前のようにこんな条件だしてくるんだよな29: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 15:59:52.504 ID:IRtct30+0
論文8本ってすごいの?34: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:01:44.688 ID:zaqm1i6iM
29
普通は1年に一本出せれば良い方30: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:00:36.832 ID:lFij5JmKp
清掃でもいいんだけど31: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:00:55.019 ID:e9yAoS6o0
向こうの博士課程はちゃんと博士として尊敬されるから…33: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:01:43.612 ID:PqFmQT2gp
上級者ってなぜか叩かれてるけどこんなん英才教育受けてる上級の子供しか太刀打ちできんだろ35: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:02:06.120 ID:7U9Ku87y0
生み出す側の人間になれるのはひと握りの逸材
殆どの人間が使う側の人間なのだから38: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:04:01.780 ID:IiBQR4p10
こ、こみゅにけーしょん……むりぽ42: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:13:49.764 ID:hUeWR0D8M
新卒時点で著名な国際会議で8本はほぼ無理
日本だと形だけの実績づくりのための発表の場を設けてる学会とかいくらかあるんだけどね49: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:44:10.204 ID:Bco/02NSr
論文8本は筆頭著者でなくてもよいなら
地方国立大の任期付助教でもいるレベル51: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 16:48:29.861 ID:hUeWR0D8M
49
わざわざ論文誌への掲載ではなく発表って書いてるんだから筆頭著者のみカウントだろ
共著者で良いなら研究室によっては学部生でもクリア出来てしまう52: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:05:05.617 ID:AwCz7Baq0
some rapid ってどういう意味なんだ?
他は分かったがここだけ意味わからんかった
英語博士頼む53: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:07:46.906 ID:bbiw7kMl0
52
多少行動が早い?56: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:12:24.823 ID:AwCz7Baq0
53
skills in some rapid prototyping environmentsome rapidってプロトタイプ環境にかかってるよな?
意味わからなくね?58: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:12:58.213 ID:1sVfslp50
56
見てなかったわ54: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:11:34.632 ID:dkvy2qv00
52
rapid prototypingっていう手法55: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:12:19.317 ID:1sVfslp50
54
へー57: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:12:43.829 ID:AwCz7Baq0
54
なるほどな
専門用語だったか59: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:16:04.173 ID:S8npAleP0
初任給2000万とかそういう感じだなこれ60: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:21:47.060 ID:UGsc3REC0
パソコン博士のお前らなら余裕じゃん61: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:30:27.211 ID:5mKOI2cg0
日本に何人いんのこんなの65: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:40:36.649 ID:tHIie1Fz0
ニューカレッジグラジュエーションてのは新卒って意味?
新卒にこんなの求めるの?66: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 17:48:37.705 ID:9rdn2wl40
新卒って言っても大学院卒だろ71: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 18:40:34.423 ID:/Qv1lU0e0
有名どころは一応は査読があるしあくまでも選考に進むための最低条件でしかないから73: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 19:40:25.714 ID:2fbqfZYGd
8本は学士卒論含めて毎年1本以上のペースで書けばできない事は無いな75: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 19:42:07.193 ID:V8WZPuRe0
この能力持ってるやつが入りたくなるくらい高待遇なの?76: 以下、5ちゃんねるからVIPがお送りします 2024/06/21(金) 19:43:39.360 ID:07DtOrbv0
マジでこれでお給料どれくらい貰えるんや全く想像がつかん🤔引用元:https://mi.5ch.net/test/read.cgi/news4vip/1718952513/』
『コメント一覧
1. 名無しのPCパーツ 2024年06月22日 14:08 ID:XxjLsbad0 著名な国際学会で論文8本は地獄すぎる 2. 名無しのPCパーツ 2024年06月22日 14:10 ID:F4HIaI0z0 >>海外でも研究開発者にコミュ力は必要なんだな あたりめーだろ むしろなんで必要ないと思ったんだよ 3. 名無しのPCパーツ 2024年06月22日 14:25 ID:c.GFTvt40 >>1 (ie. CVPR, IEEE, NeurIPS, etc) 既存のテック企業のR&D部門で働いてるレベルやね 4. 名無しのPCパーツ 2024年06月22日 14:33 ID:Et2GvZVQ0 海外の募集要項は無茶苦茶な条件だして給与も全然見合ってないけどそこから交渉で妥当なラインまで持ってくのが普通らしい。なお度々応募者を舐めていると炎上する模様。 5. 名無しのPCパーツ 2024年06月22日 14:33 ID:ICqFFtFI0 アメリカはがっつりコンピュータ-サイエンスとかやってる学生がわんさかいるので 日本なんてまるで比べるべくもなくお話にならないのが現状。 6. 名無しのPCパーツ 2024年06月22日 14:39 ID:2dk4rKra0 一般エンジニアはお断り 7. 名無しのPCパーツ 2024年06月22日 14:40 ID:d6YK5nAb0 必須条件じゃ無いのなら、Excellent communication skillsさえあれば多分いける 8. 名無しのPCパーツ 2024年06月22日 14:45 ID:6s2pMkFu0 理系もポリコレに沈みつつあるから学歴に意味があるかどうか 9. 名無しのPCパーツ 2024年06月22日 14:54 ID:ouvg4tlo0 アメリカの会社に「新卒」なんて概念は無いよ 10. 名無しのPCパーツ 2024年06月22日 14:59 ID:EfeN62lb0 >>9 別にそんなことはないぞ 新卒から正社員登用する訳じゃなくてインターンを必ず経由させるってだけだが 11. 名無しのPCパーツ 2024年06月22日 15:03 ID:e6ptY0ef0 >>2 海外の博士もコミュ障エピソードわんさかあるから 普通に求められてないと思ってたわ 12. 名無しのPCパーツ 2024年06月22日 15:08 ID:ZGs71Qq20 何一つ満たせてないワイ低みの見物や 13. 名無しのPCパーツ 2024年06月22日 15:20 ID:SwLF91OG0 これは研究職でも直近で超花形の LLM の Research Scientistの募集であって、当然別の職種の募集も大量にあってそれらの募集要項のレベルは様々 でも本スレとかほかのまとめサイトとかでそこら辺の情報が出てこないのは気になったが 14. 名無しのPCパーツ 2024年06月22日 15:22 ID:YG8VzPae0 AIが自我を持って研究してくれるようになったら、ほとんどリストラされるんか? 15. 名無しのPCパーツ 2024年06月22日 15:23 ID:vqdwEhk.0 研究はチームでやるんだからコミュニケーションないやつは追放されるだろ 16. 名無しのPCパーツ 2024年06月22日 15:24 ID:lNLXYmOT0 藤井聡太が5歳から将棋をやっていたように 出来る人間はスタートが速いから就職する頃には凄い差が付く 17. 名無しのPCパーツ 2024年06月22日 15:42 ID:Yf0oluzz0 >>8 アジアンで低身長でブサイクな日本人なら余裕やんけ 元気になったわ 18. 名無しのPCパーツ 2024年06月22日 15:42 ID:0SV..6vL0 英会話も 19. 名無しのAMDer@Y市ASH区 2024年06月22日 15:47 ID:NAOqGxpZ0 >>17 ここでその低身長で不細工な日本人の言葉を使う貴方は何人なのさ? 20. 名無しのPCパーツ 2024年06月22日 15:50 ID:.RSp7lMF0 この募集して条件満たした人って何人くらい来るのだろう 21. 名無しのPCパーツ 2024年06月22日 15:55 ID:Tq5ZsJxG0 スレチだけど、株を買えばこういう世界のスーパーエリートが頑張ってくれた果実を自宅で享受できるのよね 22. 名無しのPCパーツ 2024年06月22日 16:03 ID:Xt7VYm3Z0 これだけの能力そう居ないだろうし名も知れてそうだし直接スカウトしてそうな 23. 名無しのPCパーツ 2024年06月22日 16:20 ID:tZvUvYn10 今や世界のトップ企業だから、こういう条件でも来るんでしょ。 頑張って株価を上げてね♪ 24. 名無しのPCパーツ 2024年06月22日 16:34 ID:0C8..xZG0 日本企業「即戦力(手取13万円ボーナスなし)」 25. 名無しのPCパーツ 2024年06月22日 17:00 ID:vWLljAXF0 時価総額世界一の企業だもの そりゃ社員もトップクラスが要求されて当然 26. 名無しのPCパーツ 2024年06月22日 17:08 ID:KTBucqZ40 >>13 何の募集かもわかっていない奴らがやいやい言うのは笑えるよな 書いてないのに筆頭著者のみに決まっているとか言い出すし 日本だと企業の研究職じゃないと無理な条件 27. 名無しのPCパーツ 2024年06月22日 18:00 ID:.P55ZdIw0 これを15歳くらいでクリアする層が300万人いるからな 十分ゆるい募集 28. 名無しのPCパーツ 2024年06月22日 18:05 ID:5o9o8XZM0 日本のZ世代じゃ無理やな 29. 名無しのPCパーツ 2024年06月22日 18:10 ID:qio4RLiu0 >>6 いわゆる日本で言う一般エンジニアってのがそもそもいないよ エンジニアはエンジニア学位持ちから 30. 名無しのPCパーツ 2024年06月22日 18:14 ID:446bKeTE0 論文8本って子供の日記じゃないんだから無理やろ 31. 名無しのPCパーツ 2024年06月22日 18:37 ID:JPpFiOkO0 中国猿 韓国猿 じゃ無理でしょうね 32. 名無しのPCパーツ 2024年06月22日 18:46 ID:cbji92Q90 世界トップ企業だからこその条件だな 33. 名無しのPCパーツ 2024年06月22日 19:04 ID:KLNO5wlb0 ストックオプション$7Mの会社 34. 名無しのPCパーツ 2024年06月22日 19:47 ID:jEG1NAt30 「優秀な人は海外流出してる!」とか言うけど、NVIDIAに日本人は何人いるんだろうね 35. 名無しのPCパーツ 2024年06月22日 19:49 ID:jEG1NAt30 >>34 日本法人は抜きね、優秀じゃなくても現地の人を雇うに決まってるから 36. 名無しのPCパーツ 2024年06月22日 20:11 ID:SF2Zn5CT0 日本の大学と海外の大学は全然違うから新卒の意味合いも全然違うわな 社会人経験者が学び直しで在籍してたりとかも普通にあるし 37. 名無しのPCパーツ 2024年06月22日 22:23 ID:qXAyKf.30 nvidia求人サイトによると同等の研究ポジションの給与が150k~260k 要件全部満たしたら260kって感じだな 別に要件全部満たさなくても採用されることはあるだろうけど、給与は範囲内の下の方になる 38. 名無しのPCパーツ 2024年06月23日 00:35 ID:AdDQTQq90 国際会議は発表でいいから、日本の工学で学位持ちなら、取得後5年くらいで、条件はクリアできる。 39. 名無しのPCパーツ 2024年06月23日 00:38 ID:AdDQTQq90 >米26 発表て書いてあるんだから、筆頭に決まってるやろ 40. 名無しのPCパーツ 2024年06月23日 02:17 ID:5Y4jljy50 この条件を満たす人間が世界に何人いるんだ? 41. 名無しのPCパーツ 2024年06月23日 03:44 ID:13r7ciCD0 >>21 ただし出資した人のみだ そして株価が下がれば損失を受けてもらう 42. 名無しのPCパーツ 2024年06月23日 07:12 ID:T0RsENiY0 正直条件はとりあえず話を聞こうかって最低限であって 求められてるのはその後発明レベルの新技術を作る事 入ったところで作れませんでしたって奴はいらない 43. 名無しのPCパーツ 2024年06月23日 08:47 ID:Y0TkW8E10 東大卒なら大丈夫でしょ。日本最高の大学だから。 44. 名無しのPCパーツ 2024年06月23日 09:29 ID:YqzlERa10 >>43 「ブラジル最高の大学」「マルタ共和国最高の大学」で本当に大丈夫か? 「日本最高の大学」もNVIDIAから見たら同じこと 45. 名無しのPCパーツ 2024年06月23日 11:19 ID:hd0pf7d.0 適当に潜り込んでリファーラルで入ったほうが正面突破より早いよ。 不義理なことしてなければ直接かLinkedin経由でどこかしらから声かかるし。 46. 名無しのPCパーツ 2024年06月23日 11:21 ID:XB..z9.y0 学卒程度の無能なヒヨッ子は要らない 新人で見つからなければ人件費は上がるが経験有りの転職組でまかなうだけ 47. 名無しのPCパーツ 2024年06月23日 12:35 ID:BqbO5NBj0 このままでは国立大学の研究者がみんなNVIDIAに行ってしまう 48. 名無しのPCパーツ 2024年06月23日 12:52 ID:RVNTU2h00 世界で条件を満たした優秀な人しか雇わないと言うことでしょ 最初から厳しい条件を出していれば無駄な応募者は来ないから面接は楽と言う事 49. 名無しのPCパーツ 2024年06月23日 15:43 ID:TCxAgAPk0 >>43 学歴だけのヤツに価値はない 50. 名無しのPCパーツ 2024年06月23日 18:14 ID:.eg3syw.0 私も含めて、まわりの人たちも満たしているけど、NVIDIAに転職する人ほとんどおらんなあ。なんでやろ 51. 名無しのPCパーツ 2024年06月23日 18:17 ID:YqzlERa10 >>50 著名な国際会議で最低8本の論文を発表している人が周りにいっぱいいるのか? 著名な国際会議だぞ?人工知能学会とかじゃないぞ? 52. 名無しのPCパーツ 2024年06月23日 18:34 ID:pQqnR5E90 実技試験ないんだから楽だろ 53. 名無しのPCパーツ 2024年06月23日 20:41 ID:jrOq10.k0 どうせトンチだろ 10人くらいは水原一平みたいなのもいると思うわ 54. 名無しのPCパーツ 2024年06月24日 00:56 ID:ZaCQQyQr0 むしろ英才教育なんぞでは無理だと思うけどな 元々人と違った才能がないと 』 -
NVIDIA時価総額、世界首位526兆円 GAFAから主役交代
https://www.nikkei.com/article/DGXZQOGN060J20W4A600C2000000/『2024年6月19日 2:32 (2024年6月19日 5:50更新)
【シリコンバレー=渡辺直樹】米半導体エヌビディアの時価総額が18日、米マイクロソフトを抜いて世界首位となった。生成AI(人工知能)の登場により、スマートフォンの革新を主導したアップルやグーグルなどの米巨大企業から、株式市場の盟主の座はAI時代の新たな基盤企業へと移る。
エヌビディアの株価は18日、前日終値と比べて3.5%上昇した。QUICK・ファクトセットによると時価総額は約3兆3350億ドル(…
この記事は会員限定です。登録すると続きをお読みいただけます。』
-
[GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
https://www.4gamer.net/games/033/G003329/20240320003/









『米国時間2024年3月18日に行われたGDC 2024の技術セッション「Advanced Graphics Summit: GPU Work Graphs: Welcome to the Future of GPU Programming」において,AMDとMicrosoftは共同で,DirectX 12の新機能「Work Graph」を発表した(関連リンク)。本稿では,Work Graphとは何で,どのような利点をもたらすのかを解説したい。
セッションを担当したMicrosoftのShawn Hargreaves氏(Dev Manager, Direct 3D)と,AMDのMatthaus Chajdas氏(Fellow) 画像集 No.003のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用 画像集 No.004のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
1年以上前から標準化を進めていたAMD
話は約1年ほど前にさかのぼる。筆者は,AMDのDavid Wang氏(Senior Vice President,Engineering,Radeon Technologies Group)と,Rick Bergman氏(Executive Vice President,Computing and Graphics Business Group)にインタビューする機会があり,その中で「今後,グラフィックス業界で,新たに起きそうな標準化すべき3Dグラフィックスパラダイムは何でしょうか」という漠然とした質問をしたことがあった。それに対してWang氏は,以下のように答えている。
CPUの助けを借りずに,GPUだけでグラフィックス処理タスクを生成して,それをGPU自身で消費するGPU自己完結型の描画パイプライン駆動技術だ。
そのうえで同氏は,「これについてAMDは,とあるパートナーと共同で標準化を始めている」と付け加えていた。
このときにWang氏がほのめかしたGPU自己完結型の描画パイプラインが,まさにWork Graphである。含みを持たせて「とあるパートナー」と表現した相手は,Microsoftだったわけだ。AMDが推す「Primitive Shader」と,NVIDIAが推す「Mesh Shader」の次世代ジオメトリパイプラインの標準化戦争では,AMDが敗退した。しかし,新世代のGPU自己完結型パイプラインについては,AMD提唱の仕様が標準仕様として採用されたわけだ。
とはいえNVIDIAも,Work Graphについては「賛同の意」を示しており,今回の発表に合わせて,NVIDIA製GPUも即座に対応していくと明言している(関連リンク)Work Graphとは何か?
さて,今回の本題であるWork Graphという用語が,ピンと来ない人もいることだろう。
ここでいう「Graph」とは,「グラフ構造」を意味している。マスで表される「ノード」と「ノード」を連結させたフローチャートのようなネットワーク構造では,あるノードの処理系で特定の条件が成立すると,成立条件ごとにそれぞれ別の接続先ノードに処理系が移る。処理が移るときは,上流のノードが出力したデータが,下流のノードに入力されていく。
Work Graphにおけるノードとは,GPUのタスクを表す。それは処理系の実行命令(dispatch)に相当するコマンドであったり,単一スレッドで動作するシェーダプログラムであったり,あるいは同一のシェーダを並列で動かすグループスレッドのような場合もある。
Work Graphのメリットは,これまではGPUが処理するときに,オーケストラにおける指揮者のような役割をしていたCPUの関与が,ほとんど不要になること。GPU自身が,自発的に各処理系の実行を進められるのだ。具体的にいえば,GPUが実行すべき仕事を,CPUからPCI Expressインタフェースを通じて細々と描画コマンドとして送らずとも,あらかじめ構築しておいたWork Graphに従ってGPUが自発動作できる,と言ったイメージだ。もちろん,ゲームの進行によっては,まったく別のWork Graphが起動する場合もありうるので「ゲームグラフィックス処理において,CPUが不要になる」わけではない。
左は,CPUが定期的に介入する既存のGPU駆動方式で,右がWork GraphによってGPUが自発的に処理を駆動していく方式のイメージ 画像集 No.005のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
たとえば,「GPUの性能は高いが,CPU性能が相対的に低い」システムにおいて,GPUでの処理が終わっているのに,CPUによる「GPUが次にすべき仕事の準備」に時間がかかり,ゲームのフレームレートが思ったほど上がらないケースはよくある。Work Graphを活用すると,そういった現象をある程度は軽減できるようになるかもしれない。
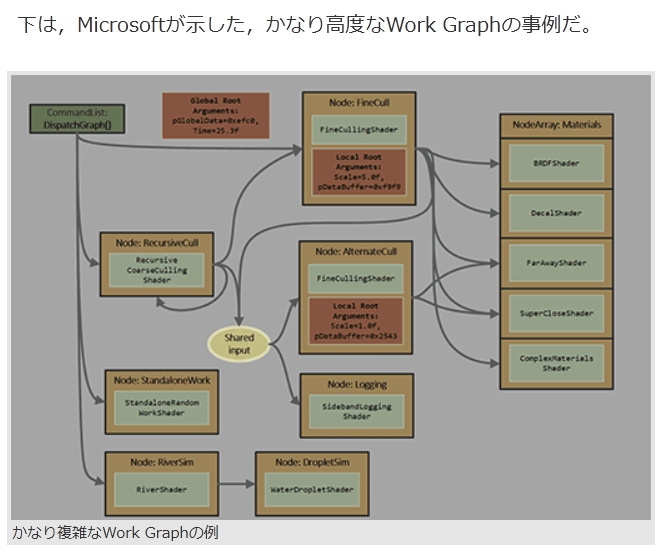
下は,Microsoftが示した,かなり高度なWork Graphの事例だ。
かなり複雑なWork Graphの例 画像集 No.006のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
シェーダプログラムとして定義された各ノードは,CPUからの起動を待つことなく実行される。各ノードにおいて実行終了条件が成立すれば,次のノードに処理が移るようなパイプライン構造となっているわけだ。もちろん,Work Graphの最上流(左上)からは,どんどん処理対象のデータが流れてくるのだが,Work Graphを構成する各ノードは,CPUからの処理を待たずに,非同期でどんどん処理を実行できる。
これは,あくまでも「例のための例」といった図であるが,Work Graphの特性をうまく説明している点はある。それは,中央やや左にある「Node:RecursiveCull」だ。
これは,左上から入力されたピクセルスレッドを,本当に描画すべきか,それとも破棄すべきか(Culling)を粗く判定する再帰構造になっている。ここで「描画すべき」と判定されたとしても,判定結果のレベルに応じて,判定詳細度の違う2つの「詳細破棄判定」(FineCullingShader)ノードに接続しているわけだ。GPUが苦手とする,動的な分岐処理系も,Work Graphを活用すれば,パフォーマンスが劇的に改善するケースもあるかもしれない。
Work Graphにおける3種類のノード
セッションでは,Work Graphで利用できる,「代表的な3種類のノード」についての解説が行われた。
●Broadcasting Launchノード
固定サイズのスレッドグループによって起動(Launch)されるもので,イメージ的には,一般的なCompute Shaderスレッドに近いノード。BroadcastingLaunchノードのイメージ 画像集 No.007のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
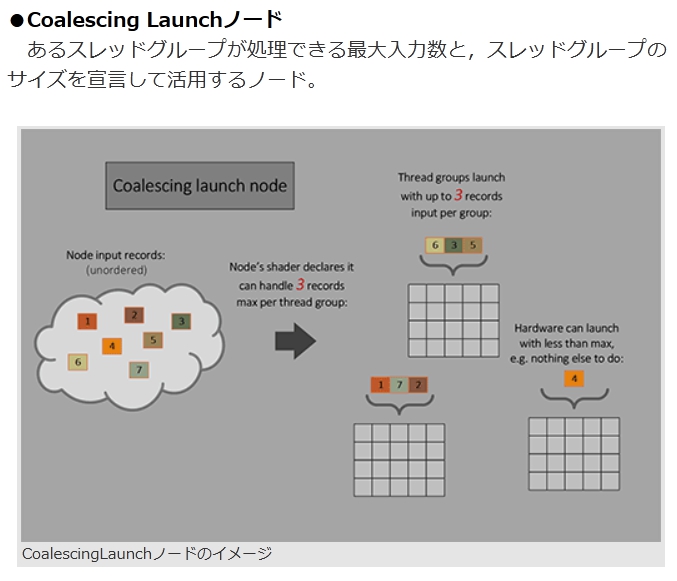
●Coalescing Launchノード
あるスレッドグループが処理できる最大入力数と,スレッドグループのサイズを宣言して活用するノード。CoalescingLaunchノードのイメージ 画像集 No.008のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
入力されたデータスレッドが,宣言された最大数を満たすと起動するが,最大数に満たない場合でも起動できる。入力された複数のデータスレッド同士に関連性がある。たとえば,互いに参照し合うことを想定した共有データがある場合に適したノードだ。
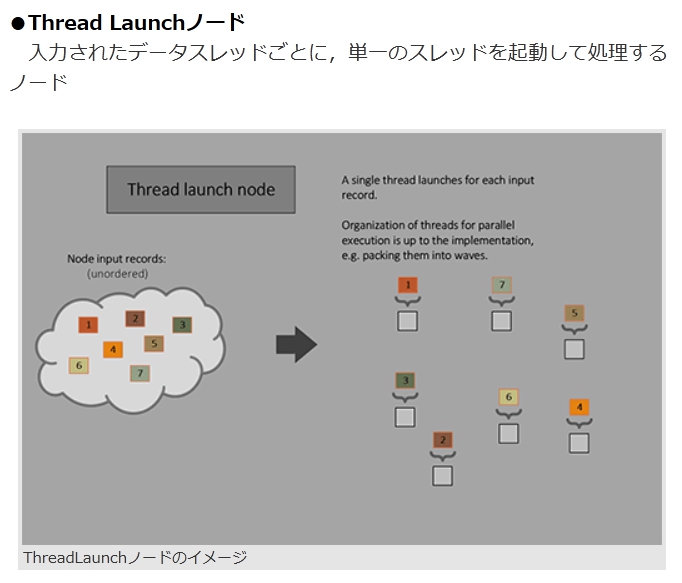
ただし,関連性がない場合は,次のノードを使うべきであるとのこと。●Thread Launchノード
入力されたデータスレッドごとに,単一のスレッドを起動して処理するノードThreadLaunchノードのイメージ 画像集 No.009のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
Work Graphで一体何ができるの?
「Work Graphを活用すれば,GPU性能の最適化につながりそう」というのが,ここまで読んでの第一印象だと思う。しかしMicrosoftとしては,これまでのGPUプログラミングでは実装できなかった(≒実装しても実用にならなかった)新しいグラフィックスアルゴリズムの開発に活用してほしい,というのが本音のようだ。
その一例として,今回のセッション内でAMDが公開したWork Graphサンプルが,以下の動画にある「Procedural Enrichment」である。
GDC 2024: Advanced Graphics Summit 「Work Graph Sample」:Procedural Enrichment
Clik to Play
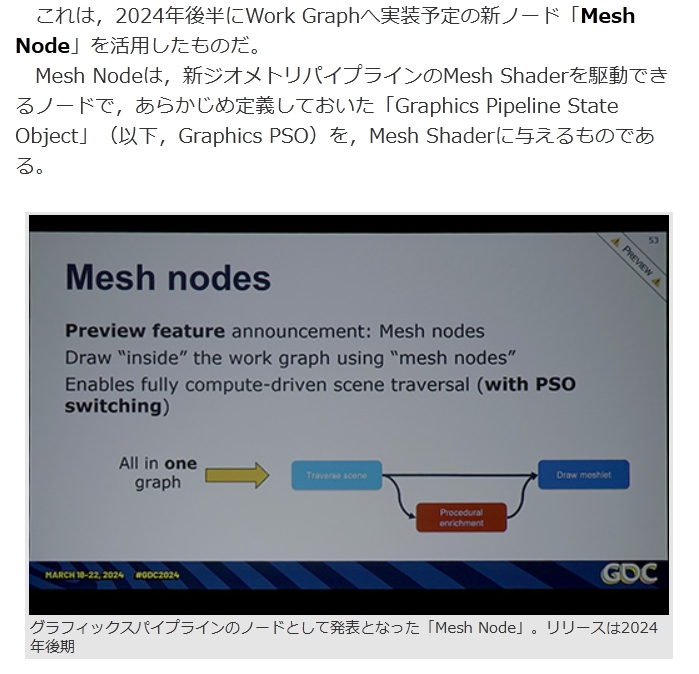
Clik to Playこれは,2024年後半にWork Graphへ実装予定の新ノード「Mesh Node」を活用したものだ。
Mesh Nodeは,新ジオメトリパイプラインのMesh Shaderを駆動できるノードで,あらかじめ定義しておいた「Graphics Pipeline State Object」(以下,Graphics PSO)を,Mesh Shaderに与えるものである。グラフィックスパイプラインのノードとして発表となった「Mesh Node」。リリースは2024年後期 画像集 No.010のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
Graphics PSOとは,DirectX 12から導入された概念で,描画したいキャラクタなどの描画プロセスの最初から最後までを,「オブジェクト」として定義したものだ。
簡単に言うと,Mesh Nodeでは,Mesh Shaderにキャラクターや小道具,大道具といった3DモデルのGraphics PSOを描画させるために入力できるノードである。極端なことをいえば,DirectX 12ベースのゲーム画面は,無数のGraphics PSOを,実際に描画したものとも言える。ようするに,Graphics PSOをMesh Shaderに入力できるノードである 画像集 No.011のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
動画のデモでは,メインのWork Graphに地形の情報を入れてやると,その土地の大きさや傾き(高低差),障害物の配置などを考慮して,Work Graphが自動的に建物の区画を決定している。さらに,区画に合わせて道のレイアウトや植生も,Work Graphが自動で決めていく。そのうえで,区画の種類に対応した3DモデルのGraphics PSOを,Mesh Nodeにて描画する流れを動画では示している。いわゆる,プロシージャルなゲームシーン構築と描画を,Work Graphで実現しているのだ。
メインのWork Graph 画像集 No.012のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
興味深いのは,メインとなるCompute ShaderベースのGraph Nodeから,グラフィックスパイプラインのMesh Nodeを呼び出せているところだろう。このデモは「デモのためのデモ」といった感じだが,ここまで高度なことが,GPUの自律描画でできるのは衝撃である。
上の動画でも説明されているが,このデモのメインWork Graphでは,植物を描画するときに「日向(ひなた)には草木が生える」「日陰にはキノコが生える」植生となるように作られている。花は,日向に一定確率で置かれて,花の近くには,一定確率で蜂が生成される。また日向の草木の近くには,これまた一定確率で蝶を生成されるという仕組みになっているようだ。
草木生成,昆虫生成のWork Graph 画像集 No.013のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
セッションの最後には,「Unreal Engine 5」の無段階LODシステムを実装した地形描画エンジンである「Nanite」を,Work Graph(※おそらくMesh Nodeも活用)で実装したデモも披露された。ただ,あくまでも実験的に実装したもので,UE5がWork Graphに対応したわけではない点に注意したい。
UE5のNaniteシステムをWork Graphで実装したデモ 画像集 No.014のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用
画像集 No.015のサムネイル画像 / [GDC 2024]CPUを使わずにGPUが自発的に描画するパイプライン「Work Graph」がDirectX 12に正式採用ただ,移植にはわずか一週間ほどしかかからなかったとのことなので,Work Graphが正式リリースされた暁には,UE5に正式採用されてもおかしくはない。
そのほかにもAMDは,Work Graphで実装したラスタライズ処理系のサンプルを公開しているので,興味のある人は参照してほしい。Work GraphはGeForceでもRadeonでも使える
Work Graphは,DirectX 12のβ版的な位置づけである「DirectX Agility SDK」から利用できるそうだ(関連リンク)。
Work Graphを活用するには,プログラマブルシェーダのバージョンとしては,「Shader Model 6.8」以上が必須となる。対応GPUは,AMDではRadeon RX 7000シリーズ,NVIDIAでは,GeForce RTX 40/30シリーズがあげられている。
Intel Arcシリーズは,現時点では対応していないものの,対応へ舵を切るとのこと。また,Qualcommも同様の表明をしているので,今後のメインストリーム技術になっていく可能性は高そうだ。
なお,現行のGPUでWork Graphをハードウェアレベルで動かせるのは,Compute Shaderのみだ。頂点シェーダやメッシュシェーダに代表されるジオメトリ系のプログラマブルシェーダや,プログラブルピクセルシェーダ,レイトレーシング関連は,今のところハードウェア対応していないが,今後,対応を拡大していく予定とのこと。まだ,いろいろな意味で「早期フェーズ」と言うことなのだろう。
一方で,Work GraphをPlayStation 5やXbox Series X|Sといったゲーム機のGPUで利用できるかは不明だ。現状,AMDは「Work Graphは,Radeon RX 7000系(RDNA3ベース)のGPUからの対応」としているので,RDNA2系のGPUを搭載するPS5やXbox Series X|Sでは対応できない可能性がある。
この業界には,「ゲーム機とゲームPCの両方に対応できていない新技術は,どんなに素晴らしくても積極的に活用されにくい」というジンクスがあるので,はたしてどうなるだろうか……。 』
-
【図解】なぜGPUはディープラーニング・AI開発に向いているの?選び方は?NVIDIAさんに聞いてきました
https://www.kagoya.jp/howto/engineer/hpc/gpu_deeplearning_ai/※ 何で、AIにはCPUよりもGPUのほうが、「向いている」のかの、分かりやすい解説記事だと思うので、紹介する。
※ GPUは、本来、「三次元グラフィックス」表示に特化した「デバイス」だった。
※ 『たとえば、先ほど話に出たバーチャファイターという格闘ゲームですが、あれはポリゴンと呼ばれる小さな三角形の組み合わせによって、キャラクターや格闘するステージ、背景などを構成します。そうしてその三角形というのは全て座標の集合からできているんです。言い換えると、要は膨大な数値の羅列なんです。
3Dの世界は、X座標・Y座標、くわえて奥行を表すZ座標による何百万個もの数字の集合からできています。その上で、キャラクターが動きますよね。三次元のオブジェクトが複雑にかたちをかえて動くのですが、このとき、ある座標をこっちに動かすであるとか、座標の変換・回転という処理をたくさんしなければなりません。
―その処理を行っているのがGPUの計算能力ということですね。
佐々木様:
その通りです。最終的には、わたしたちにきれいなグラフィックスとして見えている内容も、コンピューターの中では全て数字の塊として処理されています。』『―PCの中の頭脳というとCPUがありますが、画像の描写にCPUではなくGPUが使われるのはなぜでしょうか。
佐々木様:
簡単に言うと、CPUと同じ方法で画像の描写をしていたらCPUより早くなることはないので、GPUは画像の描写に特化したんです。具体的に言うと、グラフィックスを構成している何十万・何百万という座標の計算では、全て座標に対して同じ数をかけているんですね。やらなければならない計算量は膨大でも、同じような種類の計算を同時に行っているのです。
そこでGPUでは、スレッドと呼ばれる処理単位をたくさん並べて並列的に処理するようにしています。極端に言うとCPUでは1つずつ処理しているところをGPUではたくさんの計算を同時にできる。たとえばTesla P100というGPUには3,584機の演算器が搭載されていますが、つまり3,584個の計算をいっぺんにできるということです。』…。
※ つまり、GPUの「演算器」は、単純計算しかできないが、CPUに比べて「途方もなく多いもの」が備えられていて、それらが一斉に「並列処理」できるように作られている。
※ そして、『GPUの性能が向上するにつれ、グラフィックス描写のために培ってきた高い計算能力が、気象や地震のシミュレーションのような数値計算に役立つのではないかといったことに科学者の方々が気付いたんですね。』、ということになった。※ 世の中に、こういう「行列演算」が功を奏する分野は、あまたある…。
※ 2021年にノーベル物理学賞を受賞した、真鍋叔郎さんの業績もその一つだ…。
※ AIにおける「演算」も、そういうものの一つに過ぎない…。



※ AI関係の説明でよく出てくる図だ…。
※ 要素を抽出して、次の「層」に変形した「行列データ」を送って行くんだが、その「行列データの変形」に、途方もない量の「行列演算」を必要とする…。
※ そして、最後は、「確率」に落とし込む…。
※ その「確率」を高めるために、様々な「アルゴリズム」を駆使して、プログラムに従って、その「確率」を高めるための「試行」を、くり返し行っていく…。
※ そういう「演算処理」を実行していくには、CPUよりもGPUの方が向いている…。そういうことだ。




『公開 2018/05/29 更新 2023/07/18
AIの需要が劇的に増えている昨今、ディープラーニングで膨大な量の計算処理を必要とするシーンが増えています。そんな中、ディープラーニング用にGPUが注目される理由やGPUの選び方について、GPUの世界的リーディングカンパニーNVIDIA(エヌビディア)社の佐々木 邦暢氏に伺いました。
NVIDIA社名ロゴの前に立つ佐々木様と当社森
目次 [非表示]
GPUの成長とNVIDIA社の歴史 なぜディープラーニング・AI開発でGPUが選ばれるのか AI開発環境の作り方、GPUの選び方 カゴヤ「Tesla GPUサーバー」の魅力
GPUの成長とNVIDIA社の歴史
カゴヤ・ジャパン株式会社 森:
まずは佐々木様が御社で担当されている業務内容をお聞かせ下さい。佐々木様:
わたしはエンタープライズマーケティングという部門に所属しておりまして、その中でもハイパフォーマンスコンピューティングという分野や、AIを支えるディープラーニングの分野のマーケティングを担当しています。またDeep Learning Instituteというハンズオントレーニングのイベントの企画・運営に携わっております。手振りを使って説明される佐々木様
―ありがとうございます。
今回お話しいただくディープラーニングに関するマーケティングを担当されているのですね。次に御社の歴史や、御社のGPUがAI分野で活用されるようになった背景について教えていただけますか?佐々木様:
NVIDIAは、AIの分野においてディープラーニング関連で最近注目いただいておりますが、創業は古くて1993年です。当時はGPUコンピューティングという言葉はまだなく、NVIDIAはグラフィックアクセラレータを作る会社として始まっています。
そして今に至る過程でいくつか象徴的な出来事があります。その1つが1995年に当時人気のあったアーケードゲーム「バーチャファイター」を、弊社のNV1というグラフィックアクセラレータで動くようにPC版に移植いただいたことがあげられますね。―なつかしいですね。わたしもそのゲームを持っていました。
佐々木様:
それからマイクロソフトのDirectXというグラフィックのAPIが発表されたのが1996年。このあたりからグラフィックアクセラレータの重要性も高まってきました。そして、1999年にNVIDIAは「GeForce 256」を発表、この時GPUを「1000 万ポリゴン/秒以上を処理できる、変換、ライティング、トライアングルセットアップおよびクリッピング、レンダリングなどの各エンジンを 1 枚のチップに統合したシングルチッププロセッサ」と定義しました。GeForce 256 は1500万ポリゴン/秒の処理能力を持っていました。
―GPUコンピューティングの歴史もそこから始まるんですね。
GPUコンピューティングの歴史
佐々木様:
はい、そうです。
GPUの性能が向上するにつれ、グラフィックス描写のために培ってきた高い計算能力が、気象や地震のシミュレーションのような数値計算に役立つのではないかといったことに科学者の方々が気付いたんですね。その結果として実現したのが2006年のCUDA (Compute Unified Device Architecture/クーダ)の発表です。―CUDAとはどういったものですか?
佐々木様:
簡単に言うと、GPUが絵を描くために培ってきた計算能力を、汎用的な用途に拡張するためのプログラムを書くのに使う、エンジニア向けの枠組みです。CUDAによって、プログラマーの方々が慣れ親しんだC言語というプログラミング言語を拡張するようなかたちで、GPUの計算能力を存分に活かすことができるようになりました。―なるほど、CUDAをきっかけにして、GPUコンピューティングが隆盛していくのですね。
佐々木様:
はい。2008年には東京工業大学の『TSUBAME 1.2』が世界初のGPUスーパーコンピューターとしてTop500というスパコン番付に載り、2012年には18,688基のGPUを搭載するオークリッジ国立研究所のスーパーコンピューター『Titan』が世界で一番計算の早いスパコンになりました。―はじめはAI分野以外のところで、GPUが注目されたんですね。
佐々木様:
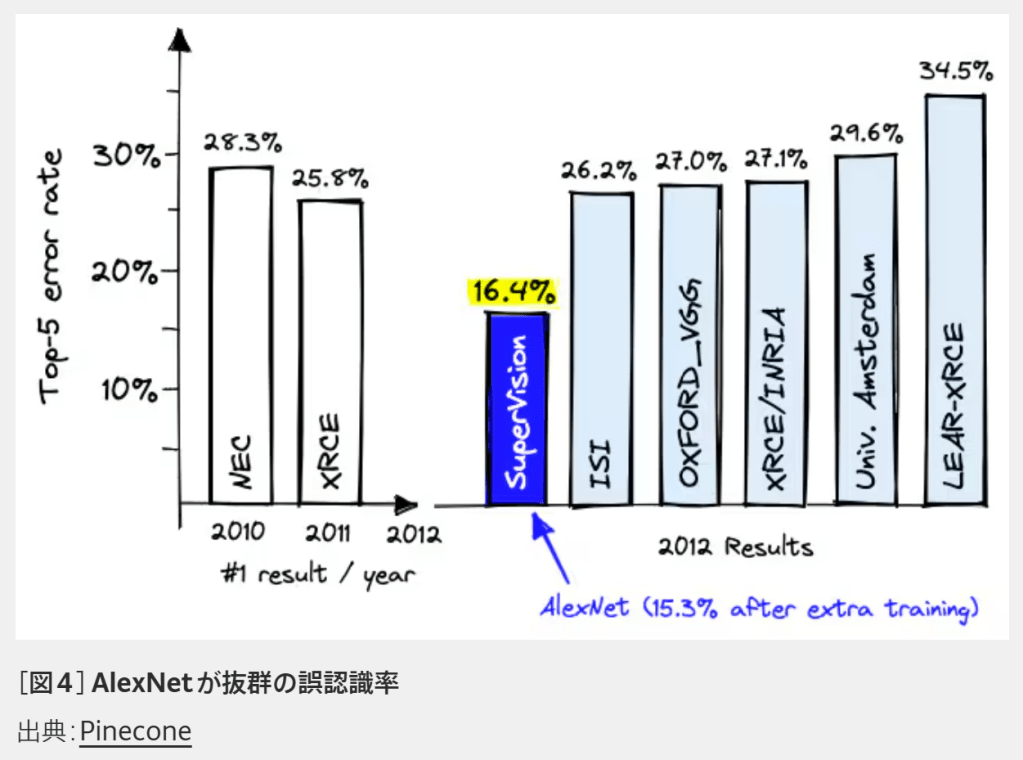
そうですね。その後にAIの基本となる機械学習やニューラルネットワークを研究していた科学者もGPUを活用し始めます。そして2012年に、GPUでトレーニングされたAlexNetというディープニューラルネットワークが、画像認識のコンテストで圧勝しました。これが、ディープラーニングが爆発的なブームとなる第一歩です。―GPUを使ったディープラーニングで、具体的に画像認識はどのくらい進化したのでしょうか。
佐々木様:
ディープラーニング以前の画像認識では、たとえば101種類の対象にたいして6割ぐらいの正解率だったんですね。当時は、「AIが人間並みの正解率は難しいね」と言われており、2010年~2011年にも2パーセントぐらいしか正解率が上がらなかったのに、その翌年にディープラーニングを適用した途端約10%もはねあがり正解率が8割を超えました。これが画像認識のブレークスルーだったといわれています。
ディープラーニングの精度グラフ
なぜディープラーニング・AI開発でGPUが選ばれるのか
ここまでは、AI/ディープラーニングの分野でGPUが選ばれた歴史について教えていただきました。それを踏まえ、ここからはディープラーニングやAI開発において、なぜGPUが採用されるのか理由をくわしく伺います。
―GPUがディープラーニングやAIの開発に使われるようになった背景については理解できました。それではなぜ、GPUの計算能力がディープラーニングに適しているのか、教えていただけますか。
佐々木様:
そもそも、GPUが培ってきたグラフィックスの描写能力とは、数値を計算する能力なんです。たとえば、先ほど話に出たバーチャファイターという格闘ゲームですが、あれはポリゴンと呼ばれる小さな三角形の組み合わせによって、キャラクターや格闘するステージ、背景などを構成します。そうしてその三角形というのは全て座標の集合からできているんです。言い換えると、要は膨大な数値の羅列なんです。
3Dの世界は、X座標・Y座標、くわえて奥行を表すZ座標による何百万個もの数字の集合からできています。その上で、キャラクターが動きますよね。三次元のオブジェクトが複雑にかたちをかえて動くのですが、このとき、ある座標をこっちに動かすであるとか、座標の変換・回転という処理をたくさんしなければなりません。
―その処理を行っているのがGPUの計算能力ということですね。
佐々木様:
その通りです。最終的には、わたしたちにきれいなグラフィックスとして見えている内容も、コンピューターの中では全て数字の塊として処理されています。そのようにずらっと並んだ数字のことを行列と呼ぶのですが、行列をかけたり足したりといった演算をひたすら繰り返すことでグラフィックスを成立させているのです。
くわえて、3次元の座標の中で計算しても、実際に描写が行なわれるディスプレイは平面ですよね。御存じのようにディスプレイはピクセル(画素)という単位によってできており、たとえばフルHDで200万画素ほどあります。その膨大な画素の1つ1つに対して、何色で点灯させるかというのも全て計算によって決めなければなりません。
―途方もない計算量ですね。
佐々木様:
はい。さらに言うと当時のバーチャファイターであると秒間30コマくらいで動いていましたが、最近登場したVRであると秒間90コマくらいになっています。つまり数百万画素あるディスプレイの計算を毎秒90コマ書き換える、つまり1/90秒以内に全ての計算を終えてデータを転送しなければならないわけです。というわけで描写能力を磨くということは計算能力を磨くということなのです。
―PCの中の頭脳というとCPUがありますが、画像の描写にCPUではなくGPUが使われるのはなぜでしょうか。
佐々木様:
簡単に言うと、CPUと同じ方法で画像の描写をしていたらCPUより早くなることはないので、GPUは画像の描写に特化したんです。具体的に言うと、グラフィックスを構成している何十万・何百万という座標の計算では、全て座標に対して同じ数をかけているんですね。やらなければならない計算量は膨大でも、同じような種類の計算を同時に行っているのです。
そこでGPUでは、スレッドと呼ばれる処理単位をたくさん並べて並列的に処理するようにしています。極端に言うとCPUでは1つずつ処理しているところをGPUではたくさんの計算を同時にできる。たとえばTesla P100というGPUには3,584機の演算器が搭載されていますが、つまり3,584個の計算をいっぺんにできるということです。
―GPUの計算能力の概要やCPUとの違いは分かりました。それがディープラーニングに適している理由を教えていただけますか。
ディープラーニングについてご説明される佐々木様
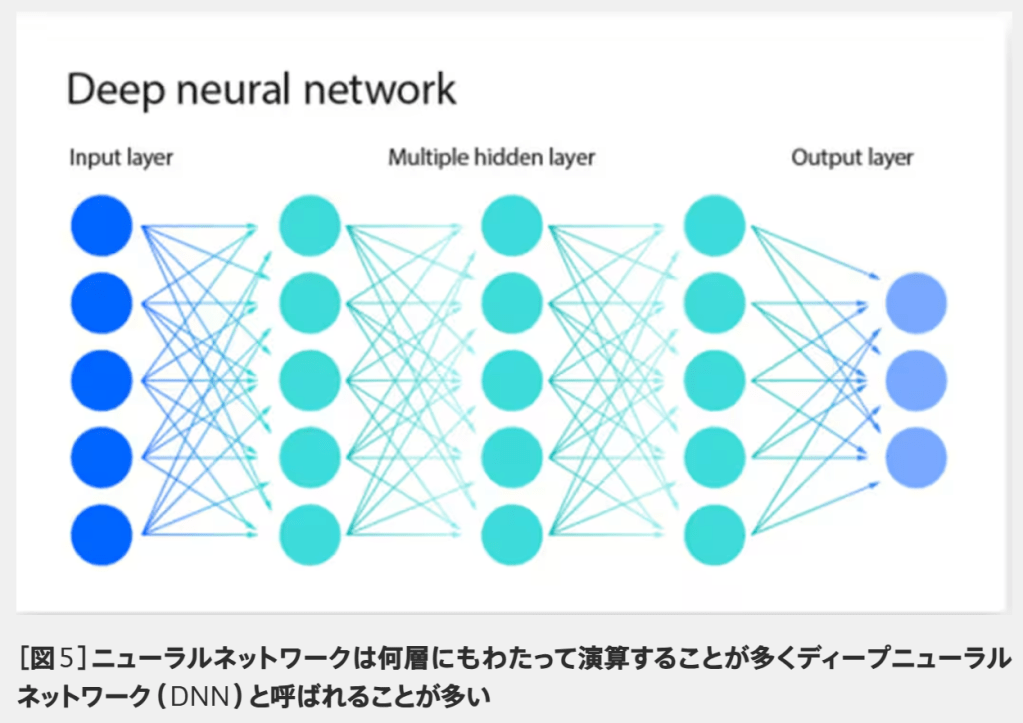
佐々木様:
はい。そのためにはまずディープラーニングの概要について理解いただく必要があります。
ディープラーニングにおいて何がディープかといえば、ニューラルネットワークという構造の階層が非常に深いという意味です。画像認識を例にとりましょう。犬の画像をニューラルネットワークに投入すると、たくさんのパラメーターをもとにそれが犬であると認識します。それができるようになるまで、たくさんの画像をニューラルネットワークへ投入し、どのパラメーターに着目すれば正解に近づくかという重みづけの調整を繰り返すのです。
最初は重みをランダムに決めたりしますので、犬を猫と判断するように、デタラメな答えがでるんですが、間違ったら「じゃあ、このあたりの重みの数字をかえてみよう」と繰り返すことで正解に近づく。
そして、このとき犬の画像自体もコンピューターの世界では数字の羅列であり、どのパラメーターに重みを置くかというのも重み行列という数値で表現しています。
このパラメーターの数はとにかく膨大です。そのため結果的に何百万・何千万という計算を繰り返すことになります。
この時行っている主な計算というのが、重みの行列に別の行列をかけて足し合わせる「行列の積和演算」という処理であり、実はこの処理が三次元のグラフィックスのポリゴンを移動させたり回転させたりするときの行列演算とそのまんま同じだったんですね。
そのため、ディープラーニングの学習については、GPUはCPUの何十倍、場合によっては何百倍もの速度で計算が完了する、GPUにむいているタスクである、というのを科学者の方々が気付いたわけです。
以前は、科学者の方々はCUDAのプログラムを自前で作成していましたが、最近では既存のフレームワークを使いディープラーニングを行っています。
そして、最近ではGoogleさんのTensorFlowや、日本だとPFNさんのChainerなどさまざまなフレームワークがありますが、そのすべてがNVIDIAのGPUに対応しています。そのくらいGPUとディープラーニングは相性が良かったんです。
ディープラーニングの仕組み
―ありがとうございます。GPUがディープラーニングで活用されている理由がよく分かりました。
次に、具体的にGPUがどんなところで利用されているか事例を教えていただけますでしょうか。ディープラーニングはもろちん、それ以外でも事例があればご紹介ください。
GPUの使用でCPUの48倍物体認識が速くなる
佐々木様:
まずディープラーニングでは、Horus Technologyさんが開発した目の不自由な方を助けられるウェラブルデバイスがおもしろいですね。このデバイスの中には、小さなGPU付きのコンピューターが搭載されていて、デバイスに付属したカメラで撮影した画像をもとにディープラーニングを行います。その上で、入力画像がGPUによって分類され、たとえば「今あなたの目の前に5人の人がいます」とか「目の前の人は怒っています」といった感情認識も行い、その結果を音声で伝えるんです。
―なるほど興味深いデバイスですね。こんなデバイスが使えれば、目の不自由な方も助かりそうですね。他にはありますか?
佐々木様:
画像分類以外ではPayPalさんが行っている決済サービスの事例があります。PayPalさんでは毎日膨大な数のお金のトランザクション処理をされていますが、その中から「この取引は怪しい、不正ではないか」と判別する必要があります。従来の手法と比較して、ディープラーニングを活用することで誤報率を半分にできたとのことです。
また、人工衛星で撮影した画像データベースをもとに、「このあたりは温暖化で砂漠化している」といった判別をディープラーニングで行っているNASAの事例、メールの添付ファイルからウイルスを検出するロジックをディープラーニングで生成しているCylance PROTECTという製品の事例などもありますね。
―いろいろなシーンでGPUのディープラーニングが使われているのですね。
佐々木様:
はい。あとは、SAPさんのBrand Impactというアプリケーションの事例も興味深いですよ。このアプリケーションでは、たとえば車のレースを映したテレビの中継映像の中で、車の車体やコースの脇に掲載された広告について、「どのメーカーの広告が何秒映ったか」というのを、画像認識により導き出し、広告の効果測定に活用しています。―ディープラーニングでそんなこともできるんですね。
佐々木様:
はい、人間の目で行うより正確かつ効率的に行えていると思います。―ディープラーニング以外で、GPUを使った事例はありますか?
佐々木様:
そうですね、これはどちらかというとGPUがもつグラフィックスの描写能力を使った事例ですが、我々が発売準備しているHolodeckというバーチャルリアリティ環境がありますね。この環境では、別々の場所にいる人がそれぞれVRゴーグルをかけ同じ仮想空間にログインします。―具体的には、その環境でどのようなことができるんですか。
Holodeckイメージ
佐々木様:
たとえば、日本・アメリカ・ヨーロッパなど別々の場所にいる車の設計士が同じ仮想空間にログインするとしますね。その上で、その仮想空間の中で、CADで使うような本物のデータを使って本物の車を再現し、それをみながら設計者同士で話し合いができるんです
仮想空間の中では、たとえば車体の色をかえたり、車のエンジンを搭載するとどう見えるかといったことを再現したりする機能もあります。これによって設計が効率化できるのです。このレベルのグラフィックスを自在に動かそうとすると本当に高い能力が必要ですが、Tesla P100クラスのGPUが4枚程度あればかなりスムーズにうごきます。最近NVIDIAは、AIやディープラーニング分野で注目されていますか、本来のグラフィックスの分野も会社の柱としてきちんと存在しているんです。
AI開発環境の作り方、GPUの選び方
GPUがAI/ディープラーニングに適している理由はわかりました。次に、開発環境や業務の本番環境で、GPUをどのようにえらべばよいか解説いただきました。
質問を交え、話を伺う森
―企業でこれからGPUを使って開発を行おうとする際に、GPUをどうやってえらべばよいか簡単に教えていただけますか?
佐々木様:
分かりました。それではNVIDIAの製品のおおまかな一覧をご覧ください。組み込み系などを除き、サーバー用・パソコン用では3種類に分かれます。GPU製品ラインナップ
まずはコンシューマー向けのGeForceという製品ラインですね。ディープラーニングを学生さんがちょっと試してみようとか開発環境で使うのであれば2万円程度のGeForceでも十分です。―そのぐらいの価格であれば、学生さんが勉強のために用意したり、企業が開発環境として使ったりする際にもハードルは低そうですね。
佐々木様:
ただし、これを業務で使うとなると話は別になってきます。業務で大量のデータを入力して何時間も学習してとか、お客様からのリクエストに応えて分類処理を行い間断なく返答を返す、24時間サービス提供するといった用途であれば、信頼性の高い環境が必要です。
そのような環境で利用されるのがTeslaという製品ラインですね。―Teslaは弊社のサービス「Tesla GPUサーバー」でも採用させていただいています。ただ、Teslaの中でもこちらのサービスで利用しているのはP40・P100という2種類のGPUです。この違いを教えていただけますでしょうか。
佐々木様:
分かりました。P40・P100はどちらも高性能なんですが、それぞれ性格が異なります。
単純に数字だけみるとP100の方が優れているようにみえるんですが、必ずしもそういうわけではなくて、性能のある部分だけみるとP40の方が優れているということもあります。―単純に数字が大きい方を使った方がよいというわけではないということですね。
佐々木様:
その通りです。簡単に言うと、P100の方が守備範囲は広いです。ディープラーニング用としての他、ハイパフォーマンスコンピューティング用にも適しています。
ハイパフォーマンスコンピューティングでは、ディープラーニングよりさらに高い精度の計算能力が求められるのですが、そのためにはP100が必要です。もう少し技術的な話をすると、64ビットの浮動小数点演算が必要な領域ではP100を使うことになります。―P40はどういったときにえらぶとよいのでしょうか。
佐々木様:
ディープラーニングに関しては、倍精度の演算性能は必須ではありません。それよりも大きなメモリがあった方が得策という面があります。GPU上のメモリは、P100よりP40の方が大きいんです。16GBのメモリを搭載するP100に対して、P40はその1.5倍の24GBのメモリを搭載しています。―ディープラーニング用途であればP40もかなり高性能ということですね。
佐々木様:
はい。そういった意味ではハイパフォーマンスコンピューティングでもなんでもできる万能選手がP100で、ディープラーニングに特化した専門家がP40という風に選び分けていただくのがよいですね。―3つの製品ラインのうち、残りのQuadroはどういったシーンに使うとよいのでしょうか。
佐々木様:
Quadroはワークステーション向けですね。たとえば自動車の会社でCADのエンジニアの方が、自分の机のワークステーションに搭載して利用するといったかたちです。
あとは開発環境でGeForceを使い、本番環境でTeslaを使う、そういった使い分けが一番わかりやすいのではないでしょうか。カゴヤ「Tesla GPUサーバー」の魅力
カゴヤでは2017年11月から、お話しにもでた「Tesla P100」「Tesla P40」を搭載したベアメタルサーバー「Tesla GPUサーバー」を、時間単位でもご利用いただけるサービスを提供開始いたしました。Tesla GPUサーバーでは、ディープラーニングやVDIに最適なサーバーインフラを、1時間370円~という業界最安級価格でご利用いただけます。ここでは、NVIDIA様からみたTesla GPU サーバーサービスの魅力について語っていただいています。
―Teslaの製造元であるNVIDIAさんは、弊社のサービス「Tesla GPUサーバー」をどのように評価いただいているでしょうか。
佐々木様:
われわれからすると、Teslaの中でもPascalという新しい世代のGPUを2種類採用して下さっていて、それが日本国内で利用できるというのがありがたいですね。われわれはディープラーニングを行うためのソフトウェアの詰め合わせ「NVIDIA GPU CLOUD」略して「NGC」という仕組みを作っています。
これを使うとすごく簡単にディープラーニングが始められるんですが、対応しているのがPascal世代以降のGPUなんですね。
またNGCでは、毎月NVIDIAがソフトウェアの詰め合わせを更新しているので、あとはもうNGCのコンテナをもってくるだけで常に最新の安定した環境をご利用いただけるので、ディープラーニングの環境構築に苦労がなくなります。
そもそもクラウドのサービスを使えばサーバーのセットアップなどによるエンジニアの工数が削減されますよね。
またソフトウェアの部分でもエンジニアそれぞれが好むフレームワークごとに独立した環境を用意できるので、そういった意味でもNGCに対応したPascalのGPUを使えるのは大きなポイントです。
それから、1時間単位の従量課金があってリーズナブルに使えるようにしていただいているのがありがたいですね。たとえば最低1ヵ月の利用でいくらからのようになると、ちょっと試してみたいというときに途端に敷居が高くなってしまいますが、従量課金で手軽に使っていただけるというのは弊社としてもありがたいですね。
―素晴らしい評価をしていただいてありがとうございます。最後に、NVIDIAさんの今後の展望についてお聞かせいただけますでしょうか。
佐々木様:
昨今AIがブームになっていますが、その具体的な技術要素がディープラーニングです。それを支える計算能力をGPUで提供するという路線は今後も伸ばしていきたいですね。ディープラーニングのモデルは最新の研究でどんどん精度があがりモデルも複雑になっており、たとえば「メモリがもっとあればいいね」といった要望をお客様からいただくこともあります。そういったご要望に応えるようなGPUを提供していきたいです。
あとNVIDIAではより性能の高いGPUをリリースするというだけでなく、先ほどのNVIDIA GPU CLOUDもそうなんですが、その性能を簡単に引き出すためのソフトウェアを一緒に提供していくというのもわれわれの展望としてあります。そのあたりは、たとえばカゴヤさんのGPUサーバーを利用すると、NVIDIAの環境がそろっている、といったように協力していければうれしいですね。
そして、私としては、冒頭にお伝えした通りディープラーニングのハンズオントレーニングを企画しておりますので、たとえばカゴヤさんのサーバーを使って同様のイベントをジョイントできるといいな、という希望もあります。
Teslaを持って話を伺う森
お話しいただいたように、GPUは今後もAI/ディープラーニングの分野であつい視線を集め続け、その需要は今後も増していくことでしょう。そんな中、NVIDIA様は、GPUのさらなる計算能力向上や、GPUの性能をより簡単に使いこなせる環境づくりを目指していらっしゃいます。弊社のTesla GPUサーバーもまた、手軽に使えるAI/ディープラーニング用の相棒として活用を検討いただければ幸いです。
※Tesla GPUサーバーの提供は終了しております。
HPCサービス SX-Aurora TSUBASA クラウド
NECのスーパーコンピューター「SX-Aurora TSUBASA」をクラウド環境でご利用できる業界随一のサービスです。
世界トップクラスのスペックで大規模データの高速処理を実現するベクトル型スーパーコンピューターを、月額定額料金のクラウドサービスとして利用できます。
関連記事
ChatGPTが使えない時の対処法
AI・IoT・HPC
ChatGPTが使えない?ログインや反応しない時の対処法について
m.haruyamam.haruyama
2023/12/08
AI・IoT・HPC
ChatGPTにできること一覧|プライベートからビジネス活用まで
m.haruyamam.haruyama
2023/11/22
ChatGPTでプログラミング
AI・IoT・HPC
ChatGPTでどれ位のプログラミング生成が可能?活用方法や上手く使うコツ
m.haruyamam.haruyama
2023/11/13この記事を書いたライター
小泉 健太郎小泉 健太郎
法人向けインターネットサービスプロバイダのサポートリーダーや販売推進担当を経験した後、2016年7月にライターとして独立。
IT関連をはじめ保険、旅行、グルメなど幅広い分野の記事を執筆中。▼主な記事の寄稿先
・次世代ゲームテスト研究所
https://blog.aiqveone.co.jp/
・保険の教科書
https://hoken-kyokasho.com/ 』 -
Graphics Processing Unit
https://ja.wikipedia.org/wiki/Graphics_Processing_Unit

『出典: フリー百科事典『ウィキペディア(Wikipedia)』
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “Graphics Processing Unit” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2015年12月)Graphics Processing Unit(グラフィックス プロセッシング ユニット、略してGPU)は、コンピュータゲームに代表されるリアルタイム画像処理に特化した演算装置あるいはプロセッサである。
グラフィックコントローラなどと呼ばれる、コンピュータが画面に表示する映像を描画するための処理を行うICから発展した。
特にリアルタイム3DCGなどに必要な、定形かつ大量の演算を並列にパイプライン処理するグラフィックスパイプライン性能を重視している。
現在の高機能GPUは高速のビデオメモリ(VRAM)と接続され、頂点処理およびピクセル処理などの座標変換やグラフィックス陰影計算(シェーディング)に特化したプログラム可能な演算器(プログラマブルシェーダーユニット)を多数搭載している。
プロセスルールの微細化が鈍化していることからムーアの法則は限界に達しつつあるが、設計が複雑で並列化の難しいCPUと比較して、個々の演算器の設計が単純で並列計算に特化したGPUは微細化の恩恵を得やすい。
さらにHPC分野では、CPUよりも並列演算性能にすぐれたGPUのハードウェアを、より一般的な計算に活用する「GPGPU」がさかんに行われるようになっており、そういった分野向けに映像出力端子を持たない専用製品や、深層学習ベースのAI向けに特化した演算器を搭載したハイエンド製品も現れている。
NVIDIA製のGPU – GeForce 6600 GT
歴史
「ビデオカード#ビデオカードの歴史」も参照
この節には複数の問題があります。改善やノートページでの議論にご協力ください。
出典がまったく示されていないか不十分です。内容に関する文献や情報源が必要です。(2015年12月) 独自研究が含まれているおそれがあります。(2015年12月)
1970年代〜1980年代
「グラフィックコントローラ#1970年代〜1980年代」も参照
この節には複数の問題があります。改善やノートページでの議論にご協力ください。
出典がまったく示されていないか不十分です。内容に関する文献や情報源が必要です。(2015年12月) 独自研究が含まれているおそれがあります。(2015年12月)
コンシューマPC向けGPUの起源は1970年代から1980年代のグラフィックコントローラにさかのぼる。
当時のグラフィックコントローラは、矩形や多角形の領域を単純に塗り潰したり、BitBlt(Bit Block Transfer、ビット単位でのブロック転送)などにより、2次元画像に対して簡単な描画処理を行うだけであり、その機能と能力は限定的だった。
グラフィックコントローラの中には、いくつかの命令をディスプレイリストとしてまとめて実行したり、DMA転送を用いることでメインCPUの負荷を減らしたりするものもあった。
このような専用のグラフィックコントローラを用いずに、DMAコントローラで処理したり、汎用CPUをグラフィック処理専用に割り当てたグラフィックサブシステムを充てるコンピュータも存在した。汎用的なグラフィックス・コプロセッサは古くから開発されてきたが、当時の技術的な制約から安価な製品では機能や性能に乏しく、また高機能なものは回路の規模が増大し非常に高価なものとならざるを得ず、結果的にパーソナルコンピュータへ広く採用されることはなかった。
1980年代から1990年代前半にかけてはBit Block Transferをサポートするチップと、描画を高速化するチップは別々のチップとして実装されていたが、チップ処理技術が進化するとともに安価になり、VGAカードをはじめとするグラフィックカード上に実装され、普及していった。
1987年のVGA発表とともにリリースされたIBMの8514グラフィックスシステムは、2Dの基本的な描画機能をサポートした最初のPC用グラフィックアクセラレータとなった。
AmigaはビデオハードウエアにBlitterを搭載した最初のコンシューマ向けコンピュータであった。
1980年代後半から1990年代前半の日本国内で広く普及していたPCとしてPC-9800シリーズがあるが、同シリーズのグラフィックの描画に関連するチップにはGDCと、GRCG・EGCがある(CRTCなどもあるが、描画には関係しない)。
GDCには直線・円弧・四角塗りつぶしなどの図形描画機能があり、この記事で扱っているタイプのLSIである。
GDCは登場時点では比較的高機能・高性能であったが、CPUの性能向上によりその利点は薄くなっていった(そのため、当時の開発者でもそれを正確に把握していない者も多い)。
GRCGは複数プレーンへの同時描画(98ではプレーンごとにセグメントアドレスを動かす必要があり面倒だった)や描画時のマスク操作などをハードウェアで行えるもので、EGCはGRCGの強化版(Enhanced Graphic Charger)である。EGCはEPSONが比較的後期まで追随しなかったことや、NECがハードウェアの仕様の公開に非積極的になった以降ということもあり、あまりよく知られていない。
さらに、AGDC(Advanced 〜)[1]やEEGC(あるいはE2GC)といったチップに至っては、非公開情報を集めた文献にもその名前以外には殆ど全く情報がない。
1990年代
この節には複数の問題があります。改善やノートページでの議論にご協力ください。
出典がまったく示されていないか不十分です。内容に関する文献や情報源が必要です。(2015年12月) 独自研究が含まれているおそれがあります。(2015年12月)
1990年代に入ると、シリコングラフィックス (SGI) が自社のグラフィックワークステーション用のグラフィックライブラリとして開発・実装したIRIS GL(英語版)がOpenGLに発展して標準化され、標準化されたグラフィックライブラリとそのAPIに対応したハードウェアアクセラレータ、という図式が登場する。
実装当初のIRIS GLはソフトウェアによるものであったが、SGIでは当初よりこのAPIをハードウェアによって高速処理させる (ハードウェアアクセラレーションを行う) ことを念頭に設計しており、程なくIRIS GLアクセラレータを搭載したワークステーションが登場する。
ただし、当初のIRIS GLアクセラレータはまだ単体の半導体プロセッサではなく、グラフィックサブシステムは巨大な基板であった。
1990年代の初めごろ、Microsoft Windowsの普及とともに、グラフィックアクセラレータへのニーズが高まり、WindowsのグラフィックスAPIであるGDIに対応したグラフィックアクセラレータが開発された。
1991年にS3 Graphicsが開発した”S3 86C911″は、最初のワンチップ2Dグラフィック・アクセラレータであった。
“86C911″という名は設計者がその速さを標榜するためポルシェ911にちなんで名付けた。86C911を皮切りとして数々のグラフィック・アクセラレータが発売された。
1995年には3DlabsがOpenGLアクセラレータのワンチップ化に成功し、低価格化と高パフォーマンス化が加速度的に進行し始める。
また同年に登場したインテルのPentium Proプロセッサの処理能力は同時代のRISCプロセッサの領域に差し掛かっており、このCPUとワンチップ化によって価格を下げたOpenGLアクセラレータのセットは、それまでメーカーに高収益をもたらしていたグラフィックワークステーションというカテゴリーにローエンドから価格破壊を仕掛ける原動力となった。
1995年までには、あらゆる主要なPCグラフィックチップメーカーが2Dアクセラレータを開発し、とうとう汎用グラフィックス・コプロセッサは市場から消滅した。1995年に3dfxによりVoodooという3Dアクセラレータが発売された。
家庭用PCの性能上のボトルネックを考慮してゲーム用に最適化されたGlideというAPIも用意され、家庭用PC上で当時のアーケードゲームに匹敵する品質のグラフィックを実現した。
Voodooシリーズは、1990年代後半の家庭用PCゲームの品質向上を牽引したシリーズとなった。
1995年にマイクロソフトがWindows 95とともに開発したゲーム作成及びマルチメディア再生用のAPI群DirectXではさらにグラフィック・アクセラレータの性能が強化された。
DirectXのコンポートネントのひとつDirect3Dは当初から[要出典]3Dグラフィック処理のハードウェア化を想定したレンダリング・パイプラインを持っていた。
1997年当時のグラフィック・アクセラレータはレンダリングのみしかサポートしていなかったが、この頃からZバッファ、アルファブレンディング、フォグ、ステンシルバッファ、テクスチャマッピング、テクスチャフィルタリングなどの機能を次々搭載し、3Dグラフィック表示機能を競うようになった。DVD-Video再生支援機能を備えるチップも現れた。
VDP等の汎用グラフィック・プロセッサについては、カーナビ等の表示用に使用され新たな市場を形成している。90年代後半からは、携帯電話に多色表示がもちいられるようになり、その分野においても有用な市場を形成している。
一方、システムの低価格化を目的に、チップセットのノースブリッジにグラフィックコアの統合を行った、統合チップセットが1997年ころから登場し始める。
1999年の「Intel 810」チップセットの登場で、低価格機には統合チップセットの使用が定着し始めた。
3DCGの中核とも言えるジオメトリエンジンは高コストが許容されるグラフィックワークステーションでは専用プロセッサとして搭載されていたが、PCでは長らくCPUが担う機能であった。
しかし、ジオメトリエンジンの別名とも言えるハードウェアによる座標変換・陰影計算処理(英: Hardware Transform and Lighting; ハードウェアT&L)が1999年にPC向けにリリースされたDirectX 7にて標準化され[2]、またこのハードウェアT&Lを世界で初めて実装して製品化したNVIDIA GeForce 256を定義する言葉として「GPU」という名称が提唱されることとなった。
ハードウェアT&Lの実装によって、NVIDIA社製品は他社製品と比較して突出した高性能を発揮するようになった。
これ以後、ジオメトリエンジンとしての機能をCPUに任せる3dfx Voodooシリーズは目立って高性能とは言えなくなった。
2000年代
この節には複数の問題があります。改善やノートページでの議論にご協力ください。
出典がまったく示されていないか不十分です。内容に関する文献や情報源が必要です。(2015年12月) 独自研究が含まれているおそれがあります。(2015年12月)
3次元グラフィックスのパイプライン処理
DirectX 8世代では、グラフィックスパイプライン中の一部の処理をユーザープログラマーが自由に記述できるプログラマブルシェーダーが導入されるようになった。
プログラマブルシェーダーは頂点シェーダー (Vertex Shader) とピクセルシェーダー (Pixel Shader) の2種類が用意され、頂点シェーダーは頂点座標や光源ベクトルの頂点単位での座標変換および頂点単位での陰影計算(シェーディング)を、ピクセルシェーダーはピクセル単位での陰影計算をそれぞれ担当する設計だった。
特に従来の固定機能シェーダーではポリゴン単位(頂点単位)でしか陰影計算を実行できなかったのに対し、ピクセル単位での陰影計算もできるプログラマブルピクセルシェーダーの導入により、表現の自由度と解像度(精細度・品質)が飛躍的に向上した。
ただし、シェーダープログラムの記述に使える言語は原始的なアセンブリ言語が基本であり、記述可能なプログラム長(命令数)もごく限られていたため、開発効率や再利用性などの面で課題を抱えていた。
なお、頂点シェーダープログラムとピクセルシェーダープログラムを実行するハードウェアユニット(演算器)のことを、それぞれ頂点シェーダーおよびピクセルシェーダーとも呼んでいた。
後にNVIDIAでCUDAを開発するIan Buckはこの最初の世代のプログラマブルシェーダーから既にGPGPUに着手しており、厳しい制約下ではあったもののレイトレーシングの高速化についての論文を発表している。
また、この世代になるとマルチテクスチャ、キューブマップ、アニソトロピック(異方性)フィルタ、ボリュームテクスチャなどが新たにサポートされ、HDRIによるレンダリングや動的な環境マッピングの生成が可能になった。
動画の再生や圧縮にシェーダーを使う技術も搭載された (Intel Clear Video、PureVideo、AVIVO、Chromotion)。
DirectX 9世代になると、このプログラマブルシェーダーがさらに進化し、シェーダーのプログラムを書くための専用の高級言語であるCg、HLSL、GLSLなどが開発され、シェーダーを物理演算などゲームでの3Dグラフィック表示以外の演算に使うことも多くなった。
Windows Vistaに搭載された機能のひとつ「Windows Aero」 (Desktop Window Manager) は画面表示にプログラマブルシェーダー(ピクセルシェーダー2.0)を利用するので[3]、この世代のビデオチップが必須になっている(Windows Aero Glassを使用しなければDirectX 8世代以前のビデオチップでもWindows Vista自体は稼働する)。
また、Mac OS XのCore ImageではOpenGLのプログラマブルシェーダーを利用して2Dグラフィックのフィルタ処理を行っている。
GeForce 8800の内部構造
統合シェーダーである「Streaming Processor」が128個搭載されている。これにより最大500GFLOPS超で処理する。
DirectX 10世代ではさらに自由度が増し、「シェーダーモデル4.0」 (SM 4.0) に基づくグラフィックスパイプラインが導入され、頂点シェーダーとピクセルシェーダーの間でジオメトリシェーダー (Geometry Shader) によるプリミティブ増減処理を行なえるようになった。ジオメトリシェーダーはOpenGL 3.2でも標準化されている。
グラフィックス描画処理では3次元空間を構成する表現のために三角形を色付けするピクセルシェーディング処理の負荷が、精細度や特殊処理などによって大きく変化するため、固定のハードウェアパイプライン構成ではボトルネックになることが多かった。
この制約を解消するために、DirectX 10世代では演算ユニットを汎用化する統合型シェーダーアーキテクチャ (en:unified shader architecture) によって固定のパイプラインの一部をより柔軟な構成に変更した。
頂点シェーダーとジオメトリシェーダー、そしてピクセルシェーダーの機能をあわせもつ統合型シェーダー (Unified Shader) [4]を多数搭載して動的に処理を振り分けることによってプログラムの自由度と共にボトルネックを解消し、演算回路数の増加に比例した画像描画処理速度の向上を得た[5]。
なお、この統合型シェーダーアーキテクチャによるハードウェアレベルでの汎用化が、GPUにおける汎用演算(GPGPU)の発展と普及を加速させていくことになる。
統合型シェーダーアーキテクチャを採用したNVIDIA GeForce 8シリーズではWindows / Mac OS X / Linux用の標準的な汎用Cコンパイラ環境 (CUDA) が提供され、一方ATI Radeon HD 2000シリーズではハードウェアに直接アクセスできる環境 (Close to Metal(英語版)) が、そしてRadeon HD 4000シリーズ以降ではATI Stream(Brook+言語と抽象化レイヤーであるCAL)によるアクセス手段が用意されている[6]。
これにより科学技術計算やシミュレーション、画像認識、音声認識など、GPUの演算能力を汎用的な用途へ広く利用できるようになった(GPGPU)。
また、特定のハードウェアベンダーやプラットフォームに依存しないOpenCLというヘテロジニアス計算環境向け標準規格に続き、米マイクロソフト社からDirectX 11 APIの一部としてGPGPU用APIであるDirectCompute(コンピュートシェーダー)がリリースされた(のちにDirectComputeをバックエンドとするGPGPU向けC++言語拡張・ライブラリとしてC++ AMPも登場した[7])。
DirectX 11のシェーダーモデル5.0では、前述のコンピュートシェーダーに加え、頂点シェーダーとジオメトリシェーダーの間に、ポリゴンの細分割・詳細化(サブディビジョンサーフェイス)をGPUで行なうテッセレーションシェーダー(ハルシェーダー、固定機能テッセレータ、ドメインシェーダー)が追加された[8]。テッセレーションシェーダーはOpenGL 4.0、コンピュートシェーダーはOpenGL 4.3でも標準化されている。
なお、主にDirectXに最適化されたGeForceやRadeonなど3Dゲーム向け製品と異なり、業務用ワークステーションなど高い信頼性や耐久性が必要とされる業務用途に特化して設計されたNVIDIA Quadroシリーズ、およびAMD FireProシリーズが存在する。
これら業務用製品はDirect3DよりもOpenGLおよびOpenGL対応アプリケーションに最適化されており、CAD、HPC、金融、CG映像、建築/設計、DTP、研究開発分野において採用されている。
そのほか、NVIDIA TeslaシリーズやAMD FireStreamシリーズ(のちにAMD FireProに統合)といった、GPGPU専用製品も登場している。
2010年代~2020年代
この節には独自研究が含まれているおそれがあります。問題箇所を検証し出典を追加して、記事の改善にご協力ください。議論はノートを参照してください。(2015年12月)
主なCPUメーカーは、従来のCPU機能だけにとどまらず、1つのCPUチップ内に複数のCPUコア(マルチコア)を搭載すると同時に、画像出力専用回路としてGPUコアも統合した製品を提供するようになった。
例えば、米AMDでは「AMD Fusion」構想において1つのダイ上に2つ以上のCPUとGPUを統合し[9][5]、米インテル社でもCore i5、Core i7、Core i3でのSandy Bridge世代から、同様の製品を提供している[10][11][12]。
なお、従来型のUMA、つまり単にCPUとGPUのチップを統合して物理メモリを共有するだけでは、CPUとGPUのメモリ空間が統一されることにはつながらない。
HSAにおけるhUMAなどのように、CPUとGPUのメモリ空間を統一するためにメモリ一貫性を確保する仕組みが用意されることで初めて、CPU-GPU間のメモリ転送作業が不要となる。
また、CPUとGPUの外部メモリが共用されるため、CPUチップの外部メモリバスにはCPUのアクセス帯域に加えてGPUのアクセス帯域も加わる。
このため、仮にCPUチップに極めて高い性能のGPUを統合しても、統合チップのメモリアクセス帯域も相応に増強されないと、それがボトルネックとなって性能向上は望めない。
GPU用のメモリ規格として長らくDDR系およびGDDR系が採用されてきたが、2015年6月に発売されたAMD Radeon R9 Fury Xでは、新しい規格系統のHigh Bandwidth Memory (HBM) [13]が世界で初めて採用された[14] [15] [16]。
しかし、高性能だが高価格なHBMの採用はコンシューマー用途では進まず、GDDR5の後継規格であるGDDR5XやGDDR6が採用されるようになっている。
2010年代後半にGPGPUという手法が広く普及したことで、HPC分野でもGPUを多用するようになった。
特に深層学習(ディープラーニング)ベースのAI用途にGPUの需要が高まっている。
VRAMに関しては費用対効果の面から、HPC用途ではたとえ高コストでも広帯域・大容量のHBM、ゲームなどのコンシューマー用途ではたとえ低帯域でも低コストのGDDRという棲み分けが起きている[17]。
一方グラフィックスAPIに関しては、Mantleを皮切りとして、Metal、DirectX 12およびVulkanのように、ハードウェアにより近い制御を可能とするローレベル (low-level) APIが出現することとなった。
ローレベルAPIはいずれもハードウェア抽象化レイヤーを薄くすることによるオーバーヘッドの低減や描画効率の向上を目的としており、またマルチコアCPUの活用を前提とした描画あるいは演算コマンドリストの非同期実行といった機能を備えている。
また、GPUでリアルタイムレイトレーシングを実現する動きも加速しつつある。
2009年にNVIDIA OptiX(英語版)[18][19][20]が、2011年にイマジネーションテクノロジーズ(英語版)のOpenRL(英語版)[21]が、そして2018年にマイクロソフトのDirectX Raytracing(英語版) (DXR) とAppleのMetal Ray Tracingが発表された。
NVIDIA GeForce RTXシリーズはDXRのハードウェアアクセラレーションに対応する最初のGPUである。
2020年にはインテルが同社としては1998年に発売した「Intel 740」以来、22年ぶりの単体GPUである「iris Xe Max」を発売し、更に2022年にインテルはPC向けで同社初の本格的な単体GPUである「Intel Arc」を発売した。
NVIDIAとAMDの2社がほぼ寡占しているPC向けの単体GPU市場にインテルが本格参戦する状況になった。
実態としては最上位でもミドルクラスの性能であり、Resizable BAR 非対応のマシンでのパフォーマンスの大幅低下やドライバの完成度の低さやアイドル時の電力効率の低さなどで主要2社の製品に劣るものの、既に十分使える製品となっているため、主要2社に対するカウンターとしての存在感を示すことには成功したと言える。
また、2023年8月になると人工知能のGPUに対する需要の爆発な成長が故GPUは供給不足に直面している[22]。
GPUの構造
この節の正確性に疑問が呈されています。問題箇所に信頼できる情報源を示して、記事の改善にご協力ください。議論はノートを参照してください。(2019年1月)
この節に雑多な内容が羅列されています。事項を箇条書きで列挙しただけの節は、本文として組み入れるか、または整理・除去する必要があります。(2015年12月)
ウィキペディアはオンライン百科事典であって、情報を無差別に収集する場ではありません。改善やノートページでの議論にご協力ください。(2019年4月)
DirectX 10世代以降のGPUは統合型シェーダーアーキテクチャに基づいて設計されており、Intel GMAなどの一部を除きGPGPUにも対応している。
NVIDIA Fermiアーキテクチャの例
NVIDIAのGPUは、統合型シェーダーアーキテクチャを採用したGeForce 8 (G80) シリーズ以降、Warp単位(32ハードウェアスレッド)での並列処理実行が特徴となっている[23] [24]。
NVIDIAのGT200アーキテクチャでは、単精度CUDAコア (SPCC) と倍精度ユニット (DPU) が分かれていた[25]が、Fermiでは単精度CUDAコア16個を2グループ組み合わせ、倍精度演算器16個と見立てて実行している[26]。
ホストインターフェース[27] GigaThreadスケジューラ[27] グラフィックスプロセッシングクラスタ (GPC)[28] ラスタライザ[28] ストリーミングマルチプロセッサ (SM) 命令キャッシュ (I-Cache)[27] Warpスケジューラ[27] 命令ディスパッチユニット[27] レジスタファイル[27] Uniformキャッシュ[27] ジオメトリコントローラ[29] ストリーミングマルチプロセッサコントローラ (SMC)[29] CUDAコア[27] ディスパッチポート[27] 命令コントローラ[27] 浮動小数点ユニット (FP Unit)[27] 整数ユニット (INT Unit)[27] 結果キュー[27] LOAD/STOREユニット (LD/ST)[27] 特殊関数ユニット (SFU)[27] - 超越関数の実行を行なう 共有メモリ / L1キャッシュ [30] テクスチャユニット[29] テクスチャL1キャッシュ[29] テッセレータ (PolyMorph Engine)[28] [31] 相互接続ネットワーク レンダー出力ユニット(英語版) (ROP)[29] L2キャッシュ[29] メモリコントローラ[27]AMD GCNアーキテクチャの例
AMDのGPUは、Radeon HD 2000~HD 6000シリーズにおいてVLIWを採用していたが、HD 7000シリーズ以降では、グラフィックスだけでなくGPGPUでも性能を発揮できるようにするために、非VLIWなSIMDとスカラー演算ユニットにより構成されたGraphics Core Next (GCN) アーキテクチャを採用している[32]。AMD GPUではWavefront単位(64ハードウェアスレッド)での並列処理実行が特徴となっている。
リクエスト調停[33] スカラーL1キャッシュ[33] 命令L1キャッシュ[33] コンピュートエンジン 非同期コンピュートエンジン (ACE)[34] コンピュートシェーダー (CS) パイプ[34] スケーラブルグラフィックスエンジン[34] グラフィックス (GFX) コマンドプロセッサー (GCP)[34] ワークディストリビュータ[34] コンピュートシェーダー (CS) パイプ[34] プリミティブパイプ[34] ハイオーダーサーフィス (HOS)[34] テッセレート[34] ジオメトリ[34] ピクセルパイプ[34] スキャンコンバーション[34] レンダーバックエンド (RB)[34] コンピュートユニット (CU)[33] / 統合シェーダーコア[34] 命令フェッチ (IF) 調停[33] SIMDプログラムカウンタ (PC) &命令バッファ (IB)[33] 命令調停 (Instruction Arbitration)[33] 分岐&メッセージユニット[33] 送出/グローバルデータ共有 (GDS) デコード[33] ベクターメモリデコード[33] スカラーデコード[33] スカラー演算装置 (Scalar ALU)[33] レジスタ[33] 演算装置 (ALU)[33] ベクターデコード[33] 混合精度SIMDユニット (MP SIMD Unit)[33] レジスタ[33] 混合精度ベクター演算装置 (MP Vector ALU)[33] ローカルデータ共有 (LDS) デコード[33] ローカルデータ共有メモリ[33] データL1キャッシュ[33] アドレスユニット[35] L1ベクターデータキャッシュ[35] データ返却ユニット[35] クロスバー (XBAR)[36] L2キャッシュ[33] メモリコントローラ[33]組み込みシステム
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “Graphics Processing Unit” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2017年9月)
ゲーム機この節は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “Graphics Processing Unit” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2017年9月)ゲーム業界においても、1990年代後半から3D描画能力の向上が求められ、ゲーム機(ゲームコンソール)ベンダーはGPUメーカーと共同で専用のGPUを開発するようになった。
汎用機であるパーソナル・コンピュータ(PC)用GPUより先行した新機能やeDRAMの搭載で差別化したものが多い。
また、汎用化・共通化のための分厚い抽象化層がほとんど不要な専用APIや専用マシン語が使えることもあいまって、同世代における下位や中位のPC用GPUよりも画像処理性能においては高性能である。
本節ではハードウェアT&Lあるいはそれに類する3次元コンピュータグラフィックスパイプラインを有するもののみを列挙する。
PlayStationに搭載されたGeometric Transfer Engine (GTE) SCE製。ハードウェアジオメトリエンジンをPC用GPUより4年ほど先行して搭載している。CPU内のコプロセッサとして動作する。 なおGTEとは別に、GPUと呼ばれるフレームバッファを扱う2Dグラフィックス処理用のチップも搭載している[37]。 PlayStation 2に搭載されたGraphics Synthesizer (GS) SCE製。GPUにeDRAMをVRAMとしてオンダイで混載し、2560bitという広帯域な内部バスを実現した。eDRAMはゲーム機用GPUに多用されるようになった。 PlayStation 3に搭載されたRSX Reality Synthesizer (RSX) NVIDIAとSCEが共同開発した。G70ベースであると説明されている[38]。 PlayStation Vitaに搭載されたPowerVR SGX543MP4+ Imagination TechnologiesとSCEが共同開発した[39]。 NINTENDO64に搭載されたRCP SGI(現AMD)製。座標計算や音声処理を全て内蔵DSPによるSIMD演算で行う構造で、これは現代で言えば頂点シェーダーによるGPGPUを行うことに相当する先鋭的なもの。 ニンテンドーゲームキューブに搭載されたFLIPPER ATI(現AMD)製。旧ArtXが担当、NEC製造。 Wiiに搭載されたHollywood AMD製。NEC製造。 Wii Uに搭載されたRadeon HD AMD製。Radeon HD 4000世代[40]。 ニンテンドー3DSに搭載されたPICA200 ディジタルメディアプロフェッショナルが開発した[41]。 ドリームキャスト、NAOMIに搭載されたPowerVR2 VideoLogic製。NEC製造。アーキテクチャとしてはDirectX 6世代相当[要出典]。 Xboxに搭載されたXGPU NVIDIA製。GeForce3と4の中間世代のアーキテクチャ[42]。Xboxは世界で最初にプログラマブルシェーダー対応のGPUを搭載したゲーム機となった。 Xbox 360に搭載されたXenos AMD製。統合型シェーダーアーキテクチャをPC用GPUより先行して搭載している[43]。DirectX 9世代とDirectX 10世代の中間に相当する。 Nintendo Switchに搭載されたNVIDIA Tegraのカスタマイズ品 NVIDIA製。カスタム品であることは公式発表されている[44]が、ベースとなったGPUがどの世代なのかは非公表である。 Vulkan 1.1、OpenGL 4.5以降、OpenGL ES 3.2に対応[45]。
なおXbox One、PlayStation 4においては、それぞれAMD製のx86互換APUのカスタマイズ版が搭載されており、GPGPUの活用とPCゲームからの移植性を重視したアーキテクチャとなっている[46]。
その他
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “Graphics Processing Unit” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2017年9月)近年[いつ?]、携帯電話やカーナビゲーションシステムの表示機能の高度化が著しく、組み込みシステムにおいて用いられていたVDPに代わって、OpenGL ES対応のプログラマブルシェーダーを搭載したGPUが採用されることが増えてきている。特に使用メモリと消費電力を抑える要求から、PowerVRのシェアが高い[要出典]。
「GPU」という名前
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “Graphics Processing Unit” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2015年12月)「GPU」は、1999年にNVIDIA Corporationが、GeForce 256の発表時に提唱した呼称である[47] [48]。
それまでビデオカード上の処理装置は「ビデオチップ」や「グラフィックスチップ」と呼ばれていたが、GeForce 256はハードウェアT&Lを世界で初めて搭載し、3次元コンピュータグラフィックスの内部計算および描画処理におけるCPU側の負荷を大幅に軽減するコプロセッサとしての地位を確立したことから、NVIDIA社は「Graphics Processing Unit」と命名した。
GPUと同様の名称として、Visual Processing Unit (VPU) が存在する。「VPU」は、3Dlabs Inc.が、Wildcat VP(量産品としては世界初の汎用シェーダー型設計のGPU[要出典])の発表時に命名した[49]。なお、VPUの呼称に関しては、ATI TechnologiesがRadeon 9500/9700の発表時に提唱したと誤解されることがある[50]が、実際は、3DlabsのWildcat VPの発表が先行している。また、ATIがVPUの呼称を使ったのは、当時は3Dlabsと提携していたからでもある。
現在[いつ?]はAMD (旧ATI) も主にGPUの呼称を使用している。
GPUとは別の分類だが、Intelは2019年から、画像認識などのコンピュータビジョンの処理に特化したプロセッサとしてVision Processing Unit(英語版) (VPU) という名称を使っている。「Intel Movidius Myriad X VPU」は、AIで利用されるニューラルネットワークを高速かつ低消費電力で実現できるエンジンとハードウェアアクセラレータを搭載する、AIアクセラレータである[51]。Meteor Lake世代のプロセッサではVPUを統合することが予定されている[52]。VPUに画像認識処理をオフロードすることで、CPU/GPU負荷を下げることが可能となる。
統合GPU
一般に、チップセットに搭載されているオンボードグラフィックスプロセッサおよびCPU内蔵GPU(統合GPU、integrated GPU: iGPU)のグラフィック機能は、単体チップ型のGPU(ディスクリートGPU、discrete GPU: dGPU)に劣るが、消費電力やコスト面では有利である。
このため、主にオフィススイートやインターネットアクセスなどを中心とした高性能が必要ない用途が想定され、低価格が求められる業務用端末(クライアント)機向けや、低発熱・低消費電力が求められるノートパソコンなどでは単体チップのGPUではなく、統合GPUが多く搭載されている。
比較的高性能なGPUを使用するゲーム機でもコストダウンを目的としてGPUの統合化が進んでいる。スマートフォンやタブレットに使用されているSoCもCPUとGPUをひとつのチップに統合している。
統合GPUでは、ビデオカードと違って専用のVRAMを持たず、メインメモリの一部をGPUに割り当てるユニファイドメモリアーキテクチャが採用されているが、通常はCPUとGPUのメモリ空間が分離されており、お互いのデータを直接参照することはできない。
そのため、事前にソフトウェアレベルあるいはドライバーレベルでのデータ転送処理が必要となる。
AMD APUはHSAのhUMAをサポートすることで、CPUとGPUのメモリ空間をハードウェアレベルで統合しており、従来のユニファイドメモリアーキテクチャよりもヘテロジニアス・コンピューティングに適した形態となっている[53][54]。
CPUとGPUはそれぞれ得意分野が異なるものの、CPUはコアあたりの性能向上が頭打ちになってきているため、伸びしろのあるGPUにダイの面積を割いて総合的な演算性能を向上させることは理にかなっている[55]。
GPU単体の製品のラインナップも、エントリ向けの低価格なローエンドから、価格と性能のバランスがとれたミドルレンジ、過酷な要求にも耐えうる高性能を持つハイエンド、そして価格を度外視して最高性能を求めるユーザー向けのウルトラハイエンドと様々である。
また、主にゲーミング用途を想定したコンシューマー向けや、業務用途を想定したプロフェッショナル・エンタープライズ向けなどに差別化されている。
しかし高性能なGPUの利用を前提とするAeroを搭載したWindows Vistaの登場以降、チップセット内、およびCPUパッケージ内に統合されているGPUコアの性能が向上してきたため、GPU単体の製品の主力は3Dゲームの快適なプレイやCADオペレーションあるいは3DCG制作におけるプレビュー用途を想定した、比較的高価で高性能なものへとシフトしている。
単体GPUは主にデスクトップPC向けのビデオカード上に実装されたものとして提供・利用されているが、ゲーミング向けの高性能ノートPCなどでは、CPU内蔵GPUだけでは性能的に不十分なため、別途マザーボード上に強力な単体GPUと専用VRAMを実装しているものもある[56]。
外部GPU
外付けの専用ボックス内にグラフィックスボードをスタッキングし、Thunderboltのような高速インターフェイス規格でPCに接続する形態(外部GPU、external GPU: eGPU)も登場している[57][58][59]。
ノートPCや一部のベンダー製デスクトップPCは、CPUやGPUを交換することはできず、拡張性に乏しい。外付けボックスを利用して高性能なeGPUをシステムに追加することで、この欠点を補うことができる。利用には対応OSが必要となる。
GPU開発企業
AMD DisplayLink(英語版)(USBのVGA出力やDVI出力用のICを開発している。ただし、これは一般的にGPUとは認識されていない) インテル(1990年代後半にIntel 740という単体GPUを手掛けた後、単体GPUから撤退し、その後は統合GPUのみ手掛けていたが、2020年に単体GPUに再参入した) Matrox(PC・コンシューマー向けの新規の自社GPU開発からは撤退し、他社製GPU採用に転向した[60]が、産業用の製品開発は継続されている) NVIDIA Moore Threads(英語版)(中国の新興GPUメーカー)
チップセットまたはCPU統合GPUのみ手がけている企業
Apple (自社製SoC専用。外販はしていない)
他社へのライセンス供与のみを行なう企業
ARM DMP Imagination Technologies(英語版)(旧VideoLogic(英語版)。1994年に社名変更[61]。元々は単体GPUを手掛けていたが、現在は組み込み市場に特化し、他社への設計のライセンス供与を行なっている。ドリームキャストで採用されたことが一番有名)
過去にGPUまたはビデオチップを手がけていた企業
ここにソースの記載がない企業は日本語もしくは英語版Wikipediaのリンク先でソースを確認されたい。
3dfx (Voodooシリーズなど。2000年末にNVIDIAに買収された) 3Dlabs(PERMEDIAシリーズやP10など。現在は低消費電力のメディアプロセッサを手がける) ALi(下記ArtXによる統合GPUの他、nVIDIAからRIVA TNT2のコアの提供を受けてAladdin TNT2という統合GPUも開発した事がある) ArtX(1990年代後半~2000年代前半にかけて、統合GPUのコアの部分を開発。主にALiの統合GPUとしてリリースされた。ATIによって買収済。ゲームキューブのGPUのコア部分を担当したことが一番有名) ATI Technologies (2006年にAMDに買収された。ATIブランドは買収後しばらく存続していたがAMDブランドに統一された[62]) Chromatic Research(英語版)(1990年代後半にMPACT2(英語版)というMPEGデコーダ内蔵のGPUを開発した事がある。ATIによって買収済) Cirrus Logic(1990年代前半~半ば頃にCL-GD54xxシリーズというローエンドGPUを開発していた。売却したグラフィック部門資産の変遷は、Magnum Semiconductor→GigPeak→Integrated Device Technology→ルネサスエレクトロニクス) チップス・アンド・テクノロジーズ 1997年にインテルに買収された[63]。 Evans & Sutherland(1990年代後半に、三菱電機と共同で「REALimage1200」「REALimage3000」というOpenGL系GPUを開発していた) Intergraph(英語版)(INTENSE 3DシリーズというGPUを開発していた[64]。グラフィックハードウェア生産部門であるINTENSE 3Dを3DLabsに売却後、ヘキサゴンに買収される) Macronix(英語版)(今はフラッシュメモリの会社だが、1990年代後半に一時期Turbo3というGPUを自社で開発していた時期がある[65]) NEC(1990年代後半にImagination Technologies/VideoLogicのPowerVR/PowerVR2のGPU製造を受託していた事がある。詳しくはPowerVRやドリームキャストの記事を参照) NeoMagic(1990年代半ば~2000年頃までMagicGraph128/256シリーズでノートPC向けGPUを開発していたが、2000年にPC向けからは撤退) Number Nine Visual Technology(Imagine128シリーズやTicket to Rideシリーズなど。1999年にS3によって買収済) Rendition(英語版)(1990年代後半にVeriteシリーズというワークステーション向けGPUを開発していた。Micronによって買収済) S3 Graphics(ViRGE/DXやDeltaChromeなど。単体GPU・チップセット統合GPUともに手掛けていたが、現在は撤退している) SGI (IRIS Graphics, RealityEngine, CRM, InifiniteRealityといったチップセットを開発していた[66][67]。1999年にグラフィックス部門をNVIDIAに売却[68]) SiS(SiS 315やXabreなど。単体GPU・チップセット統合GPUともに手掛けていたが、現在は撤退している) STマイクロエレクトロニクス(NECの後にImagination Technologies/VideoLogicのGPU製造を受託していた企業。KYRO II SEをもって撤退。詳しくはPowerVRの記事を参照) Trident Microsystems(英語版)(Blade XPやXP4など。2000年代前半にXGI Technology Inc.にグラフィックス部門を売却) Tseng Labs(ET4000/ET6000というDOS向けGPUを開発していた。グラフィック部門をATIに売却) Weitek(POWER9000/9100というワークステーション向けGPUを開発していた。ロックウェルに買収される) XGI Technology Inc.(VolariシリーズというGPUを手掛けていたが、2006年にパソコン向けからは撤退し、組み込み向けに移行) アイ・オー・データ機器(GA-1024Aなど、PC-98向けに自社でGPUを開発していた時期がある[69]) ソニー・コンピュータエンタテインメント(PlayStation向けにGeometric Transfer Engine (GTE)を、PlayStation 2向けにGraphics Synthesizer (GS)を開発。ゲーム機の項目も参照) ハドソン(PCエンジン向けにHuC6270を開発。HuC62の記事も参照)
脚注
^ 小口哲司他 (1987年). “μPD7220後継のグラフィックス・コントローラLSI, コピーや塗りつぶし機能を強化 - 日経エレクトロニクス1987.2.23” (PDF). Oguchi R&D. 2020年11月15日閲覧。 ^ Microsoft releases DirectX 7.0 | Windows Server content from Windows IT Pro ^ Schechter, Greg (2006年3月19日). “DWM's use of DirectX, GPUs, and hardware acceleration” (英語). Greg Schechter's Blog. 2009年2月14日閲覧。 ^ 【レビュー】初の統合型シェーダーアーキテクチャ「GeForce 8800シリーズ」を試す (1) 新アーキテクチャで登場したG80 | マイナビニュース ^ a b 日経エレクトロニクス 2007/10/8 「プロセサはマルチ×マルチへ」 ^ AMDのGPGPU戦略は新章へ - ATI Streamの展望、DirectX Compute Shaderの衝撃 (1) Radeon HD 4000シリーズでネイティブGPGPU | マイナビニュース ^ MicrosoftがGPGPU開発向けC++の拡張「C++ AMP」を発表 - 多和田新也(AFDSレポート)、PC Watch、Impress(2011年6月17日付配信、2012年3月24日閲覧) ^ テッセレーションの概要 ^ 現実路線へ修正されたAMDのFUSION - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2007年12月25日付配信、2012年3月24日閲覧) ^ Intelの次期CPU「Ivy Bridge(アイビーブリッジ)」を裸にする - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2012年3月2日付配信、2012年3月24日閲覧) ^ Intel NehalemとAMD FUSION 両社のCPU+GPU統合の違い - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2007年10月11日付配信、2012年3月24日閲覧) ^ CPUとGPUの境界がなくなる時代が始まる2009年のプロセッサ - 後藤弘茂のWeekly海外ニュース、PC Watch、Impress(2008年12月2日付配信、2012年3月24日閲覧) ^ 5981_High_Bandwidth_Memory_HBM_FNL - High-Bandwidth-Memory-HBM.pdf ^ 【レビュー】初のHBM搭載ビデオカード「Radeon R9 Fury X」を試す - PC Watch ^ これが“4096”の性能だ:“Fiji”と“HBM”の実力を「Radeon R9 Fury X」で知る (1/5) - ITmedia PC USER ^ Hot Chips 27 - AMDの次世代GPU「Fury」 (1) HBMを採用したAMDのGPU「Radeon R9 Fury」 | マイナビニュース ^ 株式会社インプレス (2018年3月20日). “【後藤弘茂のWeekly海外ニュース】 Intelなどプロセッサベンダーがけん引するHBM3規格” (日本語). PC Watch 2018年11月12日閲覧。 ^ NVIDIA® OptiX アプリケーション・エンジン | NVIDIA ^ NVIDIA® OptiX Application Acceleration Engine | NVIDIA ^ GTC - NVIDIA「OptiX」を解説、レイトレーシングはインタラクティブの時代へ (1) なぜ、今、レイトレーシングなのか | マイナビニュース ^ 4Gamer.net ― PowerVRのImaginationが“ハイエンドGPU”の設計に着手。ハイブリッドレンダリングハードウェア,そして新API「OpenRL」とは? ^ “GPU Shortage, Affordable Robodog, Humanizing Large Language Models, and more” (英語). GPU Shortage, Affordable Robodog, Humanizing Large Language Models, and more (2023年8月17日). 2023年10月30日閲覧。 ^ NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE P.44 IEEE 2008年 ^ ホワイトペーパー; NVIDIA の次世代 CUDA™コンピュートアーキテクチャ: Fermi™ ^ An Introduction to Modern GPU Architecture P.44 NVIDIA ^ NVIDIA GPUの構造とCUDAスレッディングモデル ^ a b c d e f g h i j k l m n o p NVIDIA (2009年). “Whitepaper; NVIDIA's Next Generation CUDA™ Compute Architecture: Fermi™ (V1.1)”. pp. 7-8. 2015年12月5日閲覧。 ^ a b c ■後藤弘茂のWeekly海外ニュース■ DirectX 11でも強力なNVIDIAの新GPU「GF100」 PC Watch 2010年1月19日 ^ a b c d e f GPU Computing Applications P.42 NVIDIA 2011年 ^ NVIDIA (2009年). “Whitepaper; NVIDIA's Next Generation CUDA™ Compute Architecture: Fermi™ (V1.1)”. p. 11. 2015年12月5日閲覧。 ^ 4Gamer.net ― NVIDIA,Fermi世代の次期GeForce「GF100」グラフィックスアーキテクチャを発表 ^ AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute P.3 2011年12月21日 ^ a b c d e f g h i j k l m n o p q r s t u v w AMD GRAPHIC CORE NEXT P.10 AMD 2011年7月 ^ a b c d e f g h i j k l m n AMD GRAPHIC CORE NEXT P.39 AMD 2011年7月 ^ a b c AMD GRAPHIC CORE NEXT P.24 AMD 2011年7月 ^ AMD GRAPHIC CORE NEXT P.33 AMD 2011年7月 ^ 【特別企画】歴代家庭用ゲーム機を軒並み分解――TGS2008「ゲーム科学博物館」より(7ページ目) | 日経 xTECH(クロステック) ^ 後藤弘茂のWeekly海外ニュース - PLAYSTATION 3のグラフィックスエンジンRSX ^ PS Vitaで採用されるGPUコア「PowerVR SGX543MP4+」のImaginationに聞く「+」の意味。PowerVRは次世代ゲーム機への採用も目指す!? - 4Gamer.net ^ 【西川善司】Wii UのGPU性能と新型コントローラに秘められた「コアゲーマー求心」の裏戦略 - 4Gamer.net ^ [CEDEC 2012]3DSはまだその実力を100%発揮できていない!? 3DSが搭載するGPUコア「PICA200」の詳細 - 4Gamer.net ^ 後藤弘茂のWeekly海外ニュース - NVIDIAチーフ・サイエンティスト インタビュー(下) ^ 3Dグラフィックス・マニアックス (5) GPUとシェーダ技術の基礎知識(5) | マイナビニュース ^ NVIDIA Gaming Technology Powers Nintendo Switch | NVIDIA Blog ^ Conformant Products - The Khronos Group Inc ^ 【後藤弘茂のWeekly海外ニュース】PlayStation 4のAPUアーキテクチャの秘密 - PC Watch ^ CreativeからGeForce 256搭載ビデオカードが登場 - AKIBA PC Hotline! 1999年10月9日号 ^ GeForce 256 ^ 3Dlabs Wildcat VP760 Datasheet ^ ATIがDirectX 9に対応したVPU「RADEON 9700」をリリース ^ 5G時代のエッジに求められるVPUとは?米インテル担当者に聞く | 日経クロステック(xTECH) ^ Intel、次世代のMeteor LakeにVPUを統合予定。第13世代CoreでLE Audio対応も - PC Watch ^ 【後藤弘茂のWeekly海外ニュース】CPUとGPUのメモリ空間を統一するAMDの「hUMA」アーキテクチャ - PC Watch ^ 【後藤弘茂のWeekly海外ニュース】AMD Kaveriのメモリアーキテクチャと今後のAPU進化 - PC Watch ^ CPU と GPU の比較: 違いを理解する | Intel ^ GeForce RTX 30 シリーズ ノート PC - NVIDIA ^ Razer Core X - Thunderbolt™ 3 eGPU ^ Mac で外付けのグラフィックプロセッサを使う - Apple サポート (日本) ^ Mac で Blackmagic eGPU を使う - Apple サポート (日本) ^ Matrox、NVIDIAのカスタム版Quadroを採用したビデオカード - PC Watch ^ Appleから利用停止宣告を受けたImaginationの今 - EE Times Japan ^ 4Gamer.net ― ATIにお別れ。AMD,ATIブランドを統合し,GPUは「AMD Radeon」に ^ ASCII. “インテルとATIが広範なクロスライセンス契約──RADEON統合チップセット登場も”. ASCII.jp. 2023年6月22日閲覧。 ^ Intergraph - 古典コンピュータ愛好会 ^ Macronix - VideoChips ^ ASCII. “業界に痕跡を残して消えたメーカー CG業界を牽引したSGI (1/4)”. ASCII.jp. 2023年6月22日閲覧。 ^ “sgistuff.net : Hardware : Graphics”. www.sgistuff.net. 2023年6月22日閲覧。 ^ EETimes (1999年8月10日). “SGI graphics team moves to Nvidia”. EE Times. 2023年6月22日閲覧。 ^ 1991年 もっと大きい画面が欲しい よりリアルに高速描画したい(アイ・オー・データ機器)
外部リンク
柿本正憲:「GPUの起源と進化」、GDEP, 2021年3月記事。 GPU移行 GPU移行に関するポータルサイト
関連項目
CPU VRAM GDDR3 GDDR5 リアルタイム3次元コンピュータグラフィックスAPI DirectX (Direct3D) OpenGL, OpenGL ES Vulkan (API) Metal (API) GPGPU ハードウェアアクセラレーション ビデオカード グラフィックアクセラレータ グラフィックコントローラ オンボードグラフィック 表話編歴グラフィックス・プロセッシング・ユニット (GPU)
GPU
デスクトップ向けインテル Arc HD Graphics NVIDIA GeForce Quadro Tesla Tegra AMD Radeon Pro(英語版) Instinct Matrox InfiniteReality(英語版) NEC µPD7220 3dfx S3 Graphics携帯機器向け
Adreno Appleシリコン Mali(英語版) PowerVR VideoCore(英語版) Vivante(英語版) Imageon Intel 2700G(英語版)
アーキテクチャ
計算カーネル(英語版) 製造 CMOS FinFET MOSFET グラフィックスパイプライン ジオメトリ バーテックス(英語版) ハイダイナミックレンジ合成 積和演算 ラスタライズ シェーディング レイトレーシング SIMD SIMT(英語版) テッセレーション T&L(英語版) タイルレンダリング(英語版) 統合型シェーダーモデル(英語版)コンポーネント
ブリッター(英語版) ジオメトリ処理(英語版) IOMMU レンダリング出力ユニット(英語版) シェーダー ストリーム処理 テンソルユニット テクスチャマッピングユニット(英語版) ビデオディスプレイコントローラ(英語版)
メモリ
DMA フレームバッファ SGRAM GDDR GDDR3 GDDR4 GDDR5 GDDR6 HBM メモリ帯域幅(英語版) メモリコントローラ 共有グラフィックメモリ(英語版) テクスチャメモリ(英語版) VRAMフォームファクタ
IPコア ビデオカード GPUクラスタ(英語版) GPUスイッチング(英語版) 外付けGPU 統合グラフィックスプロセッサユニット System-on-a-chipパフォーマンス
クロック周波数 画面解像度 フィルレート(英語版) ピクセル/秒(英語版) テクセル/秒 FLOPS フレームレート ワットあたりのパフォーマンス(英語版) トランジスタ数(英語版)関連項目
2DCG スクロール スプライト タイル(英語版) 3DCG グローバル・イルミネーション テクスチャマッピング ASIC GPGPU グラフィックライブラリ(英語版) ハードウェアアクセラレーション デジタル画像処理 圧縮 並列計算 ベクトル計算機 動画コーディング(英語版) コーデック(英語版) VLIW コモンズ コモンズ ポータル Portal:コンピュータ典拠管理: 国立図書館 ウィキデータを編集
ドイツ チェコ
カテゴリ:
GPUCPUグラフィックカードGPGPU 最終更新 2023年12月8日 (金) 17:19 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』
-
[FT]NVIDIA、ゲームで開花 強さは画像処理と計算力
https://www.nikkei.com/article/DGXZQOCB060KB0W3A201C2000000/『簡潔な話し方と革ジャンスタイルで知られる米エヌビディアの共同創業者で最高経営責任者(CEO)のジェンスン・ファン氏は、数々の栄光を手にしている。
エヌビディアは今や時価総額で世界6位。その半導体とソフトウエアで現在の人工知能(AI)革命をけん引する存在だ。今期(今年2月〜来年1月)の売上高は、米ビデオゲーム業界全体の合計額を上回る勢いだ。
その変貌ぶり織機メーカーだったトヨタと同じ
創業当初はパ…
この記事は会員限定です。登録すると続きをお読みいただけます。』
『創業当初はパソコンや米マイクロソフトのゲーム機「Xbox」向けの画像処理半導体(GPU)を製造していたが、10年ほど前にAIへと舵(かじ)を切った。それでも同社にとって昨年まではゲーム業界が依然として最大の収益源だった。
エヌビディアの変貌ぶりは古今東西の例の中でもすさまじく、トランプからゲーム機メーカーに転じた任天堂や織機から車のメーカーに発展したトヨタ自動車に匹敵する。
それだけにファン氏は当然、この数年、必死だった。同氏は11月下旬、米ニューヨーク・タイムズの金融ブログ「ディールブック」主催のイベントで「死ぬか生きるかの瀬戸際のような状況に身を置くのが好きだ。逆境こそ楽しい」と発言している。
パソコン技術の最先端を担ってきたゲーム
だがエヌビディアの方向転換は思うほどとっぴではない。ビデオゲームとAIには多くの共通点がある。ゲームにはパソコン技術の最先端を担ってきた長い歴史がある。それは、任天堂のある幹部が1980年代に家庭用ゲーム機「ファミリーコンピュータ」を発売した直後、フィナンシャル・タイムズ(FT)に対し「自社のコンピューターがゲーム以外は何もできないと認めたのは我々が初めてだ」と語った言葉にも表れている。
任天堂はその後ファミコン用ゲームソフト「スーパーマリオブラザーズ」や携帯型ゲーム機「ゲームボーイ」などのヒットを飛ばした。ファン氏が仲間とエヌビディアを設立した93年は、ソニーが最初の家庭用ゲーム機「プレイステーション」を発売する前年で、当時のゲームにはコンピューターの画像処理技術の粋が集められていた。
従って、ファン氏自身がゲーマーでなかったとしても、エヌビディアにとってゲーム関連市場は自社のGPUにはうってつけの市場だった。
事業転換には2種類ある。自然の成り行きによるものと偶然のいたずらによるものだ。DVDレンタル事業を展開していた米ネットフリックスが、動画配信へとシフトしたのは当然の進化だった。
一方、フィンランドで1865年に製紙会社として創業したノキアは、最終的に通信機器メーカーになるとは想像もしていなかった。エヌビディアのゲーム用GPUからAI向けスパコンへの転換は、この2つの間に位置するといえる。
機械学習が停滞するなか画像認識力で世界を驚かす
GPUは単純計算を同時に多数こなす並列処理が可能なため、並列処理数を増やせば処理速度が飛躍的に高まる。よってエヌビディアが1999年に初のGPUを市場に投入した直後から、ゲーム以外にも幅広い用途があることは明らかだった。ただ、ゲーム以外に具体的にどんな用途があるかはまだよくわかっていなかった。当時、機械学習は技術の進歩が停滞しており、エヌビディアはモバイルコンピューティングや大規模なビジュアルシミュレーション(編集注、様々な現象を目に見える形にし、リアルに表現すること)に力を入れていた。
ファン氏がAI市場にGPUの商機があると気づいたのは2012年だ。オープンAIのチーフサイエンティストを務めるイリヤ・サツキバー氏(編集注、理事は既に退任している)を含むグループがエヌビディアの技術を使い、「アレックスネット」というニューラルネットワークを鍛え、その画像認識能力が世界に衝撃を与えたのだった。
4年後、ファン氏は初のAI向けスパコンをオープンAIに納入した。同AIスパコンの最新版は3万5000個にも及ぶ部品で構成され、価格は25万ドル(約3700万円)を上回るが、これらのAIスパコンこそがエヌビディアの近年の成長を支えてきた。
すては計算能力、それで「AIの冬」は目覚めた
ゲームとAIは計算力がものをいう点が似ている。ゲームの画面はGPUの情報処理速度の向上で着実に進化してきた。本物のようなバーチャル世界でプレーヤー同士のアクションや絡み合いを実現するには、画像に緻密な陰影処理が必要で、それには膨大な計算を同時に多数こなす能力が必要とされる。これはまさにAI開発の「苦い教訓」だ。ニューラルネットワークの専門的な設計は重要だが、情報をいかに高速で処理し的確な画像を生成できるかを決めるのは結局は計算速度だ。ニューラルネットワークは2000年代前半にゲーム向けに設計されたGPUによるトレーニングを受け、「AIの冬」から目覚めたと言われる。
エヌビディアのディープラーニング応用研究担当バイスプレジデント、ブライアン・カタンザロ氏は「画像処理とAIには重要な共通点がある。計算能力が高いほどよい結果が得られることだ」と指摘する。
同社の最新技術は最初期のGPUに比べ数千倍(測定基準によっては数百万倍)も能力が高いため、AIは人間が恐怖を感じるほど雄弁になった。
ゲームとAIでは予算がケタ違い
ゲームとAIの間にはエヌビディアにとって有利な相違点が1つある。どんな熱心なゲーマーも自分のパソコンの情報処理速度を上げる最新のグラフィックス機材に払える金額には限界があるが、オープンAIを超えようとする企業は最新のスパコンに何億ドルでも払う点だ。エヌビディアはこうした企業に対し極めて優越的な立場にある。その状況がいつまでも続かないとしてもだ。
ゲームとAIを動かす技術は再び交わるかもしれない。人間は近い将来、「AIエージェント」と頻繁に接触しなければならなくなりそうだが、その場合キーボードで文字入力する以外の方法で接する道をみつける必要がある。そこではゲームやバーチャル世界にも似た、もっと円滑なやりとりが必要となる。
ゲームが「子どもだまし」の技術であったことはない。エヌビディアの隆盛がそれを物語っている。米IBMは当時のチェス世界王者ガルリ・カスパロフ氏を破るためスパコン「ディープ・ブルー」を開発し、97年にその目的を達成した。
それと同じようにエヌビディアはゲームの性能を上げるためGPUを進化させてきた。ゲームはその時代の技術的要求が最も高い分野だったが、そのことでGPUは他でも用途を広げることになった。たかがゲームなどと決して侮ってはならないということだ。
By John Gapper
(2023年12月2日付 英フィナンシャル・タイムズ電子版 https://www.ft.com/)
(c) The Financial Times Limited 2023. All Rights Reserved. FT and Financial Times are trademarks of the Financial Times Ltd. Not to be redistributed, copied, or modified in any way. The Nikkei Inc. is solely responsible for providing this translation and the Financial Times Limited does not accept any liability for the accuracy or quality of the translation.
【関連記事】
・岸田首相、エヌビディアCEOと面会 半導体供給増を要請
・最高益NVIDIA、時価総額1年で3倍 日米株式市場に波及 』 -
米AMD、新型AI半導体を発表 「市場成長、年70%に」
https://www.nikkei.com/article/DGXZQOGN0706G0X01C23A2000000/『【シリコンバレー=山田遼太郎】米アドバンスト・マイクロ・デバイス(AMD)は6日、人工知能(AI)向け半導体の新製品を発表した。生成AI向けに画像処理半導体(GPU)の処理能力を高め、同分野で独走する米エヌビディアに対抗する。データセンター向けAI半導体市場の成長が従来見込んだ年率50%を大きく上回り、今後4年は年70%の成長が続くとの見通しも示した。
米西部カリフォルニア州サンノゼ市で技術イ
この記事は会員限定です。登録すると続きをお読みいただけます。』
-
dGPU部門も危うい?本業回帰するIntel
https://pc.watch.impress.co.jp/docs/column/tidbit/1549980.html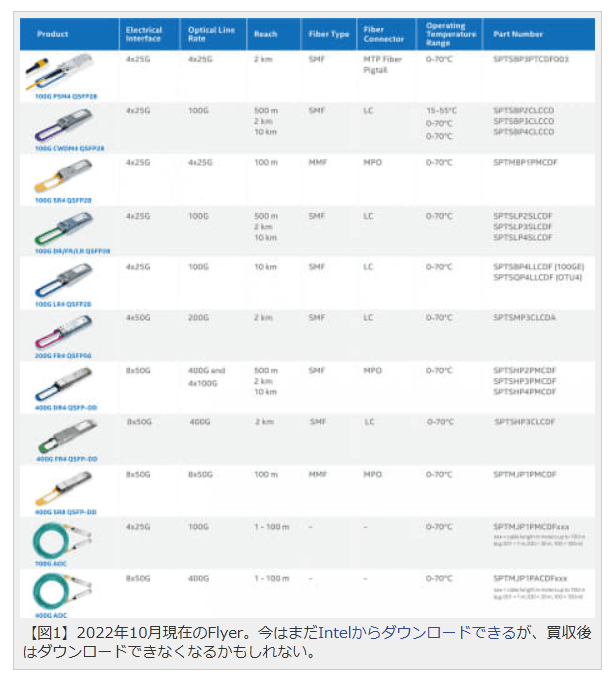






『 大原 雄介
2023年11月28日 06:13
10月27日にIntelは第3四半期の決算を発表したが、これに先立ち10月4日にPSGのスピンアウトを発表した。
新会社は2024年1月1日からスタートするが、CEOには現在DCAIのトップであるSandra Rivera氏が就任。COOは現在PSGを率いているShannon Poulin氏が就く形だ。そして10月30日、事業部としてはNEXになると思うのだが、ここが手掛けていたSilicon PhotonicsベースのPluggable Ethernet Transceiverの事業をJabiに売却している(Javiのプレスリリース)。
シリコンフォトニクスの一部部門を売却はちょっと謎
Intelからはプレスリリースは出ていないが、第3四半期の決算発表の中でゲルシンガーCEOが「当社は、シリコンフォトニクスビジネスの抜き差し可能なモジュール部門を売却することを決定しました。これにより、AIインフラストラクチャの拡張を可能にする高価値コンポーネントビジネスと、光I/Oソリューションに集中できるようになります」と明確に述べているから、理由は明白だ。
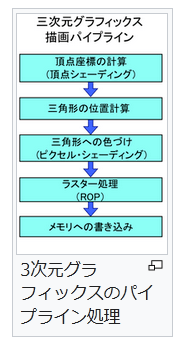
Intelは100G~400GのEthernet Moduleを販売している(図1)が、この製品は標準規格に則ったものだから、他社製品と混在させても相互接続性が確保される「はずだ」(実際には時々怪しい場合がある)し、そこに変な拡張機能を入れてもアプリケーションが対応しているとは限らない。であれば機能面での差別化はできないし、必然的に品質か値段でしか勝負にならない。
ただ品質がそこまで大きく変わるか? というと、たとえば10年や20年と使えばおそらく明確に差が出てくるだろうが、その前にネットワーク刷新が煩雑に行なわれるのが常だということを考えると、実はそこまで大きな違いは出てきにくい。
となると結局値段の叩き合いになるのは見えている。こうなると、地味に稼ぐことは可能かもしれないが、大儲けするのは困難である。であればこうしたビジネスを売り払ってしまい、In-Package Silicon Opticsのような高付加価値が期待できる分野に集中する、という考え方は分からなくもない。
ただ、元々なんでIntelがこの分野に参入したか? といえば、同社のSilicon Opticsが量産製品に使われたケースが非常に少ないためだ。筆者がぱっと思いつくのは2011年にVAIO Zで採用されたLightPeakぐらいのものだし、これも1世代限りになってしまった。いつまで経っても研究段階のままでは先に進めない。
量産製品にSilicon Opticsを採用することで、量産段階で出てくるであろうトラブルとか問題に対する知見を積むとともに、広範に使われるために必要なコストダウンへの取り組みを行なうための格好な商品として、「Pluggable Ethernet Module」が選ばれて大量出荷の実績を積んだ(図2)と言うそもそもの経緯を考えると、本当に売っちゃってよかったのか? という疑問は残るところだ。
【図2】2022年のTechFieldDay 25におけるRobert Blum氏(Sr. Director, Mktg and New Business, Silicon Photonics Product Division)のスライドより。ちなみに氏の現在のポジションは現在Applied MaterialsのHead of Product Line Management, Photonics Platforms Business.
Ethernetの方も、現在200G/Laneに向けて標準化が進んでいるほか、幾つかのMSAが独自規格のものを策定中だし、こうした用途に向けてより高速なモジュレータとかフォトディテクター、あるいはMUX/DeMUXなどのコンポーネントを実際の製品というフィールドで確認して実績を積める(図3)機会を、今回の売却で失ってしまったことになる。
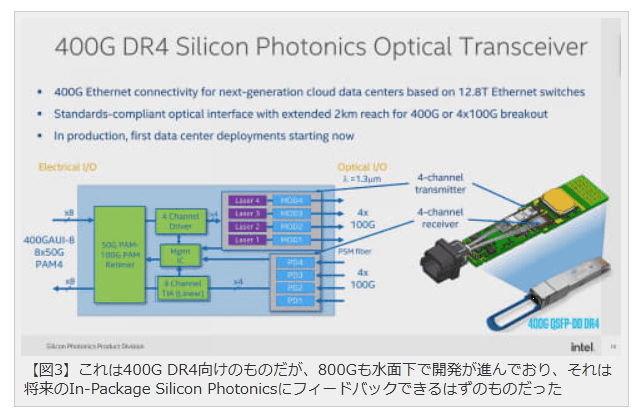
【図3】これは400G DR4向けのものだが、800Gも水面下で開発が進んでおり、それは将来のIn-Package Silicon PhotonicsにフィードバックできるはずのものだったPSGの売却は必然的な流れだったか
冒頭の話に戻るが、これはPSGも同じことである。2015年にAltera買収が報じられた際のIntelの動機は3つあったと考える。
1つは公表されている話であるが、今後のサーバービジネスにFPGAが必須と当時は考えられていたことだ。当時、たとえばMicrosoftは同社のAzureのインフラ回りの制御をCPUではなくFPGAを使って実装しており、CPUを使うよりも高い効率を実現していた。ほかにもApplication SpecificなServer Workloadの実装にFPGAが効果的(その1つにはHFT:高頻度取引と言われる金融向けの高速取引が挙げられる)という話が出てきており、こうした用途を実現するにはFPGAが欠かすことができなかった。これは最終的にIntel PAC(Programmable Acceleration Card)という形で実現している。
2つ目は、新たな収益源の確保である。2015年というのはブライアン・クルザニッチ氏がCEOをしていた時期に当たるが、クルザニッチ氏はx86ベースのCPU一本槍という従来のIntelのビジネスでは遠からず立ち行かなくなると判断、製品ポートフォリオの多角化を急速に進めようと試みる。
この結果として、同氏がCEOを務めていた2013年5月~2018年6月の間に行なわれた企業買収は実に26件。公表されている範囲で一番金額が大きかったのはAlteraの167億ドルだが、2017年のMobileyeも153億ドルだし、結局後で放棄することになったNervana Systemsも3.5~4億ドル、もっと理解ができないLSI Axxia部門には6.5億ドル、Movidiusには4億ドル、と結構細かく買収を重ねており、非公開のものまで全部含めた総額はおそらく500億ドル規模に達するだろう。
こうした多数の買収の中で、Alteraはかなり筋が良かった。というのは買収直前の2014年度末の決算報告では、売り上げが19億3,200万ドルなのに対し、粗利は12億8,400万ドルという、実に66%もの粗利率を誇った。
絶対額はともかく、粗利率は66%という大変に優れた業績であり、2014年のIntelの事業部で言えばIoTG(IoT Group)が21億4,200万ドルの売上に対して営業利益は6億1,600万ドル、粗利率28.7%と(Intelの中では相対的に)低い粗利率に喘いでいたのと好対照である。
仮にAlteraをIoTGに含めれば、売上40億7,400万ドル、営業利益19億ドルで、粗利率はおよそ46.7%。DCG(Data Center Group)の次になる稼ぎ頭であり、PCCG(PC Client Group)を上回る粗利率が実現する。
そして3つ目で説明する要因が成功すれば、Altera部門の売上はさらに伸ばせるはずだと考えたのだろう(実際にはProgrammable Solutions Groupとして別組織になったが)。
その3つ目は、ファブの利用率の向上である。もともとAlteraは2013年、それまで付き合っていたTSMCからIntel Foundryに鞍替えを決定する。TSMCの20nmが予想以上に問題が多く、その一方でIntelの22nm FinFETプロセスが非常に良好だったことを受けてだろう、次世代のStratix 10をIntelの14nmで製造することを決定。
その後買収されてからは、次世代製品をIntel 10nmで製造するロードマップを明らかにしている(図4)。これがうまく行けば、Alteraに変わってTSMCを利用することになったXilinxに性能差を付けられると思ったのだろう。
【図4】2016年8月に国内で行なわれた説明会での資料より
そしてIntelとしては、14nmと10nmのファブの稼働率を上げられることになる。これまでもXScale(Marvellが買収)/IXP Packet Processor(Netronomeとして独立)/Tabura(独立系FPGAベンダー:2015年に破綻)など小規模なファウンドリビジネスは行なっていたが、Alteraはそれとは比較にならない程多数の製品の製造を行なう。これを請け負うことで、早期に14nmや10nmの設備投資を回収できるめどが立つということだ。
10nmで躓いた結果がここにも
ところがIntelの思うように事態は進まなかった。まず14nmを利用してのStratix 10の製造が予想以上に手間取り、2016年中に出荷予定だったのがほぼ1年遅れの2017年10月まで量産出荷が伸びている。
悪いことにこの時期、Intelの10nmが完全に失敗していた。この結果、Intel自身のチップが14nmを使わざるを得ず、しかもAMDとの競合が激しくなったことでよりコア数を増やすなど競争力強化に走らざるを得ず、ダイサイズが大型化。つまりより多数のウェハを利用することになったため、Stratix 10の製造に支障をきたした。
この結果としてこうした大容量FPGAを使う用途、この時期で言えば5Gの基地局向けのシステムでAlteraは前世代の「Stratix V」しか安定して供給ができずにいた。一方のXilinxは16nmで製造する「Virtex Ultrascale+」を2016年末から量産出荷しており、結局こうしたハイエンドマーケットをXilinxに掻っ攫われることになった。おまけに10nmを使う次期ハイエンド(Falcon Mesa: Agilex)製品は、10nmの開発の遅れをモロに喰らうことになり、こちらも出荷が遅れた。
結果、2018年までIntelとXilinxでそれほど大きな差がなかったのが、2019年以降は大差がつくようになる。FPGAのような組み込み向けの場合、デザインウィン(設計を獲得)から出荷までに数年の差が生じるのは避けられない。2016~2017年の時点で5G基地局向けの設計でXilinxが大幅にシェアを獲った結果、2019年あたり(つまり実際に5G基地局の大規模設置が始まった時期)に売上の差として表れたわけだ。
そしてトップエンドの製品がAltera→Xilinxに移行したことで、Arriaなどのミドルレンジを使う用途に関してもAltera→Xilinxの移行が明確に発生。変わらないのは引き続きTSMCで製造されていたローエンドのCycloneだけという有様になった。
2015年の売上で言えば、Xilinxが23億7,700万ドル、Altera(というかIntelのPSG)が19億3,200万ドルと、55:45位の比率だったのが、2020年だと31億6,300万ドル対18億5,300万ドルで、ダブルスコアとまでは言わないものの63:37までギャップが広がっている。
おまけに、その新製品の開発に手間取ったおかげで営業利益も急速に減少しており、2020年度におけるPSGの営業利益は2億6,000万ドル、粗利率は13.5%まで減少してしまった。つまりもうPSGは新たな収益の柱になるどころか、お荷物寸前というところまで内容が棄損されてしまったわけだ。
悪いことに、この間にサーバー向けのFPGAのニーズは逆にどんどん減っていった。インフラ回り向けにはIPU(Infrastructure Processing Unit)がASICの形で登場、FPGAより安い価格と消費電力でより高い処理性能を発揮するようになった。2017年頃から興隆したAI/ML向けの用途も、推論はともかく、トレーニングではFPGAには荷が重く、結局NPUあるいはGPUがそのマーケットに充てられることになってしまった。
eASICは雲行き怪しく
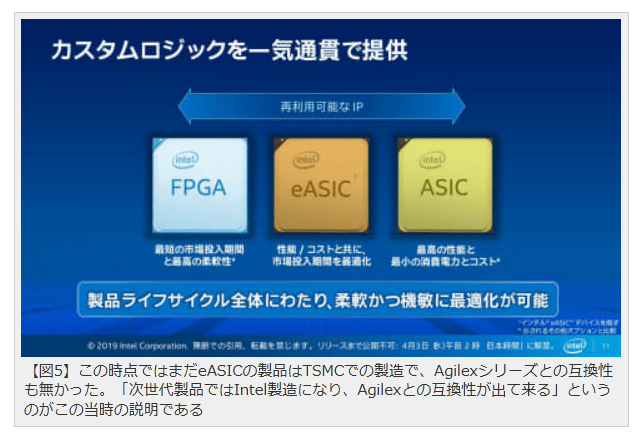
eASIC買収の翌年にはこんなロードマップ(図5)が発表されたものの、2020年に発表されたeASIC N5XシリーズはまだTSMCでの製造(これはつまりIntelによる買収前に開発されていたもの)であり、Intel Foundry製造のものはまだ量産に至っていない。そして今回の動きでPSGがIntelからスピンアウトしてしまうと、まだこの次世代eASIC製品の開発が継続されるかどうかも怪しくなってくる(後継もTSMCで、という可能性もある。もっと言えば、Agilex自身もどこまでIntel Foundryを頼るか怪しいところで、かつてのMarvellに引き取られたXScale製品のように、将来はTSMCを利用したAgilexに代替される可能性もある)。
【図5】この時点ではまだeASICの製品はTSMCでの製造で、Agilexシリーズとの互換性も無かった。「次世代製品ではIntel製造になり、Agilexとの互換性が出て来る」というのがこの当時の説明である2022年のForm 10-Kの事業部別損益(図6)の中に、既にPSGの名称はなく、「All other」の中に組み入れられてしまっている。唯一PSGの名前が出てくるのはのれん代(図6)の項目で、2022年中に全額償却を行なっているのが分かる。つまりPSGの分離は、事実上2022年末には既定路線だったことになる。
【図6】2021年まではPSGの項目があったのが消えているのが判る。これに伴い過去のPSGの売上や粗利もAll othersに移ったことで、All othersの金額が2021年度と2022年度で大きく変化している
【図7】前年の決算ではのれん代が26億5,400万ドルだったので、どっかで200万ドルほどふえたらしい(が、この数字の前では誤差の範囲ではある)
その2022年末の決算発表の中で、NEXに属するTofinoのスイッチ製品について、もう新規投資は行なわないとすることが発表されている(図8)。実際Intel Arkで確認すると、全ての製品が「Marketing Status:Discontinued」であり、いくつかの製品はまだ供給こそされているものの、もう新製品の開発は難しい。
【図8】これは事実上TofinoシリーズのSwitch製品を指すものと考えられる
そもそもこの製品はBarefoot NetworksがIntelによる買収「前」に販売していたものであるが、本来Intelは2度に渡るInfiniBand製品展開の放棄や、第2世代Omni-Path Fabric製品の開発中止などで、サーバー同士のインターコネクト製品を失っており、これを補完するものと考えられていた。
実際HPCなどこれまでOmni-Path Fabricをベースに構築してきたサイトは、より高速なインターコネクトを利用するのに現状のOmni-Path FabricのSwitchとI/F Cardを捨て、NVIDIA/MellanoxベースのInfiniBandを使うか、Ethernet Switchを利用するかという話になっており、このOmni-Path FabricベースのSwitchの代替としてTofinoベースの製品を提供すると見られていたからだ。2022年末の発表は、この路線を否定するものになった。要するにIntelはもうこうしたHPC/Cluster向けのSwitchを投入する意思はない、ということになる。
次はグラフィックス?
その一方でファブへの投資は引き続き続いているし、プロセッサへの投資も同様である。要するにIntelはもうプロセッサとそれを製造するためのFabにしか資金を投じないという話で、これはクルザニッチ氏以降の多角化路線を、それ以前の時代に戻す動きと評しても良いように思われる。
もちろん完全に、ではない。今の時点でAIを無視することはできないし、推論はともかくトレーニングにx86プロセッサは非力すぎる。だからHavana LabsベースのGaudiに関しては積極的に投資が続いている。ただそれ以外の多角化分野については、今後も売却あるいは放棄するという方向が続きそうに思える。
その筆頭に挙げられそうなのが、AXG(Accelerated Computing Systems and Graphics)だと筆者は考える。
IntelはAXGを分割、Ponte Vecchioこと「Datacenter GPU Max」やArctic Soundこと「Datacenter GPU」はデータセンターAIに、AlchemistやBattlemageに代表されるディスクリートGPUはCCGにそれぞれ移管された。そしてAXGのトップだったラジャ・コドゥリ氏はチーフアーキテクトの座に就くとされたが、実際にはそのコドゥリ氏は椎間板の手術のために2002年末から入院したことを発表しており、3月末に離職することをゲルシンガーCEOが明らかにしている。
このうち、Ponte Vecchioの後継(Rialto Bridgeはキャンセルとなったが、2025年にCPUとGPUをワンパッケージにまとめたFalcon Shoresが投入されることが2023年5月のISC 23公開されており(図9)、これで大幅な高速化を実現するとしている(図10)。こちらの製品はデータセンターAIの担当範囲で、IntelがHPCマーケットから完全撤退するのでもない限り必須なだけに、今後も開発が続くであろう。
【図9】このスライドは2022年2月のInvestor Meetingの時のもの。発想からするとAMDのInstinct MI300Aと同じAPUであるが、Intel的にはこれはXPUという分類との事。ちなみに2022年の時点ではこれを2024年中に投入予定だった
【図10】絶対性能そのものは相変わらず公開されていない。もっとも先日公開されたANLに納入されてTop 500で2位を獲ったAuroraの性能効率(消費電力あたりの性能)がかなり悪かったことを考えると、Performance/Wattを5倍以上引き上げるという目標は必須なのかも
問題はCCGが担当するというXeブランドのディスクリートGPUである。Battlemage世代が本当に開発が続けられ、出荷につながるのか? というあたりである。
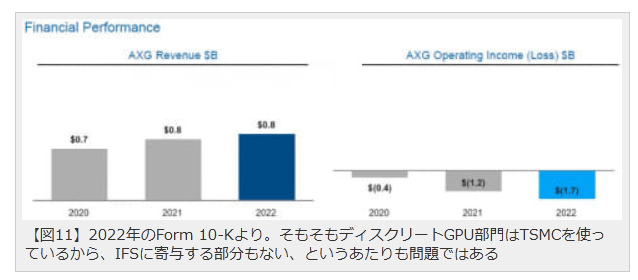
CCGに移管されてしまった結果として、今年度(2023年)におけるGPUの売上というのが見えなくなっているが、2022年までは間違いなくお荷物だった(図11)ことを考えると、CPUビジネスに直接関係ないAXGのディスクリートGPU部門が生き残るのは大変に困難であろう。だからといってPSGみたいにスピンアウトしてIPOを狙う、といっても多分無理だろうし、どこかに売却しようとしたところで買ってくれる会社も思いつかない。
【図11】2022年のForm 10-Kより。そもそもディスクリートGPU部門はTSMCを使っているから、IFSに寄与する部分もない、というあたりも問題ではある
現実問題としてディスクリートGPUビジネスからは撤退、CPUに統合するチップレット向けの開発部隊のみを残してあとは解散、といった感じになっていくように思える。早ければ年内、遅くても来年中(2024年)にはこうした動きになるように筆者には考えられる。
結局のところ、こうした一連のリストラクチャリングにより、Intelは再び2013年以前の「強いCPUの提供」と「それを支える強い製造能力の提供」を行なう会社に先祖返りしようとしているように筆者には見える。多分ゲルシンガーCEOの目的もここにあるのだろう。
問題は、その強い製造能力が本当に提供可能になるかどうか、である。まだ、行く手は茨の道が続いている。 』