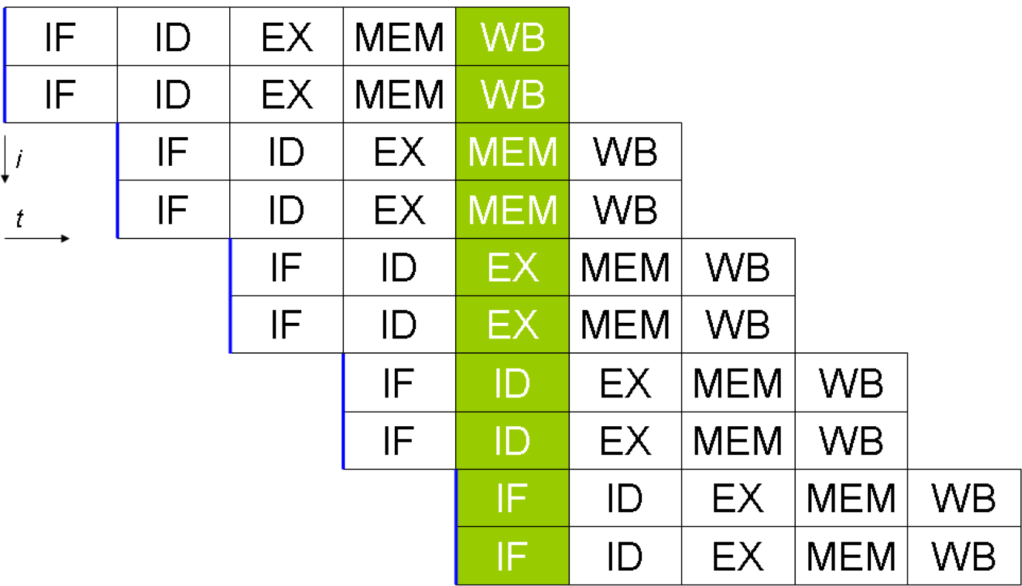
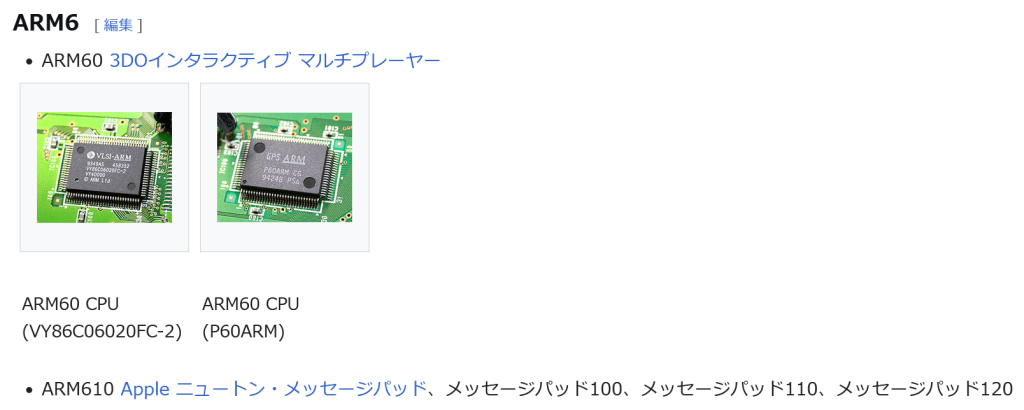
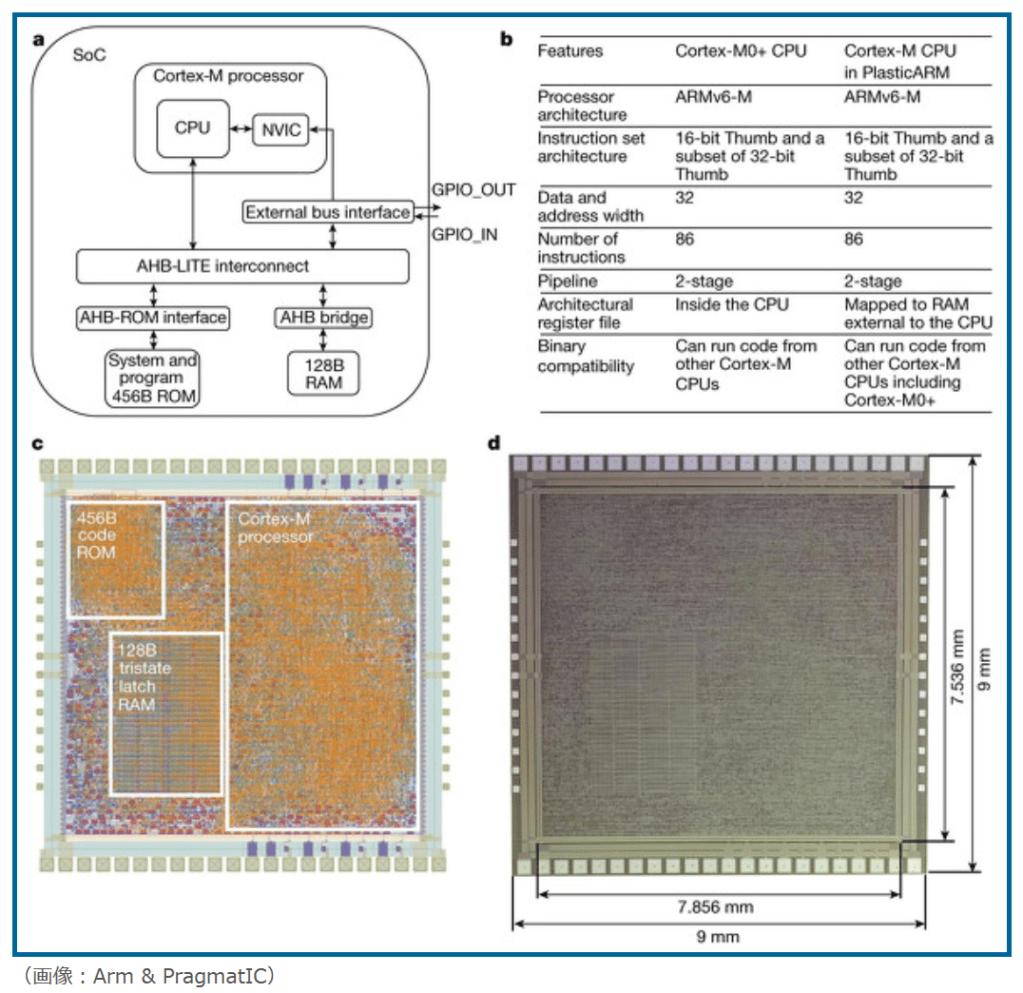
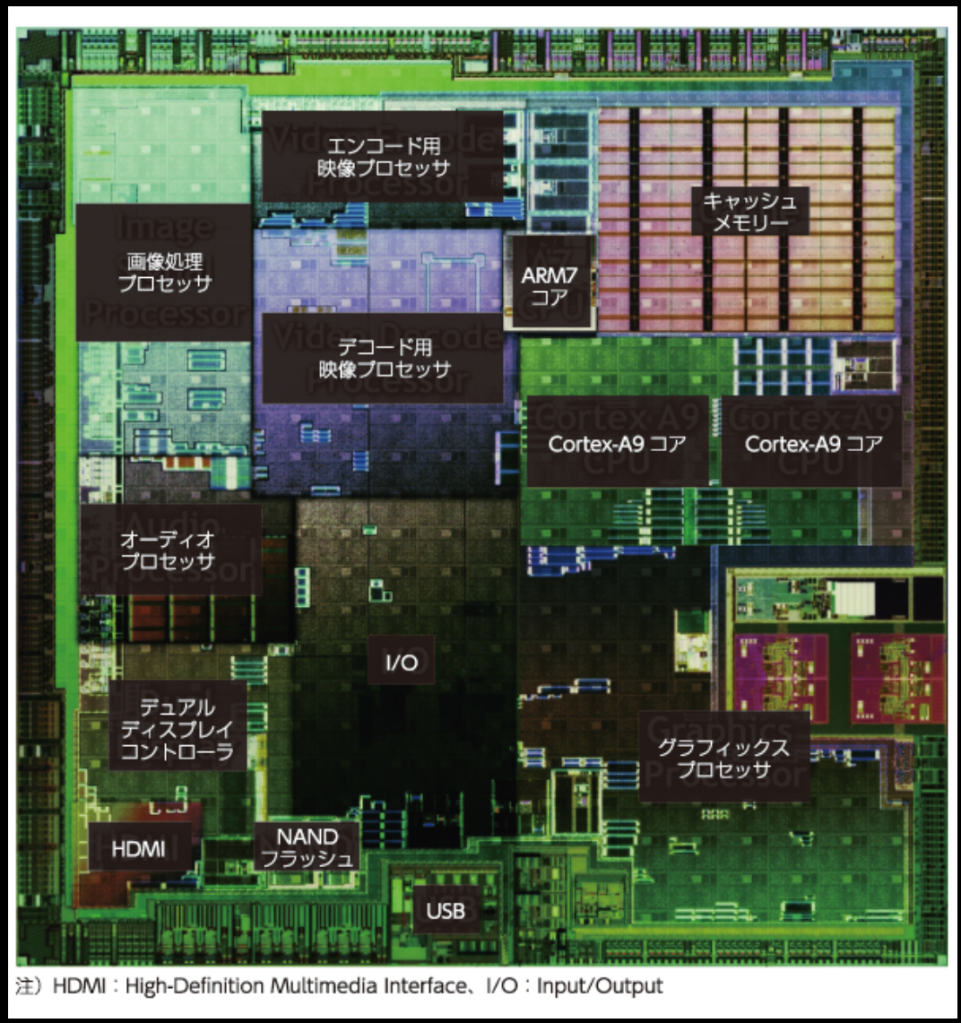
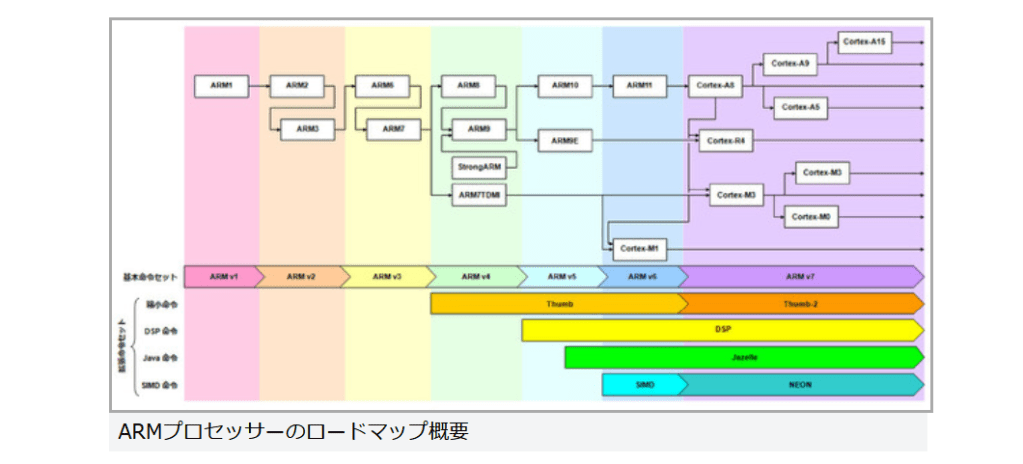
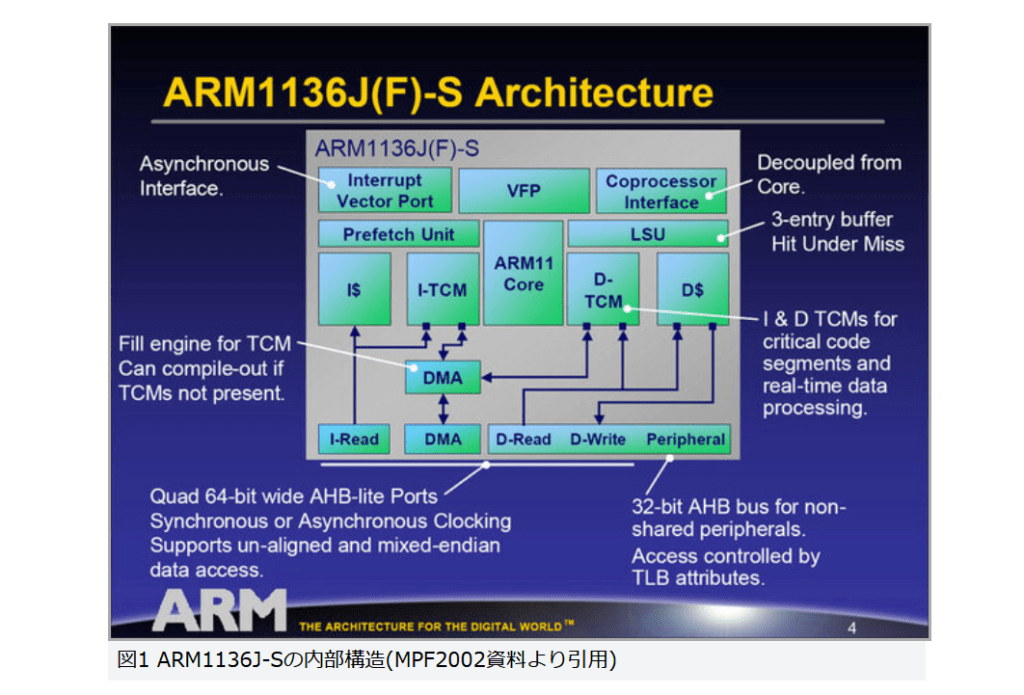
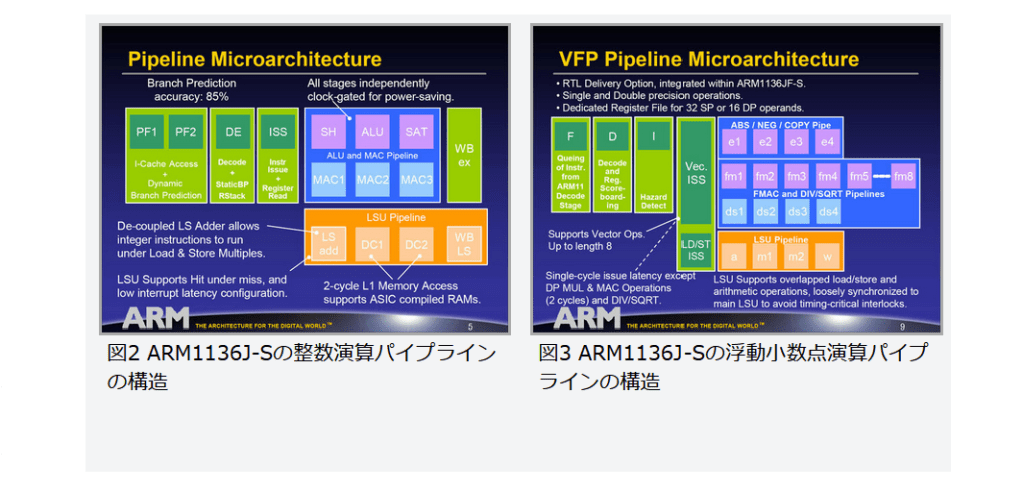
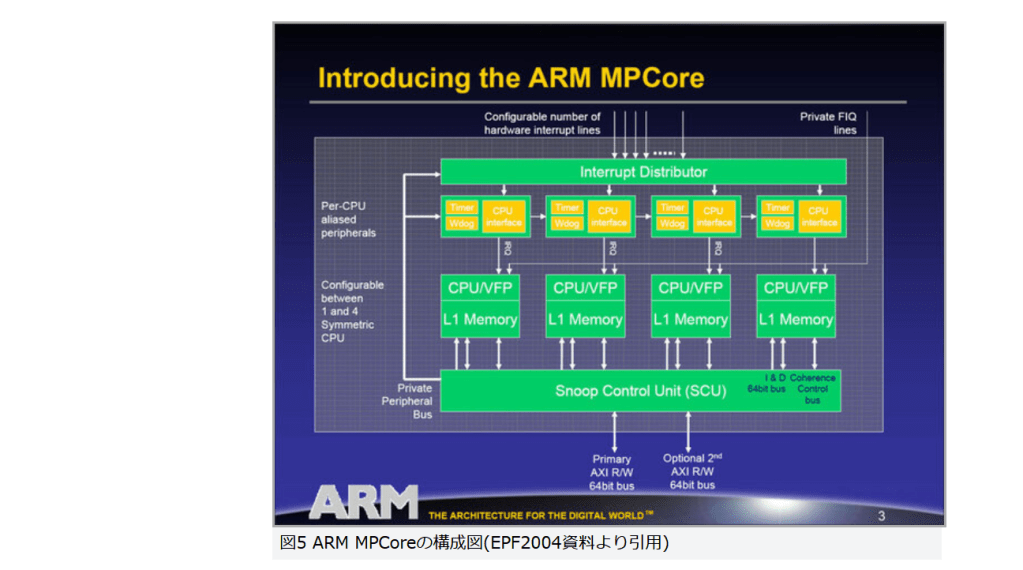
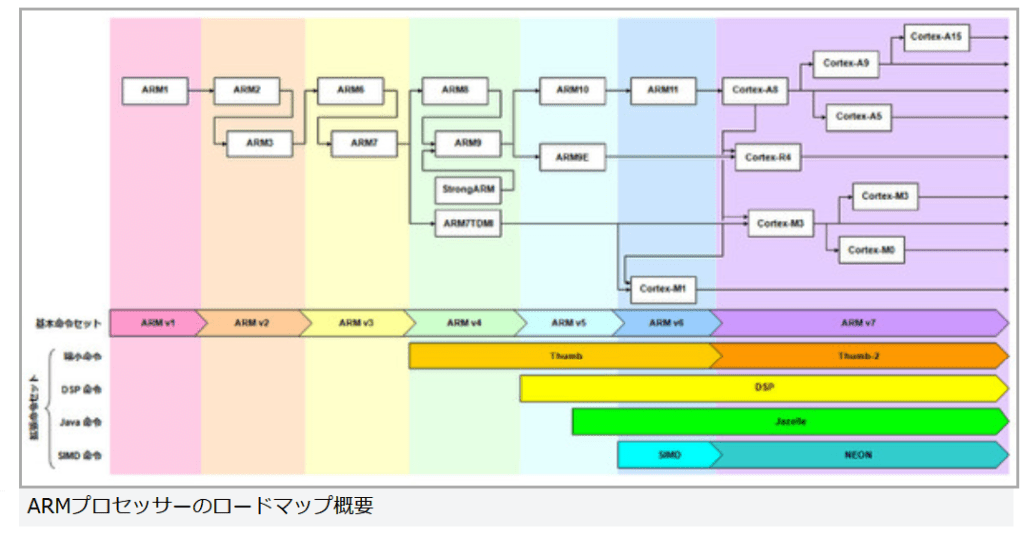
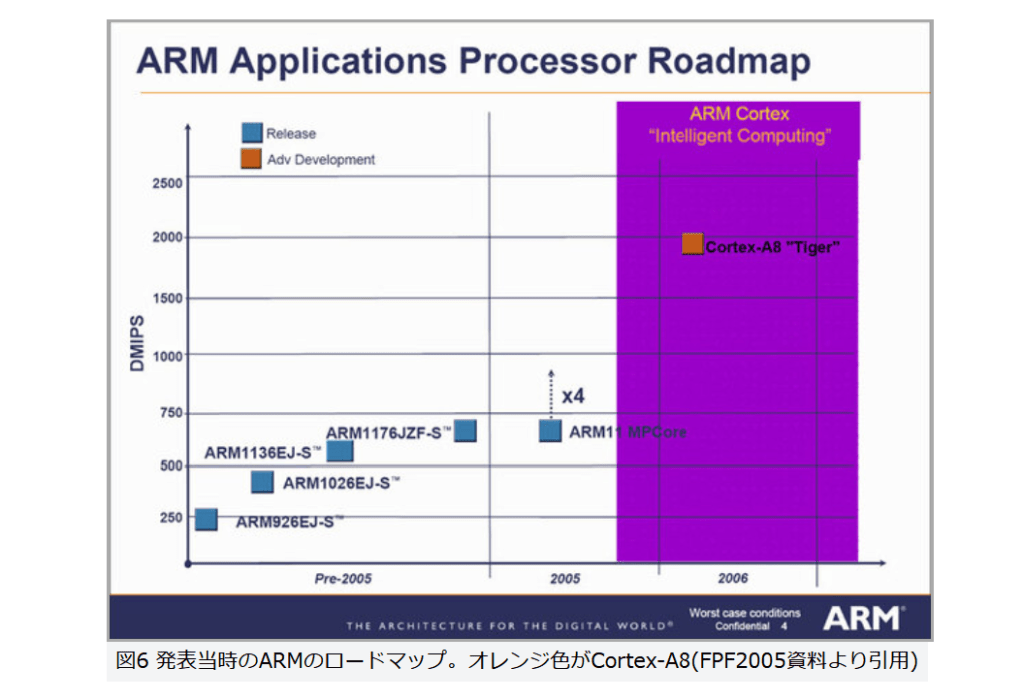
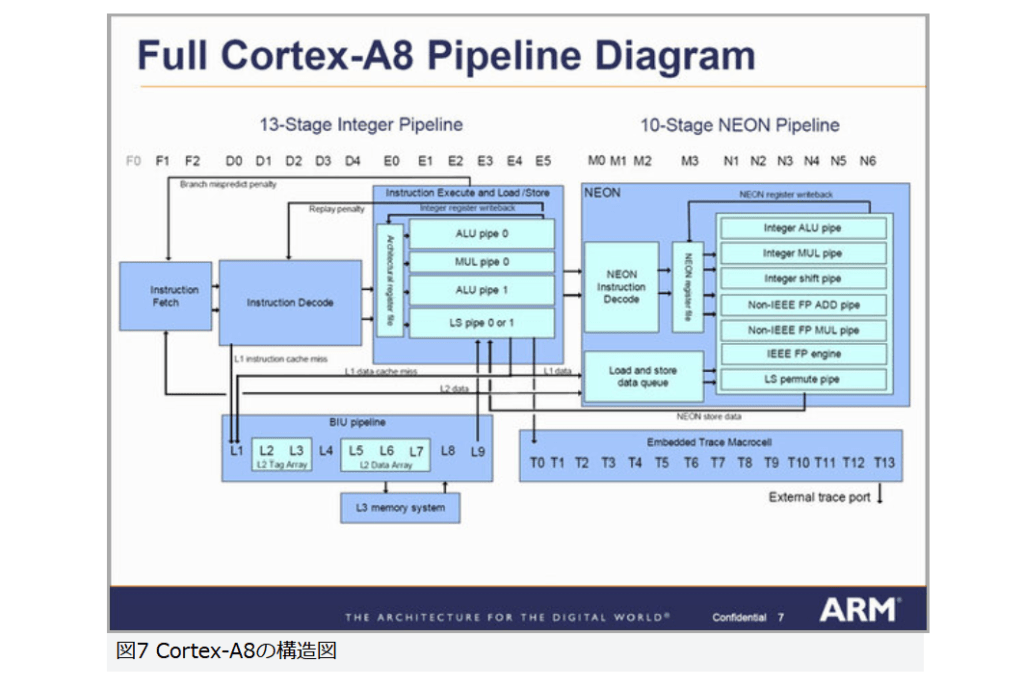
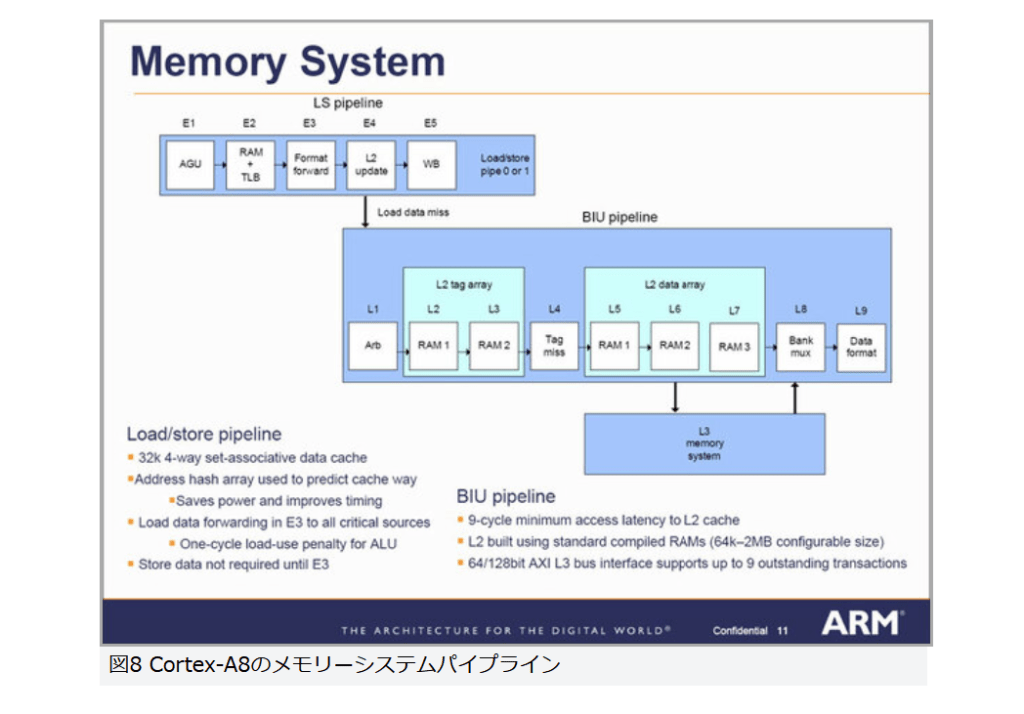
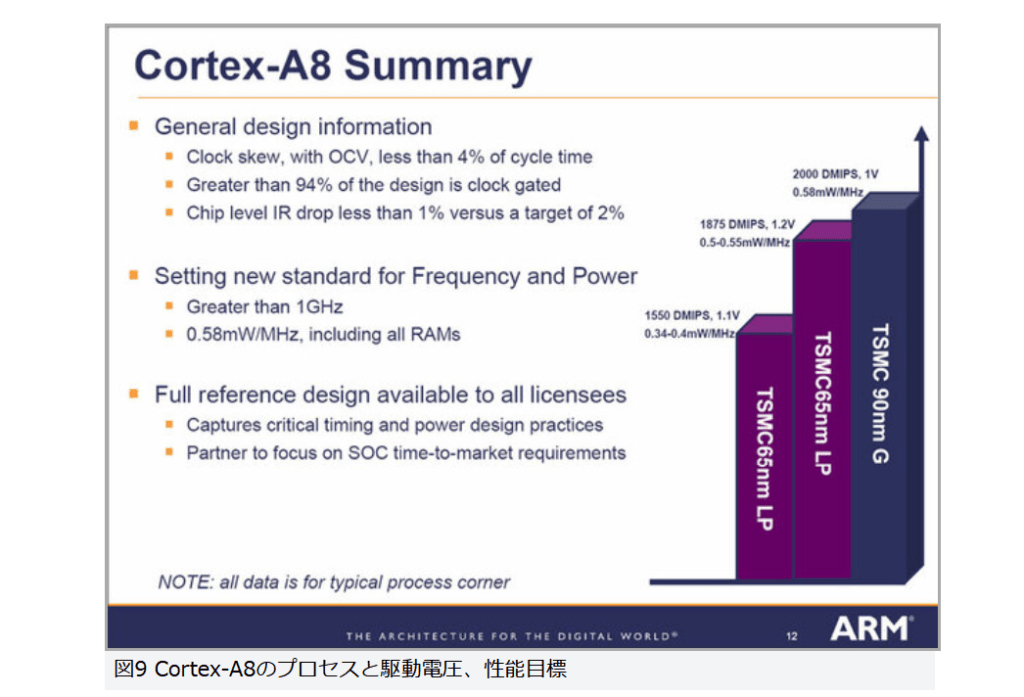
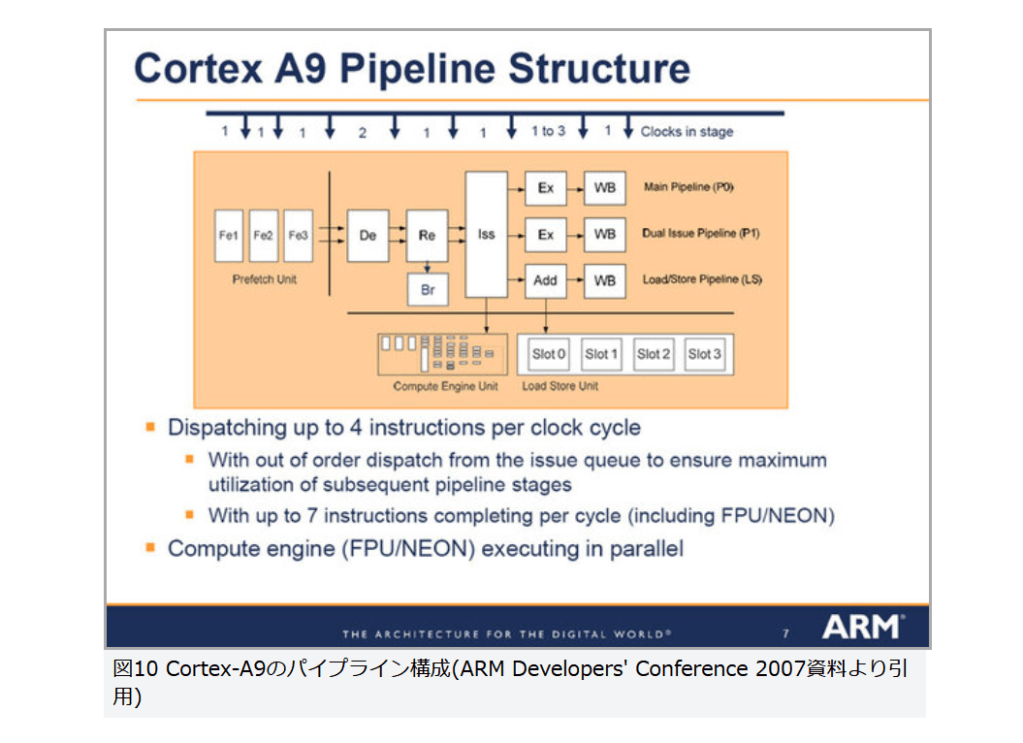
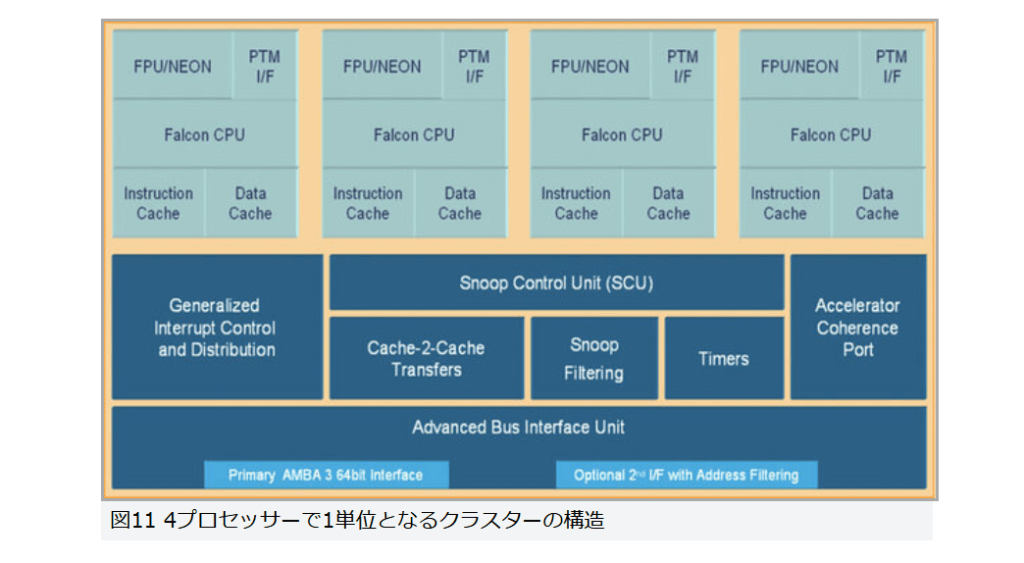
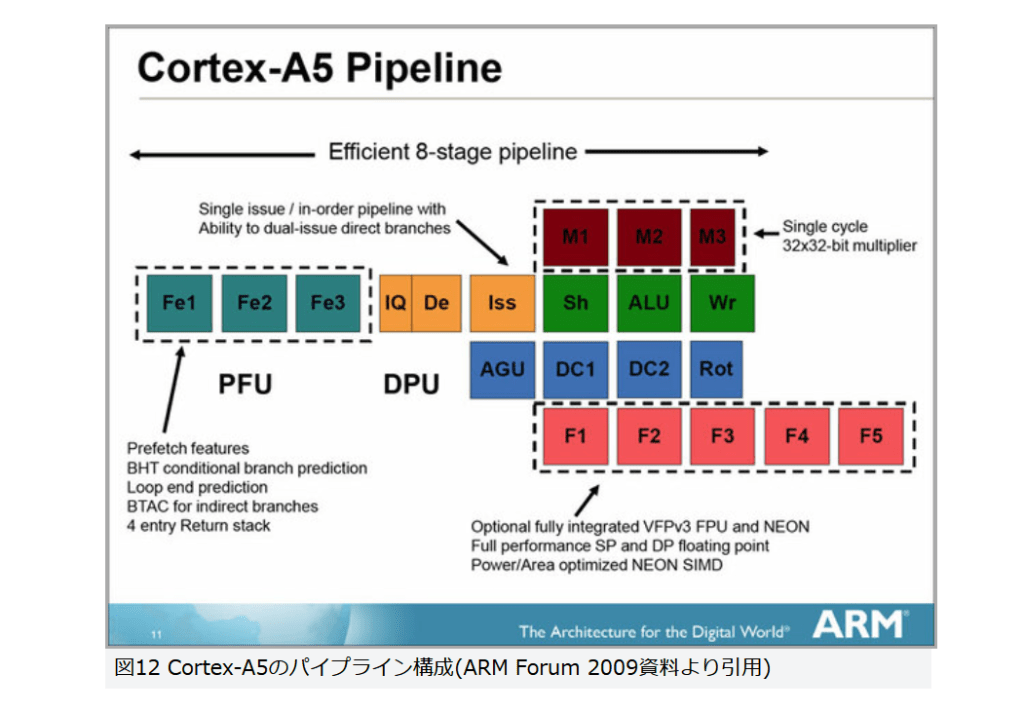
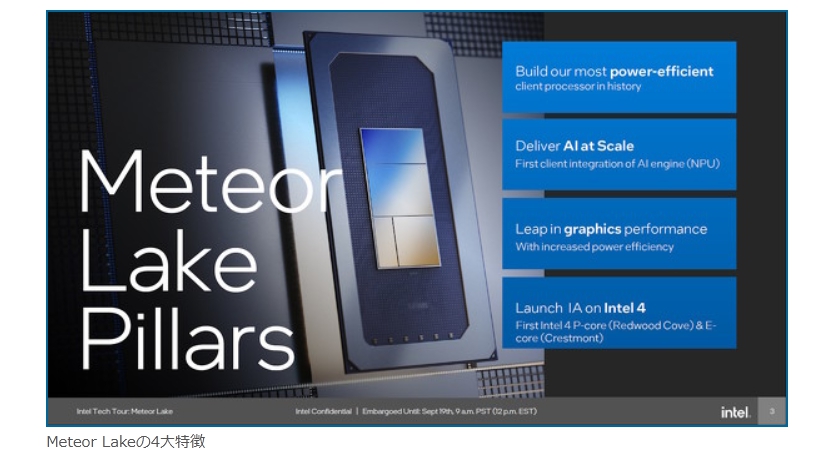
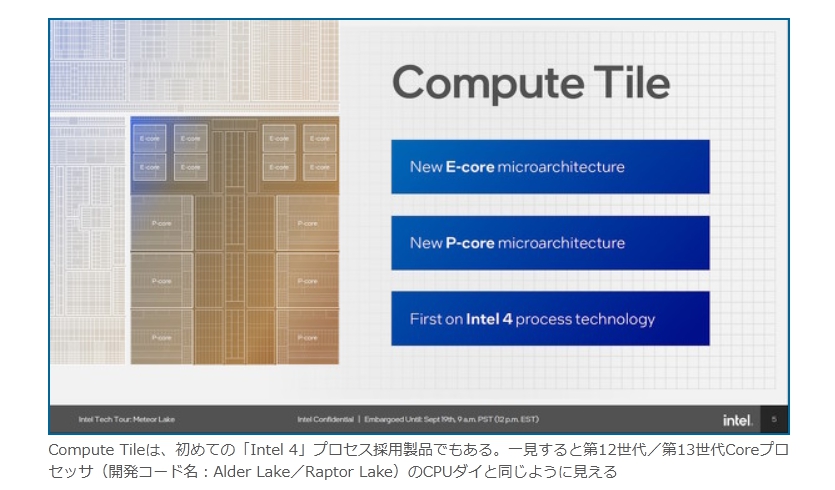
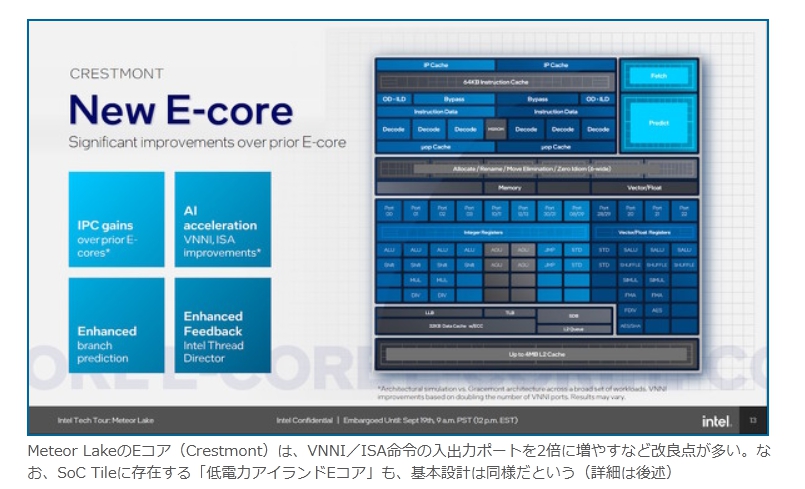
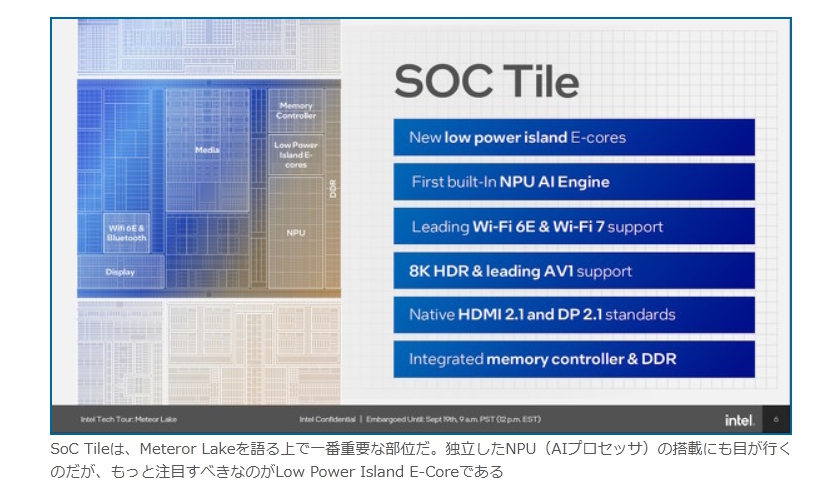
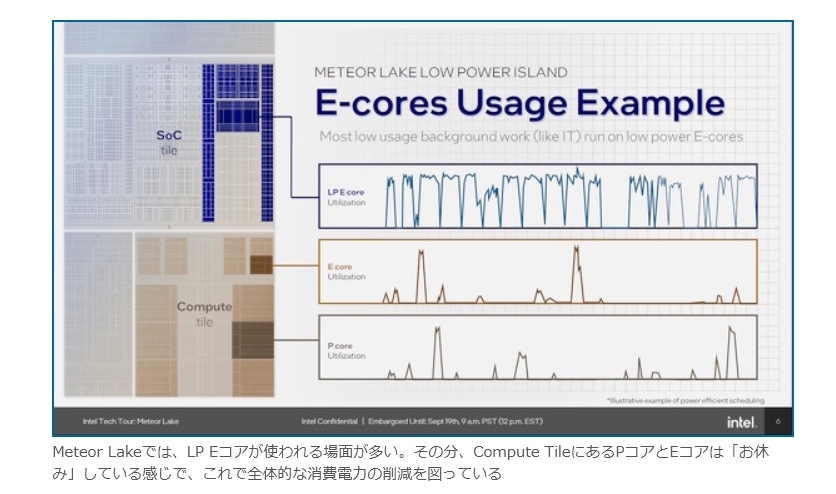
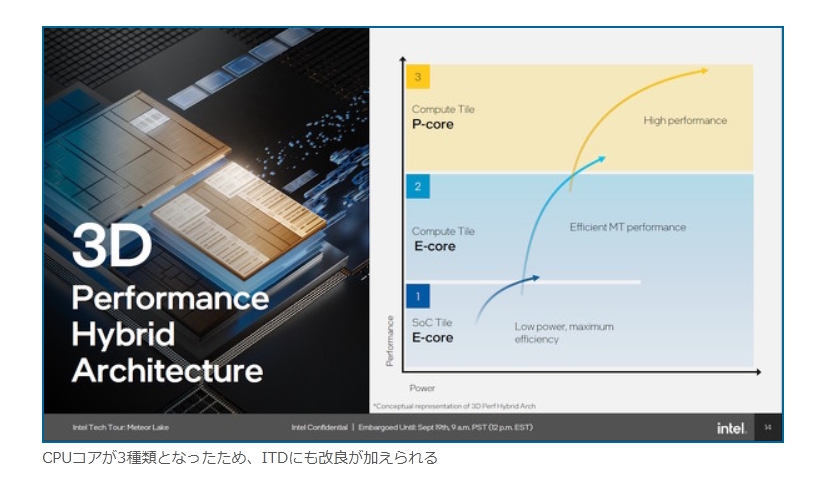
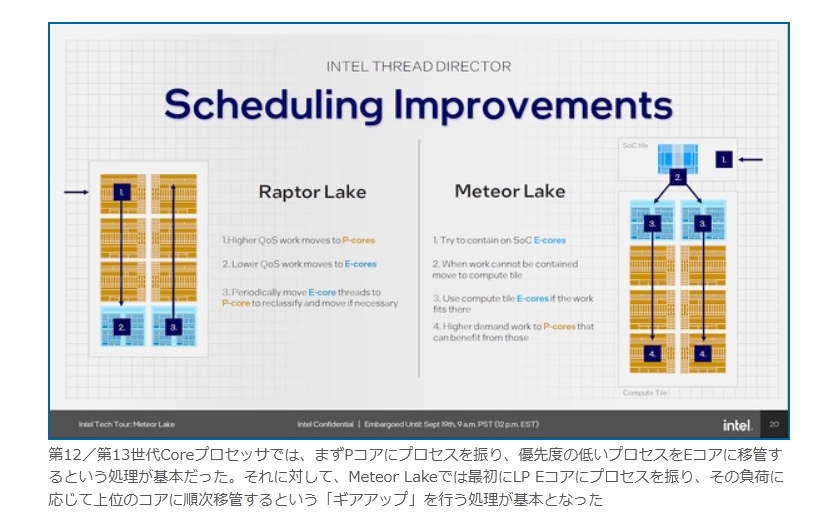
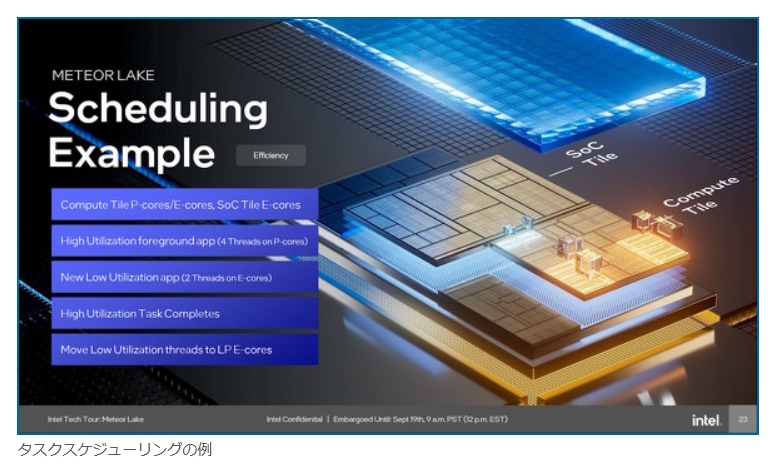
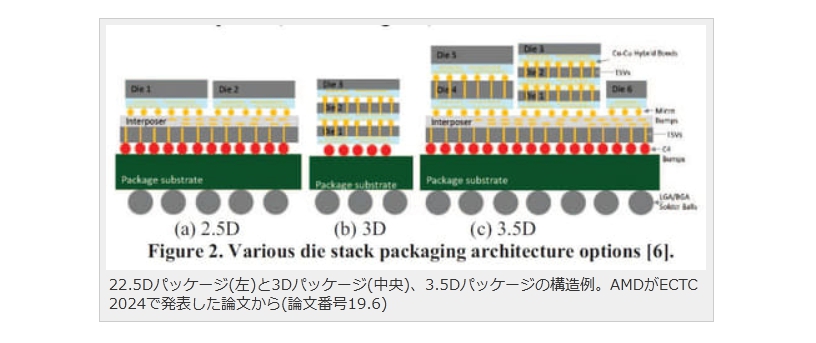
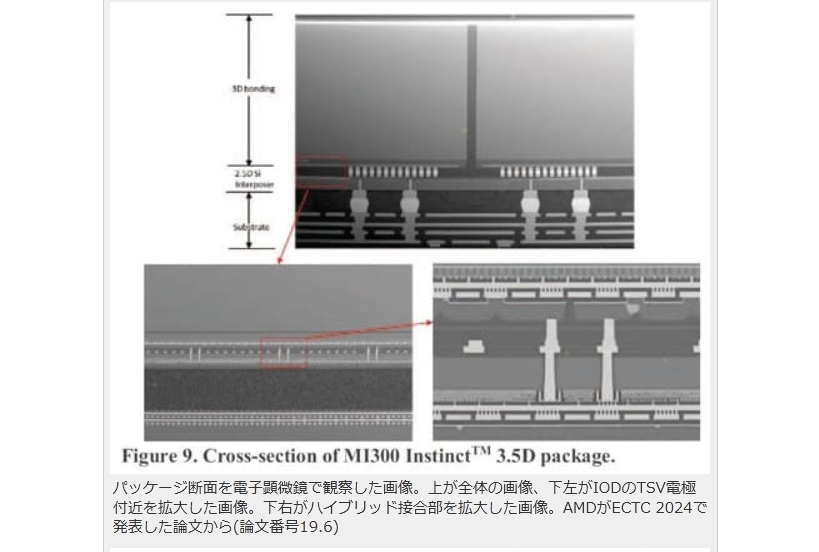
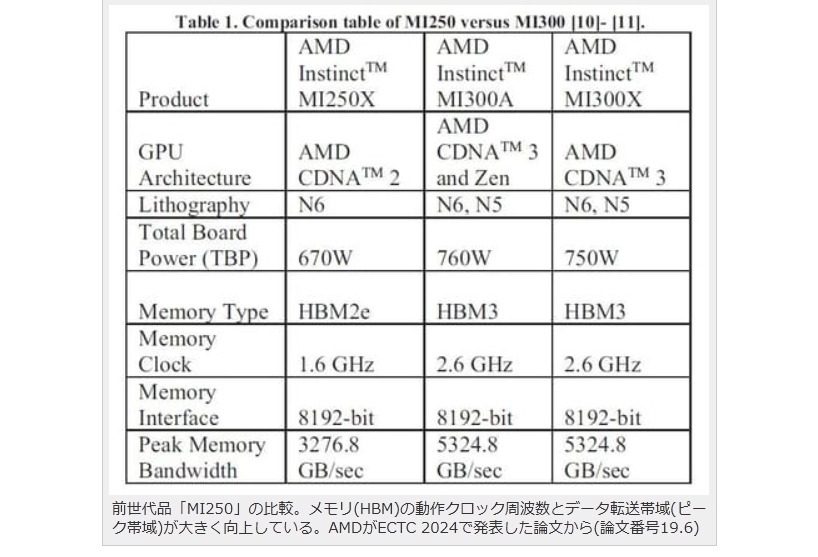
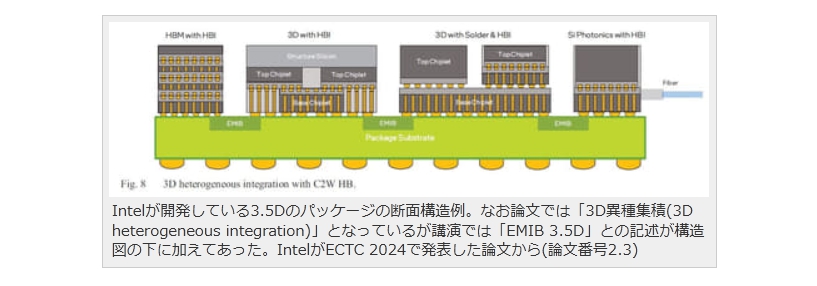
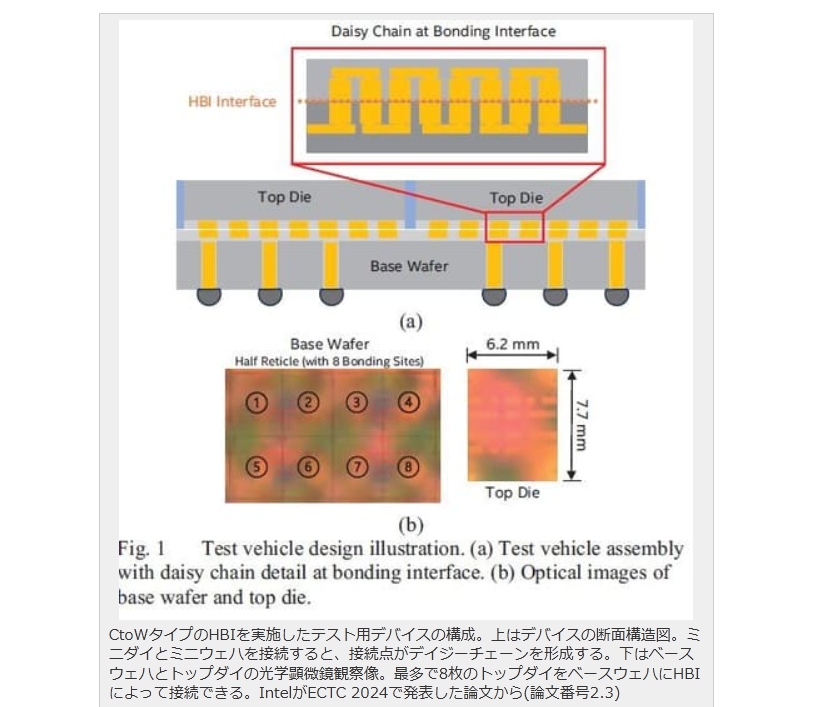
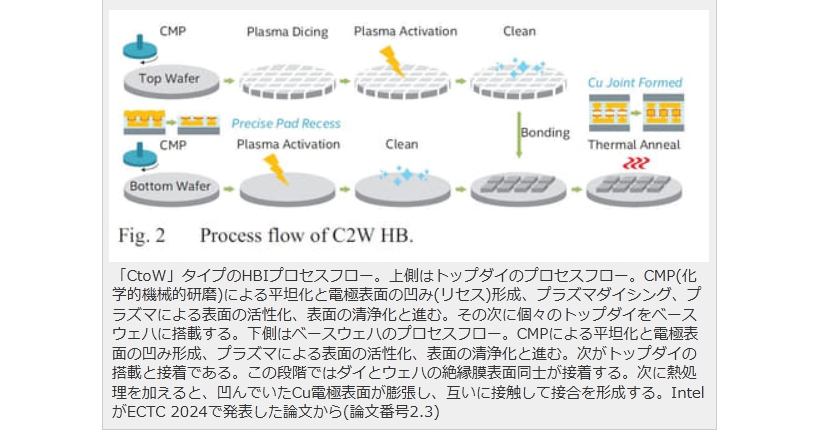
現在パーソナルコンピュータでデファクトスタンダードとなっているx86アーキテクチャでは、1993年のPentiumで2実行ユニットのインオーダ実行型のスーパースカラーを実現し、その後の”P6″(Pentium Pro と Pentium II)以降で3実行ユニットのアウトオブオーダ実行型スーパースカラーに発展した。2008年現在のIA-32アーキテクチャは単一コア当り5実行ユニットのアウトオブオーダ実行型スーパースカラーで、平均IPCは3以上を達成している。
既存のバイナリの実行プログラムの持つ並列性にはばらつきがある。ものによっては命令間の依存が全く無く、常に並列に実行可能なこともある。逆に依存関係が多く、並列性がほとんどない場合もある。例えば、a = b + c; d = e + f という命令列は依存関係がないため、並列に実行可能である。しかし、a = b + c; b = e + f という命令列は依存関係があるため、並列に実行することはできない。
同時に実行可能な命令数が増えると、依存関係をチェックするコストも急激に増大する。また、そのチェックをCPUのクロックに合わせて実行時に行わなければならないという事実が事態をさらに悪化させる。研究によれば、命令の種類を n、同時実行可能な命令数を k としたとき、依存関係チェックの回路規模は n k {\displaystyle n^{k}}、時間は k 2 log n {\displaystyle k^{2}\log n} かかるとされている。数学的には、この問題は順列における組合せ数学の問題である。
^ “super-scalar organization in which multiple execution units operate essentially independently.” AMD. (2020). Software Optimization Guide for AMD EPYC™ 7003 Processors. rev. 3.00. 関連項目 アウト・オブ・オーダー実行 投機的実行/積極的実行 EPICアーキテクチャ スーパーパイプライン 同時マルチスレッディング パイプライン処理 参考文献
出典は列挙するだけでなく、脚注などを用いてどの記述の情報源であるかを明記してください。 記事の信頼性向上にご協力をお願いいたします。(2023年1月) マイク・ジョンソン著、村上和彰監訳、『スーパスカラ・プロセッサ- マイクロプロセッサ設計における定量的アプローチ -』、日経BP社、ISBN 4-8227-1002-5 (原著 Mike Johnson, Superscalar Microprocessor Design, Prentice-Hall, 1991, ISBN 0-13-875634-1) Sorin Cotofana, Stamatis Vassiliadis, “On the Design Complexity of the Issue Logic of Superscalar Machines”, EUROMICRO 1998: 10277-10284 Steven McGeady, “The 1960CA SuperScalar Implementation of the 80960 Architecture”, IEEE 1990, pp. 232-240 Steven McGeady, et al., “Performance Enhancements in the Superscalar i960MM Embedded Microprocessor,” ACM Proceedings of the 1991 Conference on Computer Architecture (Compcon), 1991, pp. 4-7 外部リンク Eager Execution / Dual Path / Multiple Path by Mark Smotherman 表話編歴 CPUテクノロジー 表話編歴 並列計算 カテゴリ: スーパースカラー・マイクロプロセッサコンピュータアーキテクチャCPU並列コンピューティング 最終更新 2025年5月18日 (日) 05:20 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』
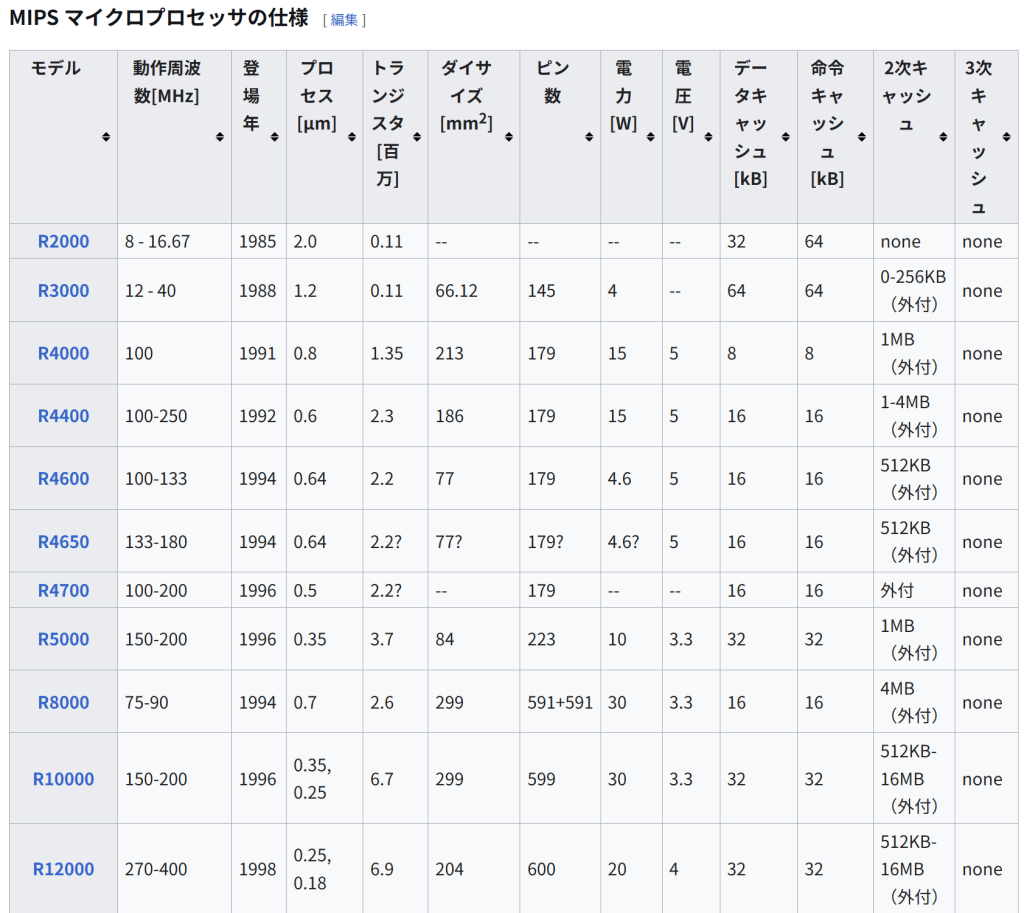
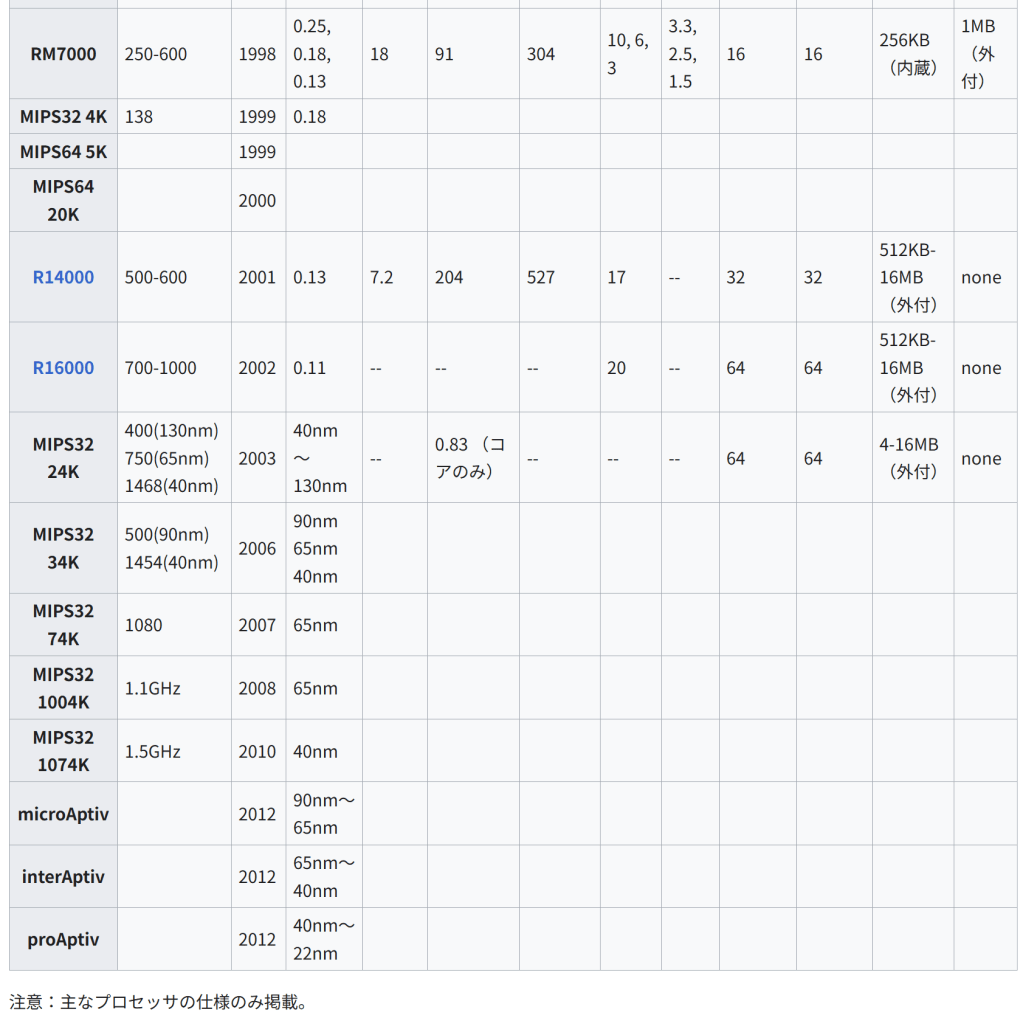
1999年、ミップス・テクノロジーズ社はライセンス体系を整理し、32ビットのMIPS32(MIPS II にそれ以降の新規機能を追加したものだが、後に遅延分岐系のbranch likely は強い非推奨となり、将来の削除が予告された[13])と64ビットのMIPS64(MIPS V ベース)に分けた。
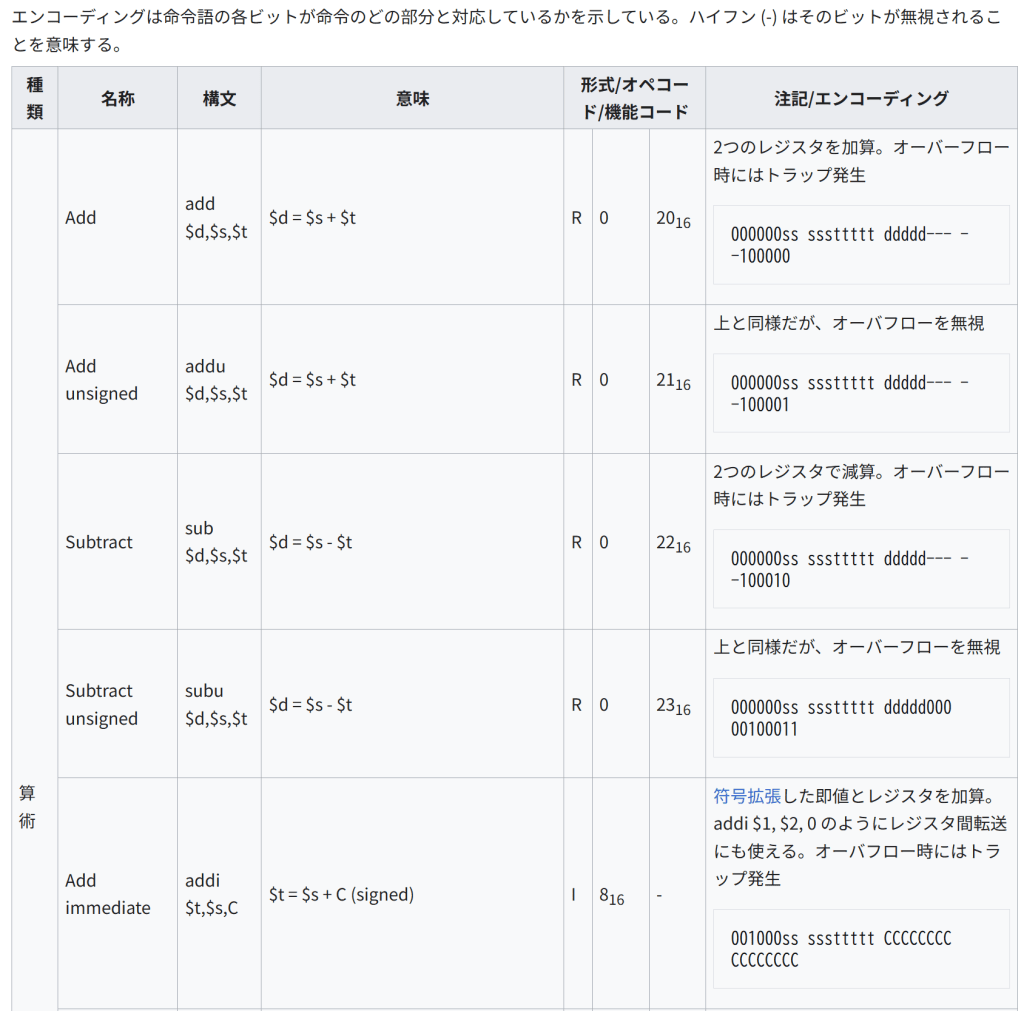
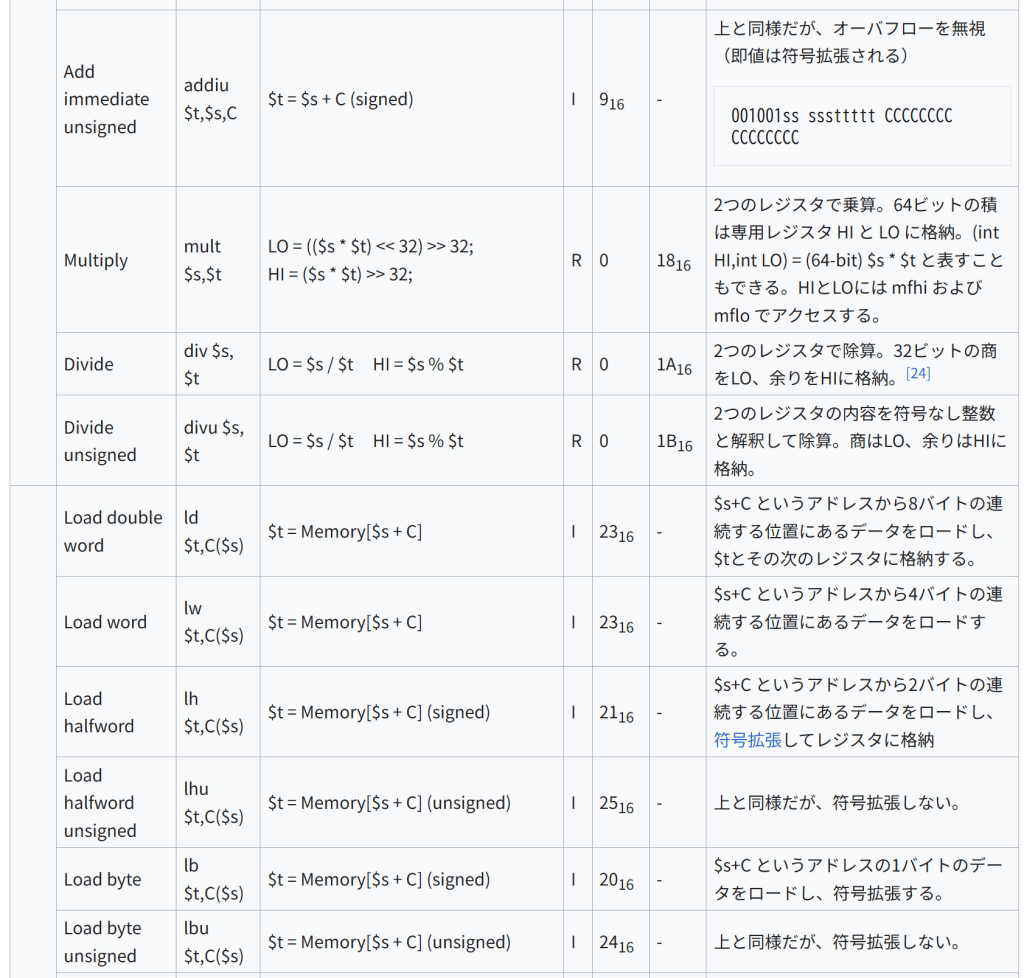
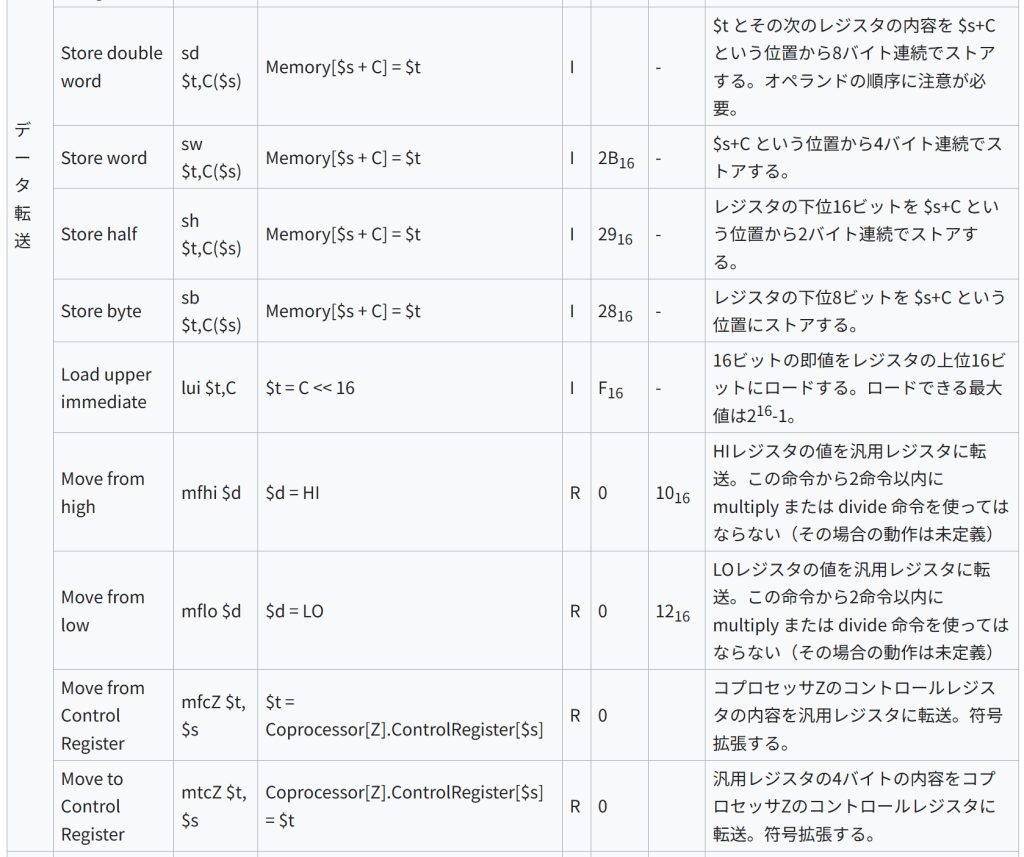
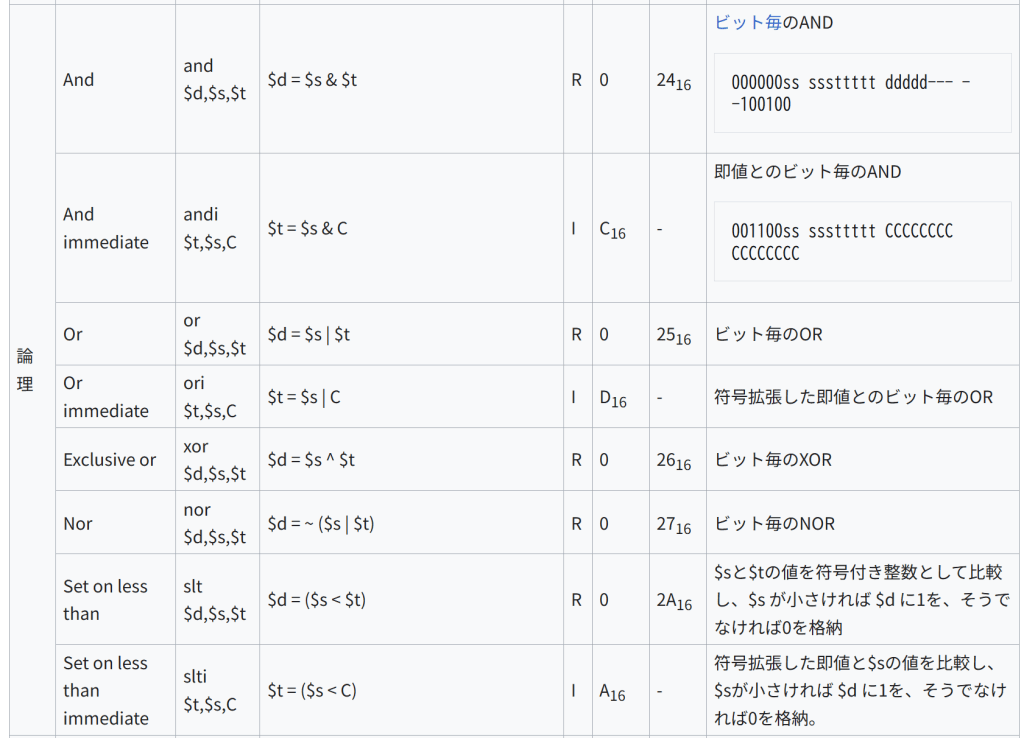
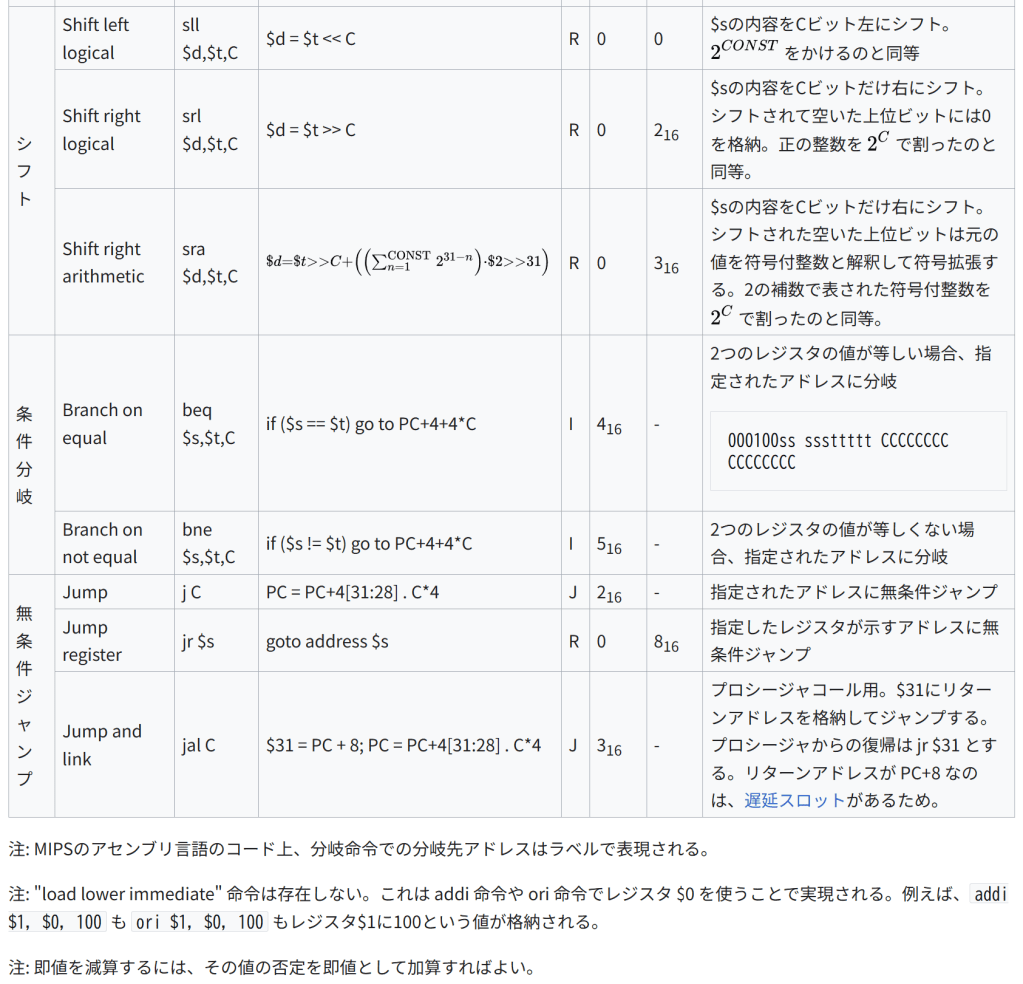
種類 名称 構文 意味 形式/オペコード/機能コード 注記/エンコーディング 算術 Add add $d,$s,$t $d = $s + $t R 0 2016 2つのレジスタを加算。オーバーフロー時にはトラップ発生 000000ss sssttttt ddddd— –100000 Add unsigned addu $d,$s,$t $d = $s + $t R 0 2116 上と同様だが、オーバフローを無視 000000ss sssttttt ddddd— –100001 Subtract sub $d,$s,$t $d = $s – $t R 0 2216 2つのレジスタで減算。オーバーフロー時にはトラップ発生 000000ss sssttttt ddddd— –100010 Subtract unsigned subu $d,$s,$t $d = $s – $t R 0 2316 上と同様だが、オーバーフローを無視 000000ss sssttttt ddddd000 00100011 Add immediate addi $t,$s,C $t = $s + C (signed) I 816 – 符号拡張した即値とレジスタを加算。addi $1, $2, 0 のようにレジスタ間転送にも使える。オーバフロー時にはトラップ発生 001000ss sssttttt CCCCCCCC CCCCCCCC Add immediate unsigned addiu $t,$s,C $t = $s + C (signed) I 916 – 上と同様だが、オーバフローを無視(即値は符号拡張される) 001001ss sssttttt CCCCCCCC CCCCCCCC Multiply mult $s,$t LO = (($s * $t) << 32) >> 32; HI = ($s * $t) >> 32; R 0 1816 2つのレジスタで乗算。64ビットの積は専用レジスタ HI と LO に格納。(int HI,int LO) = (64-bit) $s * $t と表すこともできる。HIとLOには mfhi および mflo でアクセスする。 Divide div $s, $t LO = $s / $t HI = $s % $t R 0 1A16 2つのレジスタで除算。32ビットの商をLO、余りをHIに格納。[24] Divide unsigned divu $s, $t LO = $s / $t HI = $s % $t R 0 1B16 2つのレジスタの内容を符号なし整数と解釈して除算。商はLO、余りはHIに格納。 データ転送 Load double word ld $t,C($s) $t = Memory[$s + C] I 2316 – $s+C というアドレスから8バイトの連続する位置にあるデータをロードし、$tとその次のレジスタに格納する。 Load word lw $t,C($s) $t = Memory[$s + C] I 2316 – $s+C というアドレスから4バイトの連続する位置にあるデータをロードする。 Load halfword lh $t,C($s) $t = Memory$s + C I 2116 – $s+C というアドレスから2バイトの連続する位置にあるデータをロードし、符号拡張してレジスタに格納 Load halfword unsigned lhu $t,C($s) $t = Memory$s + C I 2516 – 上と同様だが、符号拡張しない。 Load byte lb $t,C($s) $t = Memory$s + C I 2016 – $s+C というアドレスの1バイトのデータをロードし、符号拡張する。 Load byte unsigned lbu $t,C($s) $t = Memory$s + C I 2416 – 上と同様だが、符号拡張しない。 Store double word sd $t,C($s) Memory[$s + C] = $t I – $t とその次のレジスタの内容を $s+C という位置から8バイト連続でストアする。オペランドの順序に注意が必要。 Store word sw $t,C($s) Memory[$s + C] = $t I 2B16 – $s+C という位置から4バイト連続でストアする。 Store half sh $t,C($s) Memory[$s + C] = $t I 2916 – レジスタの下位16ビットを $s+C という位置から2バイト連続でストアする。 Store byte sb $t,C($s) Memory[$s + C] = $t I 2816 – レジスタの下位8ビットを $s+C という位置にストアする。 Load upper immediate lui $t,C $t = C << 16 I F16 – 16ビットの即値をレジスタの上位16ビットにロードする。ロードできる最大値は216-1。 Move from high mfhi $d $d = HI R 0 1016 HIレジスタの値を汎用レジスタに転送。この命令から2命令以内に multiply または divide 命令を使ってはならない(その場合の動作は未定義) Move from low mflo $d $d = LO R 0 1216 LOレジスタの値を汎用レジスタに転送。この命令から2命令以内に multiply または divide 命令を使ってはならない(その場合の動作は未定義) Move from Control Register mfcZ $t, $s $t = Coprocessor[Z].ControlRegister[$s] R 0 コプロセッサZのコントロールレジスタの内容を汎用レジスタに転送。符号拡張する。 Move to Control Register mtcZ $t, $s Coprocessor[Z].ControlRegister[$s] = $t R 0 汎用レジスタの4バイトの内容をコプロセッサZのコントロールレジスタに転送。符号拡張する。 論理 And and $d,$s,$t $d = $s & $t R 0 2416 ビット毎のAND 000000ss sssttttt ddddd— –100100 And immediate andi $t,$s,C $t = $s & C I C16 – 即値とのビット毎のAND 001100ss sssttttt CCCCCCCC CCCCCCCC Or or $d,$s,$t $d = $s | $t R 0 2516 ビット毎のOR Or immediate ori $t,$s,C $t = $s | C I D16 – 符号拡張した即値とのビット毎のOR Exclusive or xor $d,$s,$t $d = $s ^ $t R 0 2616 ビット毎のXOR Nor nor $d,$s,$t $d = ~ ($s | $t) R 0 2716 ビット毎のNOR Set on less than slt $d,$s,$t $d = ($s < $t) R 0 2A16 $sと$tの値を符号付き整数として比較し、$s が小さければ $d に1を、そうでなければ0を格納 Set on less than immediate slti $t,$s,C $t = ($s < C) I A16 – 符号拡張した即値と$sの値を比較し、$sが小さければ $d に1を、そうでなければ0を格納。 シフト Shift left logical sll $d,$t,C $d = $t << C R 0 0 $sの内容をCビット左にシフト。 2 C O N S T {\displaystyle 2^{CONST}} をかけるのと同等 Shift right logical srl $d,$t,C $d = $t >> C R 0 216 $sの内容をCビットだけ右にシフト。シフトされて空いた上位ビットには0を格納。正の整数を 2 C {\displaystyle 2^{C}} で割ったのと同等。 Shift right arithmetic sra $d,$t,C $
d
$ t
> C + ( ( ∑
n
1 CONST 2 31 − n ) ⋅ $ 2 > 31 ) {\displaystyle \scriptstyle \$d=\$t>>C+\left(\left(\sum _{n=1}^{\text{CONST}}2^{31-n}\right)\cdot \$2>>31\right)} R 0 316 $sの内容をCビットだけ右にシフト。シフトされた空いた上位ビットは元の値を符号付整数と解釈して符号拡張する。2の補数で表された符号付整数を 2 C {\displaystyle 2^{C}} で割ったのと同等。 条件分岐 Branch on equal beq $s,$t,C if ($s == $t) go to PC+4+4C I 416 – 2つのレジスタの値が等しい場合、指定されたアドレスに分岐 000100ss sssttttt CCCCCCCC CCCCCCCC Branch on not equal bne $s,$t,C if ($s != $t) go to PC+4+4C I 516 – 2つのレジスタの値が等しくない場合、指定されたアドレスに分岐 無条件ジャンプ Jump j C PC = PC+4[31:28] . C4 J 216 – 指定されたアドレスに無条件ジャンプ Jump register jr $s goto address $s R 0 816 指定したレジスタが示すアドレスに無条件ジャンプ Jump and link jal C $31 = PC + 8; PC = PC+4[31:28] . C4 J 316 – プロシージャコール用。$31にリターンアドレスを格納してジャンプする。プロシージャからの復帰は jr $31 とする。リターンアドレスが PC+8 なのは、遅延スロットがあるため。 注: MIPSのアセンブリ言語のコード上、分岐命令での分岐先アドレスはラベルで表現される。
注: “load lower immediate” 命令は存在しない。これは addi 命令や ori 命令でレジスタ $0 を使うことで実現される。例えば、addi $1, $0, 100 も ori $1, $0, 100 もレジスタ$1に100という値が格納される。
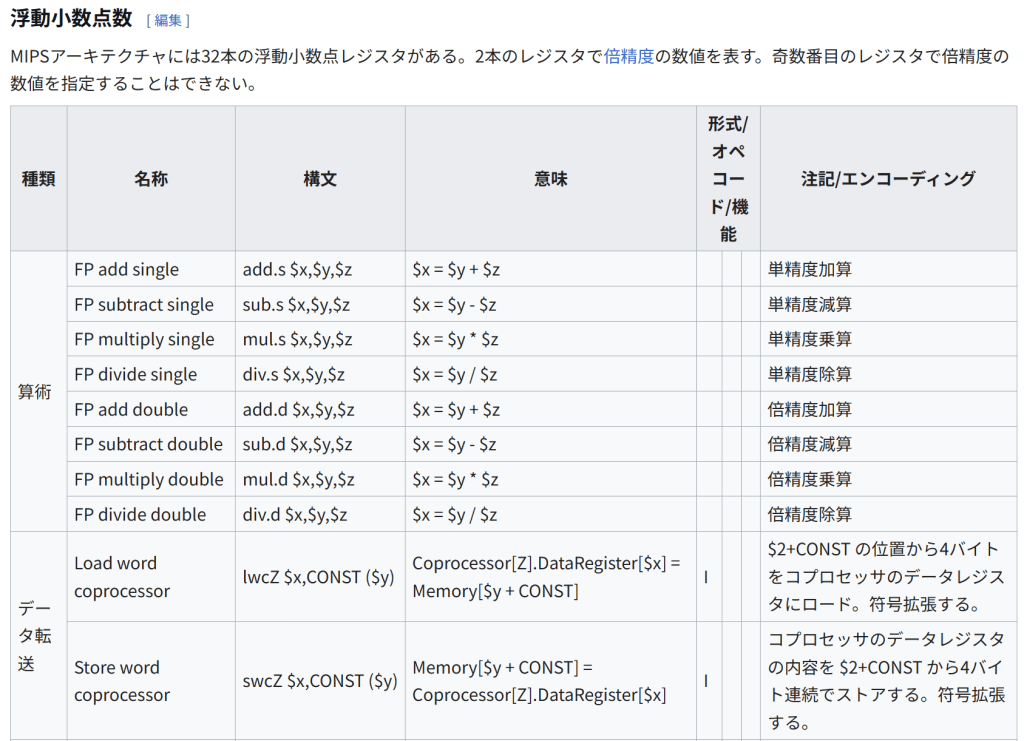
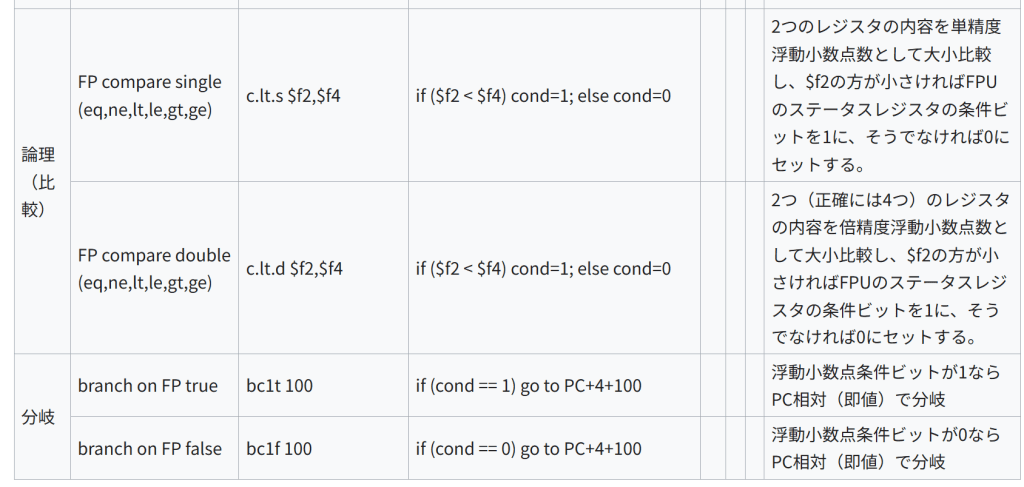
種類 名称 構文 意味 形式/オペコード/機能 注記/エンコーディング 算術 FP add single add.s $x,$y,$z $x = $y + $z 単精度加算 FP subtract single sub.s $x,$y,$z $x = $y – $z 単精度減算 FP multiply single mul.s $x,$y,$z $x = $y * $z 単精度乗算 FP divide single div.s $x,$y,$z $x = $y / $z 単精度除算 FP add double add.d $x,$y,$z $x = $y + $z 倍精度加算 FP subtract double sub.d $x,$y,$z $x = $y – $z 倍精度減算 FP multiply double mul.d $x,$y,$z $x = $y * $z 倍精度乗算 FP divide double div.d $x,$y,$z $x = $y / $z 倍精度除算 データ転送 Load word coprocessor lwcZ $x,CONST ($y) Coprocessor[Z].DataRegister[$x] = Memory[$y + CONST] I $2+CONST の位置から4バイトをコプロセッサのデータレジスタにロード。符号拡張する。 Store word coprocessor swcZ $x,CONST ($y) Memory[$y + CONST] = Coprocessor[Z].DataRegister[$x] I コプロセッサのデータレジスタの内容を $2+CONST から4バイト連続でストアする。符号拡張する。 論理(比較) FP compare single (eq,ne,lt,le,gt,ge) c.lt.s $f2,$f4 if ($f2 < $f4) cond=1; else cond=0 2つのレジスタの内容を単精度浮動小数点数として大小比較し、$f2の方が小さければFPUのステータスレジスタの条件ビットを1に、そうでなければ0にセットする。 FP compare double (eq,ne,lt,le,gt,ge) c.lt.d $f2,$f4 if ($f2 < $f4) cond=1; else cond=0 2つ(正確には4つ)のレジスタの内容を倍精度浮動小数点数として大小比較し、$f2の方が小さければFPUのステータスレジスタの条件ビットを1に、そうでなければ0にセットする。 分岐 branch on FP true bc1t 100 if (cond == 1) go to PC+4+100 浮動小数点条件ビットが1ならPC相対(即値)で分岐 branch on FP false bc1f 100 if (cond == 0) go to PC+4+100 浮動小数点条件ビットが0ならPC相対(即値)で分岐 擬似命令 MIPSアセンブラは以下の命令を受け付けるが、これらは実際にはMIPSの命令セットに存在しない。アセンブラが同等の命令列に変換し、その際に $1 ($at) レジスタを一時的に使用することがある。
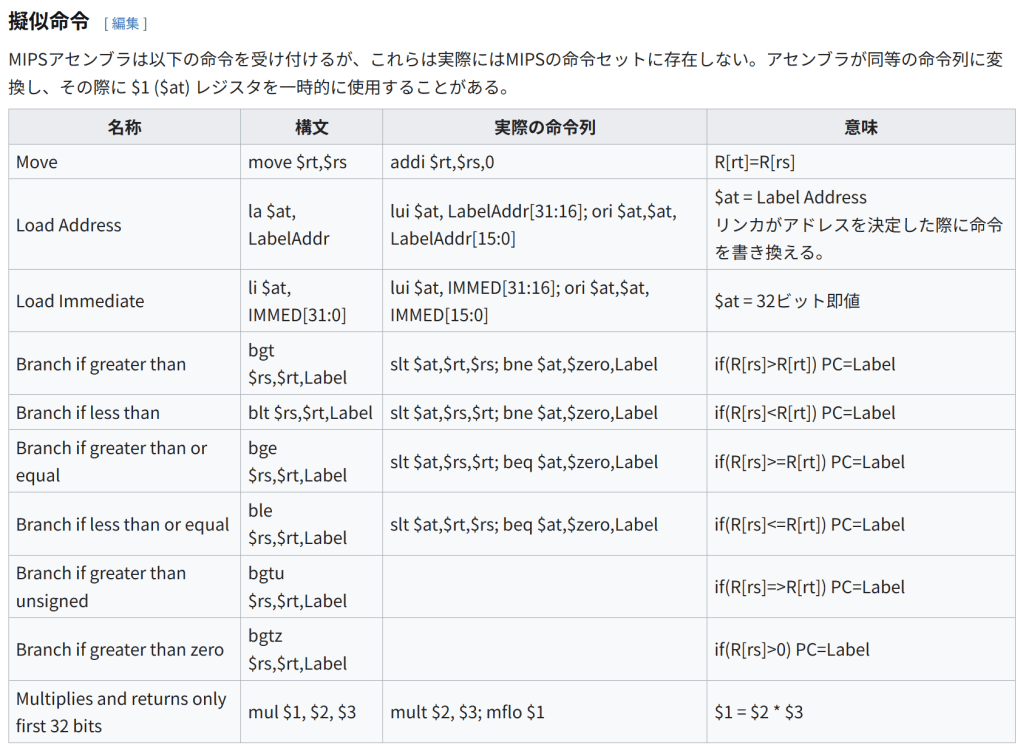
名称 構文 実際の命令列 意味 Move move $rt,$rs addi $rt,$rs,0 R[rt]=R[rs] Load Address la $at, LabelAddr lui $at, LabelAddr[31:16]; ori $at,$at, LabelAddr[15:0] $at = Label Address リンカがアドレスを決定した際に命令を書き換える。 Load Immediate li $at, IMMED[31:0] lui $at, IMMED[31:16]; ori $at,$at, IMMED[15:0] $at = 32ビット即値 Branch if greater than bgt $rs,$rt,Label slt $at,$rt,$rs; bne $at,$zero,Label if(R[rs]>R[rt]) PC=Label Branch if less than blt $rs,$rt,Label slt $at,$rs,$rt; bne $at,$zero,Label if(R[rs]=R[rt]) PC=Label Branch if less than or equal ble $rs,$rt,Label slt $at,$rt,$rs; beq $at,$zero,Label if(R[rs]<=R[rt]) PC=Label Branch if greater than unsigned bgtu $rs,$rt,Label if(R[rs]=>R[rt]) PC=Label Branch if greater than zero bgtz $rs,$rt,Label if(R[rs]>0) PC=Label Multiplies and returns only first 32 bits mul $1, $2, $3 mult $2, $3; mflo $1 $1 = $2 * $3 その他の命令 NOP命令。通常 sll $0,$0,0 という命令を使い、その機械語コードは 0x00000000 となる。 break命令。デバッガでのブレークポイント設定で使用する。 syscall命令。オペレーティングシステムのシステムコールに使われ、ユーザーモードからカーネルモードに移行する。 コンパイラのレジスタ使用規則 ハードウェアのアーキテクチャにより、以下のことが定められている。
より実用的なフリーなエミュレータとしてGXemulやQEMUプロジェクトのものがある。MIPS III および IV のプロセッサをエミュレートでき、コンピュータシステム全体のエミュレートも可能である。
商用のシミュレータは主に組み込み用MIPSプロセッサを対象としたものが存在する。例えば、Virtutech Simics (MIPS 4Kc and 5Kc, PMC RM9000, QED RM7000)、VaST Systems (R3000, R4000)、CoWare (MIPS4KE, MIPS24K, MIPS25Kf, MIPS34K) がある。
脚注 [脚注の使い方] 注釈 ^ MIPS社のR4000が登場する頃には、DEC社は自社製RISCマイクロプロセッサAlphaを完成させてこれに切り替えた。 ^ R4000は、スーパーパイプラインを世界で最初に導入した市販のマイクロプロセッサである。しかし、これによって、”Microprocessor with Interlocked Pipeline Stages” パイプライン・ステージがインターロックされるマイクロプロセッサと揶揄されることになった。 出典 ^ “MIPS32 Architecture”. ミップス・テクノロジーズ. 2009年5月27日閲覧。 ^ “MIPS64 Architecture”. ミップス・テクノロジーズ. 2009年5月27日閲覧。 ^ “MIPS-3D ASE”. ミップス・テクノロジーズ. 2009年5月27日閲覧。 ^ “MIPS16e”. ミップス・テクノロジーズ. 2021年1月14日閲覧。 ^ “MIPS MT ASE”. ミップス・テクノロジーズ. 2009年5月27日閲覧。 ^ University of California, Davis. “ECS 142 (Compilers) References & Tools page”. 2009年5月28日閲覧。 ^ Rubio, Victor P. “A FPGA Implementation of a MIPS RISC Processor for Computer Architecture Education”. New Mexico State University. 2011年12月22日閲覧。 ^ a b 神保進一著、『マイクロプロセッサ テクノロジ』、日経BP社、1999年12月6日第1版第1刷発行、ISBN 4822209261 ^ Morgan Kaufmann Publishers, Computer Organization and Design, David A. Patterson & John L. Hennessy, Edition 3, ISBN 1-55860-604-1, page 63 ^ “Earl Killian”. Paravirtual. (2010年11月26日) 2010年11月26日閲覧。 ⚠ ^ “S-1 Supercomputer Alumni: Earl Killian”. Clemson University. (2005年6月28日) 2010年11月26日閲覧. “Earl Killian’s early work w… As MIPS’s Director of Architecture, he designed the MIPS III 64-bit instruction-set extension, and led the work on the R4000 microarchitecture. He was a cofounder of QED, which created the R4600 and R5000 MIPS processors. Most recently he was chief architect at Tensilica working on configurable/extensible processors.” ⚠ ^ Jochen Liedtke(1995). On micro kernel construction. 15th Symposium on Operating Systems Principles, Copper Mountain Resort, Colorado. ^ “MIPS® Architecture For Programmers Volume II-A: The MIPS32® Instruction Set Document Number: MD00086 Revision 5.04 December 11, 2013”. p. 41. 2023年12月9日閲覧。 ^ SGI announcing the end of MIPS – ウェイバックマシン(2008年3月7日アーカイブ分) ^ CPUコアベンダからの脱却 – 変貌するMIPS Technologiesの実像を探る ^ http://www.mdronline.com/mpr/h/2006/0626/202602.html China’s Microprocessor Dilemma ^ China’s Institute of Computing Technology Licenses Industry-Standard MIPS Architectures ^ “LinuxDevices article about the Municator”. 2012年12月16日時点のオリジナルよりアーカイブ。2010年12月12日閲覧。 ^ “Yeelong Specs”. 2012年12月10日時点のオリジナルよりアーカイブ。2010年12月12日閲覧。 (LinuxDevices, Oct. 22, 2008) ^ “Silicon Graphics Introduces Enhanced MIPS Architecture to Lead the Interactive Digital Revolution”. Silicon Graphics, Inc. (1996年10月21日). 2011年2月25日閲覧。 ^ a b Gwennap, Linley (18 November 1996). “Digital, MIPS Add Multimedia Extensions”. Microprocessor Report. pp. 24–28. ^ NEC Offers Two High Cost Performance 64-bit RISC Microprocessors ^ 編集人 山形孝雄「PMC-Sierra RMシリーズの概要とRM7900&RM900x2Gの詳細」『Interface2004年7月号』CQ出版社、2004年7月1日、77-88頁。ISSN 0387-9569。 ^ a b MIPS R3000 Instruction Set Summary ^ MIPS Instruction Reference ^ Welcome Page | Open Virtual Platforms ^ Welcome to Imperas | Imperas ^ James Larus. “SPIM MIPS Simulator”. 2007年3月4日閲覧。 ^ EduMIPS64 ^ MARS MIPS simulator – Missouri State University 参考文献 David A. Patterson and John L. Hennessy (2007). Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann Publishers. ISBN 978-0-12-370606-5 David A. Patterson and John L. Hennessy; 成田光彰 (2006). コンピュータの構成と設計 第3版(上) ハードウエアとソフトウエアのインタフェース. 日経BP. ISBN 4-8222-8266-X David A. Patterson and John L. Hennessy; 成田光彰 (2006). コンピュータの構成と設計 第3版(下) ハードウエアとソフトウエアのインタフェース. 日経BP. ISBN 4-8222-8267-8 プロセッサを中心としたコンピュータの設計全般に関する書籍で、命令セットの例としてMIPSアーキテクチャを取り上げている。MIPS開発者であるジョン・L・ヘネシーも著者の一人である。 Dominic Sweetman. See MIPS Run. Morgan Kaufmann Publishers. ISBN 1-55860-410-3 MIPSアーキテクチャについての決定版的な本。ハードウェアアーキテクチャだけでなく、コンパイラやOSについても詳述している。 Farquhar, Erin; Philip Bunce. MIPS Programmer’s Handbook. Morgan Kaufmann Publishers. ISBN 1-55860-297-6 関連項目 μClinux PlayStation – CPUとしてR3000Aを搭載。 外部リンク MIPS Architectures at MIPS Technologies Full overview of MIPS architecture Patterson & Hennessy – Appendix A Summary of MIPS assembly language MIPS Instruction reference MARS (MIPS Assembler and Runtime Simulator) MIPS processor images and descriptions at cpu-collection.de A programmed introduction to MIPS assembly Mips bitshift operators MIPS software user’s manual MIPS Architecture history diagram MIPS Open initiative # 2018年12月17日(米国時間)にWave Computing社はMIPS Open(MIPS命令セットアーキテクチャ(ISA)のオープンソース化プログラム)を発表。 表話編歴 MIPSマイクロプロセッサ 表話編歴 プロセッサアーキテクチャ 典拠管理データベース: 国立図書館 ウィキデータを編集 イスラエルアメリカ カテゴリ: MIPSアーキテクチャコンピュータアーキテクチャMIPSのマイクロプロセッサ命令セットアーキテクチャアドバンスドRISCコンソーシアム 最終更新 2025年1月30日 (木) 08:43 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』
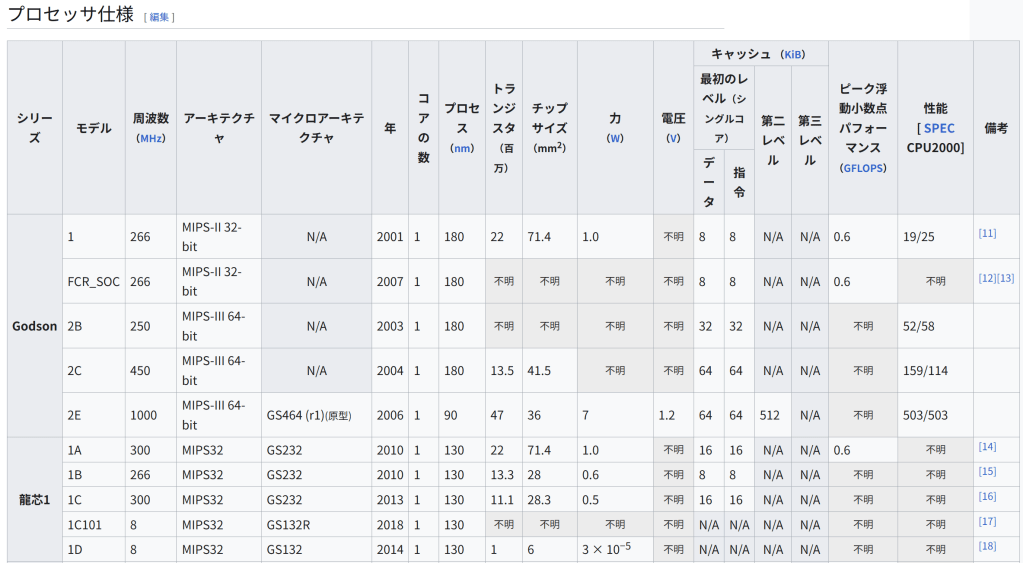
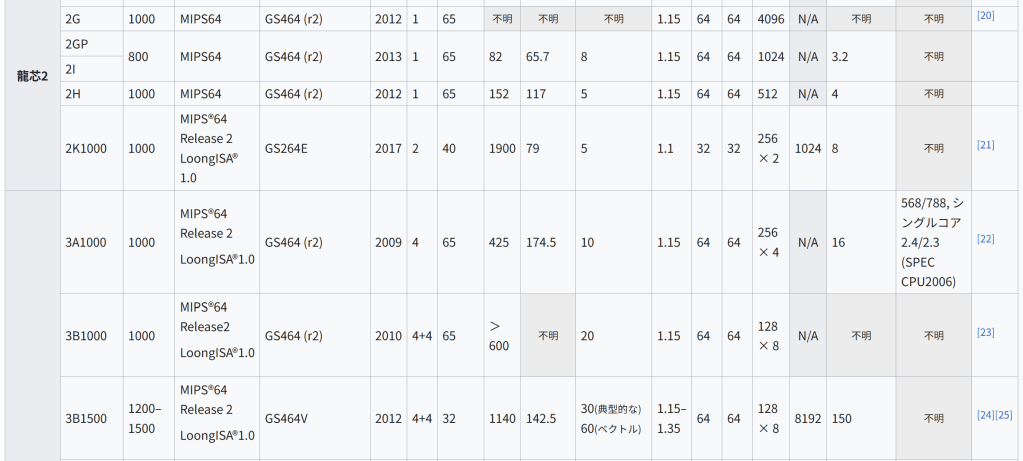
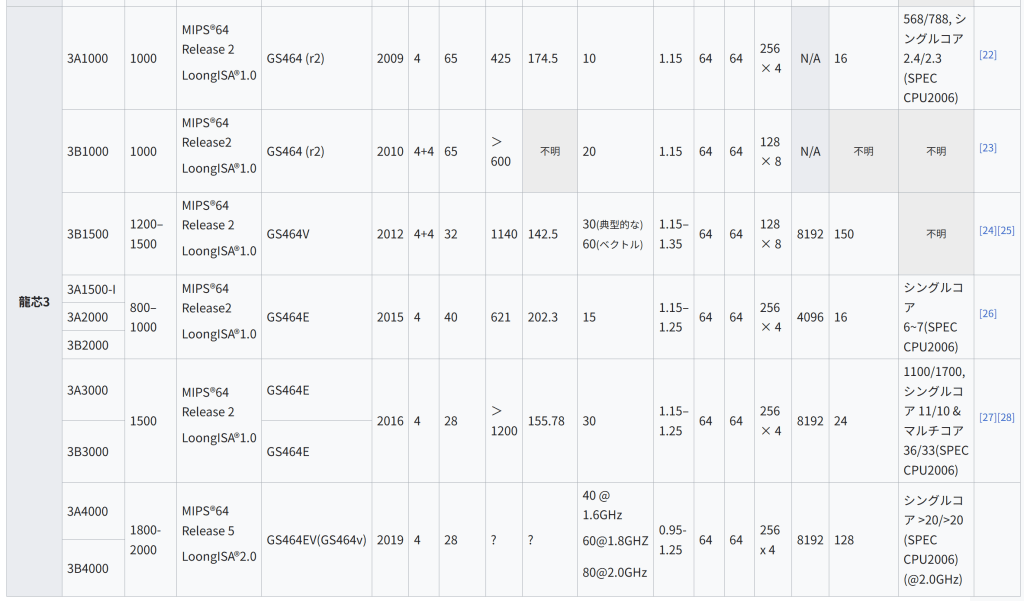
龙芯2Gは、「High Core Safety Computer CPU Development and Application」原子力高規模主要プロジェクトの支援を受けて開発された。2008年に設計されたが、龙芯の2Gおよび3Aプロジェクトの同時実装により、開発の進捗に影響を与える重複があった。2010年に正常に開発された。龙芯2Gは65ナノメートルプロセスを採用し、主周波数は1.0 GHz、トランジスタ数は1億、命令セットはMIPS64と互換性があり、X86バイナリ変換アクセラレーション命令が追加され、龙芯メディア拡張命令に加えて、64 KB命令と64 KBデータのL1キャッシュ、1 MBがある。L2キャッシュ、消費電力3W。このプロセッサでは、X86バイナリ変換テクノロジが使用され、MIPSプラットフォームでX86ダイナミックバイナリ変換を実装する方法が提案されている。龙芯2Gは、龙芯3A1000のシングルコアバージョンに相当する。龙芯2GQは、クアッドコアプロセッサである龙芯2Gの製品版である。龙芯2GQと龙芯3A1000の違いは、龙芯2GQは複数の相互接続をサポートしていないことである。龙芯2GPは後に龙芯2Iと改名された。
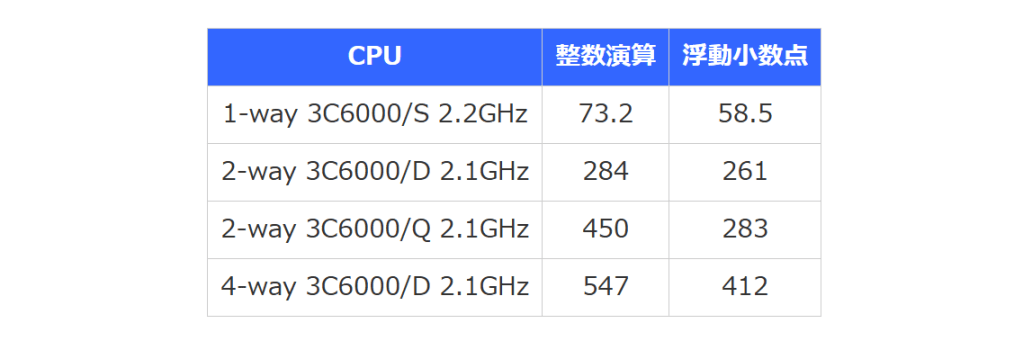
一方、3B6000Mについては、8基のLA364Eコアを内蔵し、2.5GHz駆動時でSPEC CPU 2026 Baseシングルコア固定小数点のスコアが30になるとしている。GPUも自社開発の「LG200」で、ハードウェアエンコーダ、4K/60Hz出力に対応。さらに、SM2/3/4ハードウェア暗号化アクセラレーションもサポートする。
R13 は SP とも呼ばれ、スタックポインタ R14 は LR とも呼ばれ、リンクレジスタ R15 は PC とも呼ばれ、プログラムカウンタ CPSR は下記32ビットを持つ[38]。
M (ビット 0 – 4) はプロセッサモードビット T (ビット 5) は Thumb ステートビット F (ビット 6) は FIQ 無効ビット I (ビット 7) は IRQ 無効ビット A (ビット 8) は不正データアボート無効ビット E (ビット 9) はデータエンディアンビット IT (ビット 10 – 15 と 25 – 26) は if-then ステートビット GE (ビット 16 – 19) は greater-than-or-equal-to ビット DNM (ビット 20 – 23) は書き換え禁止ビット J (ビット 24) は Java ステートビット Q (ビット 27) は sticky overflow ビット V (ビット 28) はオーバーフロービット C (ビット 29) は carry/borrow/extend ビット Z (ビット 30) は零ビット N (ビット 31) は negative/less ビット VFP/NEON用として、これらとは別に32ビット用はs0〜s31のレジスタがある。これらは、64ビットレジスタとしてd0〜d15として使える。s0〜s31とd0〜d15はオーバーラップしている。大半の ARMv7-A SoC はさらに、d16〜d31も使える。
VFP/NEON用のシステムレジスタとして、以下の3つがある。
FPSCR – Floating-point status and control register (浮動小数点状態制御レジスタ) FPEXC – Floating-point exception register (浮動小数点例外レジスタ) FPSID – Floating-point system ID register (浮動小数点システムIDレジスタ) 条件実行 ARMの命令セットにおいてユニークなのは、マシン語の最上位4ビットを占める条件コードを使用した条件実行命令であり、これによってほぼ全ての命令を分岐命令無しに条件付きで実行することができる。
脚注 [脚注の使い方] 注釈 ^ ベクトルレジスタが明示的に用意されておらず、複数のスカラレジスタに対して演算を行う。ベクタ長は固定されておらず、FPSCRという特殊なレジスタで最大8要素までのベクタ長を指定可能。また、レジスタがスカラモードのみで使えるバンクとベクタモードで使えるバンクに分けられており、レジスタの組み合わせに制約がある。 ^ ARMプロセッサのベクタモードへの対応はMVFR0レジスタの24-27ビット目を参照することで確認できる。 出典 ^ Arm’s Solution to the Future Needs of AI, Security and Specialized Computing is v9 ^ “Arm® (日本)|半導体IP|アーム公式サイト – Arm®”. arm.com. 2022年11月18日閲覧。 ^ “世の中ARMだらけ!? 現代社会を支える「ARM」ってなんだろう?”. ドスパラ. 2022年11月18日閲覧。 ^ “ARMとは”. コトバンク. 2022年11月18日閲覧。 ^ “Armがマイコン向けハイエンドCPUコア、Cortex-M85発表”. 日経. 2022年11月18日閲覧。 ^ http://www.arm.com/miscPDFs/3823.pdf ^ [1] ^ http://www.jp.arm.com/pressroom/08/080125.html ^ https://news.mynavi.jp/techplus/article/20100910-cortex-a15/ ^ https://ascii.jp/elem/000/000/645/645995/ ^ a b c d e f Douglas Fairbairn (2012年1月31日). “Oral History of Sophie Wilson”. 3 March 2016時点のオリジナルよりアーカイブ。2 February 2016閲覧。 ^ Wilson, Roger (2 November 1988). “Some facts about the Acorn RISC Machine”. Newsgroup: comp.arch. 2024年9月12日閲覧。 ^ “スマートフォンを席巻するARMプロセッサーの歴史”. ASCII.jp (2010年12月20日). 2013年7月24日閲覧。 ^ “ARMが初の64ビットCPU「Cortex-A50シリーズ」発表、サーバー向けに16コア以上に対応”. ITpro (2012年11月1日). 2014年11月27日閲覧。 ^ 2005年、ARM社のセミナー資料による。 ^ “Sony Japan | プレスリリース| クリエ用新アプリケーションCPU「Handheld EngineTM」の開発について”. http://www.sony.co.jp. 2019年4月8日閲覧。 ^ News:米速報:次世代マイクロアーキテクチャ「ARM11」発表 ^ Googleが新型「Chromebook」を発表、Samsung製で249ドル ^ 【PC Watch】 Samsung、初のARM Cortex-A15プロセッサ「Exynos 5250」 ^ 日本TI、モバイルの概念を一変させる高性能、高機能のOMAP™5プラットフォームを発表 ^ 【後藤弘茂のWeekly海外ニュース】 ARMが次世代CPU「Atlas」と「Apollo」の計画を発表 ^ AMD’s K12 ARM CPU Now In 2017 ^ 苦難の2013年を越え、輝かしい2014年に賭けるAMD (大きな期待が寄せられているサーバー向け64ビットARMプロセッサ) ^ ARM Sets New Standard for the Premium Mobile Experience – ARM ^ Qualcomm Introduces Next Generation Snapdragon 600 and 400 Tier Processors for High Performance, High-Volume Smartphones with Advanced LTE | Qualcomm ^ “ARM Cortex-M1”, ARM product website. Accessed April 11, 2007. ^ “ARM Extends Cortex Family with First Processor Optimized for FPGA”, ARM press release, March 19 2007. Accessed April 11, 2007. ^ ARM Cortex-M1 ^ Actel: 製品とサービス: プロセッサ: ARM: Cortex-M1 ^ AnandTech | Cortex-M7 Launches: Embedded, IoT and Wearables ^ Cortex-M7 Overview – ARM ^ Cortex-M23 Overview – ARM ^ Cortex-M33 Overview – ARM ^ “ARMv8-A Synchronization primitives”. p. 6. 2024年1月3日閲覧。 ^ Ltd, Arm. “Cortex-A78C”. Arm | The Architecture for the Digital World. 2023年1月14日閲覧。 ^ “Processor mode”. ARMホールディングス. March 26, 2013閲覧。 ^ “KVM/ARM”. April 3, 2013閲覧。 ^ 2.14. The program status registers – Cortex-A8 Technical Reference Manual ^ DSP & SIMD – ARM 関連項目 μClinux ソフィー・ウィルソン 外部リンク ARM Ltd. Linux Zaurusでアセンブリプログラミング 表話編歴 プロセッサアーキテクチャ 表話編歴 ARMベースのチップ 表話編歴 マイクロコントローラ 典拠管理データベース: 国立図書館 ウィキデータを編集 フランスBnF dataドイツイスラエルアメリカチェコ カテゴリ: ARMアーキテクチャマイクロプロセッサ命令セットアーキテクチャ 最終更新 2024年9月23日 (月) 11:59 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』