主成分分析
https://ja.wikipedia.org/wiki/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90







『出典: フリー百科事典『ウィキペディア(Wikipedia)』
この記事には複数の問題があります。 改善やノートページでの議論にご協力ください。
出典がまったく示されていないか不十分です。内容に関する文献や情報源が必要です。(2015年5月)
内容が専門的でわかりにくくなっている恐れがあります。(2015年5月)
出典検索?: “主成分分析” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL
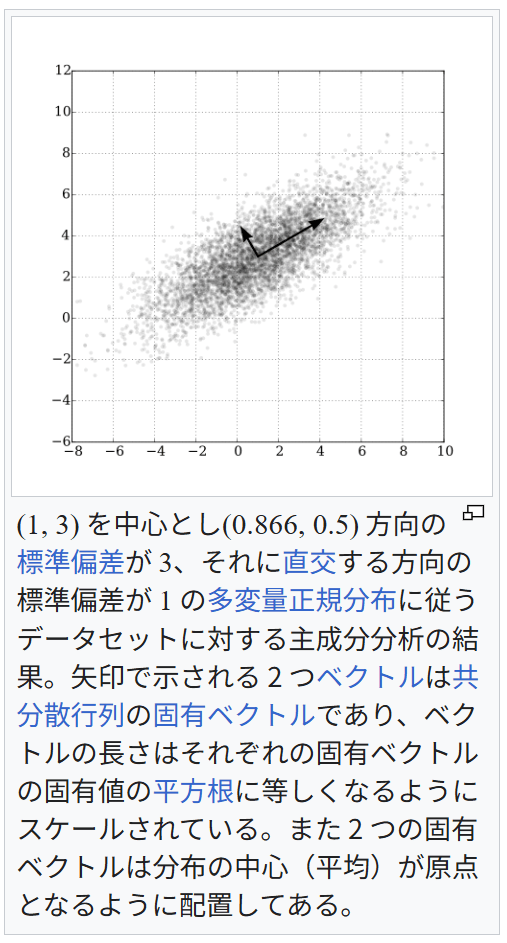
(1, 3) を中心とし(0.866, 0.5) 方向の標準偏差が 3、それに直交する方向の標準偏差が 1 の多変量正規分布に従うデータセットに対する主成分分析の結果。矢印で示される 2 つベクトルは共分散行列の固有ベクトルであり、ベクトルの長さはそれぞれの固有ベクトルの固有値の平方根に等しくなるようにスケールされている。また 2 つの固有ベクトルは分布の中心(平均)が原点となるように配置してある。
主成分分析(しゅせいぶんぶんせき、英: principal component analysis; PCA)は、相関のある多数の変数から相関のない少数で全体のばらつきを最もよく表す主成分と呼ばれる変数を合成する多変量解析の一手法[1]。データの次元を削減するために用いられる。
主成分を与える変換は、第一主成分の分散を最大化し、続く主成分はそれまでに決定した主成分と直交するという拘束条件の下で分散を最大化するようにして選ばれる。主成分の分散を最大化することは、観測値の変化に対する説明能力を可能な限り主成分に持たせる目的で行われる。選ばれた主成分は互いに直交し、与えられた観測値のセットを線型結合として表すことができる。言い換えると、主成分は観測値のセットの直交基底となっている。主成分ベクトルの直交性は、主成分ベクトルが共分散行列(あるいは相関行列)の固有ベクトルになっており、共分散行列が実対称行列であることから導かれる。
主成分分析は純粋に固有ベクトルに基づく多変量解析の中で最も単純なものである。主成分分析は、データの分散をより良く説明するという観点から、そのデータの内部構造を明らかにするものだと考えられる。多くの場合、多変量データは次元が大きく、各変数を軸にとって視覚化することは難しいが、主成分分析によって情報をより少ない次元に集約することでデータを視覚化できる。集約によって得られる情報は、データセットを元のデータ変数の空間から主成分ベクトルのなす空間へ射影したものであり、元のデータから有用な情報を抜き出したものになっている。主成分分析によるデータ構造の可視化は、可視化に必要なだけ先頭から少数の主成分を選択することで実現される。
主成分分析は探索的データ解析における主要な道具であり、予測モデル構築(英語版)にも使われる。主成分分析は観測値の共分散行列や相関行列に対する固有値分解、あるいは(大抵は正規化された)データ行列の特異値分解によって行われる[2]。主成分分析の結果は主成分得点(因子得点、英: score)と主成分負荷量(因子負荷量、英: loadings)によって評価される[3]。主成分得点とは、あるデータ点を主成分ベクトルで表現した場合の基底ベクトルにかかる係数であり、ある主成分ベクトルのデータ点に対する寄与の大きさを示す。主成分負荷量はある主成分得点に対する個々の(正規化された)観測値の重みであり、観測値と主成分の相関係数として与えられる。主成分分析は観測値の間の相対的なスケールに対して敏感である。
主成分分析による評価は主成分得点と主成分負荷量をそれぞれ可視化した主成分プロット、あるいは両者を重ね合わせたバイプロットを通して解釈される。主成分分析を実行するためのソフトウェアや関数によって、観測値の基準化の方法や数値計算のアルゴリズムに細かな差異が存在し、個々の方法は必ずしも互いに等価であるとは限らない(例えば、R言語における prcomp 関数と FactoMineR の PCA 関数の結果は異なる)。
直感的な説明
主成分分析は与えられたデータを n 次元の楕円体にフィッティングするものであると考えることができる。このとき、それぞれの主成分は楕円体の軸に対応している。楕円体の軸が短いほどデータの分散は小さく、短い軸に対応する主成分を無視することで、データの分散と同程度に小さな情報の損失だけで、データをより少ない変数で表現することができる。
楕円体の軸を見つけるには、データの平均を座標軸の原点に合わせる必要がある。そのため、データの共分散行列を計算し、共分散行列に対する固有値と固有ベクトルを計算する。また、それぞれの固有ベクトルを直交化し、正規化する必要がある。固有ベクトルの組として互いに直交する単位ベクトルが得られたなら、それらに対応する軸を持つ楕円体によってデータをフィッティングすることができる。それぞれの軸に対する寄与率(proportion of the variance: 分散の比)は、その軸に対応する固有ベクトルに対する固有値を、すべての固有値の和で割ったものとして得ることができる。
注意すべき点として、分散はデータのスケールに依存するため、主成分分析の結果はデータをスケール変換することで変わり得るということが挙げられる。
歴史と名称
主成分分析は1901年にカール・ピアソンによって導入された[4]。ピアソンは力学における主軸定理(英語版)からの類推によって主成分分析の方法を得た。主成分分析は、ピアソンとは独立に1930年代にハロルド・ホテリングよっても導入され、ホテリングによって主成分分析 (principal component analysis) と呼ばれるようになった[5][6]。(Jolliffe (2002, 1.2 A Brief History of Principal Component Analysis) 参照。)
主成分分析は応用分野によって様々な呼び名がある。
分野 呼び名
信号処理
離散(コサンビ・)カルフネン・ロエヴェ変換[注 1]
KL展開[注 2]
品質管理
ホテリング変換[注 3]
機械工学
固有直交分解[注 4]
線型代数学
行列 X の特異値分解
XTX の固有値分解
計量心理学[注 5]
因子分析[注 6]
エッカート・ヤング定理
シュミット・ミルスキー定理
気象学
経験的直交関数
雑音・振動
経験固有関数分解[注 7]
経験的成分分析[注 8]
準調和モード
スペクトル分解
構造力学
モーダル解析
関連する手法
主成分分析は因子分析によく似ている。因子分析は、データの背後にある構造に関する分野固有の仮設と、主成分分析の場合とはわずかに異なった行列に対する固有ベクトルを求める手法である、と要約できる。
主成分分析は正準相関分析 (canonical correlation analysis; CCA) とも関わりがある。正準相関分析は二つのデータセット間の相互共分散に基いて座標系を定める手続きだが、主成分分析は単一のデータセットの分散に基いて座標系を選択する手法である[7][8]。
詳細
数学的には主成分分析はデータの基底に対し直交変換(回転)を行い、新たな座標系を得ることであり[9][要ページ番号]、新しい座標系はその第一成分(第一主成分と呼ばれる)から順に、データの各成分に対する分散が最大になるように選ばれる。
以下では、データ行列 X として、各列の標本平均が 0 になるものを考える[注 9]。データ行列の各列 p はそれぞれデータが持つ特定の指標に対応し、データ行列の各行 n はそれぞれ異なる事例に対する指標の組を表す[注 10]。
主成分分析は p 次元ベクトル wk によってデータ行列 X の各行 xi を主成分得点のベクトル t(i) = (t1, …, tk)(i) に変換することであり、主成分得点tk(i) はデータ点 xi と負荷量ベクトル wk の内積によって与えられる。
t
k
(
i
)
x
i
⋅
w
k
{\displaystyle {t_{k}}{(i)}=\mathbf {x} {i}\cdot \mathbf {w} _{k}}
負荷量ベクトル w は単位ベクトルであり、各主成分得点の分散を第一主成分から順に最大化するように選ばれる。負荷量ベクトルの個数(つまり主成分の数)k は、元の指標の数 p に等しいか、より小さい数が選ばれる (k ≤ p)。負荷量ベクトルの個数、つまり新しいデータ空間の次元を元の空間の次元より少なくとることで、次元削減をすることができる(#次元削減を参照)。主成分分析による次元削減は、データの分散に関する情報を残すように行われる。
第一主成分
第一主成分に対応する負荷量ベクトル w1 は以下の条件を満たす[注 11]。
w
1
a
r
g
m
a
x
‖
w
‖
1
‖
X
w
‖
2
.
{\displaystyle \mathbf {w} _{1}={\underset {\Vert \mathbf {w} \Vert =1}{\operatorname {arg\,max} }}\Vert \mathbf {Xw} \Vert ^{2}.}
さらに変数 w が単位ベクトルという制約を除けば、上述の条件は次の等価な条件に簡約化することができる[注 12]。
w
1
a
r
g
m
a
x
w
≠
0
‖
X
w
‖
2
‖
w
‖
2
.
{\displaystyle \mathbf {w} _{1}={\underset {\mathbf {w} \neq \mathbf {0} }{\operatorname {arg\,max} }}{\frac {\Vert \mathbf {Xw} \Vert ^{2}}{\Vert \mathbf {w} \Vert ^{2}}}.}
右辺の最大化される量は XTX に対するレイリー商と見ることができる。XTX は対称行列だから、レイリー商の最大値は行列の最大固有値となり、それに伴い負荷量ベクトルは対応する固有ベクトルとなる。
第一負荷量ベクトル w1 が得られれば、データ点 xi に対応する主成分得点 t1(i) = xi · w1、あるいは対応するベクトル (xi · w1)w1 が得られる。
他の主成分
k 番目の主成分は k − 1 番目までの主成分をデータ行列 X から取り除くことで得られる:
X
^
k
X
−
∑
s
1
k
−
1
X
w
s
w
s
T
.
{\displaystyle \mathbf {\hat {X}} {k}=\mathbf {X} -\sum {s=1}^{k-1}\mathbf {X} \mathbf {w} {s}\mathbf {w} {s}^{\rm {T}}.}
負荷量ベクトルは新たなデータ行列に対して主成分得点の分散が最大となるようなベクトルとして与えられる。
w
k
a
r
g
m
a
x
‖
w
‖
1
‖
X
^
k
w
‖
2
a
r
g
m
a
x
w
≠
0
‖
X
^
k
w
‖
2
‖
w
‖
2
.
{\displaystyle \mathbf {w} {k}={\underset {\Vert \mathbf {w} \Vert =1}{\operatorname {arg\,max} }}\Vert \mathbf {\hat {X}} {k}\mathbf {w} \Vert ^{2}={\underset {\mathbf {w} \neq \mathbf {0} }{\operatorname {arg\,max} }}{\tfrac {\Vert \mathbf {\hat {X}} _{k}\mathbf {w} \Vert ^{2}}{\Vert \mathbf {w} \Vert ^{2}}}.}
このことから、新たな負荷量ベクトルは対称行列 XTX の固有ベクトルであり、右辺の括弧内の量の最大値は対応する固有値を与えることが分かる。したがって、すべての負荷量ベクトルは XTX の固有ベクトルである。
データ点 xi の第 k 主成分は主成分得点 tk(i) = xi · wk として負荷量ベクトルを基底とする表示が与えられ、また対応するベクトルは主成分得点に対応する基底ベクトルをかけた (xi · wk) wk となる。ここで wk は行列 XTX の第 k 固有ベクトルである。
X の完全な主成分分解は以下のように表わすことができる。
T
X
W
{\displaystyle \mathbf {T} =\mathbf {X} \mathbf {W} }
ここで W は p × p の正方行列であり、各列ベクトルは行列の XTX の固有ベクトルであり単位ベクトルである。
共分散
XTX はデータセット Xから与えられる経験的な標本共分散行列に比例する。
データセット X に対する、2つの異なる主成分の間の標本共分散 Q は以下のようにして得られる:
Q
(
P
C
j
,
P
C
k
)
∝
(
X
w
j
)
T
⋅
(
X
w
k
)
w
j
T
X
T
X
w
k
=
(
∗
)
w
j
T
λ
k
w
k
(
X
T
X
w
k
λ
k
w
k
)
λ
k
‖
w
k
‖
2
.
{\displaystyle {\begin{aligned}Q(\mathrm {PC} {j},\mathrm {PC} {k})&\propto (\mathbf {X} \mathbf {w} {j})^{\mathrm {T} }\cdot (\mathbf {X} \mathbf {w} {k})\&=\mathbf {w} {j}^{\mathrm {T} }\mathbf {X} ^{\mathrm {T} }\mathbf {X} \mathbf {w} {k}\&~{\overset {(\ast )}{=}}\mathbf {w} {j}^{\mathrm {T} }\lambda {k}\mathbf {w} {k}\qquad (\mathbf {X} ^{\mathrm {T} }\mathbf {X} \mathbf {w} {k}=\lambda {k}\mathbf {w} {k})\&=\lambda {k}\Vert \mathbf {w} {k}\Vert ^{2}.\end{aligned}}}
(∗) の変形において、wk が行列 XTX の固有値 λk に対応する固有ベクトルであることを利用した。XTX は対称行列であり、対称行列の異なる固有値に対応する固有ベクトル達は互いに直交するから、結局データセット X に対する異なる主成分間の標本共分散 Q(PCj, PCk) はゼロとなる。
上述の結果を言い換えると、主成分変換は経験的な標本共分散行列を対角化する座標変換であると特徴づけられる。
元々の基底に対する経験共分散行列 Q は行列記法によって以下のように表わすことができる。
Q
∝
X
T
X
W
Λ
W
T
.
{\displaystyle \mathbf {Q} \propto \mathbf {X} ^{\mathrm {T} }\mathbf {X} =\mathbf {W} \mathbf {\Lambda } \mathbf {W} ^{\mathrm {T} }.}
ここで Λ は XTX の固有値 λk からなる対角行列である。固有値 λk は対応する添え字の主成分得点の二乗和に等しい。
λ
k
‖
X
w
k
‖
2
∑
i
1
n
(
x
i
⋅
w
k
)
2
∑
i
1
n
t
k
(
i
)
2
.
{\displaystyle \lambda {k}=|\mathbf {X} \mathbf {w} {k}|^{2}=\sum {i=1}^{n}(\mathbf {x} {i}\cdot \mathbf {w} {k})^{2}=\sum {i=1}^{n}t_{k(i)}^{2}.}
行列 W が得られれば、行列 W の直交性を利用して、主成分ベクトルを基底とする経験共分散行列として次の表示が得られる。
W
T
Q
W
∝
W
T
W
Λ
W
T
W
Λ
.
{\displaystyle \mathbf {W} ^{\mathrm {T} }\mathbf {Q} \mathbf {W} \propto \mathbf {W} ^{\mathrm {T} }\mathbf {W} \,\mathbf {\Lambda } \,\mathbf {W} ^{\mathrm {T} }\mathbf {W} =\mathbf {\Lambda } .}
次元削減
線型変換 T = XW はデータ点 xi を元の p 次元の空間から、与えられたデータセットに対して各成分が互いに無相関になるような p 次元の空間へ写すが、一部の主成分だけを残すような変換も考えることができる。第一主成分から順に、各主成分に関するデータの分散が単調減少するように負荷量ベクトルが得られるため、最初の L 個の負荷量ベクトルだけを残し、残りの説明能力の低い負荷量ベクトルを無視すると、次のような変換が得られる。
T
L
X
W
L
{\displaystyle \mathbf {T} {L}=\mathbf {X} \mathbf {W} {L}}
WL は p × L の行列であり、TL は n × L の行列である。上記の変換はデータ点 x ∈ Rp に対する変換として[注 13]、t = WTx (t ∈ RL) と書くこともできる。つまり、主成分分析は p 個の特徴量を持つデータ点 x を L 個の互いに無相関な特徴量を持つ主成分得点 t へ写す線型変換 W : Rp → RL を学習する手法であるといえる[10]。 データ行列を変換することで得られる主成分得点行列は、元のデータセットの分散を保存し、二乗再構成誤差 (reconstruction error) の総和、
‖
T
W
T
−
T
L
W
L
T
‖
2
2
(
‖
X
−
X
L
‖
2
2
)
{\displaystyle |\mathbf {T} \mathbf {W} ^{\mathrm {T} }-\mathbf {T} {L}\mathbf {W} {L}^{\mathrm {T} }|_{2}^{2}\qquad (|\mathbf {X} -\mathbf {X} {L}|{2}^{2})}
を最小化するように与えられる。
354の個体について、37のY染色体STRマーカーの反復回数から計算された Y-STR(英語版) ハプロタイプに対する主成分分析の結果。主成分分析により、個体のY染色体の遺伝的な系統についてクラスタリングするようなマーカーの線型結合を得ることに成功している。
元のデータセットの分散をできる限り残すように次元削減することは、高次元のデータセットを可視化する上で重要である。例えば、主成分の数を L = 2 に選び、2つの主成分がなす平面にデータセットを射影すると、射影されたデータ点は主成分のなす平面に対して最もよく分散し、データに含まれるクラスタはそれぞれ分離される。したがって、2つの主成分がなす平面はデータを平面上にプロットする上で都合がよい。射影平面として別の平面を選んだ場合、クラスタ間のばらつきは小さくなり互いに重なり合うようになるため、実質上はそれぞれのクラスタを分類することが困難になってしまう。
回帰分析でも次元削減は有効である。回帰分析において、説明変数の数を増やすほど特定のデータに対して過剰適合したモデル、すなわち他のデータセットに対して誤った結果を与えるモデルを得がちである。モデル生成に使ったデータに対してモデルが過剰適合しないためには、説明変数の個数を適当に制限する必要があり、一つのアプローチとして、互いに強い相関を持つ説明変数を削減し、より少数の主成分によって回帰分析を行う方法がある。この方法を主成分回帰(英語版)と呼ぶ。
次元削減はノイズの大きなデータを分析する上でも適切であることが多い。データ行列の各列、つまりそれぞれの特徴量に対して独立同分布なガウシアンノイズが含まれる場合、変換されたデータ行列 T の列にも同様に独立同分布なガウシアンノイズが含まれる(座標軸の回転操作 W に対して独立同分布なガウス分布は不変であるため)。しかしながら、最初の少数の主成分に関しては、全体の分散に比べてノイズに由来する分散が小さくなるため、シグナル・ノイズ比を高めることができる。主成分分析は主要な情報を少数の主成分に集中させるため、次元削減によってノイズが支配的な成分だけを捨て、データ構造を反映した有用な成分を取り出すことができる。
特異値分解
主成分変換は行列の特異値分解とも結び付けられる。行列 X の特異値分解は以下の形式で与えられる。
X
U
Σ
W
T
.
{\displaystyle \mathbf {X} =\mathbf {U} \mathbf {\Sigma } \mathbf {W} ^{\mathrm {T} }.}
ここで、Σ は n × p の矩形対角行列であり、対角成分 σk が正の行列である。Σ の対角成分を行列 X の特異値という。U は n × n の正方行列であり、各列が互いに直交する n 次元の単位ベクトル[注 14]となる行列(つまり直交行列)である。各々の単位ベクトルは行列 X の左特異ベクトルと呼ばれる。同様に W は、各列が互いに直交する p 次元の単位ベクトルとなる p × p の正方行列である。こちらの単位ベクトルは行列 X の右特異ベクトルと呼ばれる。
X の特異値分解に基づいて XTX を表わせば、以下のようになる。
X
T
X
W
Σ
U
T
U
Σ
W
T
W
Σ
2
W
T
{\displaystyle {\begin{aligned}\mathbf {X} ^{\mathrm {T} }\mathbf {X} &=\mathbf {W} \mathbf {\Sigma } \mathbf {U} ^{\mathrm {T} }\mathbf {U} \mathbf {\Sigma } \mathbf {W} ^{\mathrm {T} }\&=\mathbf {W} \mathbf {\Sigma } ^{2}\mathbf {W} ^{\mathrm {T} }\end{aligned}}}
前節で示した XTX の固有値分解と見比べると、X の右特異ベクトルの組 W はまた XTX の固有ベクトルの組でもあり、X の特異値 σk は XTX の固有値 λk の平方根に等しいことが分かる。
特異値分解を主成分得点行列 T に対して行うと、以下のような分解が得られる。
T
X
W
U
Σ
W
T
W
U
Σ
.
{\displaystyle {\begin{aligned}\mathbf {T} &=\mathbf {X} \mathbf {W} \&=\mathbf {U} \mathbf {\Sigma } \mathbf {W} ^{\mathrm {T} }\mathbf {W} \&=\mathbf {U} \mathbf {\Sigma } .\end{aligned}}}
T の各列は X の左特異ベクトルに対応する特異値をかけたものとして表わされることが分かる。この結果は T の極分解(英語版)によっても得られる。
主成分分析の実装として、X の特異値分解のアルゴリズムがしばしば利用される。
n × L に次元削減された主成分得点行列 TL は、固有値分解の場合と同様に、寄与の大きい最初の L 個の特異値とそれに対応する左特異ベクトルだけを残すことによっても得られる:
T
L
U
L
Σ
L
X
W
L
.
{\displaystyle \mathbf {T} {L}=\mathbf {U} {L}\mathbf {\Sigma } {L}=\mathbf {X} \mathbf {W} {L}.}
特異値分解から寄与の小さな特異値を除いて TL を作るということは、元の行列とのフロベニウスノルムで測った差を最小化するような階数 L の行列を選ぶことに相当する。この結果はエッカート・ヤング定理として知られる。
ソフトウェア
Origin 「Pro」バージョンに主成分分析を含む多変量解析機能が含まれる。
Rの基本パッケージ中の多変量解析関数一覧 統計解析ツール「R言語」は主成分分析を始め多変量解析を標準で行える自由ソフトウェア。他統計ソフトやExcelのファイル取込やODBC接続も可能。FDAの申請にも使用を認められ、CRANという仕組で世界の膨大なアプリケーションを無償で使える。可視化機能に優れる。マルチプラットフォーム。
SAS 主成分分析 (PCA: Principal Component Analysis)
SPSS 多変量解析の選び方・SPSSによる主成分分析 IBM 主成分分析
脚注
[脚注の使い方]
注釈
^ 英: (Kosambi–) Karhunen–Loève transform、KLT
^ 英: Karhunen–Loève expansion
^ 英: Hotelling transform
^ 英: proper orthogonal decomposition、POD
^ 心理測定、心理統計学などとも呼ばれる。
^ 数学的な共通点は多いものの、厳密には主成分分析と因子分析は異なる手法である。両者の違いに関する議論は例えば Jolliffe 2002, Chapter 7 を参照。
^ 英: empirical eigenfunction decomposition
^ 英: empirical component analysis
^ つまり事前処理として、生のデータの各成分から成分ごとの標本平均を引く。
^ たとえば列のラベルには “年齢”, “性別”, “身長”, “体重” など一般的な属性が入り、行のラベルには “藤原”, “木曽”, “北条”, “徳川” など事例を特定する識別子が与えられる。行と列のどちらにラベルを与えるかは本質的ではなく、列と指標を対応させることは単に慣習による。
^
arg max
x
f(x) は f(x) が最大値をとるときの引数 x またはその集合を与える(arg max を参照)。作用素 arg max によって与えられる集合の元は最大値点と呼ばれることが多い。
^ ゼロでない任意のノルムのベクトルが方程式を満たすため、実際には以下の方程式の解から単位ベクトルとなるものを選ぶ。
^ Rp は p 次元の実数空間を表わす。
^ これらのベクトルは正規直交系をなす。
出典
^ Jolliffe 2002, p. 1.
^ Abdi & Williams 2010.
^ Shaw 2003, pp. [, 要ページ番号], .
^ Pearson 1901.
^ Hotelling 1933.
^ Hotelling 1936.
^ Barnett & Preisendorfer 1987.
^ Hsu, Kakade & Zhang 2012.
^ Jolliffe 2002.
^ Bengio, Courville & Vincent 2013.
参考文献
Pearson, K. (1901). “On Lines and Planes of Closest Fit to Systems of Points in Space” (PDF). Philosophical Magazine 2 (11): 559–572. doi:10.1080/14786440109462720.
Hotelling, H. (1933). “Analysis of a complex of statistical variables into principal components”. Journal of Educational Psychology 24: 417–441, 498–520.
Hotelling, H. (1936). “Relations between two sets of variates”. Biometrika 27: 321–77.
Abdi, H.; Williams, L.J. (2010). “Principal component analysis”. Wiley Interdisciplinary Reviews: Computational Statistics 2: 433–459. doi:10.1002/wics.101.
Shaw, P.J.A. (2003). Multivariate statistics for the Environmental Sciences. Hodder-Arnold. ISBN 0-340-80763-6
Barnett, T. P.; Preisendorfer, R. (1987). “Origins and levels of monthly and seasonal forecast skill for United States surface air temperatures determined by canonical correlation analysis”. Monthly Weather Review 115.
Hsu, Daniel; Kakade, Sham M.; Zhang, Tong (2012). “A spectral algorithm for learning hidden markov models”. Journal of Computer and System Sciences 78 (5): 1460-1480. arXiv:0811.4413.
Jolliffe, I.T. (2002). Principal Component Analysis (2nd ed.). Springer. ISBN 978-0-387-95442-4. MR2036084. Zbl 1011.62064
Bengio, Y.; Courville, A.; Vincent, P. (2013-3-7). “Representation Learning: A Review and New Perspectives” (PDF). Pattern Analysis and Machine Intelligence 35 (8): 1798–1828. doi:10.1109/TPAMI.2013.50.
関連項目
カルフネン・ロエヴェ定理(英語版)
カーネル主成分分析(英語版)
スパース主成分分析(英語版)
汎関数主成分分析(英語版)
点群統計モデル(英語版)
最小二乗法
主成分回帰(英語版)
固有値
特異値分解
低ランク近似(英語版)
CUR分解(英語版)
非負値行列因子分解
特異スペクトル解析(英語版)
固有顔
独立成分分析
対応分析(英語版)
多重対応分析(英語版)
除歪対応分析(英語版)
因子分析
混合データ因子分析(英語版)
正準相関
動的モード分解(英語版)
幾何学的データ分析(英語版)
非線形次元削減(英語版)
オヤの法則(英語版)
外部リンク
ウィキメディア・コモンズには、主成分分析に関連するカテゴリがあります。
Rと主成分分析
Rasmus Bro のコペンハーゲン大学での動画 – YouTube
Stanford University video by Andrew Ng – YouTube
A layman’s introduction to principal component analysis – YouTube
『主成分分析』 – コトバンク
表話編歴
統計学
標本調査
標本 母集団 無作為抽出 層化抽出法
記述統計学
連続データ
位置
平均 算術 幾何 調和 中央値 分位数 順序統計量 最頻値 階級値
分散
範囲 偏差 偏差値 標準偏差 標準誤差 変動係数 決定係数 相関係数 自己相関 共分散 自己共分散 分散共分散行列 百分率 統計的ばらつき
モーメント
分散 歪度 尖度
カテゴリデータ
頻度 分割表
推計統計学
仮説検定
パラメトリック
t検定 ウェルチのt検定 F検定 Z検定 二項検定 ジャック–ベラ検定 シャピロ–ウィルク検定 分散分析 共分散分析
ノンパラメトリック
ウィルコクソンの符号順位検定 マン・ホイットニーのU検定 カイ二乗検定 イェイツのカイ二乗検定 累積カイ二乗検定 フィッシャーの正確確率検定 尤度比検定 G検定 アンダーソン–ダーリング検定 コルモゴロフ–スミルノフ検定 カイパー検定 マンテル検定 コクラン・マンテル・ヘンツェルの統計量
その他
帰無仮説 対立仮説 有意 棄却
区間推定
信頼区間 予測区間
モデル選択基準
AIC BIC WAIC WBIC MDL
その他
偏り 偏りと分散 過剰適合 推定量 点推定 最尤推定 尤度関数 尤度方程式 最小距離推定 メタアナリシス ブートストラップ法
ベイズ統計学
確率
主観確率 ベイズ確率 事前確率 事後確率 最大事後確率
その他
ベイズ推定 ベイズ因子
相関
相関係数
ピアソンの積率相関係数 スピアマンの順位相関係数 ケンドールの順位相関係数 偏相関係数
その他
自己相関 空間的自己相関 相互相関 交絡変数 相関関係と因果関係 擬似相関 錯誤相関
モデル
一般線形モデル 一般化線形モデル 混合モデル 一般化線形混合モデル
回帰
線形
リッジ回帰 ラッソ回帰 エラスティックネット
非線形
k近傍法 回帰木 ランダムフォレスト ニューラルネットワーク サポートベクター回帰 射影追跡回帰
時系列
自己回帰モデル 自己回帰移動平均モデル ARCHモデル 対移動平均比率法 トレンド定常 傾向推定 共和分 構造変化
分類
線形
線形判別分析 ロジスティック回帰 単純ベイズ分類器 単純パーセプトロン 線形サポートベクターマシン
二次
二次判別分析
非線形
k近傍法 決定木 ランダムフォレスト ニューラルネットワーク サポートベクターマシン ベイジアンネットワーク 隠れマルコフモデル
その他
二項分類 多クラス分類 第一種過誤と第二種過誤
教師なし学習
クラスタリング
k平均法(k-means++法) DBSCAN
密度推定(英語版)
カーネル密度推定(カーネル)
その他
主成分分析 独立成分分析 自己組織化写像
統計図表
棒グラフ バイプロット(英語版) 箱ひげ図 管理図 フォレストプロット ヒストグラム 円グラフ Q-Qプロット ランチャート 散布図 幹葉図 バイオリン図 ドットプロット ヒートマップ 階級区分図
生存時間分析
生存時間関数 カプラン=マイヤー推定量 ログランク検定 故障率 比例ハザードモデル
歴史
統計学の創始者 確率論と統計学の歩み
応用
社会統計学 疫学 生物統計学 系統学 統計力学 計量経済学 機械学習 実験計画法
出版物
統計学に関する学術誌一覧 重要な出版物
全般
統計 頻度主義統計学 統計学および機械学習の評価指標
その他
方向統計学 S言語 R言語 統計検定 社会調査士 JDLA Deep Learning For GENERAL JDLA Deep Learning for ENGINEER 実用数学技能検定 品質管理検定
カテゴリ カテゴリ
スタブアイコン
この項目は、統計学に関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(プロジェクト:数学/Portal:数学)。
典拠管理データベース: 国立図書館 ウィキデータを編集
フランス BnF data ドイツ イスラエル アメリカ
カテゴリ: 統計学多変量統計次元削減機械学習データ分析行列の分解数学に関する記事
最終更新 2025年5月30日 (金) 21:49 (日時は個人設定で未設定ならばUTC)。
テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』
