MIPSアーキテクチャ
https://ja.wikipedia.org/wiki/MIPS%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3






『出典: フリー百科事典『ウィキペディア(Wikipedia)』
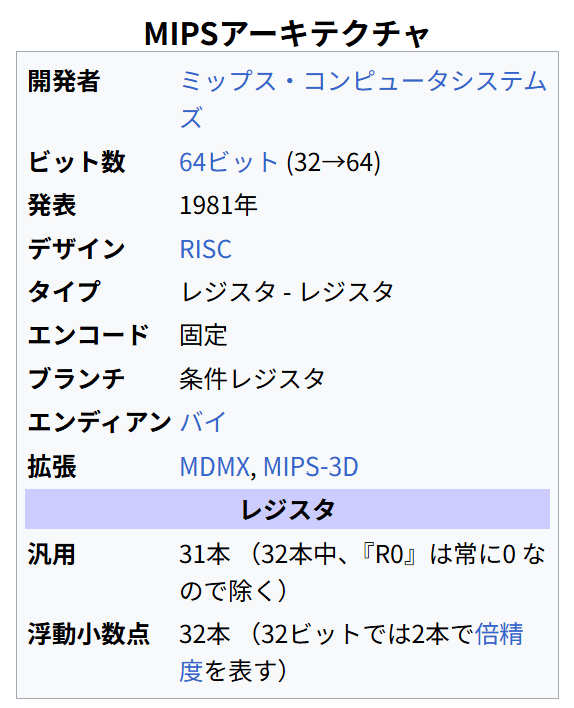
MIPSアーキテクチャ
開発者 ミップス・コンピュータシステムズ
ビット数 64ビット (32→64)
発表 1981年
デザイン RISC
タイプ レジスタ – レジスタ
エンコード 固定
ブランチ 条件レジスタ
エンディアン バイ
拡張 MDMX, MIPS-3D
レジスタ
汎用 31本 (32本中、『R0』は常に0 なので除く)
浮動小数点 32本 (32ビットでは2本で倍精度を表す)
MIPSアーキテクチャは、ミップス・コンピュータシステムズ(現ミップス・テクノロジーズ)が開発したRISCマイクロプロセッサの命令セット・アーキテクチャ (ISA) である。
概要
MIPSは “Microprocessor without Interlocked Pipeline Stages”((命令)パイプラインのステージに「インターロックされたステージ」がないマイクロプロセッサ)に由来しており、R2000の頃のマイクロアーキテクチャの特徴からの命名である(が、その後そのような特徴が薄れていったのも、他のRISCと同様である)。
MIPS値にも掛けている。
当初は32ビット幅のレジスタとデータバスを持つ32ビットの構成だったが、後に64ビットに拡張された。
MIPSアーキテクチャには下位互換のある複数の命令セットが存在する。
それぞれ、MIPS I、MIPS II、MIPS III、MIPS IV、MIPS 32、MIPS 64 と称する。
現行版は MIPS 32(32ビット実装)と MIPS 64(64ビット実装)である[1][2]。MIPS 32 と MIPS 64では命令セットだけでなく制御レジスタについても定義している。
いくつかのアドオン拡張も用意されている。
例えば、MIPS-3D は、3Dタスクで一般的な処理を行うための浮動小数点SIMD命令のシンプルなセットである[3]。
また、MDMX (MaDMaX) は、より広範な整数SIMD命令セットで、64ビット浮動小数点レジスタを流用する。
その他、MIPS16e は命令列を圧縮してプログラム格納域を小さくするための拡張である (ARMアーキテクチャのThumbエンコーディングに対抗したもの) [4]。
また、MIPS MT は、米インテル社がハイパースレッディング・テクノロジーとして普及させた技術と同等の、マルチスレッディングに適した拡張である[5]。
命令セットが非常にきれいなので、アメリカ合衆国ではコンピュータ・アーキテクチャを学校で教えるときに教材としてMIPSアーキテクチャを使うことが多い[6]。
MIPSのデザインは、もうひとつの初期のRISCであるバークレーRISC(en:Berkeley RISC)と共に、後発のRISCに影響を及ぼした。
MIPSプロセッサは、SGIのコンピュータ製品群に使われていた。
日本では、ソニーのNEWSや日本電気 (NEC) のEWS4800で使われた。
また、米DEC社は、ごく短期間だけMIPSを使ったワークステーションを製品化していた[注 1]。
また、機器組み込み分野で成功し、Windows CE製品、シスコシステムズのルーター、プリンタのエンジンなどに使われた。
ゲーム機分野でも成功を収め、NINTENDO 64、ソニー・コンピュータエンタテインメントのPlayStation、PlayStation 2、PlayStation Portable、PlayStation 3 (CECHA00/CECHB00 モデルのみ)でもMIPSアーキテクチャのプロセッサが使われた。
1990年代後半、RISCマイクロプロセッサの出荷個数ベースで3分の1がMIPSアーキテクチャの製品だったと見積もられている[7]。
歴史
RISCの先駆者
1981年、スタンフォード大学のジョン・L・ヘネシー率いるチームは、後に最初のMIPSプロセッサを生むプロジェクトを開始した。
基本コンセプトは、命令パイプラインを深くすることで劇的に性能を向上させることである。
IBM 801 などの研究や先例でこの手法はよく知られていたが、その可能性が完全に解明されていなかった。
一般にプロセッサは、命令デコーダ、演算論理装置 (ALU)、メモリとやりとりするロード/ストア・ユニットといった部分で構成されている。
パイプライン化されていない従来の「マイクロプロセッサの」設計では、1つの命令の処理を(ほぼ)完了させないと次の命令の処理を開始できず、内部ではほとんどの時間を処理に関与せずに待機するだけの回路が多くなる。
これに対して「従来のマイクロプロセッサ」ではない、例えば1960年代のIBM 7030の頃には実現されていた命令パイプライン方式では、1つの命令の処理過程を複数のステージ(段階)に分割し、各ステージを順次、次のサブユニットに送って、複数のサブユニットがオーバラップして動作できるようにする。
1つ目の命令の最初のステージの処理が終わると、次のステージの処理へ引き継がれると同時に、2つ目の命令の最初のステージの処理が平行して実行される。
3つ目の命令が入ると1つ目の命令は3ステージ先、2つ目の命令は2ステージ先、3つ目の命令は最初のステージで、3つの処理が同時に行われる。
すべてが最も効率的に動けば、複数に分割した処理過程の内容に関わらず、1ステージの処理ごとに1つの命令が完了できることになる。
命令パイプラインでは、乗算・除算命令のように命令の実行に長い時間がかかる場合、パイプラインに次の命令を取り込むのを待つ必要がある。
この問題の解決策として、パイプラインの各ステージが処理中であることを示せるようにして、パイプラインをインターロックして、次の命令のステージが進行しないように止めなければならない。
これがストールである。
分岐命令を実行すると、後続の命令が途中のステージまで進行していたものを取り消さなければならず、ストールに加えて無駄となった処理時間分も加わる。
これらがインターロックのロスとなる[8]。
ストールが発生しインターロックがかかると命令パイプラインは足踏みするため、性能向上は望めないと考えられていた。
MIPSの設計上では、すべての命令を単純化して実行処理が1クロックサイクル内で完了するよう計画された。そうできればインターロックをなくすことができる。
このような設計にすることで掛け算や割り算などの複雑な命令が1つの命令では実行できなくなるが、単純な命令だけであれば、プロセッサに与えるクロックを高速にでき早く動作させて、性能が向上すると予想された。
また、インターロック回路を加えると半導体チップの面積(ダイサイズ)が増えて、クロックを上げることが困難になるため、クロックの高速化のためにはインターロックを排除することも必要だった。
複雑だが有用だった命令を排除することは議論の中心になった。
多くの人が「複雑な掛け算を単純な多くの足し算にして、どうして速度が向上するのか」と、この設計手法、そしてRISC一般の謳い文句に懐疑的で誇大広告だと言った。
しかし、これらの意見は、この設計における速度向上のポイントが命令の機能にあるのではなく、パイプラインにあるということを無視したものだった。
時間のかかる処理にまつわる問題は、ディレイスロットで一応解決された。
例えば、2クロックサイクルかかる命令があった場合、次の命令をディレイスロットとし、そこに、前の命令と依存関係の無い、つまり前の命令の結果を必要とせず、かつ前の命令に関わっているレジスタを使用しない命令を配置することで、パイプラインを止めないようにした。
これを実現するためには、プロセッサに与える命令列を生成するコンパイラが、あらかじめ各命令ごとのクロックサイクル数を把握して、可能な限りディレイスロットを有効な命令で埋めるようにする必要があった。
それでも大部分の命令は1クロックサイクルで実行できた。
また、コンパイラ技術の進展はディレイスロットの活用頻度を向上させた。
初期のMIPSと並び、RISCの典型であり代表とされるバークレーRISC(英語版)(SPARCへの影響が大きい)と比べると、サブルーチンコールの扱い方が大きく異なる。
バークレーRISCは頻繁に実行され性能への影響が大きいサブルーチンコールの性能向上を図るために、大きなレジスタファイルを持つと同時にレジスタ・ウィンドウというメカニズムを導入したが、それによってサブルーチンコールの入れ子段数が制限されている。
サブルーチンコールは、それぞれのルーチンで専用に用いるローカルのレジスタ群を必要とし、その割り当てをハードウェアでサポートするということはチップにさらなるリソースを必要とし、設計も複雑化することを意味する。
ヘネシーは、賢いコンパイラであればハードウェアでの実装に頼らずに使っていないレジスタを見つけ出すことができ、単にレジスタを有効利用できるだけでなく、あらゆるタスクの性能向上にも寄与すると考えた。
MIPSは最も典型的なRISCのひとつだとされる、というよりも、RISCの提唱者であるヘネシーとパターソンのそれぞれが設計した命令セット(命令セットアーキテクチャ)であるということを理由に、MIPSとバークレーRISCの設計が「典型的なRISC」だとされ、それらの特徴を以て「RISCの定義」だとされているためであり、「MIPSは最も典型的なRISC」だという言明はその逆になっている。
命令語のビット数を節約するために、命令数を抑えることで、命令フォーマット中のオペコード部として必要となるビット数を抑えている。
基本オペコードは、命令語32ビットの中の6ビットを使用し[9]、残りの部分の構成の違いにより数種類の分類がある。
命令語の残りの26ビットの部分について、26ビットの分岐先アドレスとする命令フォーマット、5ビットのフィールド4個で3つのレジスタとシフト値を指定し、残り6ビットを追加のオペコードとする命令フォーマット、2つのレジスタと16ビットの即値を指定する命令フォーマットがある。
このような設計で、実行すべき命令と必要なデータ(オペランド)を1サイクルでロードできるようになった
(正確には、必要なデータはレジスタの中にあるのであり、もし1サイクルで全てを揃えたいのなら特殊な技法が必要になる。
細かく言うと、「オペコードとオペランド指定子」を(1サイクルで32ビットをメモリからロードできるように他の部分が設計されていば)1サイクルでロードできる)。
最初のハードウェア
1984年、ヘネシーは、将来商業レベルとなる可能性のあるデザインを確立し、教え子、友人らとミップス・コンピュータシステムズを設立する。
1985年、彼らは、最初のデザインであるR2000を完成させた。
また、1988年には、それを進化させたR3000を完成させた。
これらの32ビットCPUによって、ミップス・コンピュータシステムズは、1980年代に基盤を築くことができた。
なお、これらの商用デザインにおいては、スタンフォード大学での学術研究的な設計方針とは異なり、ハードウェアにインターロック機構を装備し、掛け算も割り算もサポートしていた。
なぜなら、単にひとつのプログラムを実行するだけなら、上述のディレイスロットの考え方で何とかなるが、商用としてはマルチタスクや割り込みへの対応は必須であり、インターロック機構の付加は必然だったからである。
また、半導体プロセス技術の急速な進歩がそれを可能にしていった。
インターロック機構を備えたとしても、インターロックをなるべく発生させないコンパイラ技術は高速化に必須である。
これらのプロセッサは、SGI、DEC DECstation、ソニー NEWS、NEC EWS4800などに使われた。
これらの設計にはソフトウェアアーキテクトのアール・キリアンも参加している。
彼は後に MIPS III 64ビット命令セットを設計し、R4000のマイクロアーキテクチャ開発にも関わった[10][11]。
1991年、ミップス・コンピュータシステムズ社は、最初の64ビットマイクロプロセッサR4000をリリースした[注 2][8]。
R4000は仮想アドレスだけでなく仮想空間IDを格納できる進んだTLBを採用していた。
それによって頻繁なコンテキストスイッチの度にTLBをフラッシュする必要性をなくし、他の競合するアーキテクチャ(Pentium、PowerPC、Alpha)に対して劣っていたマイクロカーネル実装時の大きな性能問題を低減させることができた[12]。
しかし、ミップス社は、R4000を市場に提供しようとしたころ、財政危機に陥った。
そこで、当時のミップス社の最大の顧客であった米SGI社は、1992年にミップス社を買い取り、これによりMIPSアーキテクチャの存続が保証された。
こうしてミップス・コンピュータシステムズ社はSGIの子会社となり、社名もミップス・テクノロジーズと変更された。
アーキテクチャのライセンス供与
1990年初頭、ミップス・テクノロジーズ社は、プロセッサの設計をサードパーティーにライセンス供与しはじめた。
プロセッサ・コア、つまり主要な演算部分の単純さによって、これは「MIPSコア」として成功を収め、従来は同等のゲート数と価格のCISCプロセッサが占めていた様々な分野でMIPSコアが使われるようになった。
ゲート数と価格は密接な関係があり、CPUの価格はキャッシュメモリ領域を除けば、ゲート数とピン数でほぼ決まっていた。
サン・マイクロシステムズも追随してSPARCコアのライセンス供与を開始したが、成功したとは言い難い。
1990年代後半にはMIPSは機器組み込み用プロセッサ分野の勝者となっていた。
1997年、4800万個目のMIPSベースのチップが出荷され、MIPS CPUファミリはモトローラのMC68000ファミリを出荷個数で抜いた。
この成功により、SGI社はミップス・テクノロジーズを1998年にスピンオフさせた。
ミップス・テクノロジーズの収入の半分はライセンス料であり、残りはサードパーティーが生産するコアの設計から来ている。
1999年、ミップス・テクノロジーズ社はライセンス体系を整理し、32ビットのMIPS32(MIPS II にそれ以降の新規機能を追加したものだが、後に遅延分岐系のbranch likely は強い非推奨となり、将来の削除が予告された[13])と64ビットのMIPS64(MIPS V ベース)に分けた。
このアナウンスと同時に、NEC、東芝、SiByte(後にブロードコムが買収)がMIPS64のライセンス供与を受けた。
フィリップス、LSIロジック、IDTもすでに参加している。
成功に成功が続き、MIPSはコンピュータに近い機器(ハンドヘルドコンピュータやセットトップボックスなど)の市場で最も使われているヘビー級CPUコアとなっている。
モトローラ社もセットトップボックスに自社のPowerPCではなくMIPSコアを採用した。
いくつかのベンチャー企業もミップス・テクノロジーズ社よりアーキテクチャ・ライセンスの供与を受けて参入してきた。
最初にMIPSプロセッサを設計したベンチャー企業はQuantum Effect Devicesだった。
MIPS社でR4300iを設計したチームはSandCraft(英語版)社を設立し、NEC向けにR5432を設計し、後にSR7100を作った。
これは、組み込み分野向けの最初のアウト・オブ・オーダー実行プロセッサである。
DECで最初にStrongARMを設計したチームはふたつのMIPS関連ベンチャーを設立した。
ひとつはSiByteでSB-1250というMIPSベースで最初のSystem-on-a-chip (SOC) を実現した製品を作った。
もうひとつのAlchemy SemiconductorはAu-1000という低電力のSOCを作った。
SiByteはブロードコムに買収された。
AlchemyはAMDに買収されたが、後にAMDはAlchemyをRaza Microelectronics (RMI) に売却した。
LexraはMIPSに似たアーキテクチャをベースにDSP機能を付加したチップをオーディオ機器市場向けに、マルチスレッド機能を付加したチップをネットワーク機器市場向けに出している。
LexraはMIPSからライセンス供与を受けていなかったため、MIPSとの間で2件の訴訟となった。
1件はLexraがMIPS互換であることを宣伝しないという条件ですぐさま解決した。
2件目は長引き、両社を疲弊させた。結局、ミップス・テクノロジーズがLexraに対してフリーライセンスと賠償金を払うことで決着した。
MIPSアーキテクチャを使ったマルチコアデバイスを構築することに特化した企業も2社登場している。
Raza Microelectronics, Inc. は低迷していたSandCraftから製品ラインを買い取り、通信およびネットワーク市場向けに8コアの製品を提供した。
Cavium Networks は元々はセキュリティ・プロセッサのベンダーだったが、こちらも同じ市場向けに8CPUコアを集積したデバイスを開発し、後に最大32コア版を開発している。両社ともに社内でコアを設計しており、MIPSからコア設計を買うのではなくアーキテクチャのライセンス供与だけを受けている。
デスクトップ市場を失う
MIPSプロセッサを使ったワークステーションシステムを製造していた企業として、SGI、ミップス・コンピュータシステムズ、Whitechapel Workstations、オリベッティ、Siemens-Nixdorf、エイサー、DEC、NEC、ソニー、DeskStation があった。
またMIPSアーキテクチャ上に移植されたオペレーティングシステムとして、SGIのIRIX、マイクロソフトのWindows NT(v4.0まで)、Windows CE、Linux、BSD、UNIX System V、QNX、ミップス自身のRISC/osなどがある。
1990年代初頭、インテルプロセッサベースのPCに対抗してMIPSプロセッサベースのコンピューティング環境を作るために、コンパック他多数の企業によって Advanced Computing Environment (ACE) というコンソーシアムが設立された。
当時、MIPSなどの強力なRISCプロセッサがインテルのIA-32アーキテクチャに取って代わるだろうという予測がなされていた。
マイクロソフトの Windows NT が当初、Alpha、MIPS、PowerPCなどのRISCアーキテクチャに対応したこともその予測を裏付ける形となった。
しかしインテルがPentiumクラスのCPUをリリースすると、マイクロソフトの Windows NT v4.0 では対応するアーキテクチャをIA-32とAlphaのみに絞った。
後にSGIがItaniumやIA-32アーキテクチャへの移行を決定すると、デスクトップ市場ではMIPSプロセッサはほぼ完全に姿を消した[14]。
組み込み市場
Ingenic JZ4725 は、MIPSベースのSoCの一例である。
1990年代を通して、MIPSアーキテクチャはコンピュータネットワーク、電気通信、アーケードゲーム、ゲーム機、プリンター、デジタルセットトップボックス、デジタルテレビ、DSLモデムやケーブルモデム、携帯情報端末といった組み込み市場で広く採用された。
MIPSの組み込み向け実装は低消費電力と低発熱を特徴とし、組み込み向けの開発ツールも充実しており、知識の蓄積もあることから、今も組み込み市場で人気を保っている。
組み込み市場向けの合成可能なコア
最近ではMIPSアーキテクチャはIPコアとして、組み込み用プロセッサの設計に使える形で利用されることが多い。
1999年の時点で、32ビットと64ビットの基本コアが提供されており、それぞれ MIPS32 4K と MIPS64 5K と呼ばれている。
それらのコアとFPU、SIMDシステム、各種I/Oデバイスなどを組み合わせてチップを設計できる。
MIPSコアは商業的に成功を収め、様々な機器で利用されている。
例えば、シスコシステムズやリンクシスなどのルーター、ケーブルモデム、ADSLモデム、ICカード、レーザープリンター、セットトップボックス、ロボット、ソニー・コンピュータエンタテインメントのPlayStation 2やPlayStation Portableなどで使われている。
携帯電話やPDAの分野では競合するARMアーキテクチャの座を奪うことはできなかった。
MIPSアーキテクチャの組み込み用プロセッサとして
IDT RC32438
ATI Xilleon
Alchemy Au1000/1100/1200
Broadcom Sentry5
RMI XLR7xx
Cavium Octeon CN30xx/CN31xx/CN36xx/CN38xx/CN5xxx
インフィニオン・テクノロジーズ EasyPort/Amazon/Danube/ADM5120/WildPass/INCA-IP/INCA-IP2
Microchip Technology PIC32
NEC EMMA/EMMA2/VR4181A/VR4121/VR4122/VR4181A/VR5432/VR5500
Oak Technologies Generation
PMC-Sierra RM11200
QuickLogic QuickMIPS ESP
東芝 Donau/TMPR492x/TX4925/TX9956/TX7901
などがある。
映像組み込みでの利用
2008年の時点で、MIPSはデジタルテレビで68%、DVDレコーダーで72%、Blu-Rayレコーダーで77%、ケーブルテレビのセットトップボックスで70%、IPテレビのセットトップボックスで77%のシェアがあり、動画のデコーダ・エンコーダを必要とする映像関係で広く使われている[15]。
MIPSベースのスーパーコンピュータ
MIPSアーキテクチャは超並列型のスーパーコンピュータにも採用された。
シリコングラフィックス (SGI) は1990年代前半からデスクトップ型のグラフィックス・ワークステーションだけでなく高性能計算市場にも注力するようになった。
R4400やR8000を使った Challenge シリーズというサーバシステムで成功を収め、後にR10000も採用している。
その後SGIはさらに強力なシステムの開発に注力するようになる。
R10000を採用した Origin 2000 はNUMA型で最大1024個のプロセッサを相互接続するものだった。
さらにそこからR14000やR16000を最大1024個構成できる Origin 3000 を開発。
しかし、SGIは2005年にIA-64アーキテクチャへの移行を決定し、MIPSベースのスーパーコンピュータの開発をやめた。
高性能計算のベンチャー企業SiCortexは、2007年にMIPSベースの超並列マシンを発表した。
MIPS64アーキテクチャをベースとし、カウツグラフのトポロジーを使って高性能インターコネクトでノードを相互接続する。
消費電力が小さく計算能力が高い。
計算ノードはMIPS64コアを8個集積したマルチコアであり、メモリコントローラ、DMAエンジン、ギガビット・イーサネット、PCI Express コントローラなどがシングルチップに集積されていて、消費電力はわずか10ワットでありながら、浮動小数点演算性能はピークで6GFLOPSとされている。
最大構成のSC5832はそのようなノードチップ972個で構成されており、MIPS64コアが5832個ある。ピーク性能は8.2テラFLOPSとされている。
龍芯
→詳細は「龍芯」を参照
龍芯は中国科学院が設計したMIPS互換のマイクロプロセッサであるが、当初はミップス・テクノロジーよりライセンスを受けていなかった。
そのマイクロアーキテクチャは中国が独自に設計したもので、初期の設計ではMIPSアーキテクチャにある4つの命令が実装されていなかった[16]。
2009年6月、中国科学院はミップス・テクノロジーズから直接、MIPS32およびMIPS64アーキテクチャのライセンス供与を受けた[17]。
2006年から各社が龍芯をベースとしたコンピュータをリリースしており、低消費電力のネットブックやネットトップもある[18][19]。
MIPS IV
MIPS IV は4番目のアーキテクチャである。MIPS III のスーパーセットであり、それまでの全てのアーキテクチャと互換性がある。MIPS IV は1994年のR8000で初めて実装された。MIPS IV で追加された点は次の通りである。
浮動小数点数のロード/ストア命令で「レジスタ + レジスタ」形式(インデックスつき)のアドレス指定を追加
単精度および倍精度の浮動小数点数の積和演算命令を追加
条件転送命令(整数レジスタと浮動小数点レジスタ)を追加
FPUの制御/ステータスレジスタに新たな条件ビットを追加し、全部で8ビットとした。
MIPS V
MIPS V は5番目のアーキテクチャで、1996年10月21日の Microprocessor Forum 1996 で発表された[20]。
主に3次元グラフィックスの性能向上を目的としている。
1990年代中ごろ、組み込み用途以外では主にSGIがグラフィックス・ワークステーションにMIPSマイクロプロセッサを使っていたためである。
MIPS V と同時にそれを補完する MIPS Digital Media Extensions (MDMX) というマルチメディア拡張(整数のみ)も発表された[21]。
MIPS V を実装した製品は結局登場しなかった。
1997年、SGIはコード名 “H1” または “Beast” と、”H2″ または “Capitan” というマイクロプロセッサを発表した。
前者は最初の MIPS V 実装で、1999年に出荷予定とされた。
“H1” と “H2” のプロジェクトは後に統合され、最終的に1998年に中止となった。
MIPS V は pair-single (PS) と呼ばれる新たなデータ型を追加していた。
これは単精度(32ビット)浮動小数点数のペアを64ビットのFPUレジスタに格納するものである。
算術演算命令、比較命令、条件転送命令ではPSデータをSIMD風に扱う。
またPSデータのロード、配置変更、変換などの命令が追加されている。
既存リソースで浮動小数点SIMDを実現しようという試みだった[21]。
MIPS CPU ファミリ
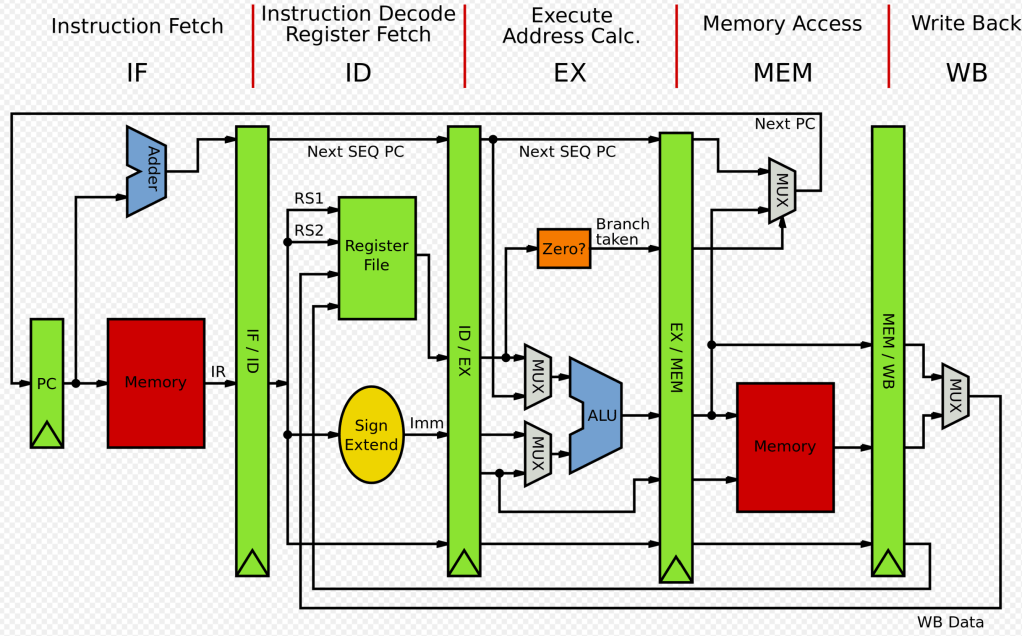
初期のMIPSのパイプライン概念図。5段パイプラインである(命令フェッチ、命令デコード、実行、メモリアクセス、ライトバック)
初の商用モデルR2000は1985年に発表された。
実行に複数サイクルを要する乗算と除算命令の処理部をチップ上にやや独立したユニットとして追加した。
乗除算の結果は直接汎用レジスタには入らず、専用のレジスタに出力されるため、それを汎用レジスタに持ってくる命令も追加された。
その命令を乗除算の完了前に発行するとパイプラインがインターロックする。
R2000は起動時にビッグエンディアンとリトルエンディアンのどちらかを選んで動作する。
32ビット汎用レジスタを32本持つが、コンディションコードレジスタを持たない。
設計者はそれがボトルネックになる可能性を考慮したためで、条件判断は指定した2つのレジスタの値の比較を行い、その結果で分岐の可否を判断する。
レジスタに入っている値で条件判断するのはAMD Am29000 や DEC Alpha とよく似ている。
なお、プログラムカウンタには直接アクセスできない。
R2000は最大4個のコプロセッサをサポートしており、そのうち1つは主CPUに組み込まれていて、例外処理、トラップ処理、メモリ管理などを行う。
したがって、実際に外付けできるコプロセッサは3個までである。
オプションの R2010 FPUをコプロセッサとして接続できる。
R2010は32ビットの浮動小数点レジスタを32本持ち、倍精度演算では64ビットレジスタ16本として使用できる。
R2000の後継としてR3000が1988年に登場した。
命令およびデータ向けにそれぞれ32KB(間もなく64KBに拡大)のキャッシュを追加し、マルチプロセッシングのためのキャッシュコヒーレンシにも配慮していた。
そのマルチプロセッササポートには欠陥があったが、R3000で何とかマルチプロセッサ構成にした製品がいくつか存在した。
R3000には当時の他のマイクロプロセッサと同様にメモリ管理ユニット (MMU) も組み込まれていた。
R3000にもR2000のときと同様に R3010 FPUが存在した。
MIPSアーキテクチャのプロセッサとしては初めて市場で成功を収め、累計100万個以上が生産された。
改良によって最高40MHzで動作するR3000Aが登場し、32VUPs (VAX Unit of Performance)の性能を発揮した。
R3000A互換の R3051 はソニー・コンピュータエンタテインメントのPlayStationに採用され、33.8688MHzで動作した。
サードパーティはR3000AとR3010をワンチップ化したものを設計しており、Performance Semiconductor のPR3400、IDTのR3500、NECのVR3600がある。
東芝のTX3900はSoCであり、Windows CE の動作するハンドヘルドPC向けに開発された。
航空宇宙分野向けに電磁波耐性を強化したMongoose-VもR3000とR3010をワンチップ化していた。
R4000シリーズは1991年に登場した。
命令セットを完全な64ビット対応に拡張し、FPUをCPUチップに統合し、従来よりずっと高いクロック周波数で動作した(当初は100MHz)。
しかし、クロック周波数を上げるために一次キャッシュは命令とデータそれぞれ8KBに減らされ、キャッシュアクセスに3サイクルかかるようになった。
動作周波数を上げるため、スーパーパイプラインと呼ばれるパイプライン段数を増やす工夫を行っている。
改良版のR4400は1993年に登場。一次キャッシュが16KBに倍増され、64ビット関連のバグ(エラッタ)が一掃され、より大きな二次キャッシュをサポートしている。
SGIの一部門となったミップスは外部バスを32ビットに縮小した低価格のR4200を設計し、さらに安価なR4300iのベースとなった。
R4300iをベースとしてNECが開発したVR4300はゲーム機のNINTENDO 64に採用された[22]。
R4700 Orion の底面のカバーを外してチップ本体が見えるようにしたもの。Quantum Effect Devices が設計し、IDTが製造した。
R4700 Orion の上面
ミップスの元従業員が創業した Quantum Effect Devices (QED) は、R4600 Orion、R4700 Orion、R4650、R5000を設計した。
R4000がクロック周波数を上げるためにキャッシュ容量を犠牲にしたのに対して、QEDは2サイクルでアクセスできる大きなキャッシュを搭載し、シリコンの面積の効率的利用を達成した。
R4600とR4700は SGI Indy の低価格版で採用され、シスコのルーター(36×0、7×00など)でもMIPSアーキテクチャとして初めて採用された。
R4650はWebTVのセットトップボックスで採用された。
R5000は単精度浮動小数点演算性能を向上させており、同クロック周波数のR4400を搭載した同型機(SGI Indy)よりもグラフィックス描画が高速になった。
SGIは同じグラフィックスボードでもR5000向けは名称を変更し、性能が高いことを強調した。
QEDはその後、ネットワーク機器やレーザープリンターなどの組み込み市場向けにRM7000とRM9000というファミリーを設計した[23]。
RM7000は256KBの二次キャッシュをチップ上に搭載し、三次キャッシュのコントローラも備えていた。
RM9xx0はSOCファミリーで、CPUにメモリコントローラ、PCIコントローラ、ギガビット・イーサネットのコントローラ、HyperTransportポートなどの高速I/Oといったノースブリッジ機能を集積している。
QEDは2000年8月、半導体企業 PMC-Sierra に買収され、PMC-SierraがMIPSアーキテクチャのプロセッサ開発を継続している。
R8000(1994年)はミップスの設計による初のスーパースケーラ方式で、複数の命令を同時に実行可能となった。
ワンチップではなく、CPU+一次キャッシュ(命令・データそれぞれ16KB)、FPU、二次キャッシュのタグRAMチップ×3(2個はキャッシュアクセス用、1つはバススヌープ用)、キャッシュコントローラの6個のチップで構成されている。
完全にパイプライン化された加算・乗算ユニットを2つ持ち、外付けの4MBの二次キャッシュからFPUが直接データを取ってくる設計である。
SGIの POWER Challenge サーバで採用され、後に POWER Indigo2 ワークステーションでも採用された。
しかし浮動小数点演算性能は高いが整数演算性能はあまり高くないため科学技術計算などにしか向かず、また複数チップで構成されるためコストが高く、SGI以外では採用例がない。
1995年R10000がリリースされた。
シングルチップでR8000よりも高いクロック周波数で動作し、一次キャッシュは命令・データ共に32KBと大きい。
スーパースケーラ設計だが、最大の改良点はアウト・オブ・オーダー実行を採用した点である。メモリ・パイプラインは1つしかなく、FPUもR8000より単純だが、整数演算性能が大幅に強化されており、低コストでもあったため、市場で成功を収めた。
その後の設計は全てR10000コアをベースとしている。R12000は0.25μmプロセスを採用してチップを縮小し、クロック周波数を高めている。それを改良したR14000でもクロック周波数を向上させると共に、外付けの二次キャッシュに DDR SRAM を利用可能にした。その後もクロック周波数を向上させ内蔵キャッシュ容量を増加させたR16000とR16000Aがリリースされた。
他にもMIPSファミリーにはR6000(1991年)がある。ECLで実装したもので、Bipolar Integrated Technology が製造した。R6000では MIPS II 命令セットが初めて採用された。TLBとキャッシュのアーキテクチャが他のMIPSファミリーとは大きく異なる。発表したとおりの性能を発揮できなかったが、CDCがサーバに採用した。しかし、すぐに市場から姿を消した。
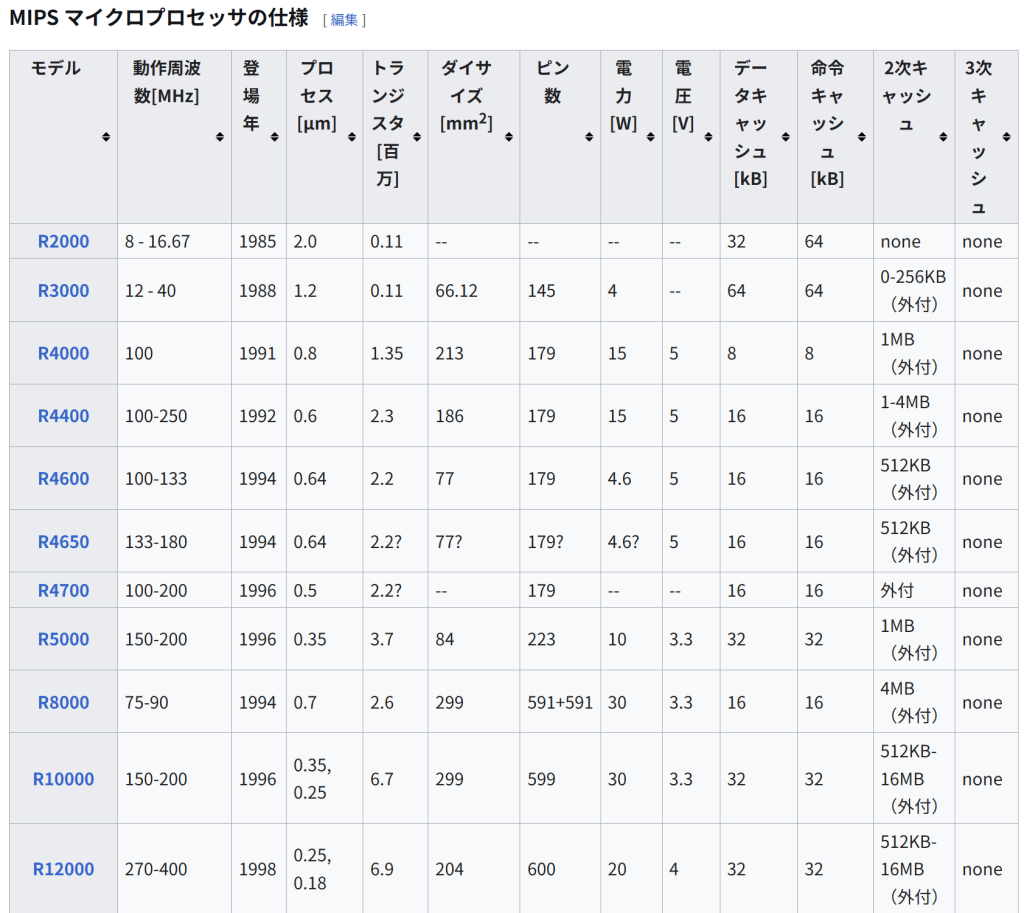
MIPS マイクロプロセッサの仕様
モデル 動作周波数[MHz] 登場年 プロセス[μm] トランジスタ[百万] ダイサイズ[mm2] ピン数 電力[W] 電圧[V] データキャッシュ[kB] 命令キャッシュ[kB] 2次キャッシュ 3次キャッシュ
R2000 8 – 16.67 1985 2.0 0.11 — — — — 32 64 none none
R3000 12 – 40 1988 1.2 0.11 66.12 145 4 — 64 64 0-256KB (外付) none
R4000 100 1991 0.8 1.35 213 179 15 5 8 8 1MB (外付) none
R4400 100-250 1992 0.6 2.3 186 179 15 5 16 16 1-4MB (外付) none
R4600 100-133 1994 0.64 2.2 77 179 4.6 5 16 16 512KB (外付) none
R4650 133-180 1994 0.64 2.2? 77? 179? 4.6? 5 16 16 512KB (外付) none
R4700 100-200 1996 0.5 2.2? — 179 — — 16 16 外付 none
R5000 150-200 1996 0.35 3.7 84 223 10 3.3 32 32 1MB (外付) none
R8000 75-90 1994 0.7 2.6 299 591+591 30 3.3 16 16 4MB (外付) none
R10000 150-200 1996 0.35, 0.25 6.7 299 599 30 3.3 32 32 512KB-16MB (外付) none
R12000 270-400 1998 0.25, 0.18 6.9 204 600 20 4 32 32 512KB-16MB (外付) none
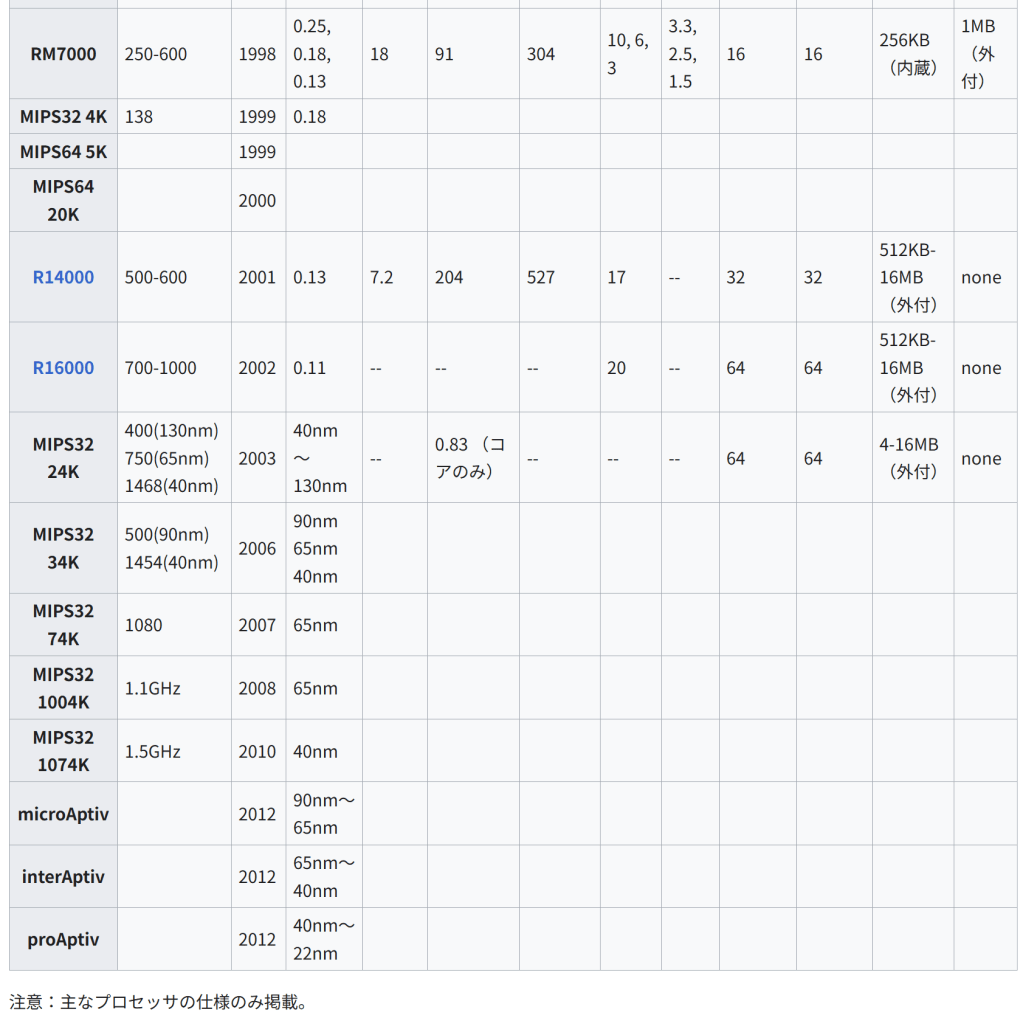
RM7000 250-600 1998 0.25, 0.18, 0.13 18 91 304 10, 6, 3 3.3, 2.5, 1.5 16 16 256KB (内蔵) 1MB (外付)
MIPS32 4K 138 1999 0.18
MIPS64 5K 1999
MIPS64 20K 2000
R14000 500-600 2001 0.13 7.2 204 527 17 — 32 32 512KB-16MB (外付) none
R16000 700-1000 2002 0.11 — — — 20 — 64 64 512KB-16MB (外付) none
MIPS32 24K 400(130nm)
750(65nm)
1468(40nm) 2003 40nm 〜 130nm — 0.83 (コアのみ) — — — 64 64 4-16MB (外付) none
MIPS32 34K 500(90nm)
1454(40nm) 2006 90nm
65nm
40nm
MIPS32 74K 1080 2007 65nm
MIPS32 1004K 1.1GHz 2008 65nm
MIPS32 1074K 1.5GHz 2010 40nm
microAptiv 2012 90nm~65nm
interAptiv 2012 65nm~40nm
proAptiv 2012 40nm~22nm
注意:主なプロセッサの仕様のみ掲載。
MIPS I の命令形式
命令は R、I、Jの3種類に分類される。どの命令も先頭に6ビットのオペコードがある。Rタイプではオペコードの次に3本のレジスタを指定するフィールドがあり、シフト量を指定するフィールド、機能を指定するフィールドが続く。Iタイプでは2つのレジスタを指定するフィールドと16ビットの即値のフィールドがある。 Jタイプでは、オペコードに続いて26ビットで分岐先アドレスを指定する[24][25]。
次表は主要な命令セットの3種類の形式を示したものである。
タイプ -31- フォーマット (ビット数) -0-
R オペコード (6) rs (5) rt (5) rd (5) シフト量 (5) 機能 (6)
I オペコード (6) rs (5) rt (5) 即値 (16)
J オペコード (6) アドレス (26)
MIPS アセンブリ言語
アセンブリ言語には、直接ハードウェア実装に対応した命令以外に複数命令の列に変換される「擬似命令」が存在する。
以下の表で、d、t、s といった文字はレジスタの番号や名前のためのプレースホルダーとなっている。
C は定数(即値)を示す。
オペコード及び機能のコードは16進数である。
MIPS32命令セットでは Add や Subtract 命令で使われる unsigned という用語が誤解を生みやすいとしている。それらの命令の signed と unsigned の違いはオペランドを符号拡張をするかしないかではなく、オーバーフロー発生時にトラップを起こすか (e.g. Add) 無視するか (Add unsigned) である。それらの命令の即値オペランド CONST は常に符号拡張される。
整数
MIPSアーキテクチャは32本の整数レジスタを持つ。算術処理を行うにはデータがレジスタ上になければならない。レジスタ$0は常に0であり、レジスタ$1はアセンブラが一時的に使用する(擬似命令や大きな定数を扱う場合)。
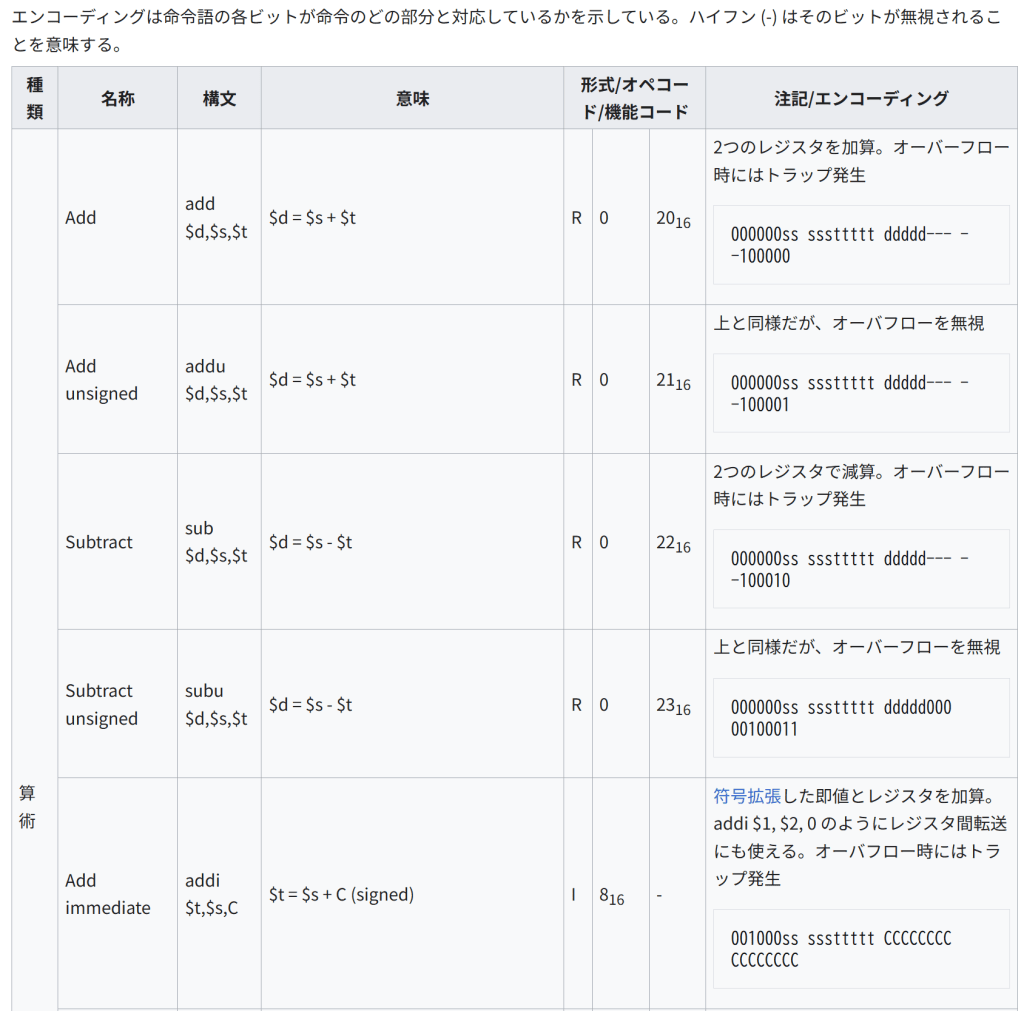
エンコーディングは命令語の各ビットが命令のどの部分と対応しているかを示している。ハイフン (-) はそのビットが無視されることを意味する。
種類 名称 構文 意味 形式/オペコード/機能コード 注記/エンコーディング
算術 Add add $d,$s,$t $d = $s + $t R 0 2016 2つのレジスタを加算。オーバーフロー時にはトラップ発生
000000ss sssttttt ddddd— –100000
Add unsigned addu $d,$s,$t $d = $s + $t R 0 2116 上と同様だが、オーバフローを無視
000000ss sssttttt ddddd— –100001
Subtract sub $d,$s,$t $d = $s – $t R 0 2216 2つのレジスタで減算。オーバーフロー時にはトラップ発生
000000ss sssttttt ddddd— –100010
Subtract unsigned subu $d,$s,$t $d = $s – $t R 0 2316 上と同様だが、オーバーフローを無視
000000ss sssttttt ddddd000 00100011
Add immediate addi $t,$s,C $t = $s + C (signed) I 816 – 符号拡張した即値とレジスタを加算。addi $1, $2, 0 のようにレジスタ間転送にも使える。オーバフロー時にはトラップ発生
001000ss sssttttt CCCCCCCC CCCCCCCC
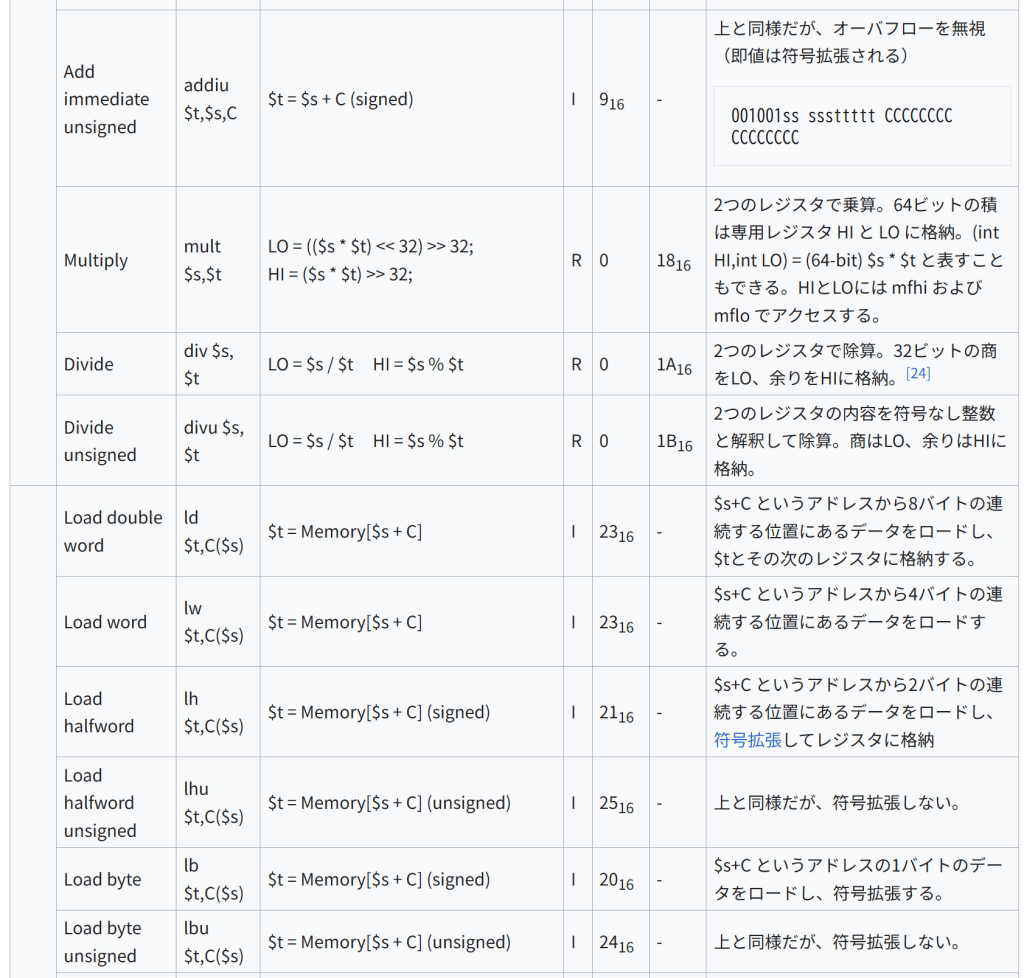
Add immediate unsigned addiu $t,$s,C $t = $s + C (signed) I 916 – 上と同様だが、オーバフローを無視(即値は符号拡張される)
001001ss sssttttt CCCCCCCC CCCCCCCC
Multiply mult $s,$t LO = (($s * $t) << 32) >> 32;
HI = ($s * $t) >> 32; R 0 1816 2つのレジスタで乗算。64ビットの積は専用レジスタ HI と LO に格納。(int HI,int LO) = (64-bit) $s * $t と表すこともできる。HIとLOには mfhi および mflo でアクセスする。
Divide div $s, $t LO = $s / $t HI = $s % $t R 0 1A16 2つのレジスタで除算。32ビットの商をLO、余りをHIに格納。[24]
Divide unsigned divu $s, $t LO = $s / $t HI = $s % $t R 0 1B16 2つのレジスタの内容を符号なし整数と解釈して除算。商はLO、余りはHIに格納。
データ転送 Load double word ld $t,C($s) $t = Memory[$s + C] I 2316 – $s+C というアドレスから8バイトの連続する位置にあるデータをロードし、$tとその次のレジスタに格納する。
Load word lw $t,C($s) $t = Memory[$s + C] I 2316 – $s+C というアドレスから4バイトの連続する位置にあるデータをロードする。
Load halfword lh $t,C($s) $t = Memory$s + C I 2116 – $s+C というアドレスから2バイトの連続する位置にあるデータをロードし、符号拡張してレジスタに格納
Load halfword unsigned lhu $t,C($s) $t = Memory$s + C I 2516 – 上と同様だが、符号拡張しない。
Load byte lb $t,C($s) $t = Memory$s + C I 2016 – $s+C というアドレスの1バイトのデータをロードし、符号拡張する。
Load byte unsigned lbu $t,C($s) $t = Memory$s + C I 2416 – 上と同様だが、符号拡張しない。
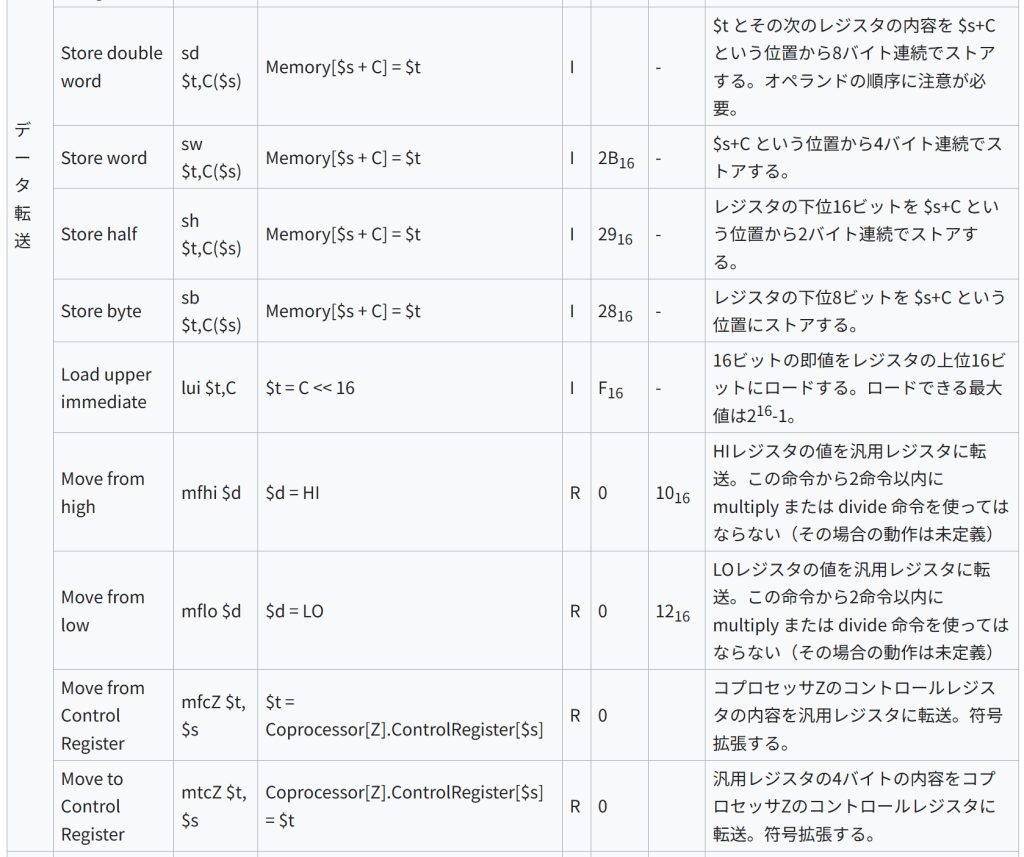
Store double word sd $t,C($s) Memory[$s + C] = $t I – $t とその次のレジスタの内容を $s+C という位置から8バイト連続でストアする。オペランドの順序に注意が必要。
Store word sw $t,C($s) Memory[$s + C] = $t I 2B16 – $s+C という位置から4バイト連続でストアする。
Store half sh $t,C($s) Memory[$s + C] = $t I 2916 – レジスタの下位16ビットを $s+C という位置から2バイト連続でストアする。
Store byte sb $t,C($s) Memory[$s + C] = $t I 2816 – レジスタの下位8ビットを $s+C という位置にストアする。
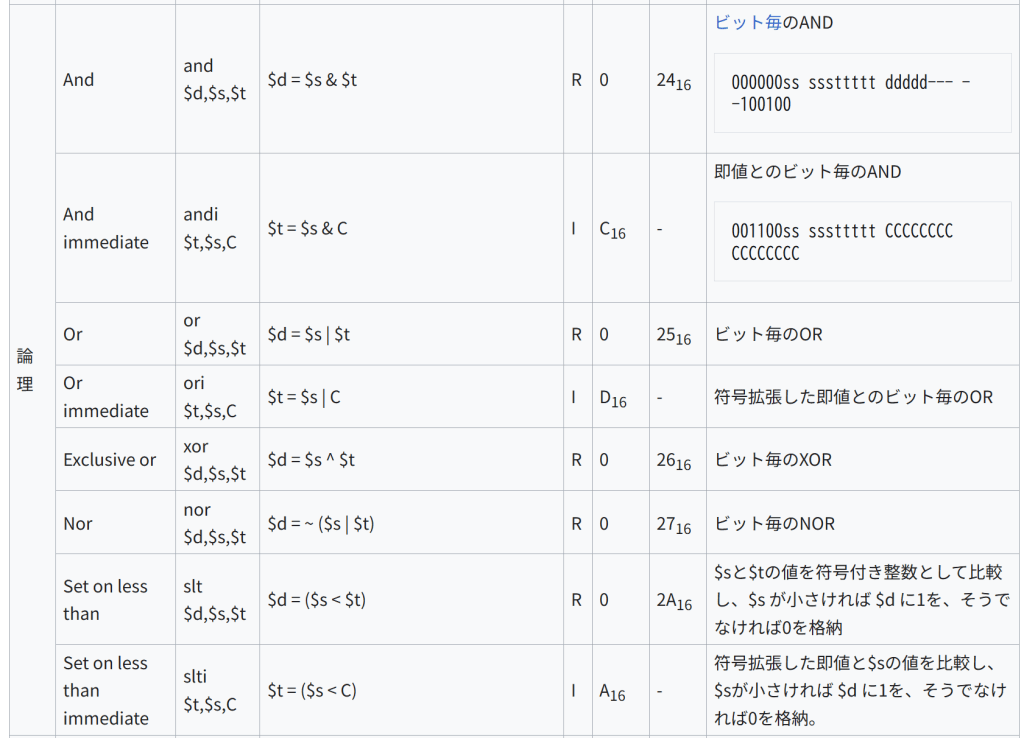
Load upper immediate lui $t,C $t = C << 16 I F16 – 16ビットの即値をレジスタの上位16ビットにロードする。ロードできる最大値は216-1。 Move from high mfhi $d $d = HI R 0 1016 HIレジスタの値を汎用レジスタに転送。この命令から2命令以内に multiply または divide 命令を使ってはならない(その場合の動作は未定義) Move from low mflo $d $d = LO R 0 1216 LOレジスタの値を汎用レジスタに転送。この命令から2命令以内に multiply または divide 命令を使ってはならない(その場合の動作は未定義) Move from Control Register mfcZ $t, $s $t = Coprocessor[Z].ControlRegister[$s] R 0 コプロセッサZのコントロールレジスタの内容を汎用レジスタに転送。符号拡張する。 Move to Control Register mtcZ $t, $s Coprocessor[Z].ControlRegister[$s] = $t R 0 汎用レジスタの4バイトの内容をコプロセッサZのコントロールレジスタに転送。符号拡張する。 論理 And and $d,$s,$t $d = $s & $t R 0 2416 ビット毎のAND 000000ss sssttttt ddddd— –100100 And immediate andi $t,$s,C $t = $s & C I C16 – 即値とのビット毎のAND 001100ss sssttttt CCCCCCCC CCCCCCCC Or or $d,$s,$t $d = $s | $t R 0 2516 ビット毎のOR Or immediate ori $t,$s,C $t = $s | C I D16 – 符号拡張した即値とのビット毎のOR Exclusive or xor $d,$s,$t $d = $s ^ $t R 0 2616 ビット毎のXOR Nor nor $d,$s,$t $d = ~ ($s | $t) R 0 2716 ビット毎のNOR Set on less than slt $d,$s,$t $d = ($s < $t) R 0 2A16 $sと$tの値を符号付き整数として比較し、$s が小さければ $d に1を、そうでなければ0を格納 Set on less than immediate slti $t,$s,C $t = ($s < C) I A16 – 符号拡張した即値と$sの値を比較し、$sが小さければ $d に1を、そうでなければ0を格納。 シフト Shift left logical sll $d,$t,C $d = $t << C R 0 0 $sの内容をCビット左にシフト。 2 C O N S T {\displaystyle 2^{CONST}} をかけるのと同等 Shift right logical srl $d,$t,C $d = $t >> C R 0 216 $sの内容をCビットだけ右にシフト。シフトされて空いた上位ビットには0を格納。正の整数を
2
C
{\displaystyle 2^{C}} で割ったのと同等。
Shift right arithmetic sra $d,$t,C
$
d
$
t
>
C
+
(
(
∑n
1
CONST
2
31
−
n
)
⋅
$
2
>
31
)
{\displaystyle \scriptstyle \$d=\$t>>C+\left(\left(\sum _{n=1}^{\text{CONST}}2^{31-n}\right)\cdot \$2>>31\right)} R 0 316 $sの内容をCビットだけ右にシフト。シフトされた空いた上位ビットは元の値を符号付整数と解釈して符号拡張する。2の補数で表された符号付整数を
2
C
{\displaystyle 2^{C}} で割ったのと同等。
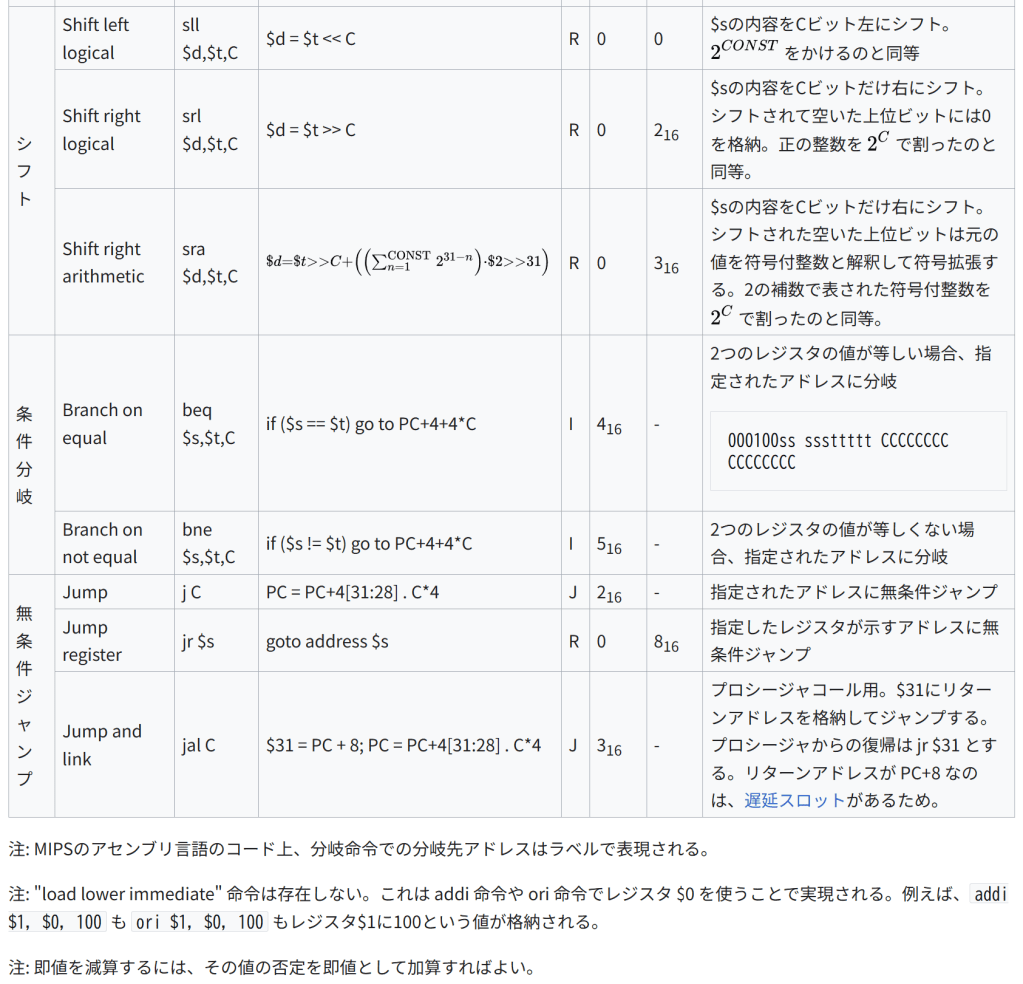
条件分岐 Branch on equal beq $s,$t,C if ($s == $t) go to PC+4+4C I 416 – 2つのレジスタの値が等しい場合、指定されたアドレスに分岐 000100ss sssttttt CCCCCCCC CCCCCCCC Branch on not equal bne $s,$t,C if ($s != $t) go to PC+4+4C I 516 – 2つのレジスタの値が等しくない場合、指定されたアドレスに分岐
無条件ジャンプ Jump j C PC = PC+4[31:28] . C4 J 216 – 指定されたアドレスに無条件ジャンプ Jump register jr $s goto address $s R 0 816 指定したレジスタが示すアドレスに無条件ジャンプ Jump and link jal C $31 = PC + 8; PC = PC+4[31:28] . C4 J 316 – プロシージャコール用。$31にリターンアドレスを格納してジャンプする。プロシージャからの復帰は jr $31 とする。リターンアドレスが PC+8 なのは、遅延スロットがあるため。
注: MIPSのアセンブリ言語のコード上、分岐命令での分岐先アドレスはラベルで表現される。
注: “load lower immediate” 命令は存在しない。これは addi 命令や ori 命令でレジスタ $0 を使うことで実現される。例えば、addi $1, $0, 100 も ori $1, $0, 100 もレジスタ$1に100という値が格納される。
注: 即値を減算するには、その値の否定を即値として加算すればよい。
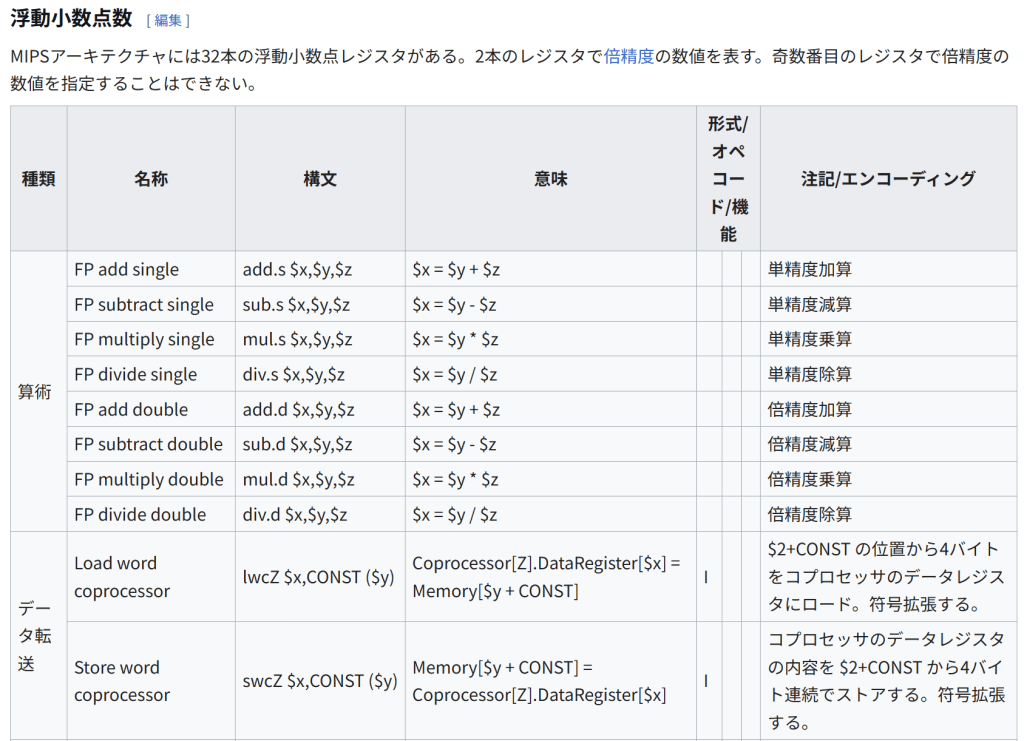
浮動小数点数
MIPSアーキテクチャには32本の浮動小数点レジスタがある。2本のレジスタで倍精度の数値を表す。奇数番目のレジスタで倍精度の数値を指定することはできない。
種類 名称 構文 意味 形式/オペコード/機能 注記/エンコーディング
算術 FP add single add.s $x,$y,$z $x = $y + $z 単精度加算
FP subtract single sub.s $x,$y,$z $x = $y – $z 単精度減算
FP multiply single mul.s $x,$y,$z $x = $y * $z 単精度乗算
FP divide single div.s $x,$y,$z $x = $y / $z 単精度除算
FP add double add.d $x,$y,$z $x = $y + $z 倍精度加算
FP subtract double sub.d $x,$y,$z $x = $y – $z 倍精度減算
FP multiply double mul.d $x,$y,$z $x = $y * $z 倍精度乗算
FP divide double div.d $x,$y,$z $x = $y / $z 倍精度除算
データ転送 Load word coprocessor lwcZ $x,CONST ($y) Coprocessor[Z].DataRegister[$x] = Memory[$y + CONST] I $2+CONST の位置から4バイトをコプロセッサのデータレジスタにロード。符号拡張する。
Store word coprocessor swcZ $x,CONST ($y) Memory[$y + CONST] = Coprocessor[Z].DataRegister[$x] I コプロセッサのデータレジスタの内容を $2+CONST から4バイト連続でストアする。符号拡張する。
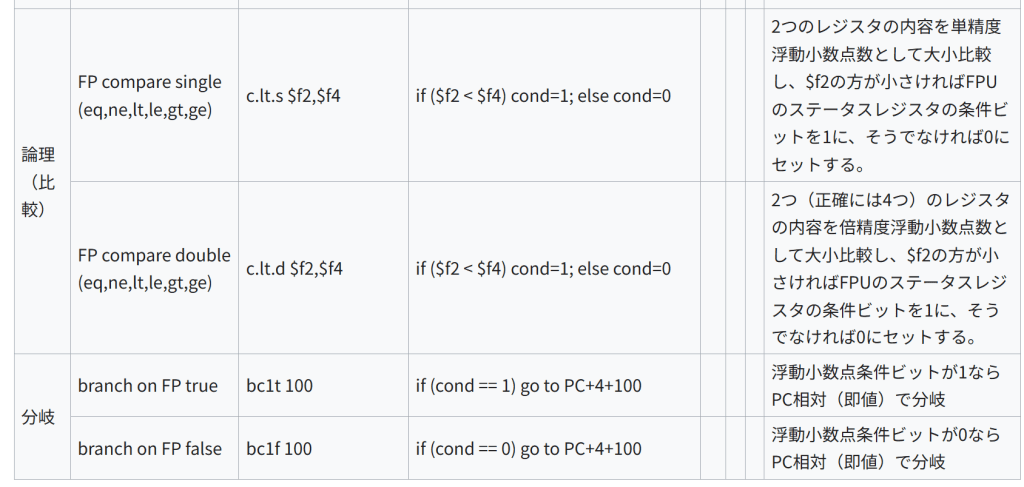
論理(比較) FP compare single (eq,ne,lt,le,gt,ge) c.lt.s $f2,$f4 if ($f2 < $f4) cond=1; else cond=0 2つのレジスタの内容を単精度浮動小数点数として大小比較し、$f2の方が小さければFPUのステータスレジスタの条件ビットを1に、そうでなければ0にセットする。
FP compare double (eq,ne,lt,le,gt,ge) c.lt.d $f2,$f4 if ($f2 < $f4) cond=1; else cond=0 2つ(正確には4つ)のレジスタの内容を倍精度浮動小数点数として大小比較し、$f2の方が小さければFPUのステータスレジスタの条件ビットを1に、そうでなければ0にセットする。
分岐 branch on FP true bc1t 100 if (cond == 1) go to PC+4+100 浮動小数点条件ビットが1ならPC相対(即値)で分岐
branch on FP false bc1f 100 if (cond == 0) go to PC+4+100 浮動小数点条件ビットが0ならPC相対(即値)で分岐
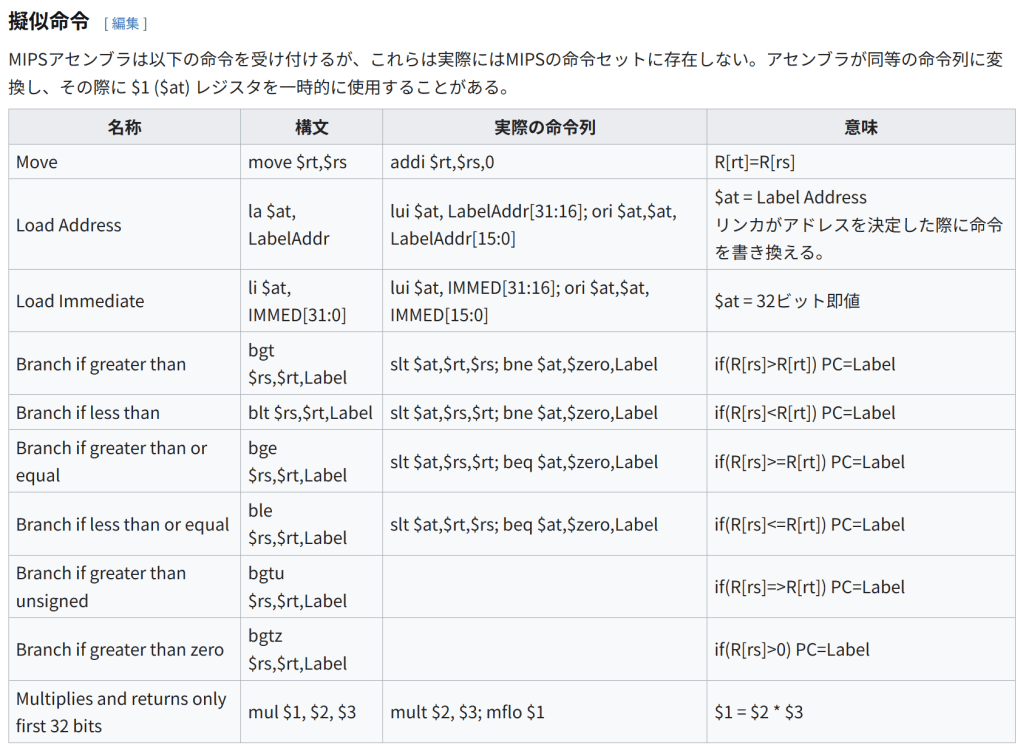
擬似命令
MIPSアセンブラは以下の命令を受け付けるが、これらは実際にはMIPSの命令セットに存在しない。アセンブラが同等の命令列に変換し、その際に $1 ($at) レジスタを一時的に使用することがある。
名称 構文 実際の命令列 意味
Move move $rt,$rs addi $rt,$rs,0 R[rt]=R[rs]
Load Address la $at, LabelAddr lui $at, LabelAddr[31:16]; ori $at,$at, LabelAddr[15:0] $at = Label Address
リンカがアドレスを決定した際に命令を書き換える。
Load Immediate li $at, IMMED[31:0] lui $at, IMMED[31:16]; ori $at,$at, IMMED[15:0] $at = 32ビット即値
Branch if greater than bgt $rs,$rt,Label slt $at,$rt,$rs; bne $at,$zero,Label if(R[rs]>R[rt]) PC=Label
Branch if less than blt $rs,$rt,Label slt $at,$rs,$rt; bne $at,$zero,Label if(R[rs]=R[rt]) PC=Label
Branch if less than or equal ble $rs,$rt,Label slt $at,$rt,$rs; beq $at,$zero,Label if(R[rs]<=R[rt]) PC=Label Branch if greater than unsigned bgtu $rs,$rt,Label if(R[rs]=>R[rt]) PC=Label
Branch if greater than zero bgtz $rs,$rt,Label if(R[rs]>0) PC=Label
Multiplies and returns only first 32 bits mul $1, $2, $3 mult $2, $3; mflo $1 $1 = $2 * $3
その他の命令
NOP命令。通常 sll $0,$0,0 という命令を使い、その機械語コードは 0x00000000 となる。
break命令。デバッガでのブレークポイント設定で使用する。
syscall命令。オペレーティングシステムのシステムコールに使われ、ユーザーモードからカーネルモードに移行する。
コンパイラのレジスタ使用規則
ハードウェアのアーキテクチャにより、以下のことが定められている。
汎用レジスタ $0 は常に 0 という値を返す。このレジスタに値を書いても変化はしないし、書いた値は消失する。
汎用レジスタ $31 は jal (jump and link) 命令でリンクレジスタとして使われる。
HIおよびLOレジスタは乗除算の結果へのアクセスに使われ、mfhi (move from high) 命令と mflo 命令がそのためにある。
汎用レジスタを使う際のハードウェア上の制限はこれだけである。
各種MIPSツールチェーンでは、レジスタをどのように使うかについて呼出規約を定めている。これはツールチェーンのソフトウェアが定めているもので、ハードウェアにそのような制限があるわけではない。
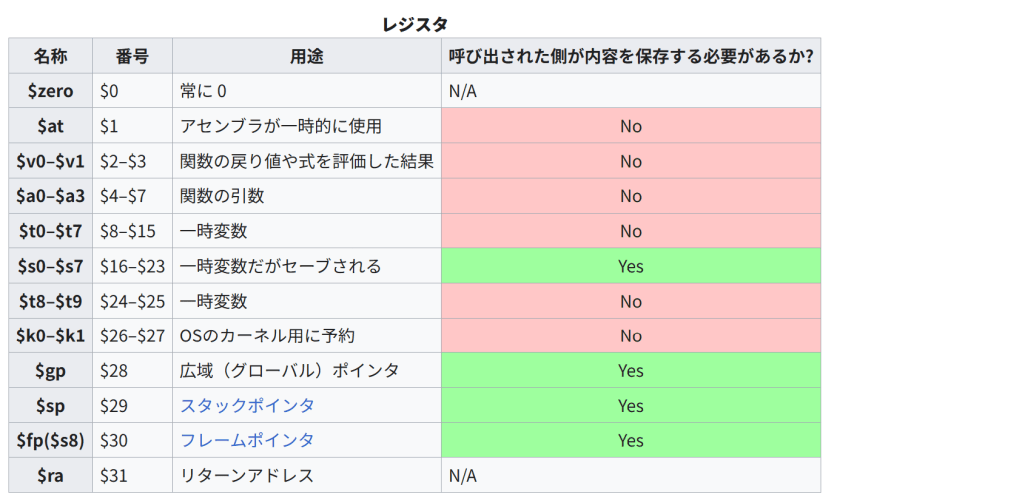
レジスタ
名称 番号 用途 呼び出された側が内容を保存する必要があるか?
$zero $0 常に 0 N/A
$at $1 アセンブラが一時的に使用 No
$v0–$v1 $2–$3 関数の戻り値や式を評価した結果 No
$a0–$a3 $4–$7 関数の引数 No
$t0–$t7 $8–$15 一時変数 No
$s0–$s7 $16–$23 一時変数だがセーブされる Yes
$t8–$t9 $24–$25 一時変数 No
$k0–$k1 $26–$27 OSのカーネル用に予約 No
$gp $28 広域(グローバル)ポインタ Yes
$sp $29 スタックポインタ Yes
$fp($s8) $30 フレームポインタ Yes
$ra $31 リターンアドレス N/A
呼び出された側が保存すると定められているレジスタは、サブルーチンや関数の呼び出しやシステムコールでも保持される。例えば、$s-レジスタをルーチン内で使うときは、その内容をスタックに一時的に退避させなければならない。$sp と $fp はルーチンに入ってきたときにセーブされ、それぞれルーチン固有の固定値でインクリメントされる。そして、そのルーチンから戻るときに元の値に戻す。一方 $ra は jal 命令でルーチンに飛び込むときに自動的に変更される。$t-レジスタはサブルーチンを呼び出すと内容が破壊されるので、必要なら呼び出す側がセーブしておかなければならない。
シミュレータ
Open Virtual Platforms (OVP)[26] では、非商用利用に限って無料で使えるシミュレータ OVPsim、プロセッサや周辺機器やプラットフォームのモデルのライブラリ、ユーザーが独自のモデルを開発できるAPIなどを提供している。ライブラリに含まれるモデルはオープンソースでC言語で書かれており、MIPSの 4K, 24K, 34K, 74K, 1004K, 1074K, M14K といったコアが揃っている。それらのモデルの開発と保守は Imperas が行っており[27]、ミップス・テクノロジーズの協力の下で評価し MIPS-Verified ™ というマークをもらっている。MIPSベースのプラットフォームのモデルとしては、非常に単純なものとLinuxのバイナリイメージをブートできるものが用意されている。それらのプラットフォーム・エミュレータはソースとバイナリの形で提供されており、高速で使いやすい。
また、教育向けのMIPS32(当初はR2000/R3000をシミュレートしていた)のフリーなシミュレータ SPIM がある[28]。EduMIPS64[29] は、GPLライセンスのグラフィカルなMIPS64シミュレータで、Java/Swingで書かれている。MIPS64 ISA の大部分をカバーするサブセットをサポートしており、アセンブリ言語で書かれたプログラムを実行したときCPU内のパイプラインで何が起きているかをグラフィカルに表示する。こちらも教育向けで、世界各地の大学で利用されている。
MARS[30] もGUIベースのMIPSエミュレータで教育向けに作られており、特にヘネシーの『コンピュータの構成と設計』を教科書として使う際に役立つよう設計されている。
より実用的なフリーなエミュレータとしてGXemulやQEMUプロジェクトのものがある。MIPS III および IV のプロセッサをエミュレートでき、コンピュータシステム全体のエミュレートも可能である。
商用のシミュレータは主に組み込み用MIPSプロセッサを対象としたものが存在する。例えば、Virtutech Simics (MIPS 4Kc and 5Kc, PMC RM9000, QED RM7000)、VaST Systems (R3000, R4000)、CoWare (MIPS4KE, MIPS24K, MIPS25Kf, MIPS34K) がある。
脚注
[脚注の使い方]
注釈
^ MIPS社のR4000が登場する頃には、DEC社は自社製RISCマイクロプロセッサAlphaを完成させてこれに切り替えた。
^ R4000は、スーパーパイプラインを世界で最初に導入した市販のマイクロプロセッサである。しかし、これによって、”Microprocessor with Interlocked Pipeline Stages” パイプライン・ステージがインターロックされるマイクロプロセッサと揶揄されることになった。
出典
^ “MIPS32 Architecture”. ミップス・テクノロジーズ. 2009年5月27日閲覧。
^ “MIPS64 Architecture”. ミップス・テクノロジーズ. 2009年5月27日閲覧。
^ “MIPS-3D ASE”. ミップス・テクノロジーズ. 2009年5月27日閲覧。
^ “MIPS16e”. ミップス・テクノロジーズ. 2021年1月14日閲覧。
^ “MIPS MT ASE”. ミップス・テクノロジーズ. 2009年5月27日閲覧。
^ University of California, Davis. “ECS 142 (Compilers) References & Tools page”. 2009年5月28日閲覧。
^ Rubio, Victor P. “A FPGA Implementation of a MIPS RISC Processor for Computer Architecture Education”. New Mexico State University. 2011年12月22日閲覧。
^ a b 神保進一著、『マイクロプロセッサ テクノロジ』、日経BP社、1999年12月6日第1版第1刷発行、ISBN 4822209261
^ Morgan Kaufmann Publishers, Computer Organization and Design, David A. Patterson & John L. Hennessy, Edition 3, ISBN 1-55860-604-1, page 63
^ “Earl Killian”. Paravirtual. (2010年11月26日) 2010年11月26日閲覧。 ⚠
^ “S-1 Supercomputer Alumni: Earl Killian”. Clemson University. (2005年6月28日) 2010年11月26日閲覧. “Earl Killian’s early work w… As MIPS’s Director of Architecture, he designed the MIPS III 64-bit instruction-set extension, and led the work on the R4000 microarchitecture. He was a cofounder of QED, which created the R4600 and R5000 MIPS processors. Most recently he was chief architect at Tensilica working on configurable/extensible processors.” ⚠
^ Jochen Liedtke(1995). On micro kernel construction. 15th Symposium on Operating Systems Principles, Copper Mountain Resort, Colorado.
^ “MIPS® Architecture For Programmers Volume II-A: The MIPS32® Instruction Set Document Number: MD00086 Revision 5.04 December 11, 2013”. p. 41. 2023年12月9日閲覧。
^ SGI announcing the end of MIPS – ウェイバックマシン(2008年3月7日アーカイブ分)
^ CPUコアベンダからの脱却 – 変貌するMIPS Technologiesの実像を探る
^ http://www.mdronline.com/mpr/h/2006/0626/202602.html China’s Microprocessor Dilemma
^ China’s Institute of Computing Technology Licenses Industry-Standard MIPS Architectures
^ “LinuxDevices article about the Municator”. 2012年12月16日時点のオリジナルよりアーカイブ。2010年12月12日閲覧。
^ “Yeelong Specs”. 2012年12月10日時点のオリジナルよりアーカイブ。2010年12月12日閲覧。 (LinuxDevices, Oct. 22, 2008)
^ “Silicon Graphics Introduces Enhanced MIPS Architecture to Lead the Interactive Digital Revolution”. Silicon Graphics, Inc. (1996年10月21日). 2011年2月25日閲覧。
^ a b Gwennap, Linley (18 November 1996). “Digital, MIPS Add Multimedia Extensions”. Microprocessor Report. pp. 24–28.
^ NEC Offers Two High Cost Performance 64-bit RISC Microprocessors
^ 編集人 山形孝雄「PMC-Sierra RMシリーズの概要とRM7900&RM900x2Gの詳細」『Interface2004年7月号』CQ出版社、2004年7月1日、77-88頁。ISSN 0387-9569。
^ a b MIPS R3000 Instruction Set Summary
^ MIPS Instruction Reference
^ Welcome Page | Open Virtual Platforms
^ Welcome to Imperas | Imperas
^ James Larus. “SPIM MIPS Simulator”. 2007年3月4日閲覧。
^ EduMIPS64
^ MARS MIPS simulator – Missouri State University
参考文献
David A. Patterson and John L. Hennessy (2007). Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann Publishers. ISBN 978-0-12-370606-5
David A. Patterson and John L. Hennessy; 成田光彰 (2006). コンピュータの構成と設計 第3版(上) ハードウエアとソフトウエアのインタフェース. 日経BP. ISBN 4-8222-8266-X
David A. Patterson and John L. Hennessy; 成田光彰 (2006). コンピュータの構成と設計 第3版(下) ハードウエアとソフトウエアのインタフェース. 日経BP. ISBN 4-8222-8267-8
プロセッサを中心としたコンピュータの設計全般に関する書籍で、命令セットの例としてMIPSアーキテクチャを取り上げている。MIPS開発者であるジョン・L・ヘネシーも著者の一人である。
Dominic Sweetman. See MIPS Run. Morgan Kaufmann Publishers. ISBN 1-55860-410-3
MIPSアーキテクチャについての決定版的な本。ハードウェアアーキテクチャだけでなく、コンパイラやOSについても詳述している。
Farquhar, Erin; Philip Bunce. MIPS Programmer’s Handbook. Morgan Kaufmann Publishers. ISBN 1-55860-297-6
関連項目
μClinux
PlayStation – CPUとしてR3000Aを搭載。
外部リンク
MIPS Architectures at MIPS Technologies
Full overview of MIPS architecture
Patterson & Hennessy – Appendix A
Summary of MIPS assembly language
MIPS Instruction reference
MARS (MIPS Assembler and Runtime Simulator)
MIPS processor images and descriptions at cpu-collection.de
A programmed introduction to MIPS assembly
Mips bitshift operators
MIPS software user’s manual
MIPS Architecture history diagram
MIPS Open initiative # 2018年12月17日(米国時間)にWave Computing社はMIPS Open(MIPS命令セットアーキテクチャ(ISA)のオープンソース化プログラム)を発表。
表話編歴
MIPSマイクロプロセッサ
表話編歴
プロセッサアーキテクチャ
典拠管理データベース: 国立図書館 ウィキデータを編集
イスラエルアメリカ
カテゴリ: MIPSアーキテクチャコンピュータアーキテクチャMIPSのマイクロプロセッサ命令セットアーキテクチャアドバンスドRISCコンソーシアム
最終更新 2025年1月30日 (木) 08:43 (日時は個人設定で未設定ならばUTC)。
テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。』
