知識蒸留:巨大なモデルの知識を抽出する
https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00040/?P=2

『PFN岡野原氏によるAI解説:第73回
岡野原 大輔
Preferred Networks 代表取締役 最高執行責任者
2021.07.09
全4450文字
この記事は日経Robotics 有料購読者向けの記事ですが
『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。
本記事はロボットとAI技術の専門誌『日経Robotics』のデジタル版です
[画像のクリックで別ページへ]
知識蒸留(以下、蒸留)は学習済みモデルの予測結果を学習目標として、他のモデルを学習させる手法である。アルコールの蒸留と同様にモデルから重要な知識だけを抽出することからこの名前が与えられている。
蒸留はモデル圧縮の手法として2015年にGeoffrey Hinton氏1)らによって提案(それ以前にも一般の機械学習などで提案されていたがニューラルネットワーク(NN)の分野ではHinton氏らが最初に提案)された。蒸留を使うことで大きなデータセットを大きなモデルで学習し、その結果を小さなモデルに移すことが可能である。
著者の岡野原大輔氏
機械学習のべき乗則(本コラム2021年3月号を参照)が示すように、学習データがいくらでも手に入る状況では、モデルが大きいほど汎化性能が高く、学習効率も高いことがわかっている。さらに大きなモデルであるほど少ないデータ数を使った転移学習でも高い性能を達成し、従来の半教師あり学習を大きく凌駕する性能を達成することがわかってきている2)。そのため、巨大なデータセットで巨大なモデルを事前学習しておき、その後に様々なタスク向けに少ないデータ数で学習するという動きが自然言語処理を中心に広がっている。』
『一方で大きなモデルは推論時の計算コストが大きいという問題があり、使用可能なハードウエアリソースに制約がある場合は使えない。そこで事前学習時には大きなモデルを利用して学習しておき、個別のタスクで使う場合には、大きなモデルをタスク専用の小さなモデルに蒸留して利用することが考えられ、蒸留が注目されている。
今回は、蒸留とは何か、なぜ汎化性能が高い大きなモデルを小さいモデルに蒸留できるのか、蒸留を成功させる条件とは何か、正則化としての蒸留について紹介していく。
蒸留とは
はじめに蒸留とは何かについて説明しよう1)。k
クラスからなる多クラス分類NNを教師ありデータを使って学習したとする。この学習済みNNの学習結果を異なるNNに移すことを考える。この学習済みNNを教師NNとよび、学習結果を移す先を生徒NNと呼ぶことにする。
教師NNと生徒NNは必ずしも同じネットワークアーキテクチャを持つ必要は無く、多くの場合は教師NNより生徒NNの方が小さいような問題設定を考える。これはモデル圧縮とみなすことができる。
通常の教師あり学習では、教師データの正解を目標に学習する。具体的には教師データの正解に対応するクラスの確率が1
であり、それ以外が0であるような分布とのクロスエントロピーを最小化するように学習する。これに対し、蒸留では教師NNの予測分布を目標とし、それとのクロスエントロピーを最小化するように学習する。あるデータに対する教師NNの予測結果をp1,p2,…,pkとし、生徒NNの予測結果をq1,q2,…,qk
とした時、この2つの分布間のクロスエントロピーは、以下のように定義される。
H(P,Q)=k∑i=1[−pilogqi]
このKLダイバージェンスを最小化するように生徒NNを学習させる。
通常の学習との違いは、教師NNの予測結果が正解ラベル以外にも確率を割り振っていることであり、蒸留は教師NNの間違い方も含め学習しているとみなせる。この正解ラベル以外の予測をHinton氏はDark Knowledge(暗黒知識)とよび、学習に重要だとしている。
蒸留を使うことで、あるモデルの学習結果を他の学習結果に移すことができる。この蒸留を使うケースはいくつかある。1つ目はモデル圧縮で教師NNが大きなモデルやアンサンブルなどでそのまま推論時に使うにはコストが大きい場合に、計算効率の高い小さいNNに移すという場合である。2つ目は正則化として蒸留することで元のモデルよりも汎化性能を改善できることであり、特に同じモデル間で移す自己蒸留である。これらについて紹介していこう。
なぜ汎化性能を保ったまま小さなモデルに蒸留できるのか
なぜ汎化性能が高い大きなモデルを小さなモデルに蒸留できるのか。これを理解するためには、なぜ大きなモデルが汎化するのかを理解する必要がある。
モデルサイズが大きい方が汎化性能が高くなる理由は大きく2つある。1つ目はモデルサイズが大きい方が汎化性能が高いフラットな解が見つかりやすくなること、2つ目はモデルがより多くのビュー(データの見方、CNNにおけるフィルタ)を持てるようになり、新しいデータに対してもうまく対応できる可能性が高くなることである3)。
これら2つを元になぜ小さいモデルに汎化性能を保ったまま蒸留できるかをみていこう。1つ目の最適化問題については、学習が終わって汎化性能が高いパラメータが決定されれば、最適化には必要だった冗長なパラメータを消去し、モデルを大幅に小さくすることができる。
2つ目は、もし実際使われるタスクが決まれば、そのタスクに必要の無いビューは捨てることができ小さくすることができる。
一方で、最初からタスクに特化した汎化性能が高い小さなNNを学習させることは難しい。
蒸留の成功条件
蒸留について多くの研究がなされてきたが、2021年6月に米グーグルBrainチームが発表した論文4)では蒸留を成功させる重要な条件を見つけたと報告した。
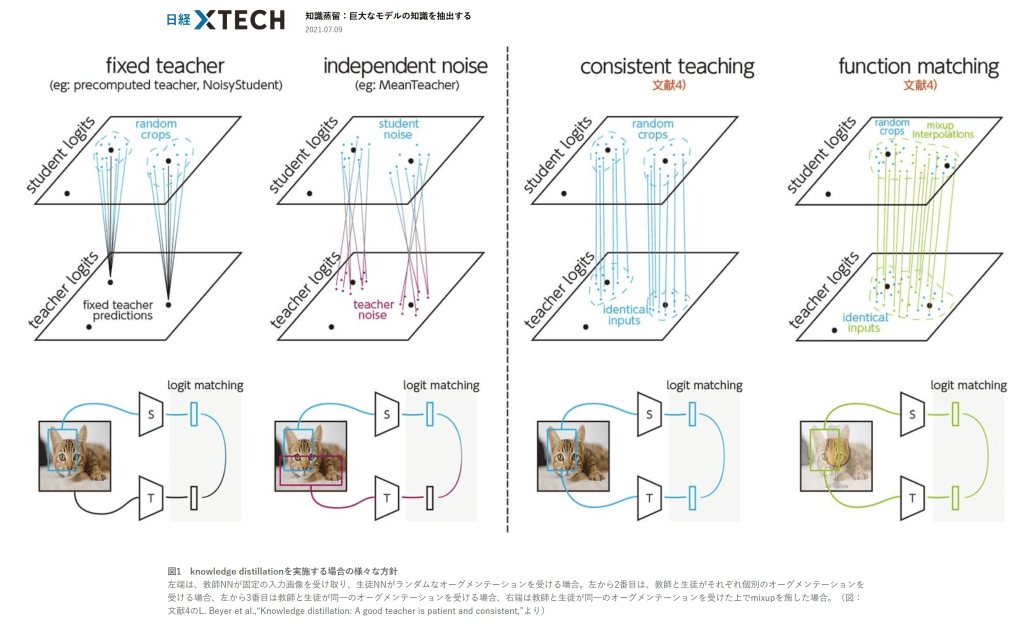
1つ目は教師NNと生徒NNが同じデータオーグメンテーションを適用した入力を使うことである。従来は目標となる教師NNの予測分布には計算資源の節約のために特定のデータオーグメンテーション(クロップなど)を適用して計算したものを毎回固定で使い、生徒NNには毎回異なるデータオーグメンテーションを使っていた。この場合、生徒NNからは教師NNの本当の予測とは違う目標を学習していることになる。生徒と同じ入力を教師NNが使うことで、一貫性のある目標を設定することができる。さらに複数の学習データの線形補間を入力に使うmixupをアグレッシブに使うことが重要であった(図1)。
図1 knowledge distillationを実施する場合の様々な方針
左端は、教師NNが固定の入力画像を受け取り、生徒NNがランダムなオーグメンテーションを受ける場合。左から2番目は、教師と生徒がそれぞれ個別のオーグメンテーションを受ける場合、左から3番目は教師と生徒が同一のオーグメンテーションを受ける場合、右端は教師と生徒が同一のオーグメンテーションを受けた上でmixupを施した場合。(図:文献4のL. Beyer et al.,“Knowledge distillation: A good teacher is patient and consistent,”より)
[画像のクリックで拡大表示]
2つ目は蒸留時には従来の教師あり学習よりもずっと長い時間学習するということである。データオーグメンテーションが強く、小さいNNへ蒸留するため最適化が難しいためだと考えられる。
これら2つの条件が満たされた場合、大きなデータセットを大きなモデル(BiT-M-R152x2)で学習した結果を小さなモデルのResNet-50に蒸留することで、ImageNetで82.8%の精度を達成できた(元の大きなモデルでは83.0%の精度)。ResNet-50を直接大きなデータセットで学習させていた場合は77.2%であり、5~6%近くも改善できることが示された。
正則化としての蒸留
蒸留には、それ自身が正則化として働くことがわかっている。蒸留とよく似た正則化としてLabel Smoothingがある。これは正解の確率を少し減らし、その他のクラスの確率を一様に少しずつ上げるという方法である。
Label Smoothingは、各クラスに所属するサンプルをより強固にクラス中心に近づける効果があることがわかっている。これは他のクラスからも一様の力で引っ張られることにより均衡点がクラス中心のみになる効果が発生するためだと考えられている5)。
一方で蒸留の場合は自己蒸留のたびに使用される基底関数の数が制限され、関数の表現力が制限されることがわかっている6)。この制約は非線形であり自己蒸留を繰り返すことで、正則化が強くなっていき、一定回数を超えるとUnder fittingを起こし汎化性能は逆に下がってしまう。このような表現力を抑える手法としては、学習を途中で止めるEarly Stoppingが知られているが、Early Stoppingではこのような基底関数を疎にする役割はなく、むしろ使われる基底関数の数自体は多くなることがわかっており、蒸留はEarly Stoppingとは別の仕組みで正則化を実現している。
蒸留の理論的な解明と実用的な発展
本稿では蒸留の仕組みについて解説を試みたが、大きなNNの汎化能力を保ったまま小さなNNになぜ蒸留できるのかについては未解明な部分が多い。
一方で実用的には、今後は巨大な事前学習用データセットを用意して、大きな学習済みモデルを作っておき、それを用途に応じて蒸留して使うような時代が想定される。またほとんどの場合はNN間の蒸留を考えているが、NN内の各モジュール間で蒸留を介して知識のやりとりをすることも考えられる。例えばGLOM(本コラム2021年5月号を参照)は蒸留を使って、重みパラメータを共有することなく位置不変の予測を実現できることを提案している。
今後、蒸留の理論的な解明と実問題での利用が進むと考えられる。
本記事はロボットとAI技術の専門誌『日経Robotics』のデジタル版です
[画像のクリックで別ページへ]
1)G. Hinton et al.,“Distilling the Knowledge in a Neural Network,” NeurIPS Deep Learning and Representation Learning Workshop, 2015. https://arxiv.org/abs/1503.02531
2)T. B. Brown et al.,“Language Models are Few-Shot Learners,”NeurIPS 2020. https://arxiv.org/abs/2005.14165
3)Z. Allen-Zhu et al.,“Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning,”https://arxiv.org/abs/2012.09816
4)L. Beyer et al.,“Knowledge distillation: A good teacher is patient and consistent,” https://arxiv.org/abs/2106.05237
5)R. Müller et al.,“When Does Label Smoothing Help?,” NeurIPS 2019. https://arxiv.org/abs/1906.02629
6)H. Mobahi et al,“Self-Distillation Amplifies Regularization in Hilbert Space,” https://arxiv.org/abs/2002.05715
岡野原 大輔(おかのはら・だいすけ)
Preferred Networks 代表取締役 最高執行責任者
2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。 』
