ARM11から最新CPUまで ARM系プロセッサーの仕組み(2010年12月27日)
https://ascii.jp/elem/000/000/579/579255/

『ARM編第1回の前回で、おおまかなロードマップと製品の特徴は説明した。今回はもう少し細かく、アーキテクチャーの特徴などを説明していきたい。
といっても、ARMプロセッサーは何しろ種類が多い。そこで話をアプリケーションプロセッサーに限り、「ARM11」以降の話をしよう。
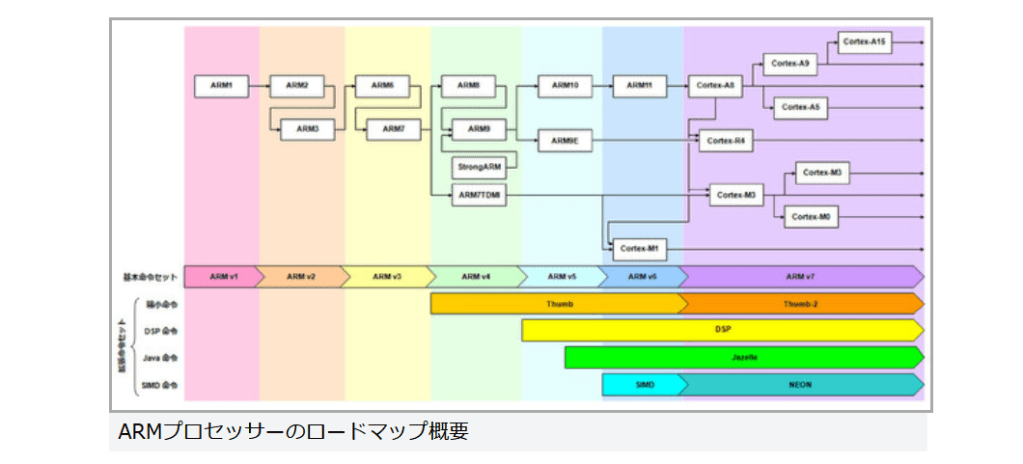
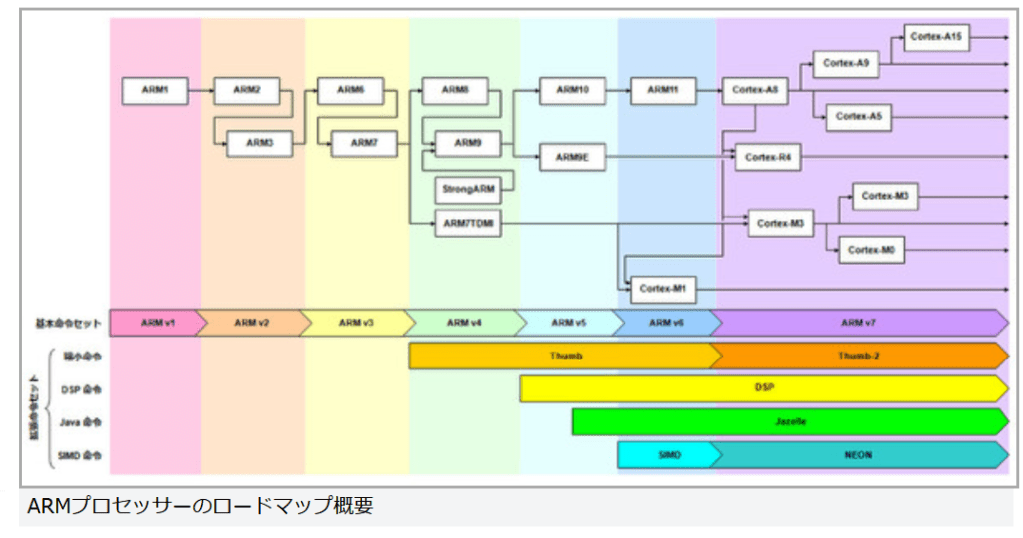
ARMプロセッサーのロードマップ概要
ARMプロセッサーのロードマップ概要
大きな改良とともに登場した ARM11
ARM11のベースとなる「ARM v6」アーキテクチャーが発表されたのは、2001年10月に開催された半導体業界イベント「Micro Processor Forum(MPF) 2001」でのことだ。当時の発表資料を見ると、ARM v5からの改善事項として以下の項目が挙げられている。
キャッシュアーキテクチャーの改善
SIMDの搭載
命令セットの改善
SoC/マルチプロセッサー向けの改良
(同期メカニズムの搭載や新メモリーモデルのサポート)
具体的にはバイエンディアンのサポート※1や、「Unaligned Memory Access」の対応※2、1次キャッシュのサポート(ARM v5までキャッシュは1階層)、「VMSA(Virtual Memory System Architecture) v6」の搭載などの項目が並んでいる。
※1 それまでのARMはリトルエンディアンのみサポートしていたが、ARM v6からLリトルエンディアン/ビッグエンディアンの両方をサポートするようになった。
※2 ARM v5までは、メモリーアクセスは必ず4byte単位だったが、v6から2/1byte単位のアクセスも可能になった。
もっとも、2001年に発表されたのはあくまでも命令セットであるARM v6のみ。これを実装した最初のARM11コアである「ARM1136J-S」「ARM1136JF-S」の発表は、2002年10月に開催された「MPF2002」となった。
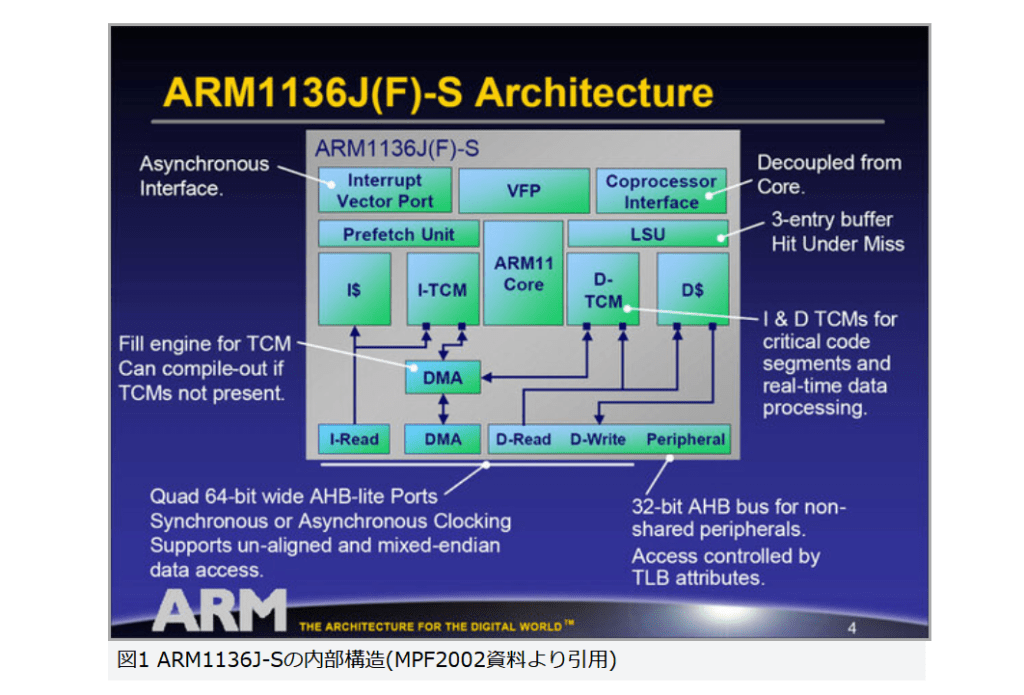
ARM1136J-Sの内部構造は、図1のようになっている。CPUコアについては後述するが、その両側に命令/データの1次キャッシュと「TCM」がそれぞれ配されている。TCMとは「Tightly Coupled Memory」の略で、簡単に言えばCPUから極めて高速(ほぼ1次キャッシュと同じレイテンシ/バンド幅)でアクセスできるメモリーである。
図1
図1 ARM1136J-Sの内部構造(MPF2002資料より引用)
「それならキャッシュでいいだろう?」という声が聞こえそうだが、キャッシュの場合、基本的にはハードウェアが勝手にFill/Retireをしてしまう(プリフェッチ命令などを使い、ある程度明示的に制御することも不可能ではないが)。そのため、例えばリアルタイム制御における割り込みハンドラのような、「キャッシュミスを起こすとそれだけで処理がタイムアウトする」ような性能に厳しい処理の場合、キャッシュに頼らずに確実にプログラムのロード(フェッチ)ができる方法が必要になる。
こうしたケースで役に立つのが、キャッシュ並みに高速なメモリーである。サイズそのものは小さいから(構成によるが、後述の例では16KB)、大きな処理ロジックを載せるには不向きだが、割り込み処理ルーチンくらいなら楽に搭載できる。これはデータ側のTCMも同じだ。例えば周辺機器と高速にデータ入出力を行なう必要がある場合、通常のメモリー経由では余分にレイテンシが掛かってしまう(メモリーから一度キャッシュを経由するため)。しかし、外部からTCMにそのままDMA転送でアクセスすれば、キャッシュを経由しない分少ないレイテンシーでアクセスできるわけだ。
TCMに類するものは、例えばMIPS系であれば「ScratchPad」と呼ばれるメモリーが利用できる。PowerPC系にはTCM/ScratchPadはないものの、「Cache Stashing」(CPU外部から直接キャッシュの内容を書き換える)という機構を持ったものがあり、これでData TCMの代替が可能である。
こうした特長は、当時はまだARM11がアプリケーションプロセッサーよりもコントローラー的な用途に使われるケースが多いと、想定されていたことに起因すると考えていいだろう。ほかにも、図1左上には割り込みコントローラ(Interrupt Vector Port)、右上にはコプロセッサー用のインターフェースが用意されている。単にCPUだけではなく、さまざまなコプロセッサーと組み合わせて使うことを当初から想定してあるあたりは、単なるアプリケーションプロセッサーとは大分異なる。
もっとも、搭載するのはあくまでもキャッシュとTCMだけで、肝心のメモリーやメモリーコントローラーを内蔵しないあたりは、コントローラーというよりもプロセッサー向けの構造といえる。』
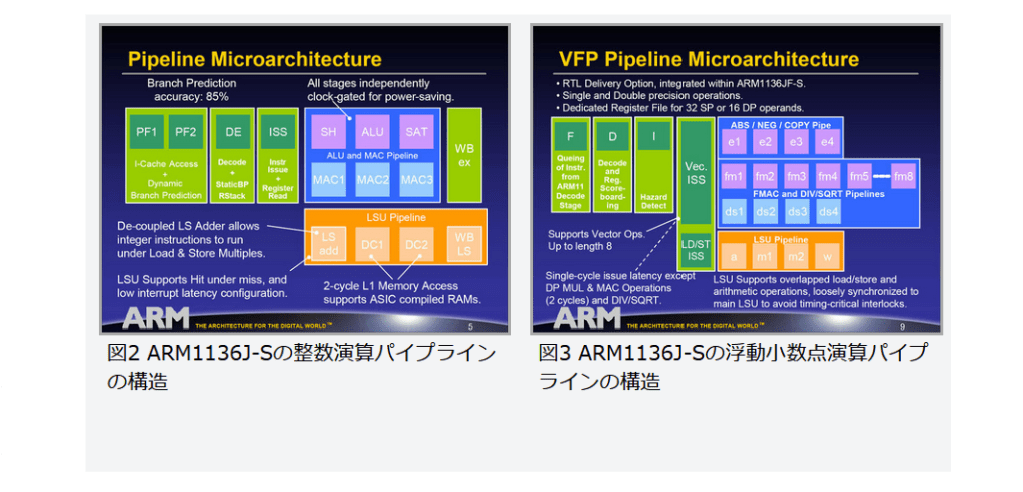
『ARM11のパイプライン構造
図2
図2 ARM1136J-Sの整数演算パイプラインの構造
図3
図3 ARM1136J-Sの浮動小数点演算パイプラインの構造
続いて内部構造について説明しよう。図2が整数演算パイプラインで、図3が浮動小数点演算のパイプライン構造となる。誤解を招かないように書いておくと、ARM11は基本的にシングルイシュー/インオーダーのプロセッサーである。図2ではまるで2命令同時実行が可能なように見えるが、もちろんそんなわけはない。単に実行ユニット部が「ALU/MACパイプライン」と「LSUパイプライン」に分かれている、というだけの話である。これは図3のVFPも同じである。
ちなみに、なぜ「VFP」と言うかといえば、ARM v5まではSIMDはサポートされていなかったため(XScaleの独自拡張であるWireless MMXは除外する)、ARM10までは「FPU」と称していた。ところがARM v6でSIMD拡張が行なわれ、FPUがSIMD演算をサポートしたために、VFPと称するようになったわけだ。
ARM11のパイプラインは、整数演算が8段、浮動小数点が8~16段という、組み込みプロセッサーとしてはやや長いパイプライン構造となっている。もっとも2002年といえば、インテルは「Northwood」(Pentium 4)、AMDは「Palomino」(Athlon)をリリースしていた頃だ。前者は20段、後者ですら10段のパイプラインだから、これに比べればまだ少ないという言い方もできる。
このARM11の発表の際には、リファレンスデザインの実装例も示された(図4)。TSMCの130nm LVプロセスを使い、最悪でも400MHzで動作すること、その際の消費電力は(外部のメモリーを除くと)0.4mW/MHz、つまり400MHz駆動で160mWにすぎないこと、エリア面積(ダイサイズとは異なる)は8.2mm2程度で収まることなどが紹介された。
図4
図4 ARM1136JF-Sのリファレンスデザイン
このARM1136J(F)-Sが、ARM11初のコアである。これに続き、「Thumb-2」という新しい拡張命令搭載した「ARM1156T2(F)-S」が2003年10月に発表された。翌2004年にはさらに、「TrustZone」というメモリー保護機構を搭載した「ARM1176J(F)-S」がリリースされる。
ARM1136J(F)-Sは公称1.25DMIPS/MHzの性能を備えており、この数字はARM1176J(F)-Sも変わらなかったが、Thumb-2を搭載したARM1156T2(F)-Sは、1.41DMIPS/MHzに達している。その一方で、製造プロセスの改善による性能向上の効果も著しい。ARM1156T2(F)-Sは台湾TSMCの「90nm G(標準)プロセス」で600MHz駆動、消費電力は0.42mW/MHz、エリア面積は1.75mm2となっている。
もっと上を行くのがARM1176J(F)-Sで、TSMCの40nm Gプロセスを使うことで990MHz駆動が可能になり、エリア面積は1.17mm2、消費電力は0.105mW/MHzまで押さえ込めるとしている。TSMCの40nm Gプロセスはごく最近のプロセスだが、当時のTSMCの90nm Gプロセスを使っても、252mWほどの消費電力で840DMIPS程度の性能だから、これは十分に高性能と言える数字である。
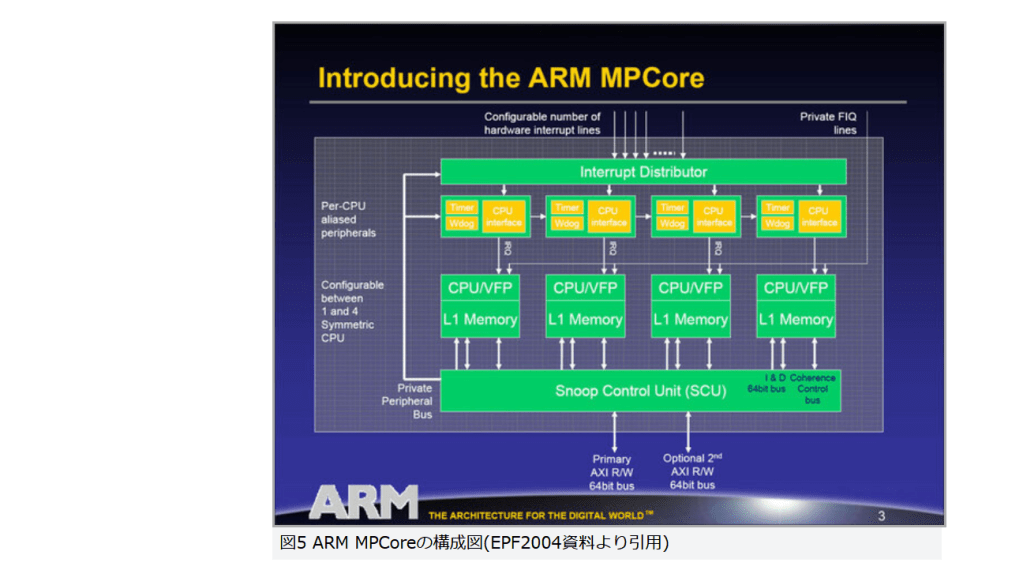
これらの改良で性能不足に対応したほか、さらにARMはARM v6をベースにしたマルチプロセッサー構成のアーキテクチャーを、2004年5月に開催された組み込み機器向けイベント「EPF(Embedded Processor Forum) 2004」で発表した。これは「ARM MPCore」として製品化されている(図5)。』
『Cortex-A8でスーパースカラーの実装に踏み切る
性能向上と並行して、ARMは次世代コアの開発も行なっており、これは「ARM v7」アーキテクチャーとして2005年に発表された。ARM v7に関してはアーキテクチャーそのものと同時に、実装したコアである「Cortex-A8」も同時に発表されている。Cortex-A8の名前は、スマートフォンやタブレット端末のCPUとして、よく目にするだろう。
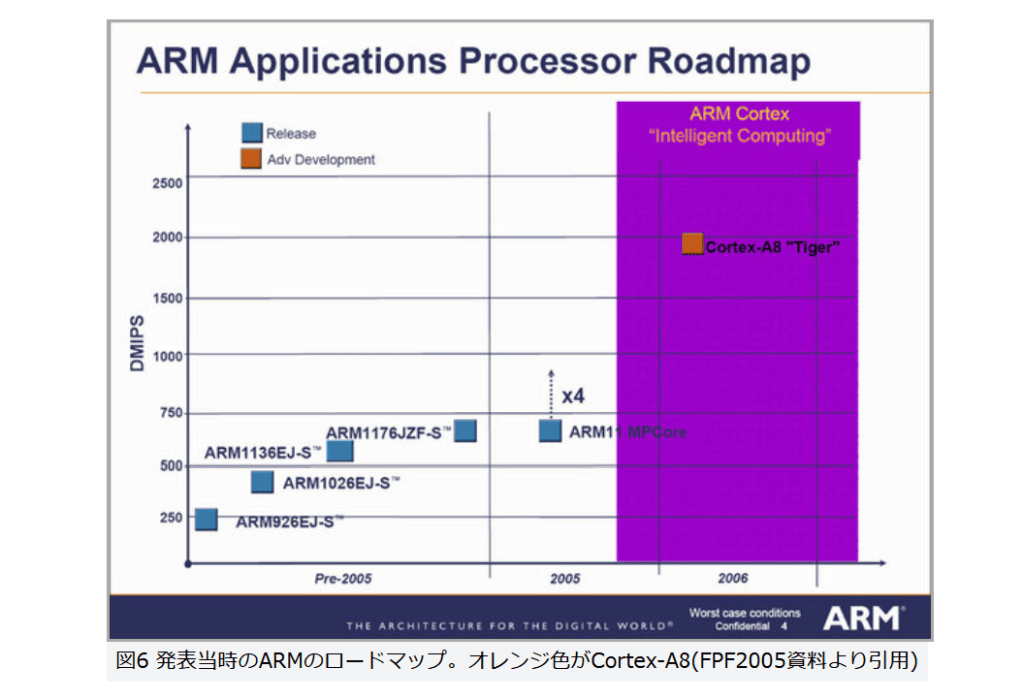
Cortex-A8の設計目標は「1GHz駆動で2000DMIPS」、つまり2.0DMIPS/MHzの実現である(図6)。これの実現のために、ARMとしては初のスーパースカラーの実装に踏み切った。
図6
図6 発表当時のARMのロードマップ。オレンジ色がCortex-A8(FPF2005資料より引用)
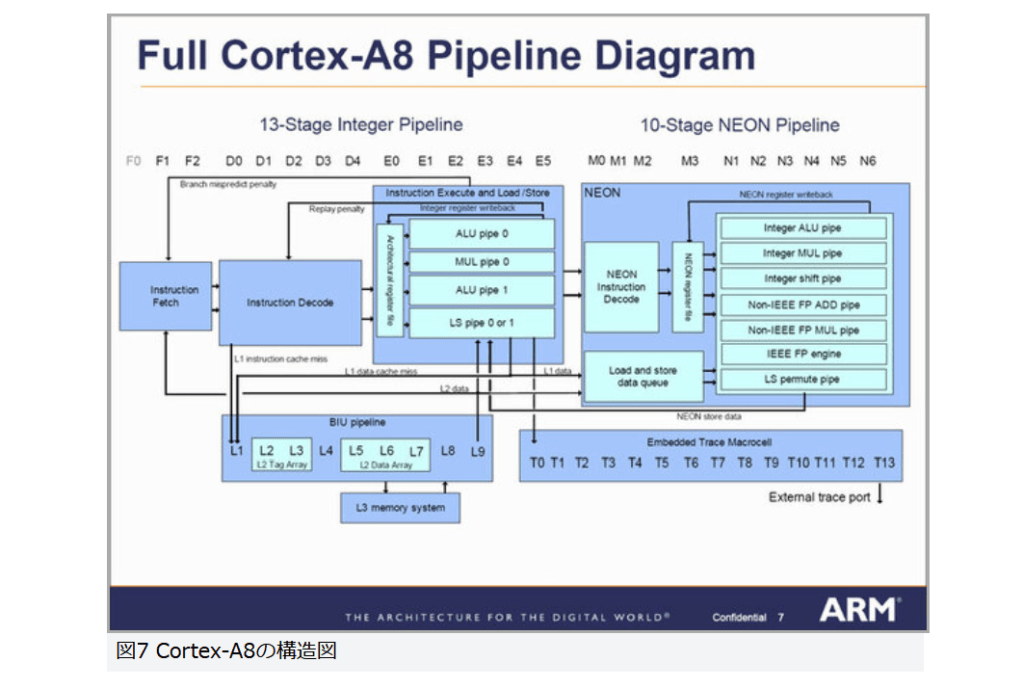
図7はCortex-A8のパイプライン構造であるが、図左にあるように命令フェッチの時点で2命令/サイクルの取り込みを行ない(矢印が2本出ている)、これをデコードして同時2命令発行を実現している。
図7
図7 Cortex-A8の構造図
実行ユニットは3つ用意され、それぞれは独立して実行されるという仕組みだ。図7では4つに見えるが、「ALU pipe 0」と「MUL pipe 0」は実はひとつのパイプで、ALUかMultiply(乗算)のどちらかを実行できる。ただしアウトオブオーダーは、Coetex-A8ではまだ実装されていない。
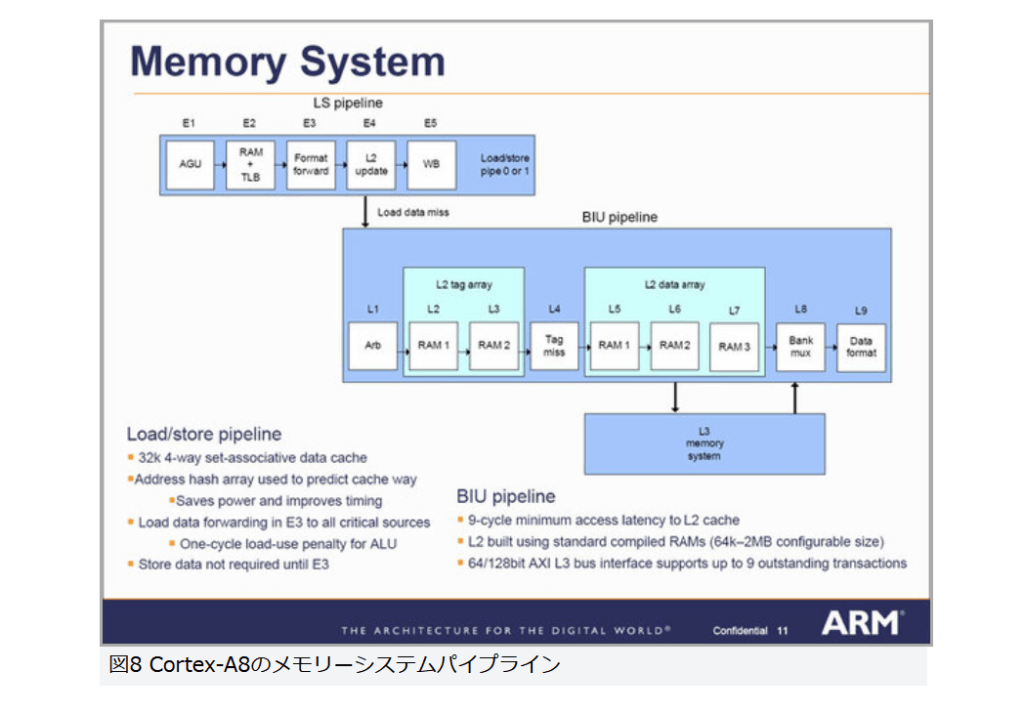
当然ながら、これを支えるメモリーシステムも大きく変化している。ロード/ストアパイプラインや、これと連動するバスインターフェースユニットのパイプラインは、2次キャッシュの存在を前提に構成されていることがわかる(図8)。
図8
図8 Cortex-A8のメモリーシステムパイプライン
こうした構成は、従来ARMが得意としてきたコントローラー系の用途にはまるで適さない。逆に言えば、ARM v7では「Cortex-A/R/M」という3種類にアーキテクチャーを分け、それぞれに適した内部構成を採用することで、こうした構成が可能になったと言える。
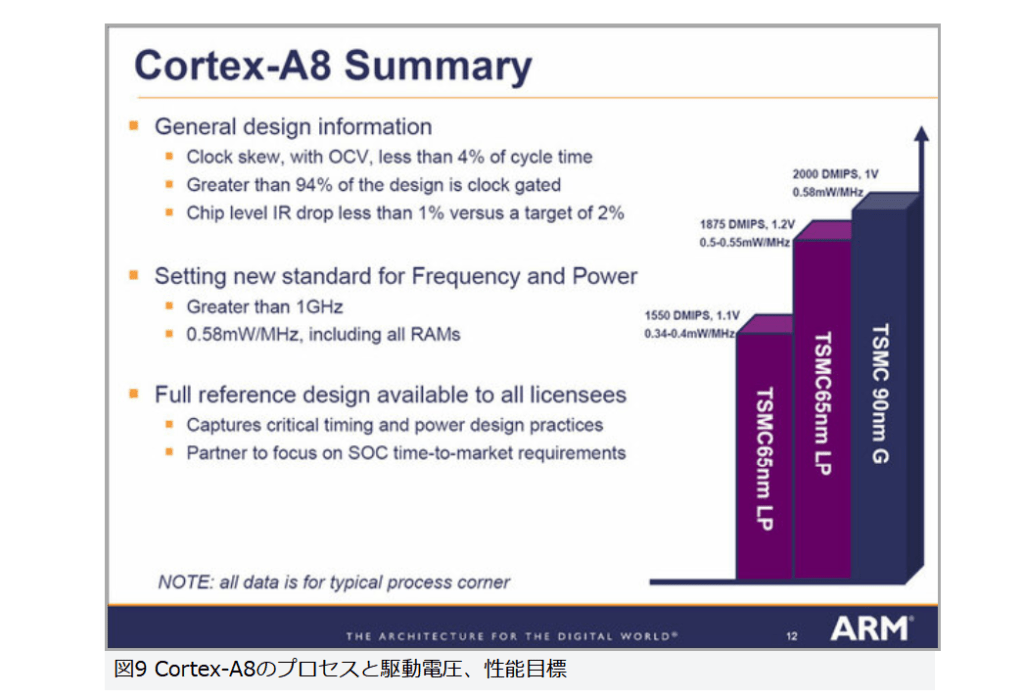
ちなみに、この時にはまだ設計目標が示されただけで、実際の性能値などは示されなかった。2006年5月に開催された半導体関連イベント「Spring Processor Forum 2006」(SPF2006)では、ARMから実装例が発表されている(図9)。
図9
図9 Cortex-A8のプロセスと駆動電圧、性能目標
TSMC 90nm Gプロセス、1.0V駆動、2000DMIPS、0.58mW/MHz
TSMC 65nm LPプロセス、1.2V駆動、1875DMIPS、0.5~0.55mW/MHz
TSMC 65nm LPプロセス、1.1V駆動、1550DMIPS、0.34~0.4mW/MHz
さすがに同じ90nm Gプロセスを使うと、ARM1176J(F)-Sより消費電力が増えているが、65nmのLPプロセスで低電圧駆動させた場合、多くても310mW程度で済んでいる。それでいて性能は2倍になっているのだから、これは大きな進歩と言える。』
『Cortex-A9で性能強化、Cortex-A5は低消費電力強化
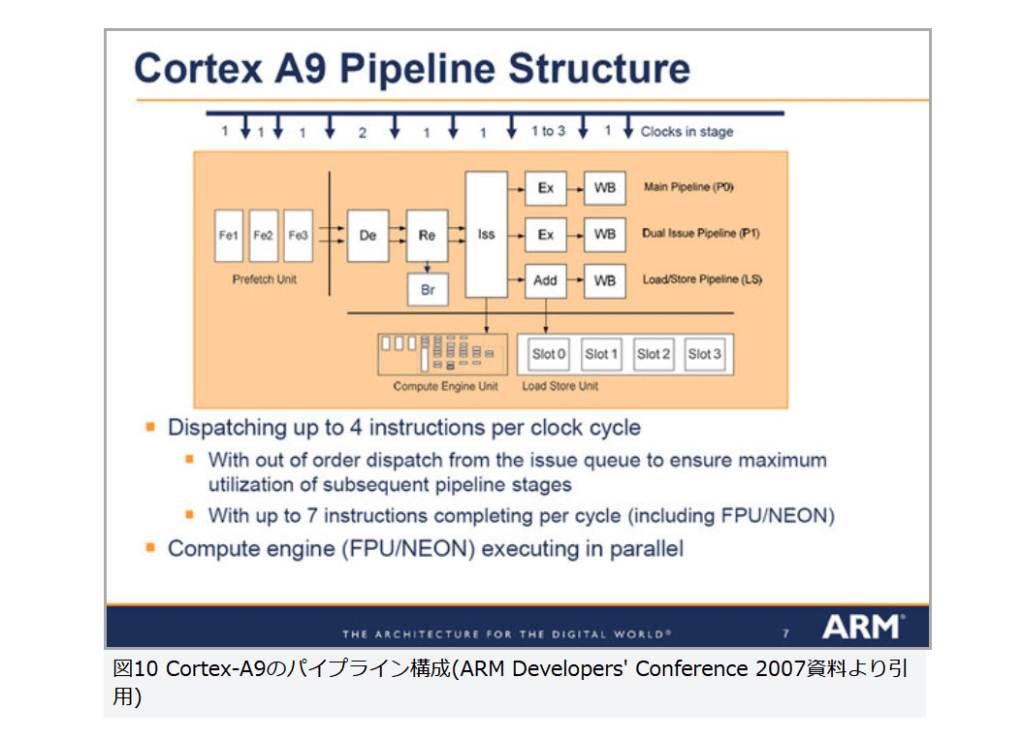
このCortex-A8にアウトオブオーダーを実装したのが、「Cortex-A9」である(図10)。パイプラインは8ステージで9~11段の可変長となり、最大4命令/サイクルのディスパッチ性能を持つ(フェッチ/デコードそのものは引き続き2命令/サイクル)。これにより、最大で2.5DMIPS/MHzまで処理性能を引き上げられた。
図10
図10 Cortex-A9のパイプライン構成(ARM Developers’ Conference 2007資料より引用)
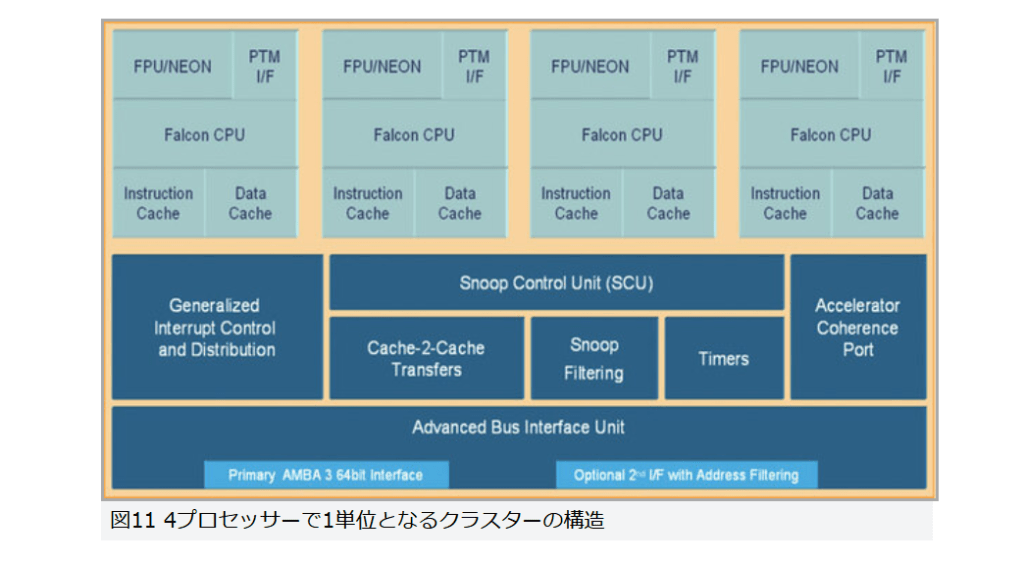
また、Cortex-A9では当初からマルチプロセッサー構成が考慮されており、4プロセッサーまではスケーラブルに対応が可能である。5プロセッサー以上も可能だが、その場合は4プロセッサー単位で「クラスター」という論理構成を作り(図11)、このクラスター同士を「AMBA 3」と呼ぶチップ内バスで接続する形になる。
図11
図11 4プロセッサーで1単位となるクラスターの構造
TSMCの65nm Gプロセスを使い、性能優先の最適化で構成した場合、Cortex-A9は830MHz駆動で2075DMIPS、消費電力はおよそ0.48mW/MHz程度となり、従来と同等レベルの性能/消費電力に抑えられている。また、同じTSMCでも40nm Gプロセスを使った場合、性能最適化なら2GHz駆動、消費電力最適化ならば0.31mW/MHzが可能という。
特に性能最適化の場合では、デュアル構成で10000DMIPS、1.9Wという数字も示されている。このクラスになるとローエンドのx86とほぼ同じ性能レンジに突入しており、結果として昨今では、タブレット端末などに多く利用されるようになってきたわけだ。
このCortex-A9に続いて発表されたのは、Cortex-Aシリーズのローエンドともいえる「Cortex-A5」である。Cortex-A8が事実上Cortex-A9で代替される一方で、「Cortex-A9ほどの性能は必要ないから、もっと低消費電力/省サイズのアプリケーションプロセッサーコアが欲しい」というニーズに応えたものだ。
この結果、内部構造はCortex-A8をシングルイシューに戻したような形となっている(図12)。
図12
図12 Cortex-A5のパイプライン構成(ARM Forum 2009資料より引用)
もっとも図にあるように、分岐状況によっては一時的にデュアルイシューで動作することもある。性能は1.57DMIPS/MHz程度で、Cortex-A8/A9に比べれば低いが、同じシングルイシューのARM11と比較すると、性能は20%増しになっている。TSMCの40nm Gプロセスを使った場合、1GHz以上の動作周波数で消費電力は0.08mW/MHz以下、40nm LPプロセスを使った場合でも600MHz程度の動作周波数で0.12mW/MHzと発表されている。
Cortex-A9の2倍の性能を目指すCortex-A15
Cortex-A5/A8/A9と揃ったラインナップで、2010年に追加されたのが「Cortex-A15」コアである。こちらはまだ内部構造などは明らかにされていないが、Cortex-A9の拡張とでも言うべき方向性で、以下の特徴を持つことが明らかにされている。
3命令/サイクルのデコードと8命令/サイクルのディスパッチを持つアウトオブオーダーのスーパースカラー構造。
トータルでおおむねCortex-A9の2倍程度の性能。
1次キャッシュはCortex-A9までの16KBから2倍の32KBに。さらに最大4MBのL2キャッシュを搭載。
メモリーなどの外部インターフェースには、128bit幅の「AMBA 4」を採用。
64bitアドレッシングや仮想化のサポート。
また、Cortex-A9をさらに拡張したマルチプロセッサー構成をサポートし、当初から1~8コアの構成が用意されるようだ。
さて、随分長くなってしまったので今回はここまで。次回はもう少し実際の製品をご紹介したいと思う。それでは皆様、良いお年を。』
