DeepSeek-R1とは?性能概要や使い方、料金体系を徹底解説!
https://www.ai-souken.com/article/what-is-deepseek-r1




















『2025-01-28
facebook
x
instagram
linked-in
この記事のポイント
DeepSeek-R1は大規模強化学習(RL)を採用した推論能力に特化した最新の言語モデルです。
技術革新が重ねられたDeepSeek-R1は、WebUIとAPIを通じて利用できるリーズナブルな料金設定も魅力です。
MITライセンスのもとで公開されているため、幅広い用途に自由に使うことができます。
監修者プロフィール
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
技術革新により進化し続けるAIの世界で、OpenAI o1の登場により「推論能力に特化した大規模言語モデル」注目されています。
その一つが、前モデルであるDeepSeek-V3をベースに、大規模強化学習を取り入れて推論性能を飛躍的に向上させた「DeepSeek-R1」です。
本記事では、DeepSeek-R1の概要から技術的特徴、料金体系、使い方、利用時の注意点に至るまで、幅広い視点からその魅力に迫っていきます。
特に、従来のモデルを凌駕する「推論性能」、それを実現する「独自の開発手法」、そして「オープンソース戦略」といった点に焦点を当て、DeepSeek-R1の可能性を紐解いていきます。
推論能力を必要とする多種多様な課題に挑む皆さんにとって、DeepSeek-R1は新たな可能性を拓く道具となるでしょう。
目次
DeepSeek-R1とは?
「DeepSeek-R1-Zero」と「DeepSeek-R1」
DeepSeek-R1-Distillモデル(蒸留モデル)
オープンソースライセンス(MITライセンス)
DeepSeek-R1のパフォーマンス
DeepSeek-R1-Distillモデルの性能
DeepSeek-R1の技術的特徴
基本モデルに対する大規模強化学習(RL)の直接適用
2つのRLステージと2つのSFTステージによる開発パイプライン
蒸留による小型モデルの高性能化
DeepSeek-R1の料金
料金の具体例
OpenAI o1シリーズとの比較
DeepSeek-R1の使い方
- Webチャット (chat.deepseek.com)
- API (platform.deepseek.com)
- ローカルでの実行方法
スマホアプリ
DeepSeek利用時の注意点
オープンソースプロジェクト「Open-R1」
まとめ
DeepSeek-R1とは?
DeepSeek-R1は、DeepSeekシリーズの最新モデルであり、推論能力に特化した大規模言語モデル(LLM)です。
前モデルであるDeepSeek-V3をベースとし、強化学習(RL) を適用することで、推論性能を大幅に向上させています。
また、DeepSeek-R1オープンソース・低価格でありながら、推論、数学、コーディングといったタスクにおいて、OpenAI-o1と同等の性能を達成しています。
➡️DeepSeek-R1のパフォーマンス
パートナー募集
「DeepSeek-R1-Zero」と「DeepSeek-R1」
DeepSeek-R1の開発過程では、まず、DeepSeek-R1-Zeroというモデルが開発されました。
このモデルは、「教師あり微調整(SFT)」を一切行わず、強化学習(RL)のみで学習させたものです。
DeepSeek-R1-Zeroは、自己検証、内省、長い思考連鎖(CoT)の生成といった、高度な推論能力を示すことが確認されました。
しかし一方で、無限ループ、可読性の低さ、言語の混在といった課題も抱えていました。
これらの課題を解決し、さらに性能を向上させるために開発されたのがDeepSeek-R1です。
DeepSeek-R1では、強化学習の前に、少量のコールドスタートデータを組み込むことで、DeepSeek-R1-Zeroの課題を克服し、より安定した、人間が読みやすい出力を実現しています。
!
ここでいうコールドスタートデータとは、強化学習を開始する前に、モデルに初期の手がかりや方向性を与えるために使用される、少量の高品質なデータを指します。
DeepSeek-R1の開発では、このコールドスタートデータを活用することで、強化学習を効率化し、最終的なモデルの性能向上に貢献しています。
DeepSeek-R1-Distillモデル(蒸留モデル)
DeepSeek-R1は、小さなモデルへの知識蒸留を容易にし、効率性と性能のバランスが取れたモデルの実現を視野に入れています。
このアプローチによって開発されたのが、DeepSeek-R1-Distillモデルです。
DeepSeek-R1-Distillモデルは、DeepSeek-R1によって生成された推論データを用いて、Qwen2.5やLlama3といったオープンソースモデルを微調整することで、性能を向上させています。
現在、1.5B、7B、8B、14B、32B、70Bのパラメータを持つ、6つのDeepSeek-R1-Distillモデルが公開されています。
モデル ベースモデル
DeepSeek-R1-Distill-Qwen-1.5B Qwen2.5-Math-1.5B
DeepSeek-R1-Distill-Qwen-7B Qwen2.5-Math-7B
DeepSeek-R1-Distill-Llama-8B Llama-3.1-8B
DeepSeek-R1-Distill-Qwen-14B Qwen2.5-14B
DeepSeek-R1-Distill-Qwen-32B Qwen2.5-32B
DeepSeek-R1-Distill-Llama-70B Llama-3.3-70B-Instruct
オープンソースライセンス(MITライセンス)
DeepSeek-R1は、MITライセンスの下で公開されており、商用利用、改変、派生物の作成が自由に行えます。
ただし、DeepSeek-R1-Distillモデルは、ベースモデルのライセンス(Apache 2.0、Llama 3.1、Llama 3.3)に従う必要があります。
このように、DeepSeek-R1は、強力な推論能力とオープンソース戦略を組み合わせた、革新的なAIモデルと言えるでしょう。
DeepSeek-R1のパフォーマンス
DeepSeek-R1は、様々なベンチマークにおいて、優れた性能を示しています。ここでは、その具体的な数値を見ていきましょう。
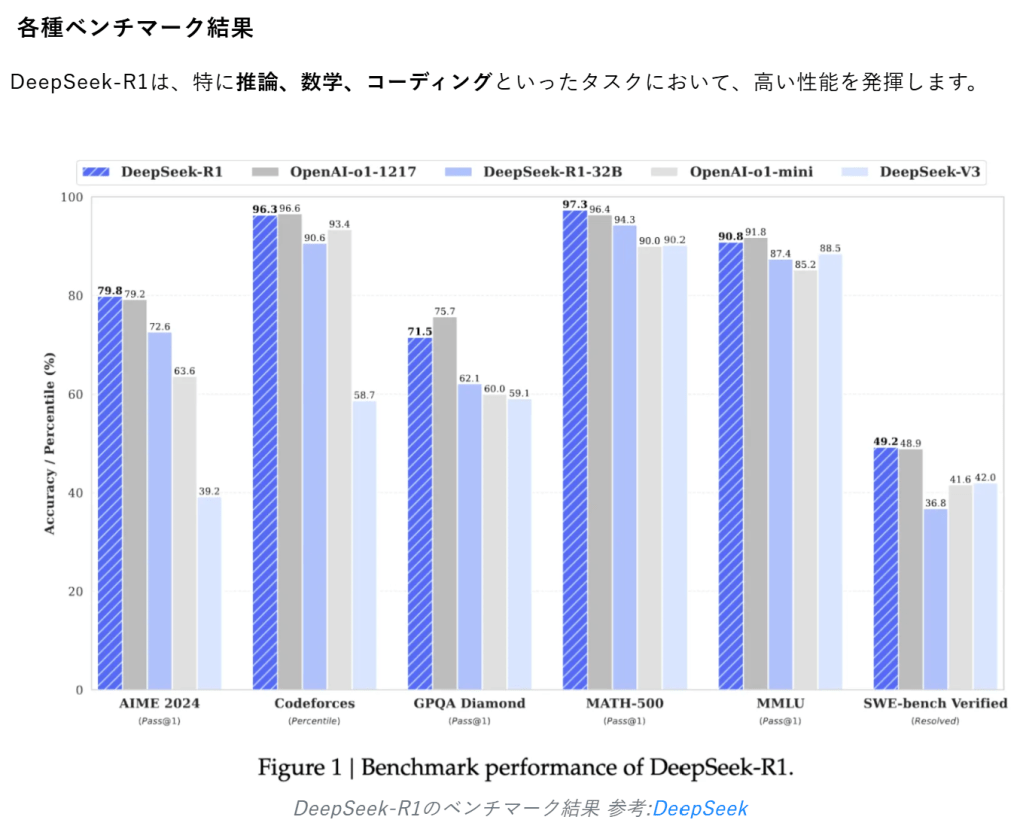
各種ベンチマーク結果
DeepSeek-R1は、特に推論、数学、コーディングといったタスクにおいて、高い性能を発揮します。
DeepSeek-R1のベンチマーク結果
DeepSeek-R1のベンチマーク結果 参考:DeepSeek
推論
AIME 2024 (Pass@1): 79.8% (OpenAI-o1-1217と同等)
MATH-500 (Pass@1): 97.3% (OpenAI-o1-1217を上回る)
コード
LiveCodeBench (Pass@1-CoT): 65.9% (OpenAI-o1-1217を上回る)
Codeforces (Elo Rating): 2029 (OpenAI-o1-1217と同等)
知識
MMLU (Pass@1): 90.8%
GPQA Diamond (Pass@1): 71.5%
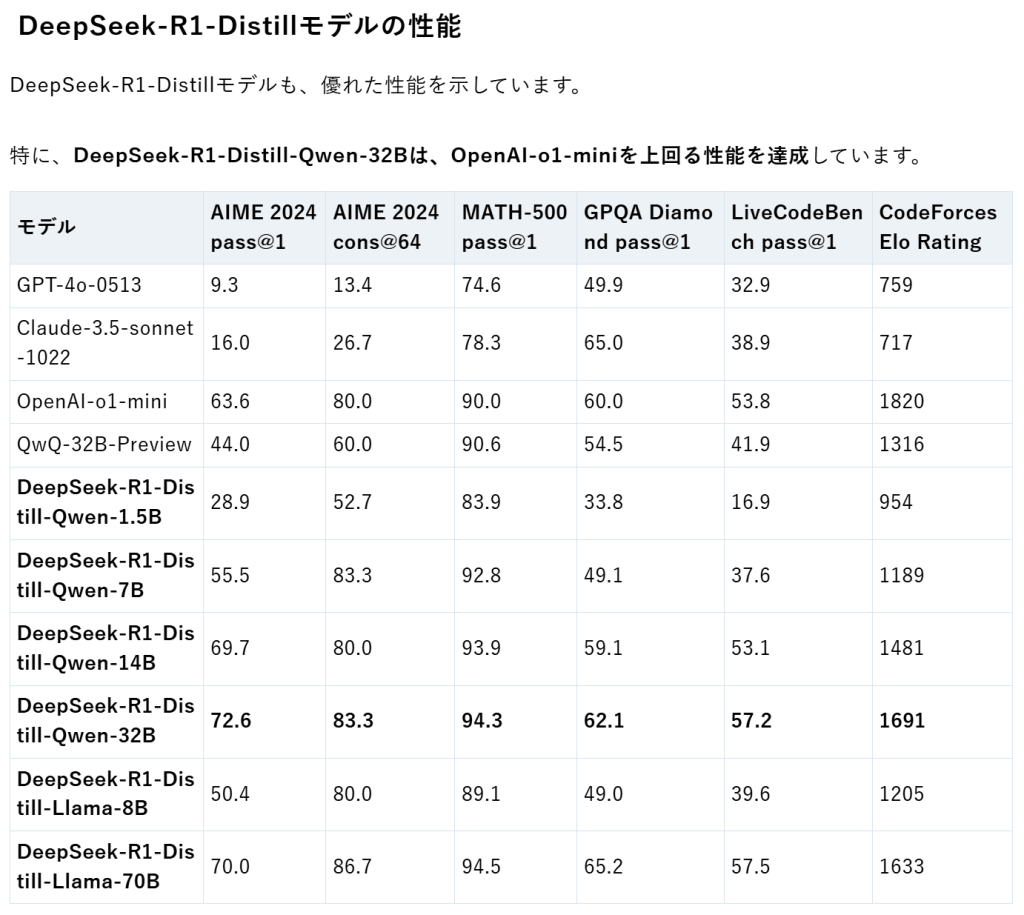
DeepSeek-R1-Distillモデルの性能
DeepSeek-R1-Distillモデルも、優れた性能を示しています。
特に、DeepSeek-R1-Distill-Qwen-32Bは、OpenAI-o1-miniを上回る性能を達成しています。
モデル AIME 2024 pass@1 AIME 2024 cons@64 MATH-500 pass@1 GPQA Diamond pass@1 LiveCodeBench pass@1 CodeForces Elo Rating
GPT-4o-0513 9.3 13.4 74.6 49.9 32.9 759
Claude-3.5-sonnet-1022 16.0 26.7 78.3 65.0 38.9 717
OpenAI-o1-mini 63.6 80.0 90.0 60.0 53.8 1820
QwQ-32B-Preview 44.0 60.0 90.6 54.5 41.9 1316
DeepSeek-R1-Distill-Qwen-1.5B 28.9 52.7 83.9 33.8 16.9 954
DeepSeek-R1-Distill-Qwen-7B 55.5 83.3 92.8 49.1 37.6 1189
DeepSeek-R1-Distill-Qwen-14B 69.7 80.0 93.9 59.1 53.1 1481
DeepSeek-R1-Distill-Qwen-32B 72.6 83.3 94.3 62.1 57.2 1691
DeepSeek-R1-Distill-Llama-8B 50.4 80.0 89.1 49.0 39.6 1205
DeepSeek-R1-Distill-Llama-70B 70.0 86.7 94.5 65.2 57.5 1633
これらの結果から、DeepSeek-R1は、推論、数学、コーディングといったタスクにおいて、最先端の性能を実現していることがわかります。
また、DeepSeek-R1-Distillモデルは、比較的小さなモデルサイズでありながら、高い性能を達成しており、効率性と性能のバランスに優れていると言えるでしょう。
DeepSeek-R1の技術的特徴
DeepSeek-R1の優れた性能を支えているのは、以下のような技術的特徴です。
基本モデルに対する大規模強化学習(RL)の直接適用
DeepSeek-R1の最も注目すべき点は、基本モデルに対して、大規模な強化学習(RL)を直接適用していることです。
従来、多くのモデルでは、教師あり微調整(SFT)を行った後にRLを適用するのが一般的でした。
しかし、DeepSeek-R1では、SFTを介さずに、基本モデルに直接RLを適用することで、モデル自身が推論の過程を自己学習することを可能にしています。
!
ここで適用されている大規模な強化学習(RL)の具体的なアルゴリズムは、Group Relative Policy Optimization (GRPO) と呼ばれるものです。
GRPOは、従来の強化学習手法で必要とされる価値モデルを用いず、グループ内の複数の出力の報酬を比較することで方策を更新します。
これにより、計算コストを削減しながら、効率的に学習を行うことができます。
このアプローチにより、DeepSeek-R1-Zeroは、自己検証、内省、長い思考連鎖(CoT)の生成といった、高度な推論能力を獲得しました。
2つのRLステージと2つのSFTステージによる開発パイプライン
DeepSeek-R1の開発では、2つのRLステージと2つのSFTステージを組み合わせた、独自のパイプラインが採用されています。
第1段階 (RL): 基本モデルにRLを適用し、推論能力を強化 (DeepSeek-R1-Zero)。
第2段階 (SFT): 少量のコールドスタートデータを組み込み、RLで発生した課題(無限ループ、可読性の低さ、言語の混在)を解決。
第3段階 (RL): 第2段階で微調整されたモデルをさらにRLで強化し、推論能力を向上。
第4段階 (SFT): 最終的なモデルの調整。
このパイプラインにより、DeepSeek-R1は、推論能力と人間にとっての読みやすさを両立した、高品質なモデルに仕上がっています。
蒸留による小型モデルの高性能化
DeepSeek-R1では、大規模なモデルの推論パターンを、より小さなモデルに蒸留する技術が採用されています。
具体的には、DeepSeek-R1によって生成された推論データを、Qwen2.5やLlama3といったオープンソースモデルに適用し、微調整することで、効率性と性能のバランスが取れたモデルを実現しています。
この技術により、リソースが限られた環境でも、DeepSeek-R1の優れた推論能力を活用することが可能になります。
これらの技術的特徴により、DeepSeek-R1は、従来のモデルを凌駕する推論性能を実現しています。
DeepSeek-R1の料金
DeepSeek-R1は、WebUI (チャット形式のインターフェース) または APIを通じて利用可能です。
WebUIを利用する場合は無料でDeepSeek-R1の機能を試すことができます。
APIを利用する場合は、従量課金制となっており、入力トークン数と出力トークン数に基づいて料金が発生します。
項目 deepseek-reasoner (DeepSeek-R1)
入力トークン 100万トークンあたり 0.14ドル(キャッシュヒット時)
100万トークンあたり 0.55ドル(キャッシュミス時)
出力トークン 100万トークンあたり 2.19ドル
コンテキストウィンドウ 64K
最大CoTトークン 32K
最大出力トークン 8K
!
deepseek-reasoner (DeepSeek-R1) の出力トークンについて
DeepSeek-R1の出力トークンには、CoT(Chain of Thought)からのすべてのトークンと最終的な回答が含まれます。
キャッシュヒットとキャッシュミスについて
料金の具体例
例えば、100万トークンの入力(キャッシュミス)と、100万トークンの出力を伴うリクエストを送信した場合、料金は以下のように計算されます。
入力トークン料金: 0.55ドル (100万トークンあたり)
出力トークン料金: 2.19ドル (100万トークンあたり)
合計料金: 0.55ドル + 2.19ドル = 2.74ドル
OpenAI o1シリーズとの比較
以下のグラフは、DeepSeek-R1と他のo1クラス推論モデルの、入力/出力API料金を比較したものです(100万トークンあたり)。
DeepSeek-R1とo1シリーズの料金比較
DeepSeek-R1とo1シリーズの料金比較 (参考:DeepSeek)
このグラフからもわかるように、DeepSeek-R1は入出力のいずれにおいても、o1シリーズと比較して優れたコストパフォーマンスを発揮します。
内製開発研修
DeepSeek-R1の使い方
DeepSeek-R1は、Webチャット、API、ローカル環境など、様々な方法で利用することができます。
- Webチャット (chat.deepseek.com)
DeepSeekの公式ウェブサイト では、DeepSeek-R1とチャット形式で対話することができます。
ウェブサイトにアクセスし、アカウントを作成またはログイン
画像の黄色矢印「DeepThink」ボタンをオンにすることで、DeepSeek-R1を利用できます。
Web検索機能との併用も可能です。
deepthinkボタン
!
推論過程は中国語表記の場合がありますが、回答は入力言語・指定した言語(英語など)で行われます。
- API (platform.deepseek.com)
DeepSeekは、OpenAI互換のAPI (platform.deepseek.com) を提供しており、開発者は自身のアプリケーションにDeepSeek-R1を組み込むことができます。
APIを利用するには、まずDeepSeekのウェブサイトでアカウントを作成し、APIキーを取得する必要があります。
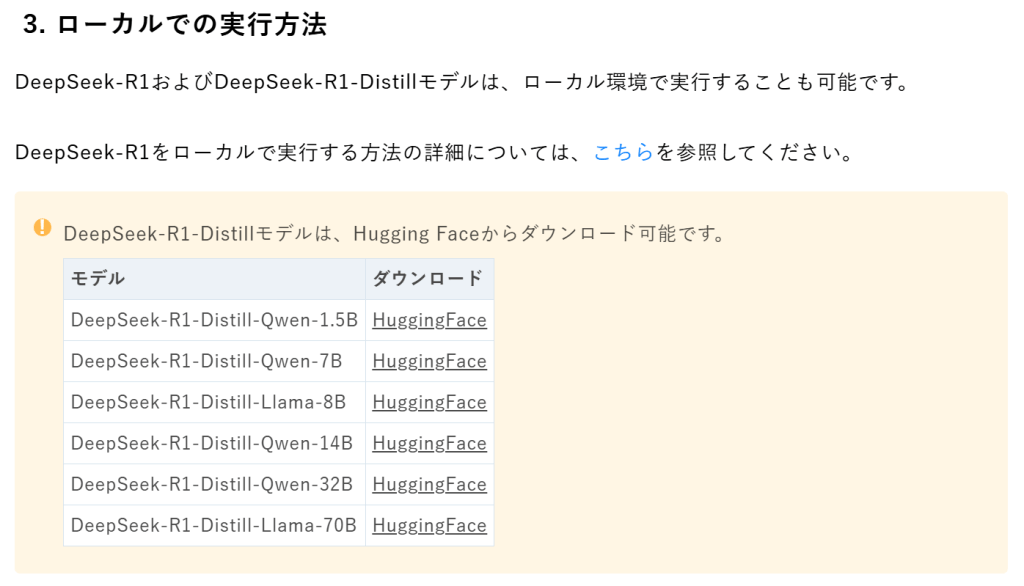
- ローカルでの実行方法
DeepSeek-R1およびDeepSeek-R1-Distillモデルは、ローカル環境で実行することも可能です。
DeepSeek-R1をローカルで実行する方法の詳細については、こちらを参照してください。
!
DeepSeek-R1-Distillモデルは、Hugging Faceからダウンロード可能です。
モデル ダウンロード
DeepSeek-R1-Distill-Qwen-1.5B HuggingFace
DeepSeek-R1-Distill-Qwen-7B HuggingFace
DeepSeek-R1-Distill-Llama-8B HuggingFace
DeepSeek-R1-Distill-Qwen-14B HuggingFace
DeepSeek-R1-Distill-Qwen-32B HuggingFace
DeepSeek-R1-Distill-Llama-70B HuggingFace
スマホアプリ
deepseek スマホアプリ
DeepSeekは、スマホアプリからでも利用可能です。
完全日本語対応で、R1・検索機能のいずれも利用できます。
Deepseek スマホアプリの利用画面
DeepSeek利用時の注意点
DeepSeekのサービスを利用する際には、利用規約を十分に確認し、理解しておくことが重要です。
利用規約の詳細については、こちらの記事を参照してください。
特に注意すべき点は以下の通りです。
準拠法および管轄裁判所
中国の法律に準拠し、中国の裁判所が管轄となるため、日本国内の法律や裁判所は適用されません。
ユーザーデータの保管場所
中国国内のサーバーに保管され、中国の法律に基づいて取り扱われます。日本の個人情報保護法が適用されない可能性があります。
DeepSeekの責任制限、保証否認、補償
DeepSeekは、損害に対する一切の責任を負わず、サービスの保証も行いません。利用者が規約違反や違法行為を行った場合、損害を補償する義務を負う可能性があります。
利用を考えている方は、必ず最新の利用規約を確認し、内容を理解した上で利用するようにしてください。
DeepSeek利用規約
DeepSeekプライバシーポリシー
DeepSeekオープンプラットフォーム利用規約
AI駆動開発
オープンソースプロジェクト「Open-R1」
DeepSeek-R1の技術に興味を持った方や、実際に自分の手で再現してみたいという方は、オープンソースプロジェクト「Open-R1」が役立ちます。
Open-R1 は、Hugging FaceがGithub上で公開しているリポジトリです。
DeepSeek-R1の再現を目指して、コミュニティ主導で開発が進められています。
このリポジトリでは、DeepSeek-R1の学習や評価に必要なコードや手順が提供されており、誰もがDeepSeek-R1の再現に挑戦することができます。
Open-R1の特徴
DeepSeek-R1の再現に必要なツールや手順を提供
シンプルさを重視した設計
コミュニティ主導で開発
Open-R1でできること
SFTやGRPOを用いたDeepSeek-R1の学習
R1ベンチマークによるモデルの評価
「distilabel」 を用いた合成データの生成
Open-R1は、DeepSeek-R1をより深く理解し、活用するための貴重なリソースとなるでしょう。興味のある方は、ぜひリポジトリを覗いてみてください。
まとめ
本記事では、DeepSeekシリーズの最新モデル「DeepSeek-R1」について解説しました。
DeepSeek-R1は、推論能力に特化した大規模言語モデルです。前モデルDeepSeek-V3をベースに、基本モデルへの大規模強化学習(RL)の直接適用という革新的なアプローチで開発されました。特に、自己検証や長い思考連鎖(CoT)の生成といった高度な推論能力が注目されます。
また、DeepSeek-R1-Distillモデルにより、効率性と性能のバランスの取れた小型モデルも提供されています。MITライセンスの下で公開されているため、商用利用や改変も自由です。
DeepSeek-R1は、質疑応答、研究開発、コンテンツ生成など、様々な分野での活用が期待されており、今後のAI開発を大きく加速させる可能性を秘めています。
メルマガ登録
AI活用のノウハウ集「AI総合研究所」サービスご紹介資料
「AI総合研究所 サービス紹介資料」は、AI導入のノウハウがないというお客様にも使いやすい最先端のAI導入ノウハウを知れる資料です。
資料ダウンロード
facebook
x
instagram
linked-in
監修者
坂本 将磨
Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
facebook
x 』
