重回帰分析
https://ja.wikipedia.org/wiki/%E9%87%8D%E5%9B%9E%E5%B8%B0%E5%88%86%E6%9E%90




『出典: フリー百科事典『ウィキペディア(Wikipedia)』
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)
出典検索?: “重回帰分析” – ニュース · 書籍 · スカラー · CiNii · J-STAGE · NDL · dlib.jp · ジャパンサーチ · TWL(2016年2月)
重回帰分析(じゅうかいきぶんせき)は、多変量解析の一つ。
回帰分析において独立変数が2つ以上(2次元以上)のもの。
独立変数が1つのものを単回帰分析という。
一般的によく使われている最小二乗法、一般化線形モデルの重回帰は、数学的には線形分析の一種であり、分散分析などと数学的に類似している。
適切な変数を複数選択することで、計算しやすく誤差の少ない予測式を作ることができる。
重回帰モデルの各説明変数の係数を偏回帰係数という。
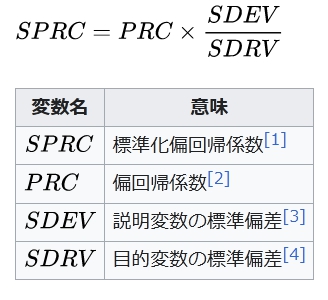
目的変数への影響度は偏回帰係数は示さないが標準化偏回帰係数は目的係数への影響度を示す。下記の関係式が知られている。
S P R C = P R C × S D E V S D R V {\displaystyle SPRC=PRC\times {\frac {SDEV}{SDRV}}}
変数名 意味
S P R C {\displaystyle SPRC} 標準化偏回帰係数[1]
P R C {\displaystyle PRC} 偏回帰係数[2]
S D E V {\displaystyle SDEV} 説明変数の標準偏差[3]
S D R V {\displaystyle SDRV} 目的変数の標準偏差[4]
例
中学生を対象に調査を行いその結果を重回帰分析したところ下の式が得られたとする。
t C × 3 + t S J × 5 + 20 = n {\displaystyle t_{C}\times 3+t_{SJ}\times 5+20=n}
変数名 意味
t C {\displaystyle t_{C}} 中学で勉強した時間数
t S J {\displaystyle t_{SJ}} 小学生の時代の塾の学習時間数
n {\displaystyle n} 知っている英単語の数
この場合、Aさんが中学で 100 {\displaystyle 100}時間、小学生時代 20 {\displaystyle 20}時間勉強していたら 100 × 3 + 20 × 5 + 20 = 420 {\displaystyle 100\times 3+20\times 5+20=420} 語を知っているという計算になる。
中学で1時間勉強すると平均的には3単語を覚えているという解釈ができる。
ここでは × 3 {\displaystyle \times 3}や × 5 {\displaystyle \times 5}という数値を重回帰分析で計算・算出するが、あくまで平均的な値であり個々のサンプルにおいてその通りに一致するとは限らない。
例えば、Aさんの英単語数は 420 {\displaystyle 420}語ではなく、実際には 450 {\displaystyle 450}語かもしれない。
全体の平均を取ると、3や5という値を取ると全体が最もうまく説明できデータによく適合するということから出てきた数値になる。
また英単語数を決めるのが勉強時間だという関係は、分析者が自分で決めるため絶対的なものではない。
あくまで勉強時間が独立変数(説明変数)だと仮定した上で分析している。そのため、予測を行うことはできてもその方向に因果関係があることは保証されない。
独立変数が二値の場合
性別や民族といった名義尺度データを説明変数に用いたい場合は、ダミー変数を導入して重回帰分析を行うことになる。
日本国内で見かける数量化I類は、実質的にはこれと同じ分析である。
ダミー変数は通常、条件ごとに説明変数を作り 0 {\displaystyle 0}と 1 {\displaystyle 1}を持つデータを設定して、分析する。
その際、重回帰では一つは回帰式に含めない(多重共線性を避けるためである)。
信号の色による車の通過速度の違いを例に取ると、
v ¯ = 50 × δ B + 15 × δ Y + 0 {\displaystyle {\overline {v}}=50\times \delta _{B}+15\times \delta _{Y}+0}
変数 意味
v ¯ {\displaystyle {\overline {v}}} 信号機のある交差点を通過する車の平均速度 ( k m / h {\displaystyle km/h})
δ B {\displaystyle \delta _{B}} 信号が青なら 1 {\displaystyle 1}、さもなくば 0 {\displaystyle 0}
δ Y {\displaystyle \delta _{Y}} 信号が黄色なら 1 {\displaystyle 1}、さもなくば 0 {\displaystyle 0}
という式が得られうる。
この場合、青でも黄色でもない条件のデータは、赤になり、計算値は定数の0になる。
つまり、赤なら平均速度 0 k m / h {\displaystyle 0km/h}となる。
解釈としては交差点を抜ける車はいないという意味になる。
また、青の場合なら平均速度は 50 k m / h {\displaystyle 50km/h}と推定されたことになる。
男女の体重の予測では、
w = 12 × δ m + 50 {\displaystyle w=12\times \delta _{m}+50}
変数 意味
w {\displaystyle w} 体重 ( k g {\displaystyle kg})
δ m {\displaystyle \delta _{m}} 男なら 1 {\displaystyle 1}、さもなくば 0 {\displaystyle 0}
という予測式が得られたら、男でない「女」の平均体重は 50 k g {\displaystyle 50kg}と計算される。
男性なら 12 k g {\displaystyle 12kg}多く、 62 k g {\displaystyle 62kg}が平均になるという意味になる。
ちなみにこれは同じデータを男女別に単純平均したものと一致する。
性別、学年など複数の変数を組み合わせて、分析することもできる。
w = α × δ m + β × G {\displaystyle w=\alpha \times \delta _{m}+\beta \times G}
変数 意味
w {\displaystyle w} 体重 ( k g {\displaystyle kg})
δ m {\displaystyle \delta _{m}} 男なら 1 {\displaystyle 1}、さもなくば 0 {\displaystyle 0}
G {\displaystyle G} 学年
また、「男性で1年生なら 1 {\displaystyle 1}」というように細かく分けてダミー変数を増やして重回帰を行うことも可能ではある。
ただし、説明変数の数が大きく増すので、連関の強いダミー変数同士で多重共線性の問題が生じやすいこと、十分な信頼性を確保するためにはサンプル数がかなり求められることなどを考えると、実用性に乏しい。
多重共線性
「多重共線性」も参照
独立変数(説明変数)を選択する際、マーケティングやアンケートでよく使う一般的な重回帰の場合、複数の説明変数同士は強い相関がないという仮定が入っている。
そのため、説明変数同士が関連性の高い場合、一般化線形モデルでは多重共線性と呼ばれる状態になるため、係数が直感に反する値になることがある。
例えば、小学校での定期テスト得点から重回帰で分析する場合、理科の点数を従属変数に、数学と国語とを説明変数にした場合、数学が増えると理科の点数が増え、国語の点数が高ければ理科の点数が減るといった意味の係数が出ることがある。
これは数学と国語との点数の間に強い相関がある(一般に、どちらの成績も学習習慣や知能の影響を強く受ける)ことで起こりうる。
この場合のように説明変数間の相関が高いと係数が不安定になりやすい。
実務的対応としては、一方を除いて分析するのが最も手軽である。
また、数学と国語の平均点と、数学と国語の得点の差というように和と差に数字を加工すると、この2つは相関がたいてい低く、かつ解釈しやすい。
数学と国語の得点の差は、数学の方が高い生徒の方が理科の点数が高い傾向があるというように理解できるためである。
ただし、このような正の相関を持つ変数同士の差得点は元の変数よりも信頼性が落ちるので、サンプル数を増やすなどの対応が求められる。
また、適切な予測力を実質的には持たない変数であっても、説明変数に加えると予測式自体の寄与率(決定係数)R2は上がることが多い。
そのため、単なるR2ではなく、その分を調整した修正R2を参照する、ステップワイズ法(英語版)等で投入する説明変数を取捨選択する、AICを見るなどの対応が求められる。
ソフトウェア
ほぼ全ての統計パッケージで重回帰分析は実行できる。
Microsoft Excel
SAS
Stata
SPSS
College Analysis
多変量解析入門
R言語 - 統計解析言語。重回帰分析だけでなく多変量解析ほか多くの統計関数を標準装備したフリーウェア。『モデル式』でモデル記述や当てはめが容易。他アプリケーションのファイル取込やODBC接続対応。FDA公認。CRANなる仕組で世界の膨大なソフトを無償利用可能。可視化機能に優れ、日本語対応。マルチプラットフォーム。Rの基本パッケージ中の回帰、分散分析関数一覧。重回帰分析はlm関数で行えるほか、独自に書かれた関数もある: [1][2]。
関連する分析手法
回帰分析
分散分析 - 重回帰モデルの有意性の検定に用いられる
数量化I類 - ダミー変数を用いた回帰分析の別名
ロジスティック回帰 - 目的変数は名義尺度、ロジスティック関数に基づく予測
プロビット分析 - 目的変数は名義尺度、正規累積関数に基づく予測
正準相関分析 - 変数群の一方が一変数のみであれば、重回帰分析と同様
パス解析 - 古典的なパス解析は、複雑なモデルについて重回帰分析の繰り返しから個々の係数を推定
共分散構造分析(構造方程式モデリング) - 重回帰モデルに対し、適合度統計量等の算出が可能
脚注
^ 英: standardised partial regression coefficient
^ 英: partial regression coefficient
^ 英: standard deviation of explanatory variable
^ 英: standard deviation of response variable
表話編歴
統計学
カテゴリ:
回帰分析数学に関する記事
最終更新 2022年3月27日 (日) 14:50 (日時は個人設定で未設定ならばUTC)。
テキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。追加の条件が適用される場合があります。詳細については利用規約を参照してください。
』
